Go语言基础:语言格式|变量|常量|数据类型|占位符|转义符
Go语言格式
输出HelloWorld
package main
//导入包语句
import "fmt" //使用fmt系统包的申明,这个系统包包含了各种输出方法,对比Java
//程序的入口,对比C语言,存在一个且唯一的main函数
func main() {
fmt.Println("Hello World")
}
函数外面只能放置标识符的声明,比如变量声明、常量声明、函数声明等等
像fmt.println("sss") 直接放在函数外面,这种是错误的
此外,go代码串结束的时候不需要分号
使用命令行编译并执行go文件
使用 go build 文件名.go 可以生成二进制文件
使用 go run 文件名.go 可以直接执行main.go文件
使用 文件名.exe 执行二进制文件
当然也可以用go build直接编译全部的go文件
变量
标识符
Go的标识符和其他语言一样,由数字、字母、下划线组成,只能以下划线和字母开头,尽量采用驼峰式命名法,名称不能是关键字和保留字
关键字和保留字
//保留字
break default func interface select
case defer go map struct
chan else goto package switch
const fallthrough if range type
continue for import return var
//关键字
//常量
true false iota nil
// 数据类型
int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64 uintptr
float32 float64 complex128 complex64
bool byte rune string error
// 内置函数
make len cap new append copy close delete
complex real imag panic recover
变量声明
- 格式1:
var 变量名称 数据类型
//格式1
var name string
var age int
var sex string
- 格式2:
var ( 变量名称 数据类型 \n 变量名称 数据类型……)
// 格式2
var(
id int
isOk bool
)
- 格式3:
var 变量名称=变量值
//格式3
var name string = "aaa"
var age int = 22
- 格式4:
var 变量1,变量2=值1,值2
//格式4
var name, age = "aaa", 22
格式3 属于创建并初始化变量,系统会自动选配最适合变量传入值的数据类型
变量初始化的必要性
上面的格式3和格式4都是变量初始化的实例
在Go语言中,变量一旦定义就必须初始化,否则就会报错
短变脸声明
在函数内部,可以进行短变量声明,使用:=符号
例子:
package main
import (
"fmt"
)
// 全局变量m
var m = 100
func main() {
n := 10
m := 200 // 此处声明局部变量m
fmt.Println(m, n)
//生成结果: 200 10
}
匿名变量
在使用多重赋值时,如果想要忽略某个值,可以使用匿名变量(anonymous variable)。 匿名变量用一个下划线_表示
如下例子
package main
import "fmt"
func foo() (int, string) {
return 10, "aaa"
}
func main() {
x, _ := foo()
_, y := foo()
fmt.Println("x=", x)
fmt.Println("y=", y)
}
//结果:
//x= 10
//y= aaa
匿名变量不占用命名空间,不会分配内存,所以匿名变量之间不存在重复声明。
注意事项:
函数外的每个语句都必须以关键字开始(var、const、func等)
:=不能使用在函数外。
_多用于占位,表示忽略值。
常量
常量用const定义,一旦定义就必须赋值,开辟一个空间并写入一个不可变的数据
常量声明
直接定义并赋值:
const pi = 3.1415
const e = 2.7182
多重定义赋值
const (
pi = 3.1415
e = 2.7182
)
多重定义赋值之省略赋值:如果在多重定义赋值中某一个常量没有赋值,则它的值自动为向上寻找最近的已经被赋值的常量值
const (
n1 = 100
n2
n3
)
// 此时n1=n2=n3=100
关键字iota
iota是go语言的常量计数器,只能在常量的表达式中使用。
iota在const关键字出现时将被重置为0。
const中每新增一行常量声明将使iota计数一次(iota可理解为const语句块中的行索引)。
使用iota能简化定义,在定义枚举时很有用。
看下面的例子:
package main
import "fmt"
const (
a1 = iota
a2
a3
_ //使用_跳过某些值
_
a4
a5 = 100
a6
a7 = iota //iota声明中间插队
a8
// 0 1 2 5 100 100 8 9
)
'此时iota对每一行出现的常量进行了计数,并且遵从上面的多重定义赋值之省略赋值的原则'
// 定义数量级
//这里的<<表示左移操作,1<<10表示将1的二进制表示向左移10位,也就是由1变成了10000000000,也就是十进制的1024。
//同理2<<2表示将2的二进制表示向左移2位,也就是由10变成了1000,也就是十进制的8。
const (
_ = iota
KB = 1 << (10 * iota)
MB = 1 << (10 * iota)
GB = 1 << (10 * iota)
TB = 1 << (10 * iota)
PB = 1 << (10 * iota)
// 1024 1048576 1073741824 1099511627776 1125899906842624
)
'可以看到,iota遇到了const关键字就变成了0,重新计数'
// 多个iota定义在一行
const (
a, b = iota, iota //0,0
c, d = iota, iota // 1,1
e, f = iota + 1, iota + 2 //3,4
// 0 0 1 1 3 4
)
'由于此时多个常量定义在一行,而iota只对一行的常量能够自增'
func main() {
fmt.Println(a1, a2, a3, a4, a5, a6, a7, a8)
fmt.Println(KB, MB, GB, TB, PB)
fmt.Println(a, b, c, d, e, f)
}
0 1 2 5 100 100 8 9
1024 1048576 1073741824 1099511627776 1125899906842624
0 0 1 1 3 4
数据类型
Go语言中有丰富的数据类型,除了基本的整型、浮点型、布尔型、字符串外,还有数组、切片、结构体、函数、map、通道(channel)等。
整形 int族
整型分为以下两个大类: 按长度分为:int8、int16、int32、int64 对应的无符号整型:uint8、uint16、uint32、uint64
后面的数字式字节数,8代表8bit
其中,uint8就是我们熟知的byte型,int16对应C语言中的short型,int64对应C语言中的long型。
| 类型 | 符号 | 描述 |
|---|---|---|
| uint8 | 无符号 | 8位整型 (0 到 255) |
| uint16 | 无符号 | 16位整型 (0 到 65535) |
| uint32 | 无符号 | 32位整型 (0 到 4294967295) |
| uint64 | 无符号 | 64位整型 (0 到 18446744073709551615) |
| int8 | 有符号 | 8位整型 (-128 到 127) |
| int16 | 有符号 | 16位整型 (-32768 到 32767) |
| int32 | 有符号 | 32位整型 (-2147483648 到 2147483647) |
| int64 | 有符号 | 64位整型 (-9223372036854775808 到 9223372036854775807) |
package main
import "fmt"
func main() {
var a uint = 22
fmt.Println(a)
}
特殊整型
| 类型 | 描述 |
|---|---|
| uint | 32位操作系统上就是uint32,64位操作系统上就是uint64 |
| int | 32位操作系统上就是int32,64位操作系统上就是int64 |
| uintptr | 无符号整型,用于存放一个指针 |
在使用int和 uint类型时,不能假定它是32位或64位的整型,而是考虑int和uint可能在不同平台上的差异。所以在跨平台开发的时候需要考虑是否对方不是64位.
获取对象的长度的内建len()函数返回的长度可以根据不同平台的字节长度进行变化。实际使用中,切片或 map 的元素数量等都可以用int来表示。在涉及到二进制传输、读写文件的结构描述时,为了保持文件的结构不会受到不同编译目标平台字节长度的影响,不要使用int和 uint。
数字字面量语法(Number literals syntax)
Go1.13版本之后引入了数字字面量语法,这样便于开发者以二进制、八进制或十六进制浮点数的格式定义数字,例如:
v := 0b00101101, 代表二进制的 101101,相当于十进制的 45。v := 0o377,代表八进制的 377,相当于十进制的 255。v := 0x1p-2,代表十六进制的 1 除以 2²,也就是 0.25。- 而且还允许我们用 _ 来分隔数字,比如说:
v := 123_456表示 v 的值等于 123456。
我们可以借助fmt函数来将一个整数以不同进制形式展示。
package main
import "fmt"
//go语言中无法定义二进制数
func main() {
// 十进制
var a int = 10
fmt.Printf("%d \n", a) // 10 %d表示整数,%s表示的是字符串
fmt.Printf("%b \n", a) // 1010 占位符%b表示二进制
// 八进制 以0开头,因为八进制是三位二进制,就是作为32位系统的时候前八位位0
var b int = 077
fmt.Printf("%o \n", b) // 77
// 十六进制 以0x开头
var c int = 0xff
fmt.Printf("%x \n", c) // ff
fmt.Printf("%X \n", c) // FF
// var d int = 18
// fmt.Println("%x \n", d) //输出%x\n 18
// 查看变量类型
fmt.Printf("%T\n", a)
// var e int8 = 9
// fmt.Println("%T\n",e)
}
| 类型 | 解释 |
|---|---|
| %d | 十进制整数 |
| %f | 浮点数 |
| %o | 八进制 |
| %x | 十六进制 |
| %T | 类型 |
| %s | 字符串类型 |
浮点型和复数
Go语言支持两种浮点型数:float32和float64。
这两种浮点型数据格式遵循IEEE 754标准:
- float32 的浮点数的最大范围约为 3.4e38,可以使用常量定义:math.MaxFloat32。
- float64 的浮点数的最大范围约为 1.8e308,可以使用一个常量定义:math.MaxFloat64。
复数使用的是:complex64和complex128
打印浮点数时,可以使用fmt包配合动词%f
package main
import (
"fmt"
"math"
)
// complex64和complex128
// 复数
var c1 complex64 = 1 + 2i
var c2 complex128 = 2 + 3i
func main() {
fmt.Println(math.MaxFloat64)//打印最大浮点数
// 浮点数
fmt.Printf("%f\n", math.Pi)
fmt.Printf("%.2f\n", math.Pi)
// 复数
fmt.Println(c1)
fmt.Println(c2)
//1.7976931348623157e+308
//3.141593
//3.14
//(1+2i)
//(2+3i)
}
布尔值
Go语言中以bool类型进行声明布尔型数据,布尔型数据只有true(真)和false(假)两个值。
注意:
布尔类型变量的默认值为false。
Go 语言中不允许将整型强制转换为布尔型.
布尔型无法参与数值运算,也无法与其他类型进行转换。
字符串
Go语言中的字符串以原生数据类型出现,使用字符串就像使用其他原生数据类型(int、bool、float32、float64 等)一样。
Go 语言里的字符串的内部实现使用UTF-8编码。 字符串的值为双引号(")中的内容(字符才是单引号),可以在Go语言的源码中直接添加非ASCII码字符,例如:
s1 := "hello"
s2 := "你好"
字符串转义符
Go 语言的字符串常见转义符包含回车、换行、单双引号、制表符等,如下表所示。
| 转义符 | 含义 |
|---|---|
\r |
回车符(返回行首) |
\n |
换行符(直接跳到下一行的同列位置) |
\t |
制表符 |
\' |
单引号 |
\" |
双引号 |
\\ |
反斜杠 |
例如,打印输出:str := "c:\Code\lesson1\go.exe"
fmt.Println("str := \"c:\\Code\\lesson1\\go.exe\"")
多行字符串
Go语言中要定义一个多行字符串时,就必须使用反引号字符:
s1 := `第一行
第二行
第三行
`
字符串操作
| 方法 | 介绍 |
|---|---|
| len(str) | 求长度 |
| +或fmt.Sprintf | 拼接字符串 |
| strings.Split | 分割 |
| strings.contains | 判断是否包含 |
| strings.HasPrefix,strings.HasSuffix | 前缀/后缀判断 |
| strings.Index(),strings.LastIndex() | 子串出现的位置 |
| strings.Join(a[]string, sep string) | join操作 |
byte和rune类型
组成每个字符串的元素叫做“字符”,可以通过遍历或者单个获取字符串元素获得字符。 字符用单引号(’)包裹起来,如:
var a = '中'
var b = 'x'
Go 语言的字符有以下两种:
- uint8类型,或者叫 byte 型,代表了ASCII码的一个字符。
- rune类型,代表一个 UTF-8字符。
当需要处理中文、日文或者其他复合字符时,则需要用到rune类型。rune类型实际是一个int32。
Go 使用了特殊的 rune 类型来处理 Unicode,让基于 Unicode 的文本处理更为方便,也可以使用 byte 型进行默认字符串处理,性能和扩展性都有照顾。
// 遍历字符串
func traversalString() {
s := "hello沙河"
for i := 0; i < len(s); i++ { //byte
fmt.Printf("%v(%c) ", s[i], s[i])
}
fmt.Println()
for _, r := range s { //rune
fmt.Printf("%v(%c) ", r, r)
}
fmt.Println()
}
//104(h) 101(e) 108(l) 108(l) 111(o) 230(æ) 178(²) 153() 230(æ) 178(²) 179(³) 在byte型下有些字符不能正常显示
//104(h) 101(e) 108(l) 108(l) 111(o) 27801(沙) 27827(河)
因为UTF8编码下一个中文汉字由3~4个字节组成,所以我们不能简单的按照字节去遍历一个包含中文的字符串,否则就会出现上面输出中第一行的结果。
字符串底层是一个byte数组,所以可以和[]byte类型相互转换。字符串是不能修改的 字符串是由byte字节组成,所以字符串的长度是byte字节的长度。
rune类型用来表示utf8字符,一个rune字符由一个或多个byte组成。
修改字符串
要修改字符串,需要先将其转换成[]rune或[]byte,完成后再转换为string。无论哪种转换,都会重新分配内存,并复制字节数组。
在所有编程语言中字符串都是不可变序列,这种操作属实没有多大必要
package main
import "fmt"
func changeString() {
s1 := "big"
// 强制类型转换
byteS1 := []byte(s1) //先转为byte类型
byteS1[0] = 'p'// 修改
fmt.Println(string(byteS1)) //在转为string类型
s2 := "白萝卜"
runeS2 := []rune(s2) //先转为rune类型
runeS2[0] = '红' //修改
fmt.Println(string(runeS2)) //再转为rune类型
}
func main() {
changeString()
}
类型转换
数据类型转换方法和其他语言一样
Go语言中只有强制类型转换,没有隐式类型转换。该语法只能在两个类型之间支持相互转换的时候使用。
比如计算直角三角形的斜边长时使用math包的Sqrt()函数,该函数接收的是float64类型的参数,而变量a和b都是int类型的,这个时候就需要将a和b强制类型转换为float64类型。
package main
import "math"
import "fmt"
func main(){
a,b:=3,4
var c int
c=int(math.Sqrt(float64(a*a+b*b)))
fmt.Println(c)
}
%占位符
一般占位符
| 占位符 | 说明 | 举例 | 输出 |
|---|---|---|---|
| %v | 相应值的默认格式。 | Printf("%v", people) | |
| %+v | 打印结构体时,会添加字段名 | Printf("%+v", people) | |
| %#v | 数据类型加上结构体以及字段名 | Printf("#v", people) | main.Human |
| %T | 相应值的数据类型的Go语法表示 | Printf("%T", people) | main.Human |
| %% | 字面上的百分号,并非值的占位符 | Printf("%%") | % |
布尔占位符
| 占位符 | 说明 | 举例 | 输出 |
|---|---|---|---|
| %t | true或 false | Printf("%t", true) | true |
整数占位符
| 占位符 | 说明 | 举例 | 输出 |
|---|---|---|---|
| %b | 二进制表示 | Printf("%b", 5) | 101 |
| %c | 相应Unicode码点所表示的字符 | Printf("%c", 0x4E2D) | 中 |
| %d | 十进制表示 | Printf("%d", 0x12) | 18 |
| %o | 八进制表示 | Printf("%d", 10) | 12 |
| %q | 单引号围绕的字符字面值,由Go语法安全地转义 | Printf("%q", 0x4E2D) | '中' |
| %x | 十六进制表示,字母形式为小写 a-f | Printf("%x", 13) | d |
| %X | 十六进制表示,字母形式为大写 A-F | Printf("%x", 13) | D |
| %U | Unicode格式:U+1234,等同于 "U+%04X" | Printf("%U", 0x4E2D) | U+4E2D |
浮点数和复数占位符
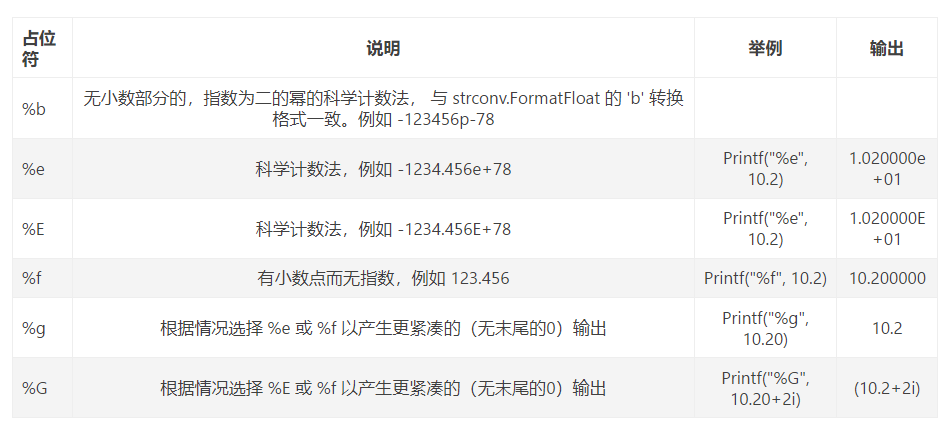
字符串
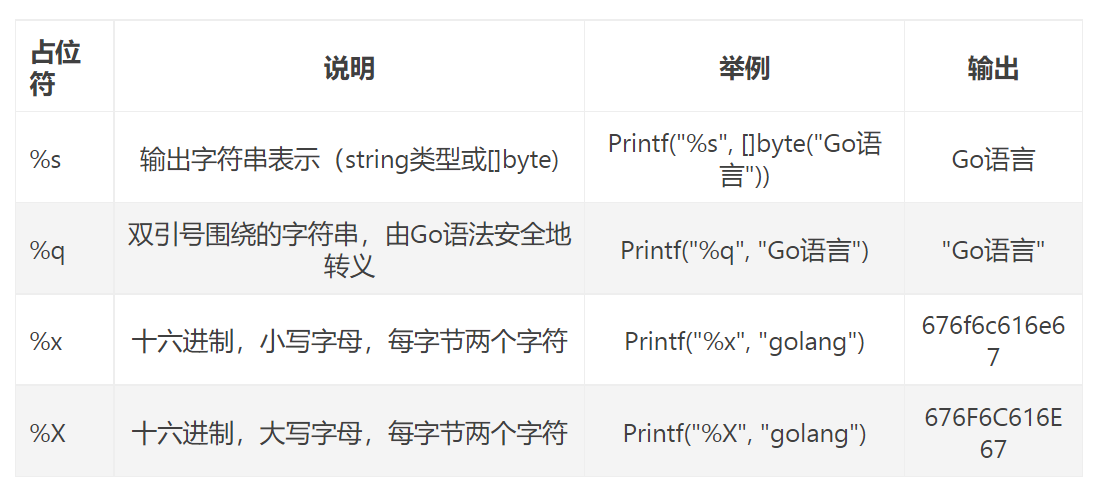
指针

其他

练习题:
编写代码分别定义一个整型、浮点型、布尔型、字符串型变量,使用fmt.Printf()搭配%T分别打印出上述变量的值和类型。
package main
import (
"fmt"
)
var(
aaa int
bbb float64
ccc bool
ddd string
)
func main() {
aaa,bbb,ccc,ddd=3,3.2,true,"aaa"
// 只有printf才能使用占位符
fmt.Printf("aaa=%T\nbbb=%T\nccc=%T\nddd=%T", aaa, bbb, ccc, ddd)
}
编写代码统计出字符串"hello沙河小王子"中汉字的数量。
package main
import "fmt"
//编写代码统计出字符串"hello沙河小王子"中汉字的数量。
func main(){
s:="hello沙河小王子"
count:=0
for _,r :=range s{
if int(r)<1000{
count+=1
}
}
fmt.Println(count)
}
本文来自博客园,作者:{Zeker62},转载请注明原文链接:https://www.cnblogs.com/Zeker62/p/15406966.html

