arm neon vs intel sse 知识普及
一、 SIMD 技术简述
传统的通用处理器都是标量处理器,一条指令执行只得到一个数据结果。但对于图像、信号处理等应用,存在大量的数据并行性计算操作,这个时候,提高数据的并行性从而提高运算的性能就显得尤为重要。因此,SIMD 技术应运而生。
SIMD 的英文全称是 Single Instruction Multiple Data,即单指令流多数据技术,SIMD 的概念是相对于 SISD(Single Instruction Single Data,单指令流单数据)提出的。SIMD 技术最初通过将 64 位寄存器的数据拆分成多个 8 位、16 位、32 位的形式来实现 byte、half word、word 类型数据的并行计算;在后续,为了进一步增加计算的并行度,SIMD 技术开始通过增加寄存器位宽来满足应用对算力的需求。
对于传统的 SIMD 技术,Intel 的 MMX、SSE 系列、AVX 系列,以及 ARM 的 Neon 架构都是其中的代表。
二、介绍SSE【https://blog.csdn.net/qq_27825451/article/details/103934359】
1.1 数据并行的两种实现
在计算机体系中,数据并行有两种实现路径:
MIMD(Multiple Instruction Multiple Data,多指令流多数据流)
SIMD(Single Instruction Multiple Data,单指令流多数据流)。
其中MIMD的表现形式主要有多发射、多线程、多核心,在当代设计的以处理能力为目标驱动的处理器中,均能看到它们的身影。
同时,随着多媒体、大数据、人工智能等应用的兴起,为处理器赋予SIMD处理能力变得愈发重要,因为这些应用存在大量细粒度、同质、独立的数据操作,而SIMD天生就适合处理这些操作。
SIMD结构有三种变体:向量体系结构、多媒体SIMD指令集扩展和图形处理单元。
注意:SIMD本身并不是一种指令集,而是一种处理思想哦,现在的一些指令集都支持SIMD。
1.2 各个CPU指令集的发展简介
(1)MMX指令——Multi Media eXtension,多媒体扩展指令集
1996年,MMX指令集率先在Pentium处理器中使用,MMX指令集支持算数、比较、移位等运算,MMX指令集的向量寄存器是64bit。
(2)SSE指令集系列——Streaming SIMD Extensions,单指令多数据流扩展
SSE在1999年率先在Pentium3中出现,向量寄存器由MMX的64bit拓展到128bit;
SSE2在2002年出现,包括了SIMD的浮点和整型运算的指令以及整型和浮点数据之间的转换;
SSE3在2004年出现,支持不对其访问,处理虚数运算的复杂指令以及水平加减操作运算指令;
SSE4.1在2006年出现,加入了处理字符串文本和面向应用的优化指令;
SSE4.2指令
总结:所有的SSE系列指令的向量寄存器都是128bit哦。
(3)AVX指令集系列——Advanced Vector Extensions
AVX指令集是Sandy Bridge和Larrabee架构下的新指令集,AVX是在之前的SSE128位扩展到和256位的单指令多数据流。
AVX出现在2008年,由128bit拓展到256bit,增强了数据重排和灵活的不对齐地址访问;
AVX2出现在2011年,增加了256bit的整数向量操作,融合乘加,跨通道数据重排等等;
AVX-512出现在2014年,由256bit拓展到512bit;
(4)Intel IMCI指令集
IMCI出现在2010年,向量寄存器长度拓展到512bit。
(5)其他指令集
AES、FMA3、EM64-T、VT-x等等
这里有一张指令集大致的发展过程表格
1.3 关于CPU指令的说明
上面的一些指令集,都是针对Intel的CPU指令的,各个芯片厂商都有相应的指令集,只不过是名称不一样,如AMD的也同样包含很多指令集,这里就不介绍了。
其他 SIMD 扩展部件还包括
摩托罗拉 PowerPC 处理器的 AltiVec、
Sun 公司 SPARC 处理器中的 VIS、
HP 公司 PA-RISC 处理器中的 MAX、
DEC 公司 Alpha 处理器中的 MVI-2、
MIPS公司 V 处理器中的 MDMX、
AMD处理器中的3DNow!、
ARM内核中的NEON、CEVA公司的VCU 等。
另外,SIMD 扩展部件最初仅用于多媒体领域和数字信号处理器中,后来,研究人员将SIMD 扩展部件应用到高性能计算机中,如,IBM 的超级计算机 BlueGene/L 和国产的神威蓝光超级计算机中都集成短向量扩展部件。国产处理器中,龙芯、迈创以及魂芯一号都含有 SIMD 扩展部件。
————————————————
版权声明:本文为CSDN博主「LoveMIss-Y」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_27825451/article/details/103934359
三、ARM NEON优化(一)——NEON简介及基本架构【http://zyddora.github.io/2016/02/28/neon_1/】
【ARM NEON优化(二)——NEON编程, 优化心得及内联汇编使用心得(http://zyddora.github.io/2016/03/16/neon_2/)】
文旨在介绍ARMv7开始增加的一项advanced SIMD extension——NEON技术。有助于帮助读者理解NEON概况,提供的实例分析有助于迅速上手NEON编程。阅读此文要求读者有基本的C/C++经验及汇编代码经验,若没有也没关系,多理解查阅资料即可。Good luck~!
Catalog
SIMD及NEON概览
SIMD
Single Instruction Multiple Data (SIMD)顾名思义就是“一条指令处理多个数据(一般是以2为底的指数数量)”的并行处理技术,相比于“一条指令处理几个数据”,运算速度将会大大提高。它是Michael J. Flynn在1966年定义的四种计算机架构之一(根据指令数与数据流的关系定义,其余还有SISD、MISD、MIMD)。
许多程序需要处理大量的数据集,而且很多都是由少于32bits的位数来存储的。比如在视频、图形、图像处理中的8-bit像素数据;音频编码中的16-bit采样数据等。在诸如上述的情形中,很可能充斥着大量简单而重复的运算,且少有控制代码的出现。因此,SIMD就擅长为这类程序提供更高的性能,比如下面几类:
- Block-based data processing.
- Audio, video, and image processing codes.
- 2D graphics based on rectangular blocks of pixels.
- 3D graphics.
- Color-space conversion.
- Physics simulations.
在32-bit内核的处理器上,如Cortex-A系列,如果不采用SIMD则会将大量时间花费在处理8-bit或16-bit的数据上,但是处理器本身的ALU、寄存器、数据深度又是主要为了32-bit的运算而设计的。因此NEON应运而生。
NEON
NEON就是一种基于SIMD思想的ARM技术,相比于ARMv6或之前的架构,NEON结合了64-bit和128-bit的SIMD指令集,提供128-bit宽的向量运算(vector operations)。NEON技术从ARMv7开始被采用,目前可以在ARM Cortex-A和Cortex-R系列处理器中采用。
NEON在Cortex-A7、Cortex-A12、Cortex-A15处理器中被设置为默认选项,但是在其余的ARMv7 Cortex-A系列中是可选项。NEON与VFP共享了同样的寄存器,但它具有自己独立的执行流水线。
NEON架构(数据类型/寄存器/指令集)
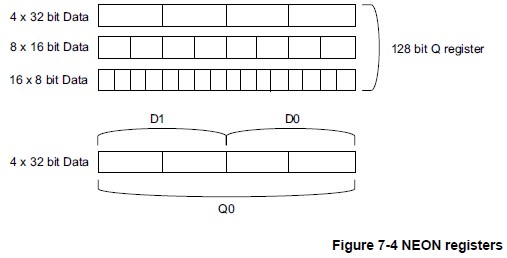
NEON支持的数据类型
- 32-bit single precision floating-point 32-bit单精度浮点数;
- 8, 16, 32 and 64-bit unsigned and signed integers 8, 16, 32 and 64-bit无符号/有符号整型;
- 8 and 16-bit polynomials 8 and 16-bit多项式。
NEON数据类型说明符:
- Unsigned integer U8 U16 U32 U64
- Signed integer S8 S16 S32 S64
- Integer of unspecified type I8 I16 I32 I64
- Floating-point number F16 F32
- Polynomial over {0,1} P8
注:F16不适用于数据处理运算,只用于数据转换,仅用于实现半精度体系结构扩展的系统。
多项式算术在实现某些加密、数据完整性算法中非常有用。
NEON寄存器(重点)
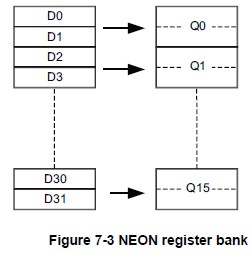
NEON寄存器有几种形式:
- 16×128-bit寄存器(Q0-Q15);
- 或32×64-bit寄存器(D0-D31)
- 或上述寄存器的组合。
注:每一个Q0-Q15寄存器映射到一对D寄存器。
寄存器之间的映射关系:
- D<2n> 映射到 Q 的最低有效半部;
- D<2n+1> 映射到 Q 的最高有效半部;
结合NEON支持的数据类型,NEON寄存器有如下图的几种形态:
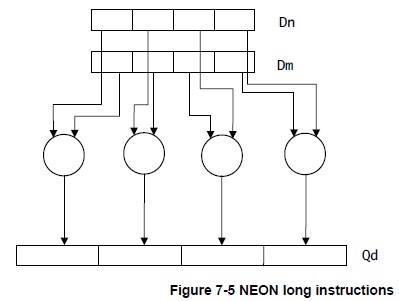
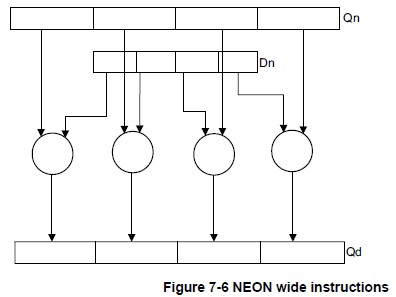
NEON 数据处理指令可分为:
- Normal instructions can operate on any vector types, and produce result vectors the same size, and usually the same type, as the operand vectors.
- Long instructions operate on doubleword vector operands and produce a quadword vector result.(操作双字vectors,生成四倍长字vectors) The result elements are usually twice the width of the operands, and of the same type.(结果的宽度一般比操作数加倍,同类型) Long instructions are specified using an L appended to the instruction.(在指令中加L)
- Wide instructions operate on a doubleword vector operand and a quadword vector operand, producing a quadword vector result.(操作双字 + 四倍长字,生成四倍长字) The result elements and the first operand are twice the width of the second operand elements.(结果和第一个操作数都是第二个操作数的两倍宽度) Wide instructions have a W appended to the instruction.(在指令中加W)
- Narrow instructions operate on quadword vector operands, and produce a doubleword vector result.(操作四倍长字,生成双字) The result elements are usually half the width of the operand elements.(结果宽度一般是操作数的一半) Narrow instructions are specified using an N appended to the instruction.(在指令中加N)
- Saturating variants
- ARM中的饱和算法:
- 对于有符号饱和运算,如果结果小于 –2^n,则返回的结果将为 –2^n;
- 对于无符号饱和运算,如果整个结果将是负值,那么返回的结果是 0;如果结果大于 2^n – 1,则返回的结果将为 2^n – 1;
- NEON中的饱和算法:通过在V和指令助记符之间使用Q前缀可以指定饱和指令,原理与上述内容相同。
- ARM中的饱和算法:
下面给出几幅图解释上述指令的操作原理,图片来自Search Results Cortex-A Series Programmer’s Guide
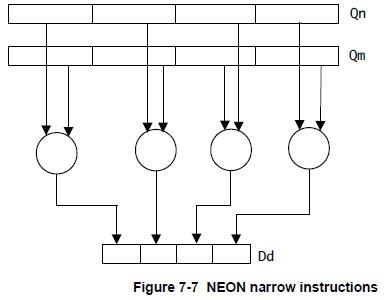
NEON指令集(重点)
ARMv7/AArch32指令格式
所有的支持NEON指令都有一个助记符V,下面以32位指令为例,说明指令的一般格式:
V{<mod>}<op>{<shape>}{<cond>}{.<dt>}{<dest>}, src1, src2
- <mod>
- Q: The instruction uses saturating arithmetic, so that the result is saturated within the range of the specified data type, such as
VQABS,VQSHLetc. - H: The instruction will halve the result. It does this by shifting right by one place (effectively a divide by two with truncation), such as
VHADD,VHSUB. - D: The instruction doubles the result, such as
VQDMULL,VQDMLAL,VQDMLSLandVQ{R}DMULH. - R: The instruction will perform rounding on the result, equivalent to adding 0.5 to the result before truncating, such as
VRHADD,VRSHR.
- Q: The instruction uses saturating arithmetic, so that the result is saturated within the range of the specified data type, such as
- <op> - the operation (for example,
ADD,SUB,MUL). - <shape> - Shape,即前文中的Long (L), Wide (W), Narrow (N).
- <cond> - Condition, used with IT instruction.
- <.dt> - Data type, such as s8, u8, f32 etc.
- <dest> - Destination.
- <src1> - Source operand 1.
- <src2> - Source operand 2.
注: {} 表示可选的参数。
比如:
VADD.I16 D0, D1, D2 @ 16位加法
VMLAL.S16 Q2, D8, D9 @ 有符号16位乘加
NEON支持的指令总结
- 运算:和、差、积、商
- 共享的 NEON 和 VFP 指令:涉及加载、多寄存器间的传送、存储
具体指令请参见ARM® Compiler armasm User Guide - Chapter 12 NEON and VFP Instructions
注:VFP指令与NEON可能相像,助记符也可能与NEON指令相同,但是操作数等等是不同的,涉及多个基本运算。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号