java数据结构
Java集合框架==数据结构的封装:
- 数组(Array)
- 栈(Stack)
- 链表(Linked List)
- 哈希表(Hash)
- 队列(Queue)
- 堆(Heap)
- 图(Graoh)
- 树(Tree)
队列:是一种特殊线性表,只允许再表的前端进行删除作者,在表后端进行插入操作。队头删除,队尾插入。
单向队列(Queue):先进先出,队头删除,队尾插入。
双向队列(Deque):两条反向队列。
(最擅长操作头和尾)
栈(stack):堆栈,先进先出。(压栈,弹栈)
栈底索引为0;
哈希表:散列表,在一般的数组中,元素在数组中的索引位置是随机的,元素的取值和元素的位置之间不存在确定的关系,因此在数组中查找特定的值时,需要把查找值和一系列的元素进行比较。
此时查询效率依赖于查找过程中所进行的比较次数。
如果元素的值(value)和在数组中的索引位置(index)有一个确定的对应关系(hash)
Hash算法:
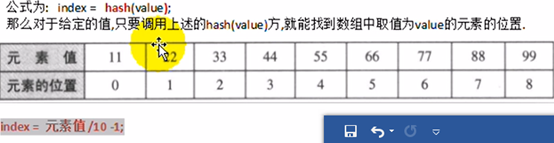
如果数组中元素的值和索引位置存在对应的关系,这样的数组称之为哈希表,最大的优点时提供查找数据的效率。
一般情况下,我们不会把哈希码(hashCode)作为元素在数组中的索引位置的,因为哈希码很大,数组长度有限会造成索引越界问题。
元素值—hash(value)-à哈希码---某一种映射关系--à元素存储索引
注意:每个哈希码是不同的
哈希表的插入查询是很效率的。
可是当哈希表接近装满时,因为数组的扩容性问题,性能较低(转移到更大的哈希表中)。
数组是会记录添加顺序,按照索引位置来存储,允许元素重复。
哈希表中:元素是不能重复的,对象如果相同则hashCode相同àindex相同,不会添加记录元素的先后顺序。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号