分布式系统关注点(21)——构建「易测试」系统的“六脉神剑”
如果第二次看到我的文章,欢迎右侧扫码订阅我哟~ 👉
每周五早8点 按时送达。当然了,也会时不时加个餐~
这篇是「分布式系统理论」系列的第20篇。提前预告一下,后面还有一篇文章,这个系列就结束了。
在之前,核心的概念都讲的差不多了。前面Z哥带你已经聊过了「数据一致性」、「高可用」、「易扩展」、「高性能」主题下的一些实践思路。
这篇讲怎么构建一个「易测试」的系统。
作为一位开发人员,可能一听到测试就想关掉这篇文章了。那我只能说too young,too naive。
作为关注我这个号的“跨界者“们,你不能将自己的边界划的太清楚,特别在当下这个变化越来越快、适者生存的时代。要活的像“水”一样,与所处的环境结合的更紧密。
除此之外,测试工作并不是单单测试人员的事,开发人员是不是编写了一个易测试的系统也至关重要。
在Z哥我过去的几年coding经验中,总结了六点认为有助于构建出一个易测试的系统建议,在这里分享给你。
第一点,分层。分层其实除了之前聊到的「易扩展」之外,对于测试工作的进行也是有很大帮助,规模越大的系统越是如此。
脑子里想象一下,一条业务线好比一根管道,每一次的业务操作会经历整根管道的流转最终到达终点。
往往很多时候,其实我们已经定位到了问题可能产生的范围,但是由于项目没有做好分层,导致每一次的测试工作不得不“从头开始”。这是多么痛苦的一件事。
做好分层只要记住一个概念就行,「高内聚低耦合」。具体可以参考之前的文章,文末放链接。
第二点,无状态。前面的文章里说过,满足无状态的功能点意味着可以动态的进行扩容而不用考虑“状态丢失”问题。其实同时它也支持了一种测试场景,就是「容量规划」。
为了支撑业务的不断发展以及不定期举行的大型活动,我们需要清楚的知道,到底部署多少台机器为宜。
当然,你也可以选择拍脑袋的方式进行,尽量多加一些就好了。但这不是一个科学的方法,也容易造成更多的浪费。
进行容量规划的过程就好比通过水龙头装水到一组杯子里。比如,你现在的要求是1分钟装入3L水,那么通过不断的调整杯子的数量和大小,理想情况是刚刚好达到这个要求为宜。
如果此时支持无状态,那么整个过程中水龙头一直开着就好了,你只要专心调整杯子的数量和大小就行。做好无状态具体也可以参考之前的文章,文末放链接。
第三点,避免硬编码,尽量配置化。可能你一看到那些庞杂的配置项就头疼,但是不得不说,配置对于测试工作的开展是有很大帮助的。
反而用“眼不见为净”的方式,硬编码到逻辑代码中是“掩耳盗铃”的办法。
特别是以下这些用途的变量,尽量放到配置中去,否则每次配置的变更都需要重新打包编译代码,是多么麻烦的一件事情。
-
容量类的配置
-
次数类的配置
-
开关类的配置
-
时间类的配置
这些类型的配置之间的共同点是,没有永远正确、永远合理的配置。你要根据你当前的需求,不断的调整他们。
如果可以引入一个集中式的配置中心就更好了,这样可以不用一个个登陆服务器去修改配置。
第四点,依赖注入。如果你平时经常编写单元测试的话,对这个应该感受颇深。因为支持依赖注入的代码,更容易编写单元测试。
但它的价值还不止于此,随着系统规模越来越大,对于直接在生产环境进行故障演练需求越迫切,因为这才足够真实。
但是又要求不能对正常的业务数据产生影响,怎么做?那就只能单独准备演练数据,然后写入到单独的数据库中。
这个时候,依赖注入就起作用了。我们可以将载入数据源的地方设计成支持依赖注入的,如此一来,你就可以灵活的切换到不同的数据源,进行故障演练。
public interface IDataSource{ public string getName(int id); } public class DataSourceMysql implements IDataSource{ public string getName(int id){ // 从正常的数据库里中获取数据。 } } public class DataSourceDrill implements IDataSource{ public string getName(int id){ // 从故障演练的数据库里中获取数据。 } } public class UserBLL{ private IDataSource _database; public UserBLL(IDataSource database){ _database = database; } public void MethodA(int id){ // do something... var name = _database.getName(id); // do something... } } //以下是调用的时候 new UserBLL(new DataSourceMysql()).MethodA(id); //处理的是正常数据 new UserBLL(new DataSourceDrill()).MethodA(id); //处理的是演练数据
第五点,打日志。测试工作最终做的好不好,看的是数据,是结果。这就意味着,对一个系统要求是「可观测」的。
一个系统的运行过程怎么来观测呢?就是通过各个地方的打日志。
之前听说过一个自嘲的段子,说我们中国程序员在硅谷为什么混的没印度人好,就是因为没人家日志打的多。说明我们很多时候都在靠“直觉”做事,但直觉会经常翻车~
怎么打好日志?主要就是2个事情,「梳理」和「归类」。先梳理罗列一下各个打日志的地方,然后通过“目的”进行「归类」。
比如你是想以应对方式来归类的话,日志可以分为马上处理,定期处理,定期关注,事后排查等等。
你想以重要程度来归类的话,就是严重错误、错误、警告、普通信息等等。
【Fault】2019-05-24 09:01:07.669 | xxxxxx 【Error】2019-05-24 09:01:07.679 | xxxxxx 【Warning】2019-05-24 09:01:07.689 | xxxxxx 【Info】2019-05-24 09:01:07.699 | xxxxxx ...
记住,不要过分吝啬你的磁盘空间,那点钱不值得你用更多排查问题的时间去换。
第六点,接口版本化,并且向前兼容。用户规模越大的系统,越不能用一刀切的方式发布,需要像一滴水滴到纸上一样,缓慢的进行蔓延,进行更新。这其实也是一种试探性的测试方式。
版本管理怎么进行呢?首先你得要有一个版本管理中心,管理着不同版本之间的依赖关系。比如以下这样。
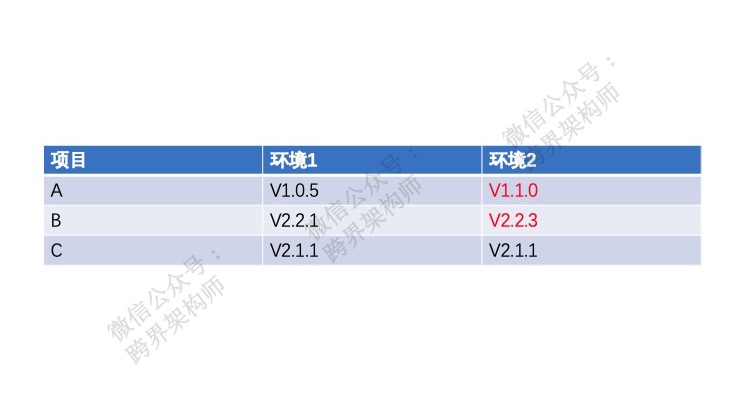
其次,你要有一个集中式的分发请求的地方。比如网关或者一些服务治理解决方案。
然后,在程序往下游系统发起请求的时候,将自己的版本号在消息头中带给网关或者服务治理框架。由他们通过上面的这个依赖关系表,路由到指定版本的服务节点上去。
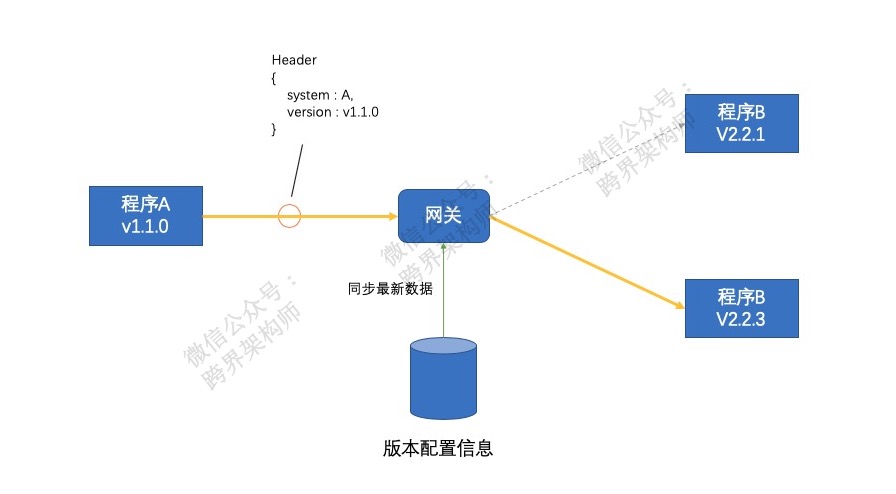
除了这个之外,你的接口实现逻辑上还需要向前兼容,否则请求是路由过来了,处理不了还是白搭。
总结一下,今天没有写什么技术性的东西,主要就是一些思路上的东西。其实,哪怕你的程序不具有「易测试性」,并不会阻碍测试工作的进行。但这并不意味着,它不重要。
你不重视它,它也不重视你,更容易给你找麻烦。谁都不希望每天都在修bug,你说是吧?

相关文章:
作者:Zachary
出处:https://zacharyfan.com/archives/744.html
如果你喜欢这篇文章,可以点一下右下角的「推荐」。
这样可以给我一点反馈。: )
谢谢你的举手之劳。
既然看到这了,送我一个「赞同」吧,支持我的创作。
想更进一步和我一起玩耍,欢迎「搜索微信公号:跨界架构师」或者在「右侧扫描」。
内容包括:架构设计丨分布式系统丨产品丨运营丨个人深度思考。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号