数据库 学习笔记
Entity Relationship Model
课程官网:https://www.pdbmbook.com/
Elements of a Database System
- database model: consists of various data models
- database state: current set of instance
- data model: provides a clear and unambiguous description of the data items, their relationships and various data constraints from a particular perspective
- external data model: contains various subsets of the data items in the logical model, also called views, tailored towards the needs of specific applications or groups of users
- conceptual data model: provides a high-level description of the data items with their characteristics and relationships; logical data model: a translation or mapping of the conceptual data model towards a specific implementation environment
- internal data model: represents the data’s physical storage details
- catalog: contains the data definitions, or metadata (data that describes other data), of your database application; guarantees consistency
- database users
- architect: design conceptual data model
- designer: translate conceptual data model into a logical internal data model
- administrator: responsible for the implementation and monitoring of the database
- application developer: develops database applications in a programming language such as Java or Python
- business user: run applications
- database languages
- DDL: data defining language
- DML: data manipulation language
- SQL: structured query language
Architecture of DBMS
- connection manager: provides facilities to setup a database connection
- security manager verifies whether a user has the right privileges
- DDL compiler: ideally 3 compilers, one for each layer; upon successful compilation, DDL compilers registers the data definitions in the catalog
- query processor
- DML compiler
- query parser and query rewriter
- query optimizer
- query executor
- storage manager
- transaction manager
- buffer manager
- lock manager
- recovery manager
Conceptual Data Modeling using Entity Relationship Model
Phases of design:
- requirement collection and analysis -> database requirements
- -> conceptual design -> conceptual data model
- -> logical design -> logical data model
- -> physical design -> internal data model
ER (entity relationship) model:
- entity types
- attribute types
- domain
- key attribute types
- composite attribute types
- relationship types
- weak entity types
- ternary relationship types
Relational Database
Superkey: a subset of attribute types of a relation R with the property that no two tuples in any relation state should have the same combination of values for these attribute types; may have redundant attributes; may not be unique
Candidate key (key): minimal superkey without redundancy; may not be unique
Primary key: selected candidate key used to identify tuples in the relation; unique
Foreign key: primary key from another tuple
Functional Dependency:
A functional dependency X -> Y between two sets of attribute types X and Y, implies that a value of X uniquely determines a value of Y
Normalization Forms
目的:防止不一致现象;防止有效信息被删除;减少冗余
1NF:
Every attribute type of a relation must be atomic and single valued
2NF:
Every non-prime attribute must depend on each whole candidate key, not just part of it. A non-prime attribute is an attribute that is not part of any candidate key of the relation.
3NF:
消除一个关系中的传递依赖(transitive dependency)
如下表格不符合3NF:
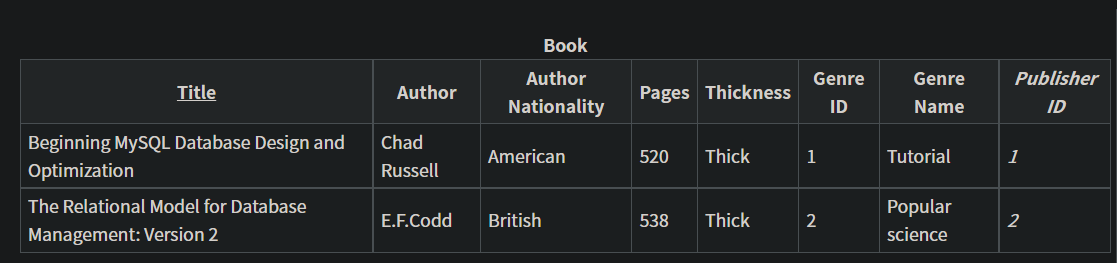
原因:Title->Genre ID->Genre name; Title->Author->AuthorNationality
Boyce-Codd Normal Form (BCNF):
A relational schema R is in Boyce-Codd normal form if and only if for every one of its dependencies X->Y, at least one of the following conditions hold:
- X->Y is a trivial functional dependency
- X is a superkey for schema R
Trivial dependency: X->Y when y is a subset of X. 用于消除不同的candidate key中的属性互相依赖的情况。
如下表格不符合BCNF:
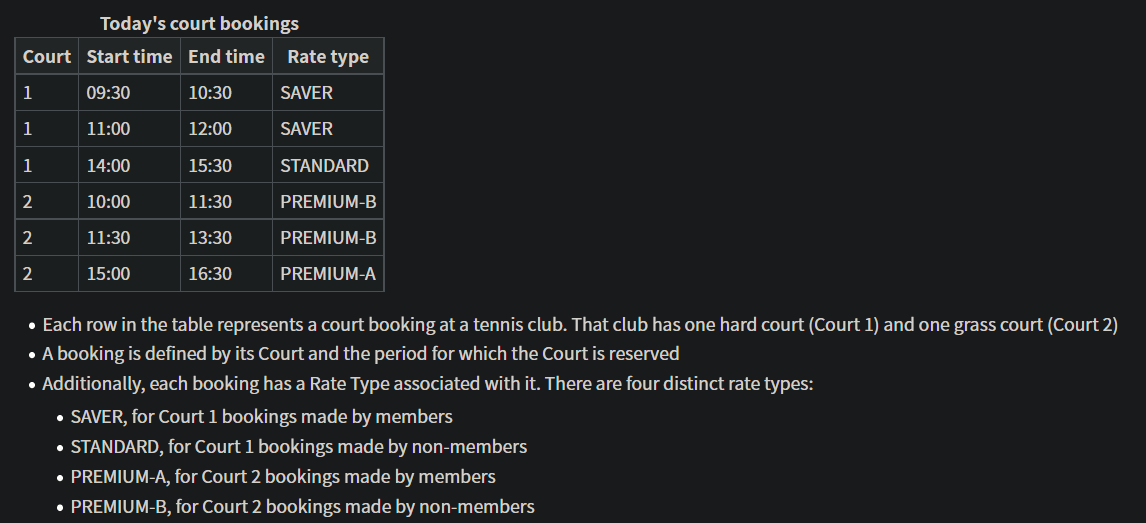
其中4个属性都属于某个candidate key;court 1的rate type为SAVER和STANDARD,court 2的rate type为PREMIUM-A和PREMIUM-B。
易知Rate type -> Court。
4NF:
Multivalued dependencies: If the column headings in a relational database table are divided into three disjoint groupings X, Y, and Z, then, in the context of a particular row, we can refer to the data beneath each group of headings as x, y, and z respectively. A multivalued dependency X->->Y signifies that if we choose any x actually occurring in the table (call this choice xc), and compile a list of all the xc,y,z combinations that occur in the table, we will find that xc is associated with the same y entries regardless of z
A table is in 4NF if and only if, for every one of its non-trivial multivalued dependencies X->->Y, X is a superkey.
用于消除对于有着X, Y, Z三组属性的关系R中,对于某个X,对任意Y都有相同Z的取值的情况。
如下表格不符合4NF:
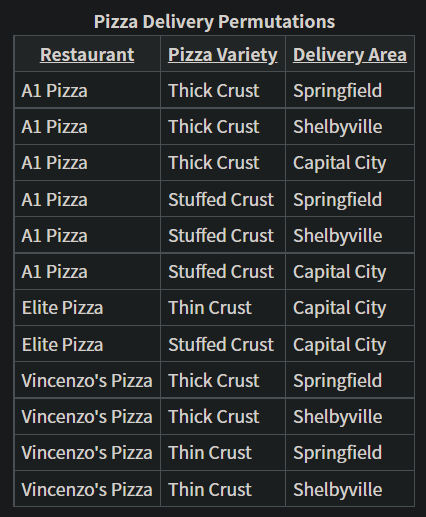
原因:对于同一家餐厅而言,它的每个菜品配送范围都是一样的
Mapping a conceptual ER Model to a Relational Model
Mapping entity types
Mapping relationship types
- binary 1:1 relationship type
- binary 1:n relationship type
- binary n:m relationship type
- unary and n-ary relationship type
基本SQL语句
基本语法:
SELECT ... FROM ... WHERE ...
别名:SELECT column_name AS column_alias FROM table_name table_alias;
SELECT id AS FROM demo d;
Aggregation Query: COUNT, MAX, MIN
COUNT后可加DISTINCT
GROUP BY:按某一列分组;每一组只返回一个结果。常用于聚合查询;当用于普通查询时,作用类似于DISTINCT。
HAVING: added to SQL because the WHERE keyword cannot be used with aggregate functions. 常与GROUP BY连用。
IN/ALL/ANY:用于嵌套查询
两种嵌套方式:
- WHERE后
- FROM后+别名
增加约束示例:
ALTER TABLE property
ADD CONSTRAINT property_pro_c_id_fkey FOREIGN KEY (pro_c_id) REFERENCES client(c_id) ON DELETE CASCADE;
删除约束示例:
ALTER TABLE property DROP CONSTRAINT property_pro_c_id_fkey;
插入一行:
INSERT INTO table_name VALUES (...)
更新表中数据:
UPDATE table_name SET column_name=expression WHERE ...
删除表中数据:
DELETE FROM table_name WHERE ...
Extended Relational Databases
Triggers:
CREATE TRIGGER SALARYTOTAL AFTER INSERT ON EMPLOYEE
FOR EACH ROW
WHEN (NEW.DNR IS NOT NULL)
UPDATE DEPARTMENT
SET TOTAL-SALARY = TOTAL-SALARY + NEW.SALARY
WHERE DNR = NEW.DNR
CREATE TRIGGER WAGEDEFAULT BEFORE INSERT ON EMPLOYEE
REFERENCING NEW AS NEWROW
FOR EACH ROW
SET (SALARY, BONUS) = (SELECT BASE_SALARY, BASE_BONUS FROM WAGE WHERE JOBCODE = NEWROW.JOBCODE)
Stored procedures
CREATE PROCEDURE REMOVE-EMPLOYEES (DNR-VAR IN CHAR(4), JOBCODE-VAR IN CHAR(6)) AS
BEGIN
DELETE FROM EMPLOYEE
WHERE DNR = DNR-VAR AND JOBCODE = JOBCODE-VAR;
END
递归查询
Physical File Organization and Indexing
rba: random block access
sba: sequential block access
Record organization
- relative location
- embedded identification
- pointers and lists: ideal for dealing with variable length records
Blocking factor: determines how many records are retrieved with a single read operation
- fixed length records: \(BF=\lfloor BS/RS \rfloor\),where BS stands for block space, RS stands for record space
- variable length records: average number of records in a block
Primary file organization versus secondary file organization
Primary file organization
- heap
- sequential
- random
- indexed sequential file organization
- primary index file organization: sparse, one for each block
- clustered index file organization: 在相同策略下,由于数据的不同,既有可能是密集索引(每个值都有大量重复),也有可能是稀疏索引(每个值都只出现一次)
- multilevel indexes
- list
Secondary indexes
- sequential index: unique
- non-unique
- dense index
- inverted file
- hash index
- bitmap index: types with limited set of values
- join index: combines types from 2 or more tables
Multilevel indexes -> B tree & B+ tree
Physical Database Organization
Database access methods
- functioning of query optimizer
- query cardinality = table cardinality * product(filter factors)
- index search with atomic search key
- multiple index and multicolumn index search
- to cater for all possible search keys, \(\binom n{\lceil n/2\rceil}\) indexes are required.
- index only access
- full table scan
Create indexes:
CREATE INDEX index_name
ON table_name (column1_name, column2_name);
Transaction Management
ACID properties:
- atomicity: multiple database operations that alter the database state can be treated as one indivisible unit of work; success or fail as a whole
- consistency: a transaction, if executed in isolation, renders the database from one consistent state into another consistent state; do not violate constraints
- isolation: in situations where multiple transactions are executed concurrently, the outcome should be the same as if every transaction were executed in isolation
- durability: effects of a committed transaction should always be persisted into the database
Serializable schedules: precedence graph
- 创建有向边Ti -> Tj ,如果Tj在由Ti写入后读取值
- 创建有向边Ti -> Tj ,如果Tj在被Ti读取后写入值
- 创建有向边Ti -> Tj ,如果Tj在由Ti写入后写入值
若此有向图中不存在环,则可以序列化
Lock
- shared
- exclusive
Two-phase Locking Protocol
- growth phrase
- shrink phrase
Cascading rollback: best way to avoid this, is for all transactions to hold their locks until they have reached the ‘committed’ state.
Deadlock: detected by wait-for graph
Isolation levels:
- read uncommitted: typically only allow for read-only transactions
- read committed: uses short-term read locks
- repeatable read: uses both long-term read locks and write locks
- serializable: avoid phantom reads
这里需要强调可重复读与可序列化的区别。可重复读不允许并发修改已有内容,但允许加入新内容,因此对原有内容修改时可能会发现新的未被修改的内容出现;可序列化则通过更严格的限制避免这种情况。
Lock granularity
错题
Physical/logical data independence指当前层的改变不影响上层

 浙公网安备 33010602011771号
浙公网安备 33010602011771号