Linux中hadoop 单机_伪分布_安装与配置
步骤一:创建 hadoop 用户,并为 hadoop 用户授权
(1) 在一个新的Linux系统CentOS-7-x86_64-DVD-1708.iso中,开始用户是root不是hadoop用户是,那么需要增加一名为Hadoop的用户。执行下面命令查看hadoop用户是否存在。
$cat /etc/passwd |grep hadoop
(2) 如果 hadoop 用户不存在则创建 hadoop 用户,则继续执行(3),如果 hadoop 用户存在则执行步骤(4)。
(3) 创建用户 hadoop。(若系统没有sudo此命令,则 yum install net-tools 安装)
$sudo useradd -m hadoop -s /bin/bash
(4)设置密码为 hadoop(密码不回显)
$sudo passwd hadoop
(5)为 hadoop 用户授予 sudo 权限。(为hadoop用户授权会出现错误:hadoop is not in the sudoers file. This incident will be reported. :解决方法点击此链接:https://blog.csdn.net/haijiege/article/details/79630187 )
1.切换到root用户下,怎么切换就不用说了吧,不会的自己百度去.
2.添加sudo文件的写权限,命令是:chmod u+w /etc/sudoers
3.编辑sudoers文件vi /etc/sudoers找到这行 root ALL=(ALL) ALL,在他下面添加xxx ALL=(ALL) ALL (这里的xxx是你的用户名)ps:这里说下你可以sudoers添加下面四行中任意一条
youuser ALL=(ALL) ALL
%youuser ALL=(ALL) ALL
youuser ALL=(ALL) NOPASSWD: ALL
%youuser ALL=(ALL) NOPASSWD: ALL
第一行:允许用户youuser执行sudo命令(需要输入密码).第二行:允许用户组youuser里面的用户执行sudo命令(需要输入密码).
第三行:允许用户youuser执行sudo命令,并且在执行的时候不输入密码.第四行:允许用户组youuser里面的用户执行sudo命令,
并且在执行的时候不输入密码.4.撤销sudoers文件写权限,命令:chmod u-w /etc/sudoers这样普通用户就可以使用sudo了.
————————————————
版权声明:本文为CSDN博主「haijiege」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/haijiege/article/details/79630187
$sudo adduser hadoop sudo
(6)重启计算机,以 hadoop 用户登录。
$reboot
步骤二:修改集群节点名称,添加域名映射。
(1)将节点名称写入/etc/hostname 文件中。
$sudo vi /etc/hostname
(2)将节点的 IP 地址与主机名写入/etc/hosts 中,完成域名映射的添加。
$sudo vi /etc/hosts
例如: 172.17.67.10 master
如图配置完成:

(3)重新启动计算机。
$reboot
步骤三:SSH 登录权限设置
(1)在节点上安装 SSH。
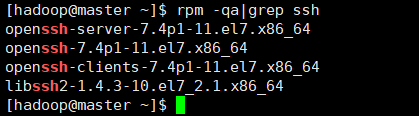
查看ssh的安装包 :rpm -qa | grep ssh
查看ssh是否安装成功 :ps -ef | grep ssh
下图安装好的:

未安装则输入命令:
$sudo yum install openssh-server
(2)在节点上生成公钥和私钥。
$ssh-keygen –t rsa (命令输入后等待自动完成)
在~/目录下自动创建目录.ssh,内部创建 id_rsa(私钥)、id_rsa.pub(公钥)、 authorized_keys 文件。
(3)将节点的公钥发送到 .ssh/authorized_keys 文件中。
$cd ~/.ssh
$ssh-copy-id -i id_rsa.pub hadoop@***
注意:分别用集群中各个节点名称(包括自身)替换***。
(4)测试 SSH 免密码登录。(暂时还需输入密码登录)
$ssh localhost
chmod 600 ~/.ssh/authorized_keys

测试成功后,可以执行 exit 命令结束远程登录。
步骤四:安装 Java 环境
(1)在目录/usr/lib 中创建 jvm 目录,并将目录所有者修改为 hadoop 用户。
$sudo mkdir /usr/lib/jvm/
$sudo chown –R hadoop:hadoop /usr/lib/jvm
(2)使用tar命令解压安装jdk-8u121-linux-x64.tar.gz文件到目录/usr/lib/jvm。
$cd ~/ (进入jdk安装包目录进行解压)
$sudo tar -zxvf jdk-8u121-linux-x64.tar.gz -C /usr/lib/jvm/
(3)配置 JDK 环境变量,使其生效。
①使用 vi 命令打开用户的配置文件.bashrc。
$sudo vi ~/.bashrc
②在文件中加入下列内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_121
export JRE_HOME=$JAVA_HOME/jre
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export CLASSPATH=$CLASSPATH:.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
③使环境变量生效,并验证 JDK 是否安装成功。
$ source ~/.bashrc #生效环境变量
$ java –version #如果打印出 java 版本信息,则成功

步骤五:伪分布式集群安装配置
(1)使用 tar 命令解压安装 hadoop-2.7.3.tar.gz 文件到目录/usr/local,并重命 名为 hadoop。
$cd ~/ #进入 hadoop-2.7.3.tar.gz 文件所在目录
$sudo tar -zxvf hadoop-2.7.3.tar.gz -C /usr/local
$cd /usr/local #进入/usr/local 查看解压结果
$ls #解压后目录名为 hadoop-2.7.3
$sudo mv ./hadoop-2.7.3 ./hadoop #为简化操作,文件夹重命名为 hadoop
(2)将目录/usr/local/hadoop 的所有者修改为 hadoop 用户。
$ sudo chown -R hadoop:hadoop /usr/local/hadoop
(3)修改环境变量,并使其生效。
①修改环境变量
$sudo vi ~/.bashrc #打开用户配置文件 在用户配置文件.bashrc 中写入下列 hadoop 配置信息。
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_HOME=/usr/local/hadoop
export YARN_CONF_DIR=${YARN_HOME}/etc/hadoop
② 生效环境变量 $source ~/.bashrc
(4)配置 Hadoop 文件 伪分布环境中,伪分布式需要修改下列 4 个配置文件。
$cd /usr/local/hadoop/etc/hadoop
$vi filename(文件)
①hadoop-env.sh 中配置 JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_121
②yarn-env.sh 中配置 JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_121
③修改 core-site.xml 文件。

④修改 hdfs-site.xml 文件。


(5)格式化 NameNode 节点。
$cd /usr/local/hadoop
$bin/hdfs namenode -format
注意:若格式化之后,重新修改了配置文件,那么需要重新格式化操作,在 此之前需要删除 tmp、dfs、logs 文件夹。
(8)启动 Hadoop 服务
$cd /usr/local/hadoop
$sbin/start-dfs.sh
$sbin/start-yarn.sh
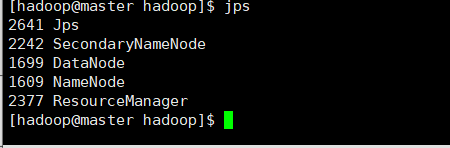
(9)验证是否安装成功。
① 执行 jps 命令查看服务
$sbin/start-all.sh 命令可用于启动整个hadoop服务
更详细转载:https://www.cnblogs.com/hopelee/p/7049819.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号