波士顿房价预测实验
1.题目描述:
描述:波士顿房价预测是一个经典的机器学习任务,类似于程序员世界的“Hello World”。和大家对房价的普遍认知相同,波士顿地区的房价受诸多因素影响。该数据集统计了13种可能影响房价的因素和该类型房屋的均价,期望构建一个基于13个因素进行房价预测的模型。
① 假设:因为房价是一个连续值,所以房价预测显然是一个回归任务,可用简单的线性回归模型解决,预测y和x关系表达式如
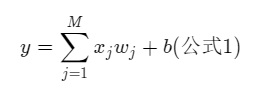
② 评价:线性回归模型使用均方误差作为损失函数(Loss),用以衡量预测房价和真实房价的差异,公式如下:
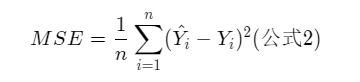
③ 影响因素:
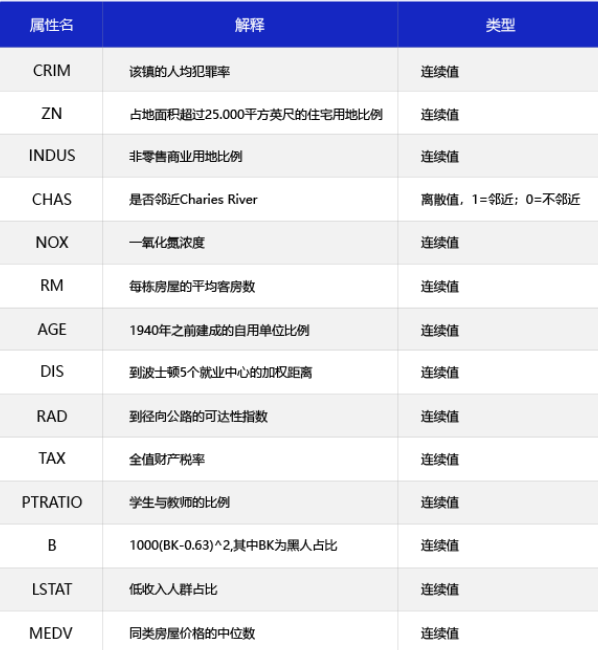
feature_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM',
'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
④梯度计算公式
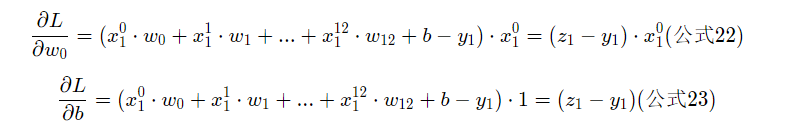
梯度变化:w=w-eta*grandient_w
⑤输出格式
Epoch 0 / iter 0, loss = 1.0281
不同场景的深度学习模型具备一定的通用性,五个步骤即可完成模型的构建和训练即数据处理、模型设计、训练配置、训练过程、模型保存。通过波士顿房价预测来举例描述以上步骤。
2.numpy库解决
import numpy as np
import matplotlib.pyplot as plt
# 数据处理
# 封装成load data函数
def load_data():
# 从文件导入数据
datafile = './work/housing.data'
data = np.fromfile(datafile, sep=' ')
# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \
'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
# 将原始数据进行Reshape,变成[N, 14]这样的形状
data = data.reshape([data.shape[0] // feature_num, feature_num])
# 将原数据集拆分成训练集和测试集
# 这里使用80%的数据做训练,20%的数据做测试
# 测试集和训练集必须是没有交集的
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
# 计算训练集的最大值,最小值
maximums, minimums = training_data.max(axis=0), training_data.min(axis=0)
# 对数据进行归一化处理
for i in range(feature_num):
data[:, i] = (data[:, i] - minimums[i]) / (maximums[i] - minimums[i])
# 训练集和测试集的划分比例
training_data = data[:offset]
test_data = data[offset:]
return training_data, test_data
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
cost = error * error
cost = np.mean(cost)
return cost
def gradient(self, x, y):
z = self.forward(x)
gradient_w = (z-y)*x
gradient_w = np.mean(gradient_w,axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = (z-y)
gradient_b = np.mean(gradient_b)
return gradient_w, gradient_b
def update(self, gradient_w, gradient_b, eta=0.01):
self.w = self.w - eta * gradient_w
self.b = self.b - eta * gradient_b
def train(self, training_data, num_epochs, batch_size=10, eta=0.01):
n = len(training_data)
losses = []
for epoch_id in range(num_epochs):
np.random.shuffle(training_data)
mini_batches = [training_data[k:k + batch_size] for k in range(0, n, batch_size)]
for iter_id, mini_batch in enumerate(mini_batches):
x = mini_batch[:, :-1]
y = mini_batch[:, -1:]
a = self.forward(x)
loss = self.loss(a, y)
gradient_w, gradient_b = self.gradient(x, y)
self.update(gradient_w, gradient_b, eta)
losses.append(loss)
print('Epoch {:3d} / iter {:3d}, loss = {:.4f}'.
format(epoch_id, iter_id, loss))
return losses
# 获取数据
train_data, test_data = load_data()
# 创建网络
net = Network(13)
# 启动训练
losses = net.train(train_data, num_epochs=50, batch_size=100, eta=0.1)
# 画出损失函数的变化趋势
plot_x = np.arange(len(losses))
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()
3.paddle框架实现
# 加载飞桨、NumPy和相关类库
import paddle
from paddle.nn import Linear
import paddle.nn.functional as F
import numpy as np
def load_data():
# 从文件导入数据
datafile = './work/housing.data'
data = np.fromfile(datafile, sep=' ', dtype='float32')
# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数
feature_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM',
'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
feature_num = len(feature_names)
# 将原始数据进行Reshape,变成[N, 14]这样的形状
data = data.reshape([data.shape[0] // feature_num, feature_num])
# 将原数据集拆分成训练集和测试集
# 这里使用80%的数据做训练,20%的数据做测试
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
# 计算训练集的最大值,最小值
maximums, minimums = training_data.max(axis=0), training_data.min(axis=0)
# 对数据进行归一化处理
for i in range(feature_num):
data[:, i] = (data[:, i] - minimums[i]) / (maximums[i] - minimums[i])
# 训练集和测试集的划分比例
training_data, test_data = data[:offset], data[offset:]
return training_data, test_data
class Regressor(paddle.nn.Layer):
# self代表类的实例自身
def __init__(self):
# 初始化父类中的一些参数
super(Regressor, self).__init__()
# 定义一曾全连接层,输入维度是13,输出维度是1
self.fc = Linear(in_features=13, out_features=1)
# 网络的前向计算
def forward(self, inputs):
z = self.fc(inputs)
return z
# 声明定义好的线性回归模型
model = Regressor()
# 开启模型训练模式
model.train()
# 加载数据
training_data, test_data = load_data()
# 定义优化算法,使用随机梯度下降SGD
# 学习率设置为0.01
opt = paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())
EPOCH_NUM = 10 # 设置外层循环次数
BATCH_SIZE = 10 # 设置batch大小
n = len(training_data)
# 定义外层循环
for epoch_id in range(EPOCH_NUM):
# 在每轮迭代开始之前,将训练数据的顺序随机的打乱
np.random.shuffle(training_data)
# 将训练数据进行拆分,每个batch包含10条数据
mini_batches = [training_data[k:k + BATCH_SIZE] for k in range(0, n, BATCH_SIZE)]
# 定义内层循环
for iter_id, mini_batch in enumerate(mini_batches):
x = np.array(mini_batch[:, :-1]).astype("float32") # 获得当前批次训练数据
y = np.array(mini_batch[:, -1:]).astype("float32") # 获得当前批次训练标签(真实房价)
# 将numpy数据转为飞桨动态图tensor的格式
house_features = paddle.to_tensor(x, dtype="float32")
prices = paddle.to_tensor(y, dtype="float32")
# 前向计算
predicts = model(house_features)
# 计算损失
loss = F.square_error_cost(predicts, label=prices)
avg_loss = paddle.mean(loss)
if iter_id % 20 == 0:
print("epoch: {}, iter: {}, loss is: {}".format(epoch_id, iter_id, avg_loss.numpy()))
# 反向传播,计算每层参数的梯度值
avg_loss.backward()
# 更新参数,根据设置好的学习率迭代一步
opt.step()
# 清空梯度变量,以备下一轮计算
opt.clear_grad()
# 保存模型参数,文件名为LR_model.pdparams
paddle.save(model.state_dict(), 'LR_model.pdparams')
print("模型保存成功,模型参数保存在LR_model.pdparams中")
4.疑问
1.归一化,为什么最大值,最小值在train——data产生,而不是data
2.w b 是随机生成的,是在找随机生成的wb中最合适的把
3. np.random.seed(0)固定且平缓了
4.self.b = 0.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号