
个人项目:论文查重
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/homework/13229 |
| 这个作业的目标 | 设计一个论文查重项目,了解软件开发流程 |
| gitHub项目地址 | https://github.com/Abaistudy/Personal-project |
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| Estimate | 估计这个任务需要多少时间 | 20 | 10 |
| Development | 开发 | 300 | 350 |
| Analysis | 需求分析 (包括学习新技术) | 120 | 120 |
| Design Spec | 生成设计文档 | 120 | 90 |
| Design Review | 设计复审 | 20 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| Design | 具体设计 | 60 | 90 |
| Coding | 具体编码 | 180 | 150 |
| Code Review | 代码复审 | 60 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 120 | 180 |
| Test Repor | 测试报告 | 20 | 10 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | 10 |
| 合计 | 1150 | 1260 |
二、思路分析以及接口设计
题目回顾:
-
设计一个论文查重算法,输入一份原文文件和一份抄袭版论文的文件,计算重复率并在指定答案文件中输出。注意答案文件中输出的答案为浮点型,精确到小数点后两位
-
输入输出格式:按照传递命令行参数的方式提供文件的位置,需要从指定的位置读取文件,并向指定的文件输出答案。
python main.py [原文文件] [抄袭版论文的文件] [答案文件]
运行环境:
PyCharm 2021.1.3 (Professional Edition)
python 3.9
思路分析:

主要计算模块接口设计
1.文本预处理(preprocess_text):去除标点符号,使用jieba库进行分词,最后返回以空格分隔的词语序列。
def preprocess_text(text):
"""
文本预处理:去除标点符号,换行符,并进行分词
"""
# 避免输入文本为空出错
if not text:
return ""
# 去除标点符号和换行符
text = text.translate(str.maketrans('', '', string.punctuation + '\n\r\t'))
# 使用 jieba 进行分词
words = jieba.lcut(text)
# 返回以空格分隔的词语序列
return ' '.join(words)
2.文本向量化(vectorize_texts):使用 TF-IDF 算法将两个文本向量化。
def vectorize_texts(text1, text2):
"""
使用 TF-IDF 将两个文本向量化
"""
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform([text1, text2])
return tfidf_matrix
3.计算余弦相似度(calculate_cosine_similarity):使用 sklearn 里面的cosine_similarity函数计算向量化文本的余弦相似度。
def calculate_cosine_similarity(tfidf_matrix):
"""
计算余弦相似度
"""
if tfidf_matrix.shape[1] == 0: # 如果向量的维度为0,返回0相似度
return 0.0
# 计算两个向量之间的余弦相似度
similarity = cosine_similarity(tfidf_matrix[0:1], tfidf_matrix[1:2])[0][0]
return similarity
各接口之间的关系
plagiarism_check是主函数,负责协调整个流程。首先调用read_file读取原文和抄袭文件的内容。- 读取的文本传入
preprocess_text,该函数去除标点符号并进行分词,生成预处理后的文本。 - 经过预处理的文本交给
vectorize_texts,使用TF-IDF算法将两个文本向量化。 - 向量化结果传给
calculate_cosine_similarity,计算两个文本的余弦相似度。 - 最后,相似度结果由
save_similarity_to_file保存到指定的输出文件中。
每个接口相互配合,完成从文件读取、文本处理到相似度计算和结果保存的完整查重流程。
关键点:
- 文本预处理:通过正则表达式去除标点符号,用
jieba分词库进行中文分词,确保文本处理的准确性。 TF-IDF向量化:利用TfidfVectorizer将文本转化为向量,衡量词语的重要性并准备相似度计算。- 余弦相似度:计算两个文本向量的余弦值,用于评估文本相似度,处理空向量情况避免错误。
- 命令行输入:通过命令行参数接收输入和输出文件路径,需严谨参照使用说明。
独到之处
- 中文特化处理:使用
jieba分词库,适合中文文本处理,确保准确查重。 - 模块化设计:各步骤独立封装,易于扩展和维护。
- 余弦相似度计算:使用了
scikit-learn的cosine_similarity函数来计算余弦相似度,相比手动编写公式更快且更稳定。 - 清晰易用:通过命令行参数控制文件路径,输出精确结果,便于用户操作。
三、性能分析
使用cproflie库进行性能分析,生成performance_analysis_result文件,使用snakeviz程序将性能分析结果进行可视化。`
cProfile.run("plagiarism_check(orig_file, plagiarism_file, output_file)", filename="performance_analysis_result")
snakeviz.exe -p 8080 .\performance_analysis_result
性能分析结果如图:

可见在主函数plagiarism_check中,函数preprocess_text运行时间最长。明显是执行jieba库中的lcut函数运行时间长,要先优化得找到更好的文本预处理方法
四、单元测试
测试点分析
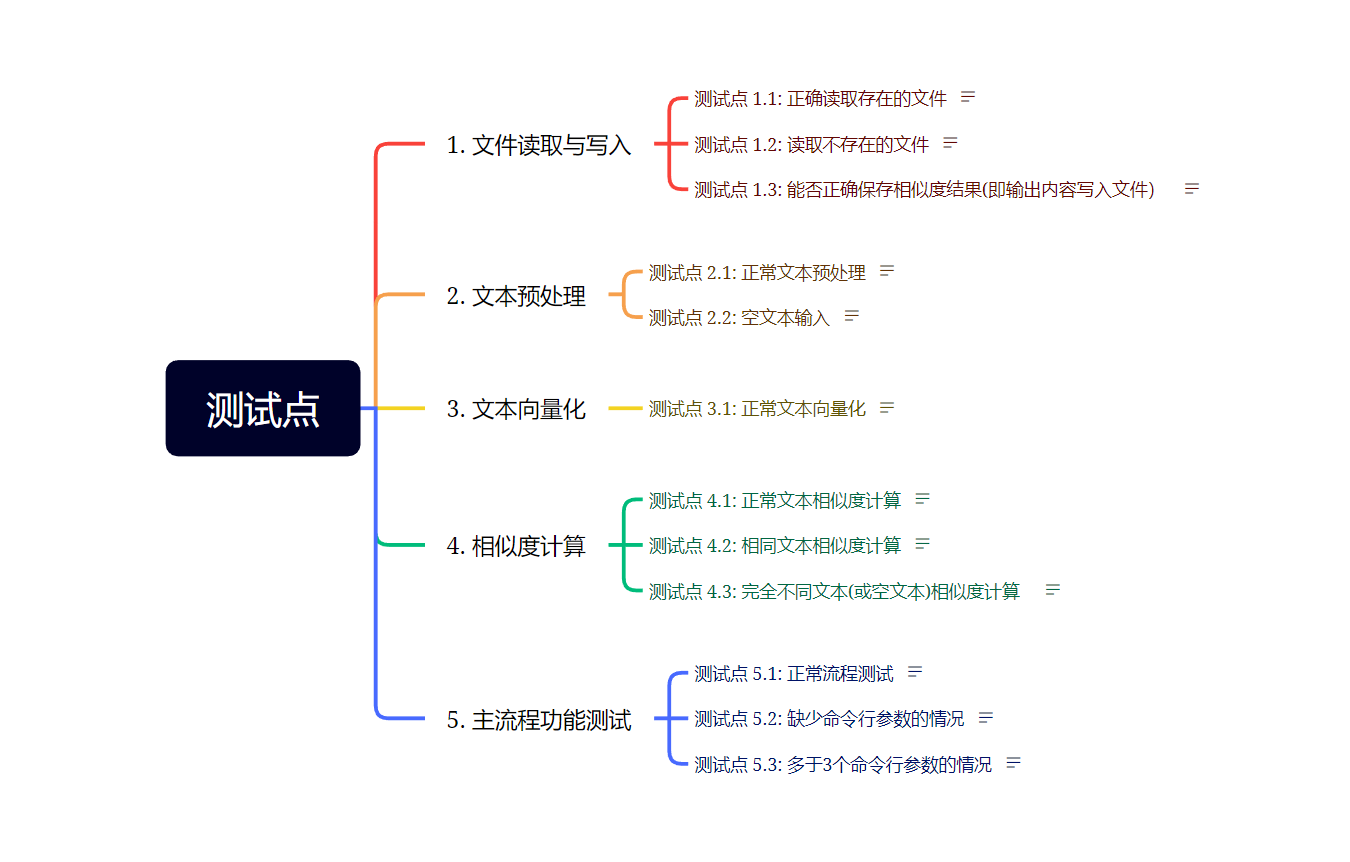
1.测试文件的读写功能
测试点:
-
已存在的文件能否正确读取
-
读取不存在的文件时能否提示错误
-
得到的相似度结果能否正确保存
测试代码
def test_read_file_existing(self):
"""
1.1: 测试能否正确读取已存在的文件
预期:text非空
"""
test_file = './test_text/orig.txt'
text = main.read_file(test_file)
assert text is not None
def test_read_file_not_found(self):
"""
测试点 1.2: 测试读取不存在的文件
预期:报错,并提示错误文件名
"""
# 404.txt 不存在
test_file = './test_text/404.txt'
with pytest.raises(FileNotFoundError):
main.read_file(test_file)
def test_save_similarity_to_file(self):
"""
测试点 1.3: 测试能否正确保存相似度结果(即输出内容写入文件)
预期:读取文件内容与写入时一致
"""
test_output_file = './test_text/test_output.txt'
main.save_similarity_to_file(test_output_file, 0.75)
with open(test_output_file, 'r', encoding='utf-8') as f:
result = f.read()
assert result == '0.75'
os.remove(test_output_file)
2.测试文本预处理功能
测试点:
-
正常文本能否正确处理
-
空文本能否正确处理
-
乱码文本能否正常处理
测试代码
def test_preprocess_text_normal(self):
"""
测试点 2.1: 测试正常文本预处理
预期:返回分词后字符串
"""
text = "你好,世界!这是一个测试。"
result = main.preprocess_text(text)
assert result == "你好 世界 这是 一个 测试"
def test_preprocess_empty_text(self):
"""
测试点 2.2: 测试空文本处理
预期:返回空字符串
"""
text = ""
result = main.preprocess_text(text)
assert result == ""
3.测试文本向量化功能
测试点:
- 正常文本能否正确向量化
测试代码
def test_vectorize_texts_normal(self):
"""
测试点 3.1: 测试正常文本向量化
预期:与计算结果一致
"""
text1 = "这是一个测试"
text2 = "这是另一个测试"
tfidf_matrix = main.vectorize_texts(text1, text2)
assert tfidf_matrix.shape == (2, 2) # 2 行(文本),2列(词汇数)
4.测试余弦相似度计算功能
测试点:
- 不同文本的相似度计算是否正确(小于1)
- 相同文本的相似度计算是否正确(等于1)
- 完全不同文本(或空文本)的相似度计算是否正确(极小,小于0.1)
测试代码
def test_calculate_similarity_normal(self):
"""
测试点 4.1: 测试不同文本的相似度计算
预期:返回一个不大于1的浮点数
"""
text1 = "这是一个测试"
text2 = "这是另一个测试"
text1 = main.preprocess_text(text1)
text2 = main.preprocess_text(text2)
tfidf_matrix = main.vectorize_texts(text1, text2)
similarity = main.calculate_cosine_similarity(tfidf_matrix)
assert 0 <= similarity <= 1
def test_calculate_similarity_identical(self):
"""
测试点 4.2: 测试相同文本的相似度计算
预期:返回1.0
"""
text1 = "这是一个测试"
text2 = "这是一个测试"
text1 = main.preprocess_text(text1)
text2 = main.preprocess_text(text2)
tfidf_matrix = main.vectorize_texts(text1, text2)
similarity = main.calculate_cosine_similarity(tfidf_matrix)
similarity = round(similarity, 2)
assert similarity == 1.0
def test_calculate_similarity_completely_different(self):
"""
测试点 4.3: 测试完全不同文本(或空文本)的相似度计算
预期:返回的余弦相似度极小,小于0.1
"""
text1 = "这是一个测试"
text2 = "完全不同的文本"
text3 = ""
tfidf_matrix1 = main.vectorize_texts(text1, text2)
tfidf_matrix2 = main.vectorize_texts(text1, text3)
similarity1 = main.calculate_cosine_similarity(tfidf_matrix1)
similarity2 = main.calculate_cosine_similarity(tfidf_matrix2)
assert similarity1 < 0.1
assert similarity2 == 0.0
5.测试主流程功能
测试点:
-
主函数流程是否能正常运行
-
缺少命令行参数的情况能否处理
-
多于3个命令行参数的情况能否处理
测试代码
def test_main_flow(self):
"""
测试点 5.1: 测试主函数
预期:各个断言通过
"""
orig_file = './test_text/orig.txt'
plagiarism_file = './test_text/orig_0.8_add.txt'
output_file = './test_text/orig_output.txt'
orig_file = main.read_file(orig_file)
plagiarism_file = main.read_file(plagiarism_file)
assert orig_file is not None
assert plagiarism_file is not None
tfidf_matrix = main.vectorize_texts(orig_file, plagiarism_file)
similarity = main.calculate_cosine_similarity(tfidf_matrix)
assert 0 <= float(similarity) <= 1
main.save_similarity_to_file(output_file, similarity)
with open(output_file, 'r', encoding='utf-8') as f:
result = f.read()
assert result == str(round(similarity, 2))
def test_missing_arguments(self):
"""
测试点 5.2:模拟缺少命令行参数的情况
预期:退出码非正常
"""
orig_file = './test_text/orig.txt'
plagiarism_file = './test_text/orig_0.8_add.txt'
output_file = './test_text/orig_output.txt'
# 使用 os.system 运行命令,少传递一个参数来模拟缺少参数的情况
exit_code = os.system(f'python main.py {orig_file} {plagiarism_file}')
# 预期程序返回非零状态码,因为命令行参数不足
assert exit_code != 0 # os.system() 返回的非零代码表示错误
def test_extra_arguments(self):
"""
测试点 5.3:模拟多于3个命令行参数的情况
预期:退出码非正常
"""
orig_file = './test_text/orig.txt'
plagiarism_file = './test_text/orig_0.8_add.txt'
extra_file = "./test_text/orig_0.8/del.txt"
output_file = './test_text/orig_output.txt'
# 使用 os.system 运行命令,多传递一个参数来模拟过多参数的情况
exit_code = os.system(f'python main.py {orig_file} {plagiarism_file} {extra_file} {output_file}')
# 预期程序返回非零状态码,因为命令行参数过多
assert exit_code != 0 # os.system() 返回的非零代码表示错误
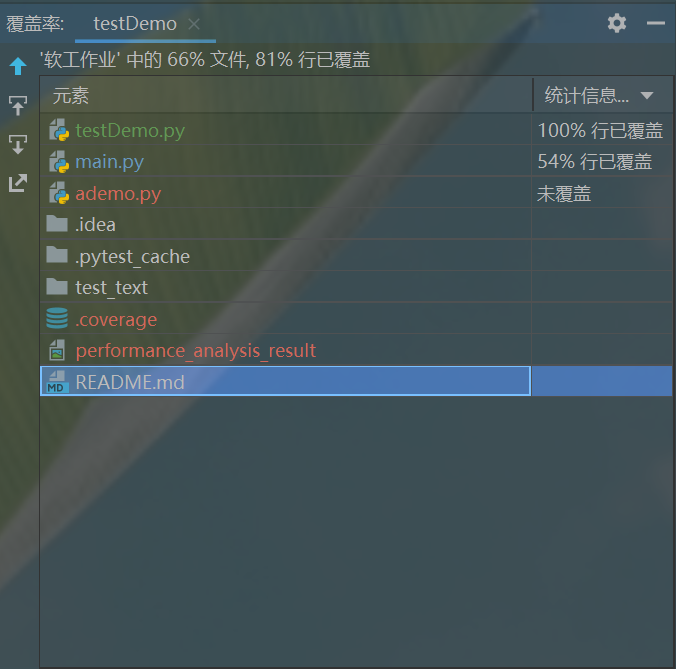
覆盖率
五、异常处理
- 读取出错异常
FileNotFoundError
原因分析:文件路径错误或文件不存在
处理结果:提醒用户出错原因和出错文件名。
def read_file(file_path):
if not os.path.exists(file_path):
raise FileNotFoundError(f"文件路径错误或文件不存在: {file_path}")
try:
with open(file_path, 'r', encoding='utf-8') as f:
return f.read()
except Exception as e:
raise IOError(f"读取文件时出错: {e}")

- 写入异常
IOError
原因分析:由于权限问题无法进行写入
处理结果:提醒用户写入出错。
def save_similarity_to_file(output_file, similarity):
"""
将相似度结果保存到指定文件,保留两位小数
"""
try:
with open(output_file, 'w', encoding='utf-8') as f:
f.write(f"{similarity:.2f}")
except Exception as e:
raise IOError(f"写入文件时出错: {e}")

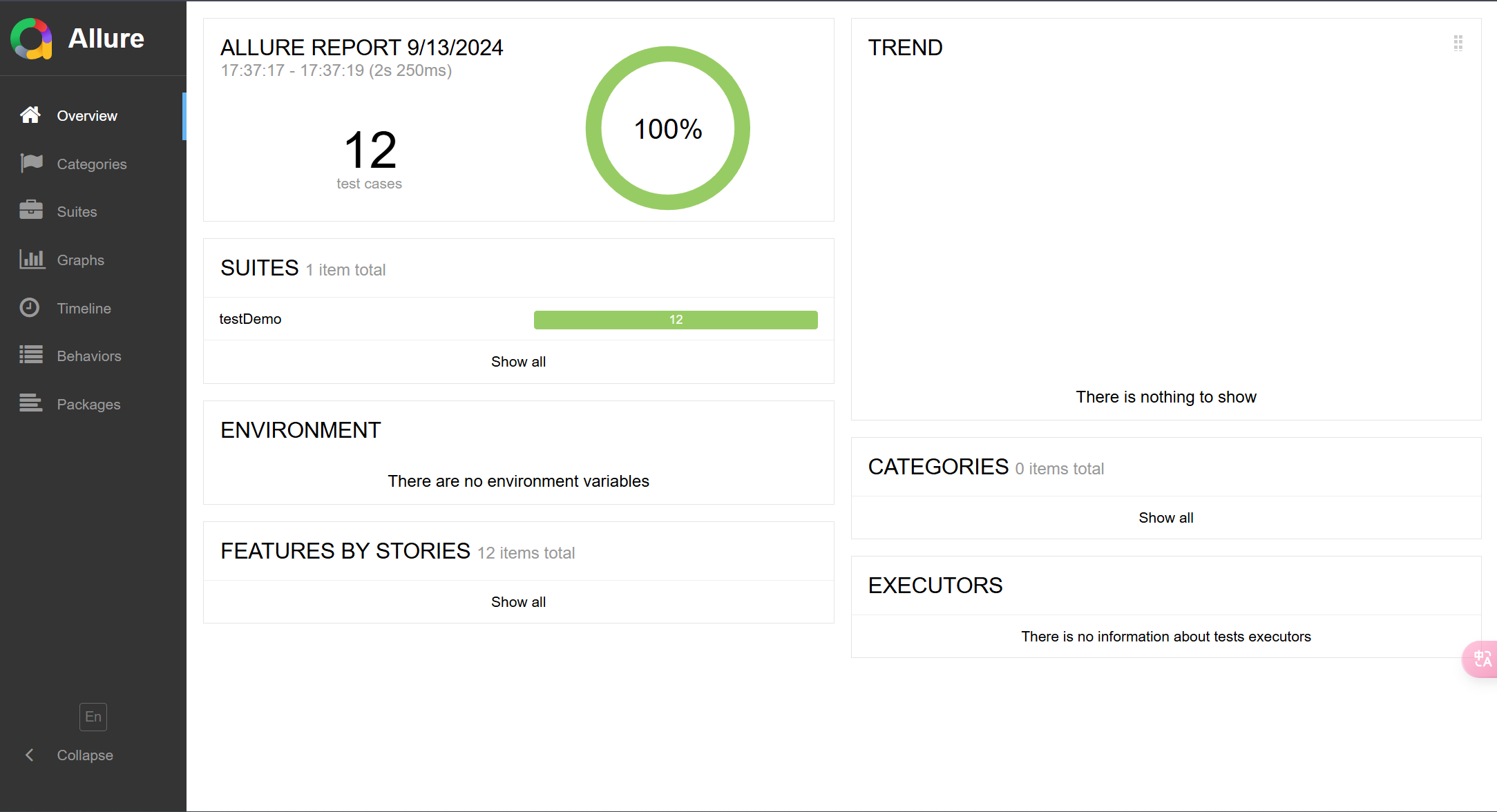
六、测试报告
使用allure生成测试报告如图
# 命令行输入
pytest main.py --alluredir result
# 最后一个路径指定了json文件输出的目录
allure generate result -o resport_allure --clean
# 从json文件路径中提取数据,输出一个html网页到指定路径
allure open resport_allure
# 打开测试报告网页

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步