

【论文阅读】A Survey of State-Action Representations for Autonomous Driving
有段时间之前读的文章了,师兄推荐的,感觉挺好的,讲的是状态和动作的设计方式
1 表示车辆
1.1 Encodings
1.1.1 连续坐标系
每辆车的状态用位置、车头朝向和速度表示:
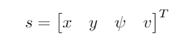
则所有车(N个)状态的集合描述了道路交通的复合状态:

参考系可以是绝对的,但是通常采用ego-centric,以自车为中心的参考系。This reduces the region of state-space in which the policy must perform。
如此的一个状态空间,其规模是。很好理解,每辆车4个维度描述,周围N辆车加上自车,总共4(N+1)。
/////////////////////////////////////////
相关的文章:
This representation is used in (Forbes et al., 1995; Wheeler et al., 2015; Bai et al., 2015; Gindele et al., 2015; Song et al., 2016; Sunberg et al., 2017; Paxton et al., 2017; Lee and Seo, 2017; Shalev-Shwartz et al., 2017; Galceran et al., 2017; Chen et al., 2017; Paxton et al., 2017).

(这句话不是很理解)
////////////////////////////////
1.1.2 离散坐标系
连续坐标系表示的状态空间规模太大。为了缩小,可以将连续的空间离散化,使得状态空间从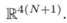 变成
变成 ,I是每辆车的状态对应的离散化空间。(其实就是把高维空间变成散点集合了,看左图到右图)。
,I是每辆车的状态对应的离散化空间。(其实就是把高维空间变成散点集合了,看左图到右图)。

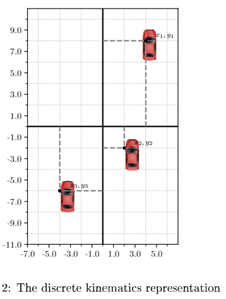
大多数时候,采用均匀采样的方式离散化。但是,均匀离散化后的状态空间,常常面临两个问题:要不然太大(细颗粒度),要不然太粗糙(粗颗粒度)。为解决这一问题, Tehrani et al. (2015)用每辆车的相对速度来调整采样栅格的大小;而Brechtel et al. (2014)建议自动学习一种在给定任务下,对连续空间的充分有效的划分方式。
1.1.3 空间栅格
以上两种编码方式到目前为止是有效的,因为它们使用了表示场景所需的最小的信息量。然而,它们缺少了两种重要的属性。
① 排列不变性
我们希望一个驾驶的策略不依赖于交通环境中的车辆列出的顺序。理想情况下,这一属性应该从框架的设计中自然地得到,而不是仅依赖于数据增强(data augmentation)来涵盖N! 种可能的排列。
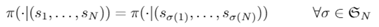
我的理解,假设环境里有ABC三辆车,那么按前两种编码方式,这样的环境的状态表达有3!种(ABC, BCA, CBA等),按道理π(ABC)应该完全等于π(BCA),但如何做到这一点呢?总之这样的编码方式会使得同一个环境具有多种状态上的表达,使强化学习模型造成困惑。
② 对车辆数N的依赖性(想说的应该是不依赖性)
以上表述中,车辆数N总是被涵盖,状态的维度是不确定的,总是4(N+1)。我们想要一个大小恒定的输入,既为了函数的收敛,也是为了避免复杂度指数级增长。
用占据栅格的表达可以解决以上的限制。不显式地表达车辆状态的空间维度,而是隐性地通过状态变量z在栅格图中的布局得到的。
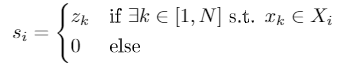
z常常仅用占据信息0-1变量表示,那OGM则是一个单通道图像。也可以有附加的通道,来表示车头朝向和速度。
这种状态空间的大小是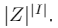 ,I应该就是栅格的数量,长乘宽。
,I应该就是栅格的数量,长乘宽。

1.2 坐标系
1.2.1 笛卡尔坐标
大部分情况下使用。不详细介绍
1.2.2 极坐标
以自车为原点,建立极坐标。这种策略与LIDAR和radar等传感器的数据格式一致。
角扇区索引:与栅格表示类似。索引的标准不建立在不同的车辆个体身上,也就是说不给一辆车编一个号作为输入。可以根据其所属的离散化的角扇区来归类。每个扇区内保留确知数量的车辆信息(一般只取用最近的,而忽略该扇区更远距离的)。
我的理解:这一方式与“可行驶边界的思想类似”,类似于把极坐标按角度均匀离散化,然后看这些角度上有没有占据,看离的最近的车在哪,由此表示环境。
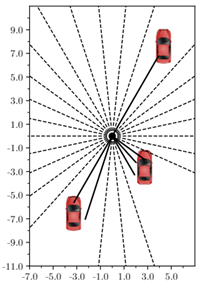
以扇区内最近车的距离来看,就是组成一个单通道向量。也可以有额外的通道,比如速度,车的种类等等。
1.3 相机图片
相机原始图像信息。可以是顶视角,也可以是前视角。
用这种方式,基本上不需要对原始图像进行预处理就可以获得状态表示(最多就是缩放裁剪之类)。
然而,这种表示的缺点就是太高维了。此外,轨迹规划的传递模型(transition model,不知如何翻译)也几乎没有,因为针对视频的预测太困难。
1.4 其他特征
1.4.1 意图(intentions)
未来轨迹经常取决于驾驶员的内在意图。为了在马尔科夫决策过程的框架中建立动态模型,意图必须作为车辆状态的一部分,但其基本不能直接观测得到。
一些文章的做法:①每个agent的状态里赋一个不可观测的离散化意图:目标位置的点坐标。②在交叉口前给出语义级(semantic)的目标作为意图,包括了{直行,左转,右转,停车}。③上面两种的意图仅是目标终点,其决策过程中的其他属性也可以被表示,比如礼貌程度和进攻性(politeness, aggressivity)。④意图模式(intent modes),描述所有行为,全过程,比如:保持车道,准备换道,换道。⑤基于观测用贝叶斯预测行为的模式。
最后,其他agent的意图可以作为高度表达力的目标函数。
1.4.2 横向特征
给状态附加rule-based特征,比如换道是否可行、换道是否有益。然而,这样的信息一般都储存在动作集和其价值之中(也就是不作为状态向量的一部分)。
1.4.3 纵向特征
不使用纵向上到前车的距离,而使用TTC(time to collision)碰撞时间,附加在状态向量中。定义为:
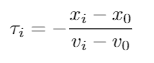
车头时距(time gap)也可以,定义为
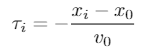
感觉车头时距没有TTC合理。
1.5 Full trajectory
不是仅考虑当前时间步,而是直接处理整条轨迹的全部范围。我理解上好像是用预测得到的其他智能体的整条未来轨迹作为其状态。
2 表示环境
第一节是如何表示动态障碍物,这一节说如何表示静态的环境:①障碍物位置 ②可行驶的空间 ③与交通法规相关的信息
2.1 笛卡尔坐标
简单地列出每个障碍物的位置、几何信息,组成一个tuple
这种表示很紧凑(compact),很简洁,没有冗余,因为安全空间的信息没有被储存。然而,这种表示方法大小并不统一,也缺少数据上的空间结构。
2.2 笛卡尔占据栅格
动态障碍物和静态障碍物的栅格选择可以是不一样的,比如文章中可以用笛卡尔栅格表示静态环境然后用极坐标栅格表示行人的位置。
2.3 极坐标栅格
同上
2.4 相机图像
可以预处理一下,比如做语义分割来辨别可驾驶区域。
2.5 道路结构
路网的先验知识能够提供非常有意义的信息。比如Van对目标追踪到的曲线是描述,是通过其相对于一条已规划好的路径(我的理解就是参考线,类似Frenet坐标系)的方向、宽度(?)、横向偏移量等。Seff从相机图像中提取道路结构特征,比如:可行驶的方向(这么抽象是怎么表示出来的?值得看看)、到交叉口的距离。
上一段说的是路网的先验知识如何获取、如何表示,没有涉及到在状态向量建模的时候如何应用。实际上,状态空间中很少直接包括道路结构信息。
一些文章将路网的静态参考信息,用于定义状态空间的约束条件,很好理解,把超出道路区域的地方设为不可行域。Shalev,把道路信息用于未来潜在碰撞的自车责任认定,避免责任在自车的碰撞状态。
更多的情况是,把道路结构不作为静态的状态信息,而是用于定义奖励函数。比如,在道路的某些区域内行驶能够得到更高的奖励,一般是沿着已知的导航路线并在车道中心处行驶(Levine、Liu等5篇文章)。Gindele用图graph表示路网,用来评估自车规划出的轨迹的cost(这是不是说的也太含糊了,怎么评价呢?)。道路的边界也可以用曲线方程来表示,比如William不把道路信息放在状态state里面,其弊端在于,测试的时候,policy无法依靠路网这一信息,所以最优轨迹的生成始终只能局限于一个特定的道路环境内。我的理解是,如果道路信息不在state里面,环境输入其实是缺失的,训练得到的模型无法利用道路这一信息,不具备根据不同道路信息给出相应action的能力。打个比方,动态和静态障碍物完全不存在的情况下(即其他状态信息完全相同),如果state中不含道路信息,那么模型在弯道和直道的输出将会是同一条轨迹,具体输出哪个就取决于训练时的场景,这显然不合理。同时,如果训练场景兼有弯道和直道且其他信息完全一样的情况下,其奖励函数会不同(因为输入不存在道路信息,但奖励函数与路网相关),这也会造成模型训练时的困惑,使得模型不稳定。只能用直道训练,然后只能在直道上测试。所以我觉得很有必要把道路信息放入state向量。
也可以不放入state向量,然后用在线的方式,根据道路信息对获得的结果作优化调整,以保持最优解和道路结构信息的一致性。
2.6 交通规则
除了道路结构,交通规则也可以被编码成为状态表示的一部分。
比如,Paxton在状态空间中加入了一些特征,描述当前车道的速度限制、车辆是否进入停车区域、有无路权。(这些属性怎么获取?感知模块获取,比如从摄像头图像中提取。)
再一次地,这些交通规则也可以用作奖励函数的定义而不是状态空间的表示。Liu惩罚了红灯进入交叉口、逆向行驶、非机动车道行驶的行为。
同样的,也可以不放入state向量,然后用在线的方式,根据交通规则对获得的结果作优化调整,以保持最优解和交通规则信息的一致性。
3 动作空间
3.1 连续动作
开车时候其实只需要考虑很少的控制器:方向盘角度、油门、制动踏板、变速箱(啊这还少吗?),其中各种踏板或档位变速箱常以一个统一的加速度来表征。
因此,典型的连续动作空间由纵向加速度(acceleration)和转向角(steering angle)组成,通常用于低级控制任务。
高级一些的表示,可以忽略部分动力学约束。比如Chen et al. (2017)直接用纵向速度和横向速度。
最后,如果用独立的策略,分别决定加速度和转角的话,可以只以其中一个作为action,而另一个用另外的方式生成。
3.2 离散动作
为了简化并且加速策略的最优化,常见的方式是将连续动作空间离散化,直接的表示就是把动作空间的范围合并在一起然后离散化。
一般是均匀采样离散化。
通常情况是,只有少量可能的动作会被选择。比如说,只给三种可选的加速度值:{decelerate a = −α, maintain velocity a = 0, accelerate a = +α}。
然而,线性均匀采样的方法总是面临要不然太粗粒度,要不然太高维度的问题。那么一个朴素的想法就是,能不能在出现频率较大的区间细化采样,而较小的区域粗略采样?Xu et al. (2016)提出,由于转向角的概率分布集中于中心(0),因此选择在对数空间中进行采样,就实现了越靠近0采样间距越小越密集。
同样的,也可以只考虑其中一个维度。一些文章的思路是先路径速度分解,先用一个单独的横向规划控制器生成一个路径,然后用强化学习以加速度为action,选定纵向加速度。
一个离散动作空间存在的问题是,离散化暗含了指令上的不连续性,会导致不稳定性和急动的(Jerky)轨迹。比如,加速度此刻是1,下一秒是-1,下一秒是-2,转向角同理。有两种解决办法:①假定这些离散动作都是抽象的,暗含了某种平滑连续的控制策略。我的理解是,将一些抽象的特征作为离散动作,解码后能映射到一个平顺轨迹或者连续变化的控制量。②在动力学上用更高阶的导数作为控制量。比如用加速度的变化率(jerk)或者转向角的变化率。
3.3 时间抽象(temporal abstraction,不知如何翻译)
以上的动作都是直接控制车辆的动力学命令,是直接的控制量,所以要保持在非常高的决策频率(10Hz左右)。Shalev-Shwartz认为,决策时这么密集的时间分辨率,使得价值函数的估计的信噪比非常小(这句话没有理解),因为其方差随时间线性增长,使得训练非常困难。
为解决这一问题,一些方法将原始的动作重复若干个时间步,来降低时间分辨率,由此降低方差。
一个规则性更强的方法是:选择的框架(options framework)。将一系列对于原始动作的子策略的集合称作options,再设计一个选定optiosn的策略,用作高等级的决策。Options是由系统的设计者定义的,作为引入先验知识的方式(比如跟车时的特性,换道时的特性)。尽管和原始动作相比,降低了策略的表达能力(不能够一个策略考虑所有情况),但仍然允许定义复杂的动作,并提高了采样效率。
自动驾驶领域有一些广泛使用的options选项:事实上,自车的横向行为通常可以被三个选项涵盖:{change to left lane, change to right lane, stay on current lane}。此外,有文章也考虑了准备变道的过程(靠近车道的一边,并开启转向灯)。有文章引入了交叉口的单独的选项:{左转,右转}。在有障碍物时,一些特定的maneuver也被使用。比如换道避障行为和超车行为。纵向行为也可以用Options表示。比如brake选项,会使得车辆用最大制动减速度。通过交叉口时,可以分为{等候,稍缓,直接通过}。这些选项不如一组离散化的加速度的表述性强,但策略更容易学习到。也可以使用开环策略(何谓开环策略?),Wei et al. (2010)定义了一组加速度的profiles,比如“保持恒定加速度维持t1秒,保持恒定速度维持t2秒”
最后,合并了纵向和横向目标的options也可以使用,比如(Shalev-Shwartz et al., 2017)用选项图(option graph)生成了10000个语义级的actions,指定了车道级的横向目标,也指定了纵向上与其他车辆相关的相对位置及其速度曲线。(Paxton et al., 2017)的选项:跟车,安全时变道,绕过前车,在交叉口前停车。(Codevilla et al., 2017),加速度和转向角的低级控制策略,由更高级的控制策略{左转,右转,直行}调节。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号