树上问题
- DFS 序和树上差分的方法非常重要
- 这些树上问题一般离线后会又好写又快,建议使用离线的方法
- 难点在于分析问题的具体性质,难以概括
- 若是查询树上路径信息,可以使用树上差分方法
- 任何范围修改查询问题,如果能差分的话想都不想就差分是不会有问题的,推荐直接这样做
- 典型的差分方法有:序列差分、树上差分、二维前缀和查分。
- 为什么这样做?通过差分我们可以将一个高维问题以常数代价转换为低维问题,而问题低一维往往简单很多,如线段树转树状数组差分。因此做题看到可以差分的区间,树路径等范围,想都不想直接差分掉
tarjan 求 lca
https://www.bilibili.com/video/BV1nE411L7rz/?spm_id_from=333.337.search-card.all.click
\(n\) 个点,\(m\) 次询问,离线做法。
时间复杂度 \(O(n \log n+ m)\)。tarjan 有一种 \(O(n+m)\) 的做法,不学了。实在过不去加个按秩合并就是了。
算法思想:考虑在 dfs 过程中解决询问。考虑 \(i\) 节点的两个不同子树上的节点,他们的 lca 为 \(i\)。我们要先把询问挂在节点上,然后在遍历的时候,依次遍历几个子树,并把先遍历的且已经遍历完的子树都标记到 \(i\) 节点(也就是在 \(i\) 节点的其他子树上对它的询问的答案均为 \(i\),这个过程用并查集方便维护)。
算法过程:
- 把所有询问挂在节点上。
- dfs 这一棵树。
- 当我们遍历到一个节点时,一个一个子树遍历,遍历完的子树使用并查集合并到该节点。
- 对于一对询问,解决它的一定是后遍历到的那个点。因为此时前遍历到的点已经被合并到了两个点分叉的地方,也就是 lca。
- 这样就可以计算出每一个询问的答案。
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define f(i, a, b) for(int i = a; i <= b; i++)
typedef long long ll;
typedef unsigned long long ull;
typedef long double ld;
typedef pair<int, int> pii;
#define fi first
#define se second
int n, m, s;
vector<pii> q[500010];
vector<int> g[500010];
int ans[500010];
int f[500010];
int vis[500010];
int get(int x) {
if(f[x] == x) return x;
return f[x] = get(f[x]);
}
void merge(int x, int y) {
x = get(x); y = get(y);
f[x] = y;
}
void dfs(int now, int fa) {
vis[now] = 1;
for(int i : g[now]) {
if(i == fa) continue;
dfs(i, now);
for(pii j : q[i]) {
int x = j.first;
if(vis[x]) ans[j.second] = get(x);
}
merge(i, now);
}
}
signed main() {
ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
cin >> n >> m >> s;
f(i, 1, n) f[i] = i;
f(i, 1, n - 1) {
int x, y; cin >> x >> y;
g[x].push_back(y); g[y].push_back(x);
}
f(i, 1, m){
int u, v; cin >> u >> v;
q[u].push_back({v, i});
q[v].push_back({u, i});
}
dfs(s, 0);
f(i, 1, m) cout << ans[i] << endl;
return 0;
}
给定 \(n\) 个点的树,\(m\) 次查询,每次查询 \(x\) 到 \(y\) 路径点权和
考虑转化为“点到根的链上的点权和(第一个常见降维转化),这个可以 \(O(n)\) 预处理。
怎么转化?\(dis_x + dis_y - dis_{lca} - dis_{fa_{lca}}\) 即可。
离线之后用 tarjan lca,可以做到 \(O(n + m)\)。
欧拉序
给一个 \(n\) 个点的树,有 \(m\) 次查询,每次给两个点 \(x,y\),求 \(x\) 是否为 \(y\) 的祖先。
可以用 lca 直接判断,但是我们有线性做法,而这个做法的思想需要学习。
考虑欧拉序,也就是当我们进入和退出一个节点的时候在欧拉序中加入这个数,一棵子树就变成了一个序列。
例如:
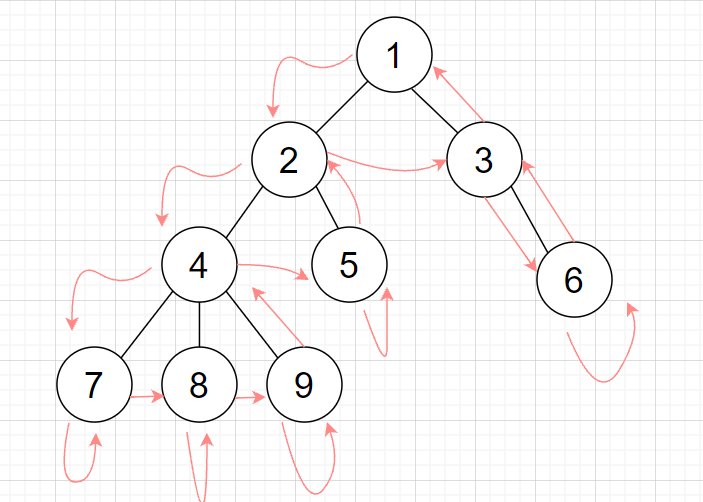
上图的欧拉序为 \(1,2,\color{blue}{4,7,7,8,8,9,9,4},5,5,2,3,6,6,3,1\)。
那么以 \(4\) 为根的子树即为上面蓝色的一段。
考虑 \(x\) 的两个位置是否包含 \(y\) 的即可。
求子树和
考虑 \(n\) 个字符串和 \(m\) 次询问,每次给定两个字符串\(s1,s2\),问有多少字符串既有 \(s1\) 前缀又有 \(s2\) 后缀。
考虑正反建两棵 trie,问题就变成了求特定两个节点的子树和。(有 \(s_1\) 前缀,也就是在 trie 上表示 \(s_1\) 的节点的子树里面)考虑欧拉序转换成序列,那么就变成了数正方形内出现两次的叶子有多少个。考虑只添加叶子的话可以两个点缩成一个点,因此可以树状数组二维数点。
求 LCA
这里介绍一种不一样的欧拉序:每一次经过一个点的时候就记录一次欧拉序。
类似这样:
void dfs(int now) {
euler[++cnt] = now;
for(int i : son[now]) {
dfs(i);
euler[++cnt]=now;
}
}
这样,我们会发现 LCA 就相当于欧拉序上的 RMQ。可以用 ST 表维护,每次查询 \(\min(first(x), first(y))\),其中 \(first(x)\) 是 \(x\) 第一次出现的时刻。
子树上问题
例题:CF1778E
题目:给定一棵树,\(q\) 次询问每次定根,查询子树线性基。
\(n,q \le 2\times 10^5\)。
首先线性基的合并是 \(A\times A\) 的,\(A = \log v\)。其实就是插入新的 \(A\) 个数罢了。没有逆操作。
子树问题,如果不是用到上面那种欧拉序(用到的话也不太适合做复杂的数据结构),那么都可以用 \(dfn\) 简洁地处理。回溯时可以不要在序中继续加入一次,而是直接记录其子树 \(dfn\) 最大值(我们记为 \(dgn\) 数组)。
那么换根也不怕。假设一开始的根后来被变成子树了,而换的根原来是子孙。那么我们需要先找出这个子孙属于哪一个儿子的子树。这怎么处理比较好写?
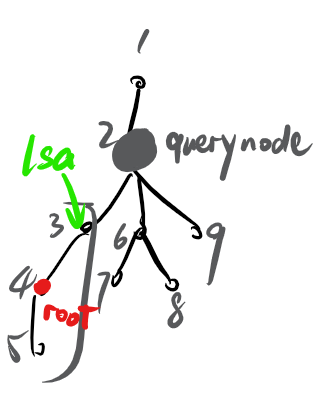
先求 \(query\) 和 \(root\) 的 lca,如果不等于 \(query\),直接在原树上找到就好了。否则,考虑 lsa(哪一个儿子包含了 \(root\))。这个直接用 \(dep_{root} - dep_{query} - 1\) 倍增即可。
那么查询范围为 \([1, dfn_q] \cup [dgn_{lsa} + 1, dgn_q] \cup [dgn_q + 1, +\inf]\)。注意子树外面的东西是两个区间而不是一个。可以合并为 \([1, dfn_q] \cup [dgn_{lsa} + 1, +\inf]\) 这两个范围。
维护 dfn 上线段树即可。
(注意我们有两种可以用的序列,一种是上面的欧拉序,一种是 dfn。)
CF1796E
【题意】
给定一棵 \(n\) 点树,可以选定一个根,然后在上面选出一些深度不相同的点组成的链,这种方案的权值为这里面最短链的长度。求所有方案中,最大权值。
\(n \le 2 \times 10^5\)
【分析】
首先,这个剖分方式是“短链剖分”,而且是只能剖成不拐弯的链。但是我们二分答案可以有更好的判定。先考虑定下根了的情况。这种情况下,令 \(dp_i\) 表示该节点还需要往上加上多少个点才能达到长度要求。显然 \(dp_i = \max \limits_{j \in son_i} dp_j - 1\)。并且如果有两个节点的 \(dp\) 值都 \(>0\),这个根一定不可行。
考虑这种情况下可能可行的根其实是有限的。如果这个有两个不好的子节点的点不是根,那么只有这两个不好子节点末端可能是根,其他情况下这个点依然存在两个不好的子节点或者不优(很好证明,但是证明的时候可以发现是根的情况会有所不同)。如果是根也好办,当没有其他节点满足存在两个不好子节点的时候,从一个不好子节点出发,一定能将两个节点“展平”,而这是能做到的最好效果(体会一下,如果有其他不好的,选其他的可能修复该节点和根;如果没有,最多是修复根)。
另外一种情况是 \(dp_1 > 0\)。这时候只有使用 \(1\) 的最短链(肯定是它导致的)做根是最好的选择。
注意特殊情况判断。
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define f(i, a, b) for(int i = (a); i <= (b); i++)
#define cl(i, n) i.clear(),i.resize(n);
#define endl '\n'
typedef long long ll;
typedef unsigned long long ull;
typedef pair<int, int> pii;
const int inf = 1e9;
//#define cerr if(false)cerr
//#define freopen if(false)freopen
#define watch(x) cerr << (#x) << ' '<<'i'<<'s'<<' ' << x << endl
void pofe(int number, int bitnum) {
string s; f(i, 0, bitnum) {s += char(number & 1) + '0'; number >>= 1; }
reverse(s.begin(), s.end()); cerr << s << endl;
return;
}
void cmax(int &x, int y) {if(x < y) x = y;}
void cmin(int &x, int y) {if(x > y) x = y;}
//调不出来给我对拍!
int mnl[200100];vector<int> t[200100]; int top[200100];
bool ok=0; int wt=0,ft=0;int n;
void dfs(int now,int fa,int tar) {
int tmp=-inf; int num=0;
for(int i : t[now]){
if(i==fa)continue;
dfs(i,now,tar);
if(mnl[i]>0){
num++;
if(num>=2&&!ok){
wt=now;ft=top[i];
}
}
if(mnl[i]-1>tmp)top[now]=top[i];
cmax(tmp,max(0ll, mnl[i]-1));
}
if(tmp==-inf)tmp=tar-1,top[now]=now;
mnl[now]=tmp;
if(num>=2){
ok=1;
}
}
bool ck(int mid){
dfs(1,0,mid);
if(!ok&&mnl[1] <= 0){
return 1;
}
else {
if(mnl[1]>0)wt=1;
int fft=ft;
ok=0;
int dft=top[wt];
dfs(dft,0,mid);
if(!ok&&mnl[dft] <= 0)return 1;
else {
if(fft>n)return 0;
ok=0;
dfs(fft,0,mid);
if(!ok&&mnl[fft]<=0)return 1;
else return 0;
}
}
}
signed main() {
ios::sync_with_stdio(0);
cin.tie(NULL);
cout.tie(NULL);
//freopen();
//freopen();
//time_t start = clock();
//think twice,code once.
//think once,debug forever.
int T; cin >> T;
while(T--) {
cin>>n;f(i,1,n)t[i].clear();
f(i,1,n-1){int u,v;cin>>u>>v;t[u].push_back(v);t[v].push_back(u);}
int l=1,r=n;while(l<r){
int mid=(l+r+1)>>1;
ok=0;
if(ck(mid)) l=mid;
else r=mid-1;
}
cout<<l<<endl;
}
//time_t finish = clock();
//cout << "time used:" << (finish-start) * 1.0 / CLOCKS_PER_SEC <<"s"<< endl;
return 0;
}
/*
2023/x/xx
start thinking at h:mm
start coding at h:mm
finish debugging at h:mm
*/
树上背包
这样的一个过程:
int cnt = 1;
for(int i : son[now])
for(int j = 0; j <= cnt; j++)
for(int k = 0; k <= size[i]; k++) {
dp[now][j + k] += dp[now][j] * dp[i][k]
}
好像对于一个根节点,一个一个地把子树收纳进自己的“背包”里面的过程叫树上背包。其时间复杂度为 \(\mathbf{O(n^2)}\)。因为可以看做这样的子树合并过程:
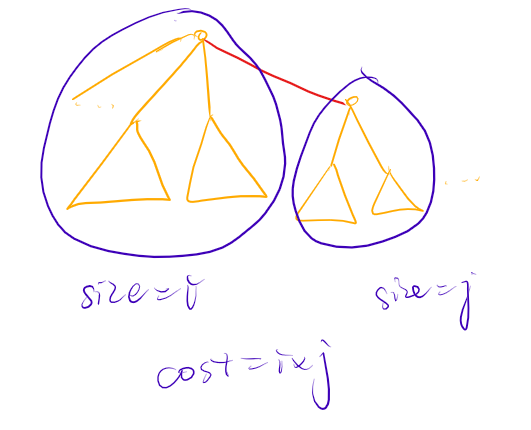
其中每一次合并的过程中产生 \(i \times j\) 的贡献。可以看成是,每一对点合并产生 \(1\) 的贡献。因此时间复杂度 \(O(n^2)\)。
这种证明过程对决策单调性 dp,树上背包和启发式合并都很相似,是计算分别的“贡献”得到一个更紧的上界。
树链剖分
将树进行轻重链剖分,把树剖成 dfs 序上 \(\log\) 段。
启发式合并、线段树合并
对于树上路径问题,考虑在某一个路径的 lca 位置将其处理。如果对于 lca,处理所有路径的时候所用到的信息量大小和子树 size 有关,那么可以使用启发式合并做到 \(O(n \log n \times T(merge))\),具体是这样做的:
(维持原数组版本)
考虑现在 dfs 到的 lca。其每一个子树都有一个大小为其 size 的 set。考虑将最大的那个复制到根节点,时间复杂度 \(O(1)\)。考虑将其他的 set 暴力插入,时间复杂度每个元素 \(O(\log)\)。同时,类似树形背包一样,对目前正在合并的子树和代表之前所有子树信息的这个 set 进行处理,算贡献。这个时间复杂度也和 size 相关。(对两个数组做处理的复杂度,看着办,但是如果 \(O(n^2)\) 那是不可以的)
这样总时间复杂度是 \(O(n \log n \times T(merge))\) 的,因为我们省去了重子树的合并,所以每一次合并操作所得到的数组 size 一定大于自己的两倍,得证。
如果维护的是一个 \(\log\) 数据结构比如树状数组,那么总共将会是两个 \(\log\) 的。这时候不妨使用线段树合并。
线段树合并的过程之前讲过,其合并操作总时间复杂度对于整棵树是 \(O(n \log n)\) 的。是因为我们记录的信息可以打包带走。
点分治
对于无根树信息(路径等)我们可以进行点分治维护。
重心的定义:这个点的最大子树大小不超过一半。带权的时候这个定义可能与其他定义不兼容,但是这个定义找到的重心是满足点分治中心性质的。也就是层数不超过 \(O(\log n)\)。对每一层重心连边重新建树,得到的是点分树,其性质是每两个点的 lca 在原图上都在这两个点的简单路径上。
插播一句魔改点分树,如果重心的定义是树中点的标号最大的一个,可以从小到大枚举点,对于某一个点向标号比自己低的点加边,当前时刻得到的森林中它在的那个连通块就是它的点分子树,这个子树的性质在 JOI2023D 中有讨论。
对于路径信息,我们可以像前面的思想一样,利用到会穿过路径的性质,进行贡献的维护。要注意的是,这样维护贡献的时候要在当前层就再对每个子树 dfs 一次(边界是 vis 数组中的 1)减去相同子树贡献(这点和上面不同,上面是利用树形背包的思想,但是这里已经保证了复杂度,再加上这个思想也还是一样)。
对于有根树信息例如子树大小,我们发现当前层有之多一个子树是连向原来的父亲,对这个子树单独处理,其他子树都是连向原来的儿子,可以类似处理。
边分治
某一条边是分治中心。找边,让两边的大小比较均匀。然后删掉这条边。找边可以暴力找,复杂度是对的。
作用是让分治之后只有两个联通子图,(可能)更好合并。但是如果图是菊花图,会造成时间复杂度变成 \(O(n^2)\)。这时候我们需要三度化,不改变任意两点之间距离的情况下将一棵树变成一棵二叉树。
具体方式是,先建图,然后 dfs 的时候加两个点,均匀地把连上的点分配给这两个点上。
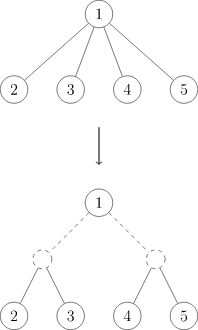
几乎所有点分治的题边分都能做。
P9133 大富翁
【题意】
给定一棵树和数组 \(w\),两方轮流选择点,每次选择点 \(i\) 之后需要向系统支付 \(w_i\) 元,向对手支付 (\(i\) 的祖先中被对手选过的点数 - \(i\) 的子树中被对手选过的点数) 元钱。两方的目标都是最大化自己得到的钱。求先手能够得到多少钱。
【分析】
考虑拆贡献。
首先观察到对于两个分别被两个人选的点,不管是谁选了,都会产生一样的贡献,所以和时间没有关系,只和场面有关系。
然后考虑某个场面下先手获得的分数:
\(\sum \limits_{x \in A} -x\) 祖先上对方选了的个数 \(+x\) 子树上对方选了的个数 \(-w_i\)
等于:
\(\sum \limits_{x \in A} -dep_x + x\) 祖先上自己选了的个数 \(+size_x -x\) 子树上自己选了的个数 \(-w_i\)
考虑两个自己选的点,在祖先上产生 \(-1\) 的贡献,在子孙上产生 \(1\) 的贡献,所以全部可以抵消掉。
于是变成了 \(\sum \limits_{x \in A} -dep_x + size_x - w_x\)。后手也是一样的。所以根据这个排序就好了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号