275.算法设计工具―STL
1.概述
1.1定义
STL主要由container(容器)、algorithm(算法)和iterator(迭代器)三大部分构成,容器用于存放数据对象(元素),算法用于操作容器中的数据对象。
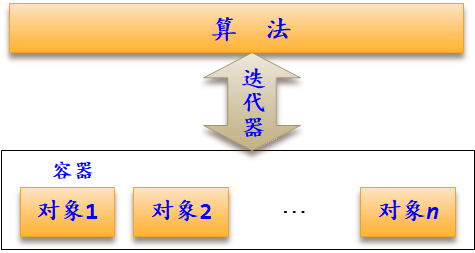
1.2stl容器
一个STL容器就是一种数据结构,如链表、栈和队列等,这些数据结构在STL中都已经实现好了,在算法设计中可以直接使用它们。


为此,使用STL时必须将下面的语句插入到源代码文件开头:
using namespace std;
这样直接把程序代码定位到std命名空间中。
1.3STL算法
STL算法是用来操作容器中数据的模板函数,STL提供了大约100个实现算法的模版函数。例如,STL用sort()来对一个vector中的数据(通用数据)进行排序,用find()来搜索一个list中的对象。
STL算法部分主要由头文件<algorithm>、<numeric>和<functional>组成。
例如,以下程序使用STL算法sort()实现整型数组a的递增排序:
#include <algorithm> using namespace std; void main() { int a[]={2,5,4,1,3}; sort(a,a+5); for (int i=0;i<5;i++) printf("%d ",a[i]); //输出: 1 2 3 4 5 printf("\n"); }
1.4stl迭代器
指针的另一个说法
STL迭代器用于访问容器中的数据对象。
每个容器都有自己的迭代器,只有容器自己才知道如何访问自己的元素。
迭代器像C/C++中的指针,算法通过迭代器来定位和操作容器中的元素。
(整型指针只能指整型,向量指向量)
常用的迭代器有:
iterator:指向容器中存放元素的迭代器,用于正向遍历容器中的元素。
const_iterator:指向容器中存放元素的常量迭代器,只能读取容器中的元素。
reverse_iterator:指向容器中存放元素的反向迭代器,用于反向遍历容器中的元素。
const_reverse_iterator:指向容器中存放元素的常量反向迭代器,只能读取容器中的元素。
迭代器的常用运算如下:
++:正向移动迭代器。
--:反向移动迭代器。
*:返回迭代器所指的元素值。
vector<int> myv; //即将定义一个整型变量 myv.push_back(1); //push_back尾部插入 myv.push_back(2); myv.push_back(3); //向量的定义和变量的插入 vector<int>::iterator it; //定义正向迭代器it for (it=myv.begin();it!=myv.end();++it) //从头到尾遍历所有元素 myv.end()最后一个元素的后面 printf("%d ",*it); //输出:1 2 3 printf("\n"); vector<int>::reverse_iterator rit; //定义反向迭代器rit for (rit=myv.rbegin();rit!=myv.rend();++rit) //从尾到头遍历所有元素 myv.rend()第一个元素的前面 printf("%d ",*rit); //输出:3 2 1 printf("\n");
2.常用的STL容器
顺序容器
适配器容器
关联容器
2.1顺序容器
2.1.1 vector(向量容器)
1.定义
它是一个向量类模板。向量容器相当于数组。
用于存储具有相同数据类型的一组元素,可以从末尾快速的插入与删除元素,快速地随机访问元素,但是在序列中间插入、删除元素较慢,因为需要移动插入或删除处后面的所有元素。
定义vector容器的几种方式如下:
vector<int> v1; //定义元素为int的向量v1 相当于动态数组 vector<int> v2(10); //指定向量v2的初始大小为10个int元素 vector<double> v3(10,1.23); //指定v3的10个初始元素的初值为1.23 vector<int> v4(a,a+5); //用数组a[0..4]共5个元素初始化v4
2.成员函数
- vector提供了一系列的成员函数,vector主要的成员函数如下:
- empty():判断当前向量容器是否为空。
- size():返回当前向量容器的中的实际元素个数。
- []:返回指定下标的元素。
- reserve(n):为当前向量容器预分配n个元素的存储空间。
- capacity():返回当前向量容器在重新进行内存分配以前所能容纳的元素个数。
- resize(n) :调整当前向量容器的大小,使其能容纳n个元素。
- push_back():在当前向量容器尾部添加了一个元素。
- insert(pos,elem):在pos位置插入元素elem,即将元素elem插入到迭代器pos指定元素之前。
- front():获取当前向量容器的第一个元素。
- back():获取当前向量容器的最后一个元素。
- erase():删除当前向量容器中某个迭代器或者迭代器区间指定的元素。
- clear():删除当前向量容器中所有元素。
- 迭代器函数:
- begin():返回指向容器第一个元素的迭代器
- end():返回指向容器最后元素(后面)的迭代器
- rbegin():倒数
- rend():倒数
调用方法:变量点函数
#include <vector> using namespace std; void main() { vector<int> myv; //定义vector容器myv vector<int>::iterator it; //定义myv的正向迭代器it myv.push_back(1); //在myv末尾添加元素1 it=myv.begin(); //it迭代器指向开头元素1 myv.insert(it,2); //在it指向的元素之前插入元素2 myv.push_back(3); //在myv末尾添加元素3 myv.push_back(4); //在myv末尾添加元素4 it=myv.end(); //it迭代器指向尾元素4的后面 it--; //it迭代器指向尾元素4 myv.erase(it); //删除元素4 for (it=myv.begin();it!=myv.end();++it) printf("%d ",*it); printf("\n"); }
//结果213
2.1.2string(字符串容器)
1.定义
string是一个保存字符序列的容器,所有元素为字符类型,类似vector<char>。
除了有字符串的一些常用操作以外,还有包含了所有的序列容器的操作。字符串的常用操作包括增加、删除、修改、查找比较、连接、输入、输出等。
创建string容器的几种方式如下:
char cstr[]="China! Greate Wall"; //C-字符串 string s1(cstr); // s1:China! Greate Wall string s2(s1); // s2:China! Greate Wall string s3(cstr,7,11); // s3:Greate Wall string s4(cstr,6); // s4:China! string s5(5,'A'); // s5:AAAAA
2.常用的成员函数如下
- empty():判断当前字符串是否为空串。
- size():返回当前字符串的实际字符个数(返回结果为size_type类型)。
- length():返回当前字符串的实际字符个数。
- [idx]:返回当前字符串位于idx位置的字符,idx从0开始。
- at(idx):返回当前字符串位于idx位置的字符。
- compare(const string& str):返回当前字符串与字符串str的比较结果。在比较时,若两者相等,返回0;前者小于后者,返回-1;否则返回1。
- append(cstr):在当前字符串的末尾添加一个字符串str。
- insert(size_type idx,const string& str) :在当前字符串的idx处插入一个字符串str。
- empty():判断当前字符串是否为空串。
- size():返回当前字符串的实际字符个数(返回结果为size_type类型)。
- length():返回当前字符串的实际字符个数。
- [idx]:返回当前字符串位于idx位置的字符,idx从0开始。
- at(idx):返回当前字符串位于idx位置的字符。
- compare(const string& str):返回当前字符串与字符串str的比较结果。在比较时,若两者相等,返回0;前者小于后者,返回-1;否则返回1。
- append(cstr):在当前字符串的末尾添加一个字符串str。
- insert(size_type idx,const string& str) :在当前字符串的idx处插入一个字符串str。
- 迭代器函数:begin()、end()、rbegin()最后一个元素后面、rend()第一个函数前面。
#include <iostream> #include <string> using namespace std; void main() { string s1="",s2,s3="Bye"; s1.append("Good morning"); //s1=" Good morning" s2=s1; //s1=" Good morning" int i=s2.find("morning"); //i=5 查找i位置 s2.replace(i,s2.length()-i,s3); //相当于s2.replace(5,7,s3) cout << "s1: " << s1 << endl; //s1=" Good morning" cout << "s2: " << s2 << endl; //s1=" Good Bye" }
求解模板生成工具问题。成成最近在搭建一个网站,其中一些页面的部分内容来自数据库中不同的数据记录,但是页面的基本结构是相同的。例如,对于展示用户信息的页面,当用户为Tom时,网页的源代码如下:
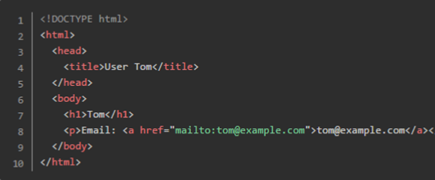
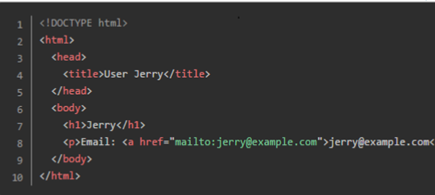
而当用户为Jerry时,网页的源代码如下:
这样的例子在包含动态内容的网站中还有很多。为了简化生成网页的工作,成成觉得他需要引入一套模板生成系统。模板是包含特殊标记的文本。成成用到的模板只包含一种特殊标记,格式为{{ VAR }},其中VAR是一个变量。该标记在模板生成时会被变量VAR的值所替代。例如,如果变量name = "Tom",则{{ name }}会生成Tom。具体的规则如下:
变量名由大小写字母、数字和下划线(_)构成,且第一个字符不是数字,长度不超过16个字符。
变量名是大小写敏感的,Name和name是两个不同的变量。
变量的值是字符串。
如果标记中的变量没有定义,则生成空串,相当于把标记从模板中删除。
模板不递归生成。也就是说,如果变量的值中包含形如{{ VAR }}的内容,不再做进一步的替换。
输入格式:输入的第一行包含两个整数m和n,分别表示模板的行数和模板生成时给出的变量个数。接下来m行,每行是一个字符串,表示模板。接下来n行,每行表示一个变量和它的值,中间用一个空格分隔。值是字符串,用双引号(")括起来,内容可包含除双引号以外的任意可打印 ASCII 字符(ASCII码范围32, 33, 35~126)。
输出格式:输出包含若干行,表示模板生成的结果。
样例输入:
11 2 <!DOCTYPE html> <html> <head> <title>User {{ name }}</title> </head> <body> <h1>{{ name }}</h1> <p>Email: <a href="mailto:{{ email }}">{{ email }}</a></p> <p>Address: {{ address }}</p> </body> </html> name "David Beckham" email "david@beckham.com"
样例输出:
<!DOCTYPE html> <html> <head> <title>User David Beckham</title> </head> <body> <h1>David Beckham</h1> <p>Email: <a href="mailto:david@beckham.com">david@beckham.com</a ></p> <p>Address: </p> </body> </html>
评测用例规模与约定:
0≤m≤100,0≤n≤100
输入的模板每行长度不超过80个字符(不包含换行符)。
输入保证模板中所有以 {{ 开始的子串都是合法的标记,开始是两个左大括号和一个空格,然后是变量名,结尾是一个空格和两个右大括号。
输入中所有变量的值字符串长度不超过 100 个字符(不包括双引号)。
保证输入的所有变量的名字各不相同。
解:采用vector<string>向量content存放网页,每一行作为一个元素。用map<string,string>容器存放转换字符串。例如,对于题目中的样例,content向量中下标为0到10的元素如下:
<!DOCTYPE html> <html> <head> <title>User {{ name }}</title> </head> <body> <h1>{{ name }}</h1> <p>Email: <a href="mailto:{{ email }}">{{ email }}</a></p> <p>Address: {{ address }}</p> </body>
mymap映射容器中包含如下两个结点(注意双引号是值的一部分):
mymap[email]= "david@beckham.com" mymap[name]= "David Beckham"
然后扫描content的每个元素,查找形如“{{ var }}”的字符串,将{{ var }}用mymap[var]替换(注意替换部分不包含双引号),在一个元素中可以有多个需要替换的内容。例如,将:
href="mailto:{{ email }}">{{ email }}</a></p> 替换为: href="mailto:david@beckham.com">david@beckham.com</a></p>
字符串查找、替换均采用string的成员函数完成。对应的程序如下:
#include <iostream> #include <vector> #include <string> #include <map> using namespace std; vector<string> content; //存放网页 map<string,string> mymap; //存放转换字符串 int m,n; void trans() //网页转换 { for(int i=0;i<m;i++) //转换content向量中的所有行 { int pos=0,pos1,pos2; do { pos1=content[i].find("{{",pos); //从pos位置开始查找第一个{{ pos2=content[i].find("}}",pos1); //从pos1位置开始查找第一个}} if(pos1>=0 && pos2>=0) //找到{{ }} { string var=content[i].substr(pos1+3,pos2-pos1-4); if(mymap.count(var)) //提取形如{{var}} { string result=mymap[var].substr(2, mymap[var].length()-3); content[i].replace(pos1,var.length()+6,result); //替换 } else content[i].replace(pos1,var.length()+6,""); pos=pos1+var.length(); } else //没有找到{{ }},pos指向当前字符串末尾 pos = content[i].length(); } while(pos<content[i].length()); } } int main() { int i; string line; cin >> m >> n; cin.ignore(); //屏蔽回车键 for(i=0;i<m;i++) //输入m行存放在content向量中 { getline(cin,line); content.push_back(line); } for(i=0;i<n;i++) //输入n行按空格分为两个部分 { getline(cin,line); int pos = line.find(" "); mymap.insert(map<string,string>::value_type( line.substr(0,pos),line.substr(pos))); } trans(); for (i=0;i<m;i++) //输出网页转换结果 cout << content[i] << endl; return 0; }
2.1.3deque(双端队列容器)
1.定义
它是一个双端队列类模板。双端队列容器由若干个块构成,每个块中元素地址是连续的,块之间的地址是不连续的,有一个特定的机制将这些块构成一个整体。可以从前面或后面快速插入与删除元素,并可以快速地随机访问元素,但删除元素较慢。
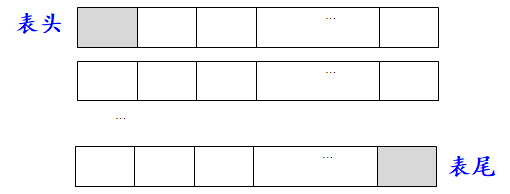
定义deque双端队列容器的几种方式如下:
deque<int> dq1; //定义元素为int的双端队列dq1 deque<int> dq2(10); //指定dq2的初始大小为10个int元素 deque<double> dq3(10,1.23); //指定dq3的10个初始元素的初值为1.23 deque<int> dq4(dq2.begin(),dq2.end()); //用dq2的所有元素初始化dq4
2.deque主要的成员函数如下
- empty():判断双端队列容器是否为空队。
- size():返回双端队列容器中元素个数。
- push_front(elem):在队头插入元素elem。
- push_back(elem):在队尾插入元素elem。
- pop_front():删除队头一个元素。
- pop_back():删除队尾一个元素。
- erase():从双端队列容器中删除一个或几个元素。
- clear():删除双端队列容器中所有元素。
- 迭代器函数:begin()、end()、rbegin()、rend()。
#include <deque> using namespace std; void disp(deque<int> &dq) //输出dq的所有元素 { deque<int>::iterator iter; //定义迭代器iter for (iter=dq.begin();iter!=dq.end();iter++) printf("%d ",*iter); printf("\n"); } void main() { deque<int> dq; //建立一个双端队列dq dq.push_front(1); //队头插入1 dq.push_back(2); //队尾插入2 dq.push_front(3); //队头插入3 dq.push_back(4); //队尾插入4 printf("dq: "); disp(dq); dq.pop_front(); //删除队头元素 dq.pop_back(); //删除队尾元素 printf("dq: "); disp(dq); }
//3124
//12
2.1.4list(链表容器)
1.定义
它是一个双链表类模板。可以从任何地方快速插入与删除。它的每个结点之间通过指针链接,不能随机访问元素。
![]()
定义list容器的几种方式如下:
list<int> l1; //定义元素为int的链表l1 list<int> l2 (10); //指定链表l2的初始大小为10个int元素 list<double> l3 (10,1.23); //指定l3的10个初始元素的初值为1.23 list<int> l4(a,a+5); //用数组a[0..4]共5个元素初始化l4
2.list的主要成员函数如下
- empty():判断链表容器是否为空。
- size():返回链表容器中实际元素个数。
- push_back():在链表尾部插入元素。
- pop_back():删除链表容器的最后一个元素。
- remove ():删除链表容器中所有指定值的元素。
- remove_if(cmp):删除链表容器中满足条件的元素。
- erase():从链表容器中删除一个或几个元素。
- unique():删除链表容器中相邻的重复元素。
- clear():删除链表容器中所有的元素。
- insert(pos,elem):在pos位置插入元素elem,即将元素elem插入到迭代器pos指定元素之前。
- insert(pos,n,elem):在pos位置前插入n个元素elem。
- insert(pos,pos1,pos2):在迭代器pos处插入[pos1,pos2)的元素。
- reverse():反转链表。
- sort():对链表容器中的元素排序。
- 迭代器函数:begin()、end()、rbegin()、rend()。
说明:STL提供的sort()排序算法主要用于支持随机访问的容器,而list容器不支持随机访问,为此,list容器提供了sort()采用函数用于元素排序。类似的还有unique()、reverse()、merge()等STL算法。
#include <list> using namespace std; void disp(list<int> &lst) //输出lst的所有元素 { list<int>::iterator it; for (it=lst.begin();it!=lst.end();it++) printf("%d ",*it); printf("\n"); } void main() { list<int> lst; //定义list容器lst list<int>::iterator it,start,end; lst.push_back(5); //添加5个整数5,2,4,1,3 lst.push_back(2); lst.push_back(4); lst.push_back(1); lst.push_back(3); printf("初始lst: "); disp(lst); it=lst.begin(); //it指向首元素5 start=++lst.begin(); //start指向第2个元素2 end=--lst.end(); //end指向尾元素3 lst.insert(it,start,end); printf("执行lst.insert(it,start,end)\n"); printf("插入后lst: "); disp(lst); }
2.2关联容器
2.2.1set(集合容器)/ multiset(多重集容器)
1.定义
set和multiset都是集合类模板,其元素值称为关键字。set中元素的关键字是唯一的,multiset中元素的关键字可以不唯一,而且默认情况下会对元素按关键字自动进行升序排列。
查找速度比较快,同时支持集合的交、差和并等一些集合上的运算,如果需要集合中的元素允许重复那么可以使用multiset。
2.set/multiset的成员函数如下
- empty():判断容器是否为空。
- size():返回容器中实际元素个数。
- insert():插入元素。
- erase():从容器删除一个或几个元素。
- clear():删除所有元素。
- count(k):返回容器中关键字k出现的次数。
- find(k):如果容器中存在关键字为k的元素,返回该元素的迭代器,否则返回end()值。
- upper_bound():返回一个迭代器,指向关键字大于k的第一个元素。
- lower_bound():返回一个迭代器,指向关键字不小于k的第一个元素。
- 迭代器函数:begin()、end()、rbegin()、rend()。
#include <set> using namespace std; void main() { set<int> s; //定义set容器s set<int>::iterator it; //定义set容器迭代器it s.insert(1); s.insert(3); s.insert(2); s.insert(4); s.insert(2); printf(" s: "); for (it=s.begin();it!=s.end();it++) printf("%d ",*it); printf("\n"); //s:1 2 3 4 multiset<int> ms; //定义multiset容器ms multiset<int>::iterator mit; //定义multiset容器迭代器mit ms.insert(1); ms.insert(3); ms.insert(2); ms.insert(4); ms.insert(2); printf("ms: "); for (mit=ms.begin();mit!=ms.end();mit++) printf("%d ",*mit); printf("\n"); } //ms:1 2 2 3 4
2.2.2map(映射容器)/ multimap(多重映射容器)
1.定义
类似于数组,关键字当成下标
map和multimap都是映射类模板。映射是实现关键字与值关系的存储结构,可以使用一个关键字key来访问相应的数据值value。
在set/multiset中的key和value都是key类型,而key和value是一个pair类结构。
pair类结构的声明形如:
struct pair { T first; T second; }
map/multimap利用pair的<运算符将所有元素即key-value对按key的升序排列,以红黑树的形式存储,可以根据key快速地找到与之对应的value(查找时间为O(log2n))。
map中不允许关键字重复出现,支持[]运算符;而multimap中允许关键字重复出现,但不支持[]运算符。
2.map/multimap的主要成员函数如下
empty():判断容器是否为空。
size():返回容器中实际元素个数。
map[key]:返回关键字为key的元素的引用,如果不存在这样的关键字,则以key作为关键字插入一个元素(不适合multimap)。
insert(elem):插入一个元素elem并返回该元素的位置。
clear():删除所有元素。
find():在容器中查找元素。
count():容器中指定关键字的元素个数(map中只有1或者0)。
迭代器函数:begin()、end()、rbegin()、rend()。
在map中修改元素非常简单,这是因为map容器已经对[]运算符进行了重载(对其含义进行重新定义)。例如:
map<char,int> mymap; //定义map容器mymap,其元素类型为pair<char,int> mymap['a'] = 1; //或者mymap.insert(pair<char,int>('a',1) );
//键字符型‘单引号’ 值int
获得map中一个值的最简单方法如下:
int ans = mymap['a'];
只有当map中有这个关键字('a')时才会成功,否则会自动插入一个元素,值为初始化值。可以使用find() 方法来发现一个关键字是否存在。
#include <map> using namespace std; void main() { map<char,int> mymap; //定义map容器mymap mymap.insert(pair<char,int>('a',1)); //插入方式1 mymap.insert(map<char,int>::value_type('b',2)); //插入方式2 mymap['c']=3;
//插入方式3 map<char,int>::iterator it; for(it=mymap.begin();it!=mymap.end();it++) printf("[%c,%d] ",it->first,it->second); printf("\n"); } //[a,1] [b,2] [c,3]
2.3适配器容器
2.3.1stack(栈容器)
它是一个栈类模板,和数据结构中的栈一样,具有后进先出的特点。栈容器默认的底层容器是deque。也可以指定其他底层容器。
例如,以下语句指定myst栈的底层容器为vector:
stack<string,vector<string> > myst; //第2个参数指定底层容器为vector
stack容器主要的成员函数如下:
- empty():判断栈容器是否为空。
- size():返回栈容器中实际元素个数。
- push(elem):元素elem进栈。
- top():返回栈顶元素。
- pop():元素出栈。
注意:stack容器没有begin()/end()和rbegin()/rend()这样的用于迭代器的成员函数。
#include <stack> using namespace std; void main() { stack<int> st; st.push(1); st.push(2); st.push(3); printf("栈顶元素: %d\n",st.top()); printf("出栈顺序: "); while (!st.empty()) //栈不空时出栈所有元素 { printf("%d ",st.top()); st.pop() ; } printf("\n"); }
2.3.2queue(队列容器)
它是一个队列类模板,和数据结构中的队列一样,具有先进先出的特点。不允许顺序遍历,没有begin()/end()和rbegin()/rend()这样的用于迭代器的成员函数。
主要的成员函数如下:
- empty():判断队列容器是否为空。
- size():返回队列容器中实际元素个数。
- front():返回队头元素。
- back():返回队尾元素。
- push(elem):元素elem进队。
- pop():元素出队。
#include <queue> using namespace std; void main() { queue<int> qu; qu.push(1); qu.push(2); qu.push(3); printf("队头元素: %d\n",qu.front()); printf("队尾元素: %d\n",qu.back()); printf("出队顺序: "); while (!qu.empty()) //出队所有元素 { printf("%d ",qu.front()); qu.pop(); } printf("\n"); }
2.3.3priority_queue(优先队列容器)
它是一个优先队列类模板。优先队列是一种具有受限访问操作的存储结构,元素可以以任意顺序进入优先队列。
一旦元素在优先队列容器中,出队操作将出队列最高优先级元素。
主要的成员函数如下:
- empty():判断优先队列容器是否为空。
- size():返回优先队列容器中实际元素个数。
- push(elem):元素elem进队。
- top():获取队头元素。
- pop():元素出队。
#include <queue> using namespace std; void main() { priority_queue<int> qu; qu.push(3); qu.push(1); qu.push(2); printf("队头元素: %d\n",qu.top()); printf("出队顺序: "); while (!qu.empty()) //出队所有元素 { printf("%d ",qu.top()); qu.pop(); } printf("\n"); }
3.STL在算法设计中的应用
3.1存放主数据
算法设计重要步骤是设计数据的存储结构,除非特别指定,程序员可以采用STL中的容器存放主数据,选择何种容器不仅要考虑数据的类型,还有考虑数据的处理过程。
例如,字符串可以采用string或者vector<char>来存储,链表可以采用list来存储。
【例1.11】有一段英文由若干单词组成,单词之间用一个空格分隔。编写程序提取其中的所有单词。
解:这里的主数据是一段英文,采用string字符串str存储它,最后提取的单词采用vector<string>容器words存储。
#include <iostream> #include <string> #include <vector> using namespace std; void solve(string str,vector<string> &words) //产生所有单词words { string w; int i=0; int j=str.find(" "); //查找第一个空格 while (j!=-1) //找到单词后循环 { w=str.substr(i,j-i); //提取一个单词,从i到j-i在str里面取 words.push_back(w); //单词添加到words中 i=j+1; j=str.find(" ",i); //查找下一个空格 } if (i<str.length()-1) //处理最后一个单词 {
w=str.substr(i); //提取最后一个单词 words.push_back(w); //最后单词添加到words中 } }
void main() { string str="The following code computes the intersection of two arrays"; vector<string> words; solve(str,words); cout << "所有的单词:" << endl; //输出结果 vector<string>::iterator it; for (it=words.begin();it!=words.end();++it) cout << " " << *it << endl; } 所有的单词: The following code computes the intersection of two arrays
3.2存放临时数据
在算法设计中,有时需要存放一些临时数据。通常的情况是,如果后存入的元素先处理,可以使用stack栈容器;
如果先存入的元素先处理,可以使用queue队列容器;如果元素处理顺序按某个优先级进行,可以使用priority_queue优先队列容器。
【例1.12】设计一个算法,判断一个含有()、[]、{}三种类型括号的表达式中所有括号是否匹配。
解:这里的主数据是一个字符串表达式,采用string字符串str存储它。在判断括号是否匹配时需要用到一个栈(因为每个右括号都是和前面最近的左括号匹配),采用stack<char>容器作为栈。
#include <iostream> #include <stack> #include <string> using namespace std; bool solve(string str) //判断str中括号是否匹配 { stack<char> st; int i=0; while (i<str.length()) //扫描str的所有字符 { if (str[i]=='(' || str[i]=='[' || str[i]=='{') st.push(str[i]); //所有左括号进栈 else if (str[i]==')') //当前字符为')' { if (st.top()!='(') //若栈顶不是匹配的'(',返回假 return false; else //若栈顶是匹配的'(',退栈 st.pop(); } else if (str[i]==']') //当前字符为']' { if (st.top()!='[') //若栈顶不是匹配的'[',返回假 return false; else //若栈顶是匹配的'[',退栈 st.pop(); } else if (str[i]=='}') //当前字符为'}' { if (st.top()!='{') //若栈顶不是匹配的'{',返回假 return false; else //若栈顶是匹配的'{',退栈 st.pop(); } i++; } if (st.empty()) //str处理完毕并且栈空返回真 return true; else return false; //否则返回假 } void main() { cout << "求解结果:" << endl; string str="(a+[b-c]+d)"; cout << " " << str << (solve(str)?"中括号匹配":"中括号不匹配") << endl; str="(a+[b-c}+d)"; cout << " " << str << (solve(str)?"中括号匹配":"中括号不匹配") << endl; } /* (a+[b-c]+d) 中括号匹配 (a+[b-c}+d) 中括号不匹配 */
3.3检测数据元素的唯一性
可以使用map容器或者哈希表容器检测数据元素是否唯一或者存放累计个数。
【例1.13】设计一个算法判断字符串str中每个字符是否唯一。如,"abc"的每个字符是唯一的,算法返回true,而"accb"的中字符'c'不是唯一的,算法返回false。
解:设计map<char,int>容器mymap,第一个分量key的类型为char,第二个分量value的类型为int,表示对应关键字出现的次数。
将字符串str中每个字符作为关键字插入到map容器中,插入后对应出现次数增1。如果某个字符的出现次数大于1,表示不唯一,返回false;如果所有字符唯一,返回true。
bool isUnique(string &str) //检测str中的所有字符是否唯一的 { map<char,int> mymap; for (int i=0;i<str.length();i++) {
mymap[str[i]]++; if (mymap[str[i]]>1) return false; } return true; }
求多少对相反数。有N个非零且各不相同的整数。请你编一个程序求出它们中有多少对相反数(a和-a为一对相反数)。时间限制为1.0s,内存限制:256.0MB。
输入格式:第一行包含一个正整数 N(1≤N≤500)。第二行为N个用单个空格隔开的非零整数,每个数的绝对值不超过1000,保证这些整数各不相同。
输出格式:只输出一个整数,即这N个数中包含多少对相反数。
样例输入:
5
1 2 3 -1 -2
样例输出:
2
解:可以直接采用暴力思路求解,但可能超时。
这里使用STL的map容器mymap(其实用哈希表效率更高),对于输入的负整数x,将(-x,1)插入。扫描所有输入的正整数y,当mymap[y]存在时说明对应一个相反数对,ans增1。
#include <stdio.h> #include <map> using namespace std; #define MAX 505 int main() { int ans=0; //累计相反数对的个数 int n,x,i; int a[MAX]; map<int,int> mymap; scanf("%d",&n); for (i=0;i<n;i++) { scanf("%d",&x); a[i]=x; if (x<0) //将负整数插入mymap mymap.insert(pair<int,int>(-x,1)); } for (i=0;i<n;i++) if (a[i]>0 && mymap[a[i]]) ans++; printf("%d\n",ans); }
3.4数据排序
对于list容器的元素排序可以使用其成员函数sort(),对于数组或者vector等具有随机访问特性的容器,可以使用STL算法sort()。
下面以STL算法sort()为例讨论。
1)内置数据类型的排序
对于内置数据类型的数据,sort()默认是以less<T>(小于关系函数)作为关系函数实现递增排序。
为了实现递减排序,需要调用<functional>头文件中定义的greater类模板。
例如,以下程序使用greater<int>()实现vector<int>容器元素的递减排序(其中sort(myv.begin(),myv.end(),less<int>())语句等同于sort(myv.begin(),myv.end()),实现默认的递增排序):
#include <iostream> #include <algorithm> #include <vector> #include <functional> //包含less、greater等 using namespace std; void Disp(vector<int> &myv) //输出vector的元素 { vector<int>::iterator it; for(it = myv.begin();it!=myv.end();it++) cout << *it << " "; cout << endl; } void main() { int a[]={2,1,5,4,3}; int n=sizeof(a)/sizeof(a[0]); vector<int> myv(a,a+n); cout << "初始myv: "; Disp(myv); //输出:2 1 5 4 3 sort(myv.begin(),myv.end(),less<int>()); cout << "递增排序: "; Disp(myv); //输出:1 2 3 4 5 sort(myv.begin(),myv.end(),greater<int>()); cout << "递减排序: "; Disp(myv); //输出:5 4 3 2 1 }
2)自定义数据类型的排序
对于自定义数据类型如结构体数据,同样默认是less<T>(即小于关系函数)作为关系函数,但需要重载该函数。另外还可以自己定义关系函数()。在这些重载函数或者关系函数中指定数据的排序顺序(按哪些结构体成员排序,是递增还是递减)。
归纳起来,实现排序时主要有两种方式:
方式1:在声明结构体类型中重载<运算符,以实现按指定成员的递增或者递减排序。如sort(myv.begin(),myv.end())调用默认<运算符对myv容器的所有元素实现排序。
方式2:自己定义关系函数(),以实现按指定成员的递增或者递减排序。如sort(myv.begin(),myv.end(),Cmp())调用Cmp的()运算符对myv容器的所有元素实现排序。
#include <iostream> #include <algorithm> #include <vector> #include <string> using namespace std; struct Stud { int no; string name; Stud(int no1,string name1) //构造函数 { no=no1; name=name1; } bool operator<(const Stud &s) const //方式1:重载<运算符 { return s.no<no; //用于按no递减排序,将<改为>则按no递增排序 } }; struct Cmp //方式2:定义关系函数() { bool operator()(const Stud &s,const Stud &t) const { return s.name<t.name; //用于按name递增排序,将<改为>则按name递减排序 } }; void Disp(vector<Stud> &myv) //输出vector的元素 { vector<Stud>::iterator it; for(it = myv.begin();it!=myv.end();it++) cout << it->no << "," << it->name << "\t"; cout << endl; } void main() { Stud a[]={Stud(2,"Mary"),Stud(1,"John"),Stud(5,"Smith")}; int n=sizeof(a)/sizeof(a[0]); vector<Stud> myv(a,a+n); cout << "初始myv: "; Disp(myv); //输出:2,Mary 1,John 5,Smith sort(myv.begin(),myv.end()); //默认使用<运算符排序 cout << "按no递减排序: "; Disp(myv); //输出:5,Smith 2,Mary 1,John sort(myv.begin(),myv.end(),Cmp()); //使用Cmp中的()运算符进行排序 cout << "按name递增排序: "; Disp(myv); //输出:1,John 2,Mary 5,Smith }
3.5优先队列作为堆
在有些算法设计中用到堆,堆采用STL的优先队列来实现,优先级的高低由队列中数据元素的关系函数(比较运算符)确定,很多情况下需要重载关系函数。
1)元素为内置数据类型的堆
对于C/C++内置数据类型,默认是less<T>(小于关系函数)作为关系函数,值越大优先级的越高(即大根堆),可以改为以greater<T>作为关系函数,这样值越大优先级的越低(即小根堆)。
例如,以下程序中pq1为大根堆(默认),pq2为小根堆(通过greater<int>实现):
#include <iostream> #include <queue> using namespace std; void main() { int a[]={3,6,1,5,4,2}; int n=sizeof(a)/sizeof(a[0]); //(1)优先级队列pq1默认是使用vector作容器 priority_queue<int> pq1(a,a+n); cout << "pq1: "; while (!pq1.empty()) { cout << pq1.top() << " "; //while循环输出:6 5 4 3 2 1 pq1.pop(); } cout << endl; //(2)优先级队列pq2使用vector作容器,int元素的关系函数改为greater priority_queue<int,vector<int>,greater<int> > pq2(a,a+n); cout << "pq2: "; while (!pq2.empty()) { cout << pq2.top() << " "; //while循环输出:1 2 3 4 5 6 pq2.pop(); } cout << endl; }
2)元素为自定义类型的堆
对于自定义数据类型如结构体数据,同样默认是less<T>(即小于关系函数)作为关系函数,但需要重载该函数。
另外还可以自己定义关系函数()。在这些重载函数或者关系函数中指定数据的优先级(优先级取决于哪些结构体,是越大越优先还是越小越优先)。
#include <iostream> #include <queue> #include <string> using namespace std; struct Stud //声明结构体Stud { int no; string name; Stud(int n,string na) //构造函数 { no=n; name=na; } bool operator<(const Stud &s) const //重载<关系函数 { return no<s.no; } bool operator>(const Stud &s) const //重载>关系函数 { return no>s.no; } }; //结构体的关系函数,改写operator() struct StudCmp { bool operator()(const Stud &s,const Stud &t) const { return s.name<t.name; //name越大越优先 } }; void main() { Stud a[]={Stud(2,"Mary"),Stud(1,"John"),Stud(5,"Smith")}; int n=sizeof(a)/sizeof(a[0]); //(1)使用Stud结构体的<关系函数定义pq1 priority_queue<Stud> pq1(a,a+n); cout << "pq1出队顺序: "; while (!pq1.empty()) //按no递减输出 { cout << "[" << pq1.top().no << "," << pq1.top().name << "]\t"; pq1.pop(); } cout << endl; //pq1出队顺序: [5,Smith] [2,Mary] [1,John] //(2)使用Stud结构体的>关系函数定义pq2 priority_queue<Stud,deque<Stud>,greater<Stud> > pq2(a,a+n); cout << "pq2出队顺序: "; while (!pq2.empty()) //按no递增输出 { cout << "[" << pq2.top().no << "," << pq2.top().name << "]\t"; pq2.pop(); } cout << endl; //pq2出队顺序: [1,John] [2,Mary] [5,Smith] //(3)使用结构体StudCmp的关系函数定义pq3 priority_queue<Stud,deque<Stud>,StudCmp > pq3(a,a+n); cout << "pq3出队顺序: "; while (!pq3.empty()) //按name递减输出 { cout << "[" << pq3.top().no << "," << pq3.top().name << "]\t"; pq3.pop(); } cout << endl; } //pq3出队顺序: [5,Smith] [2,Mary] [1,John]
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号