

【论文阅读】End-to-End Object Detection with Transformers(DETR)
摘要:提出了一个新的方法,把目标检测看作直接的集合的预测问题。消除了很多其他方法需要的手工设计的先验的环节,比如非极大抑制、anchor设计等。DETR是什么?DEtection TRansformer, 重要元素包含两项:基于集合的全局损失函数(用二部匹配进行唯一预测)以及一个transformer的encoder-decoder架构。输入一个固定的很小的已学目标的集合,DETR就推理物体和全局图像信息的关系来直接平行输出最终预测的集合。
1.introduction
目标检测的目标是什么?预测一系列bbox集合的位置和每个物体的标签。现有方法的表现受到后处理步骤的影响,比如非极大抑制、anchor设计等。为了简化pipeline,这篇文章用了个直接的集合预测方法来绕过附加的代理任务。
transformer是序列预测的一个流行的框架(我就很好奇这是怎么建模成一个序列预测问题的)。self-attention机制明确对序列中元素之间两两的交互关系进行了建模,使其特别适合于特定情况下的集合预测,比如要求删除重复预测的目标检测任务(这样就不需要非极大抑制什么的了)。DETR可以一次预测所有对象,并使用一个集合损失函数进行端到端训练,在预测目标和ground-truth目标之间进行二部匹配。matching loss function给每个GT目标都分配一个预测值,并且预测目标的排列顺序不便,这样就可以平行地分配。
模型在COCO上面取得很好的效果。
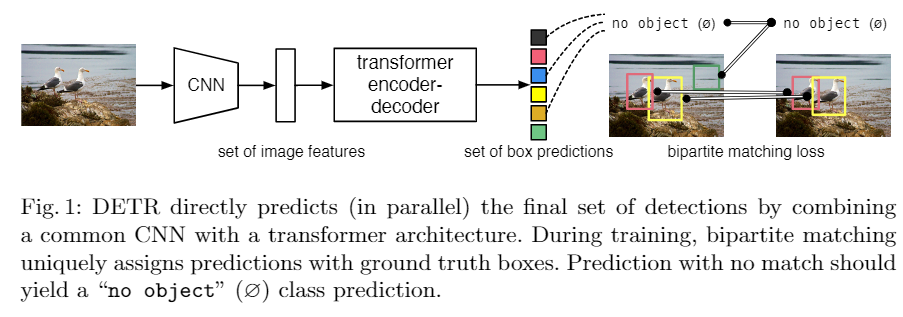
2.related works
baseline方法不适用于目标检测这种元素间有潜在交互的任务,需要全局的推理方案来预测元素之间的交互,来避免冗余。
通常的解决方案是基于匈牙利算法(指派问题解法)设计一个损失,在GT目标和预测目标之间找到一个二部分配。本文仍然用二部分配,但是不用自回归模型,而是用并行解码的transformer。
词汇
streamline
invariant
permutation
auxiliary
crucial
ethos

 浙公网安备 33010602011771号
浙公网安备 33010602011771号