将上下文融入知识图谱以进行常识推理
将上下文融入知识图谱以进行常识推理
Fusing Context Into Knowledge Graph for Commonsense Reasoning 论文阅读笔记
背景:很多方法结合了预训练模型和知识图谱,但是图谱缺乏上下文,对概念和关系理解不够准确。
想法:利用外部实体描述来为图谱实体提供上下文信息。对于 CommonsenseQA 任务,主要步骤如下:
- 提取问题和选项中的概念,并找到与这些概念相关的三元组。
- 从 Wkitionary 中提取这些概念的描述,将它作为三元组的附加的输入喂给预训练模型。
Introduction
仅通过图谱描述和相邻信息推理还是不充分,但是可以直接从外部源得到准确的定义。
为了产生能无缝地整合到预训练模型的结构数据,我们需要提供每个概念在图谱中的全局视角,包括邻接概念、它们的关系以及一个明确的描述。为此作者提出了模型 DEKCOR:
DEKCOR: DE-scriptive Knowledge for COmmonsense Reasoning
-
提取包含的概念;
-
从 ConceptNet 中提取问题概念和选择概念之间的边;
如果上述的边不存在,则为每个包括选择概念的三元组计算相关分数,取分数最高的一个。
-
通过多种文本匹配准则,从 Wkitionary取出这些概念的定义。
-
将问题、选项、选择的三元组和定义喂入 Albert,相关分数在后续的注意力和 softmax 层生成。
Method
问题定义:$$G = (V, E), Q, c_1, ..., c_n$$
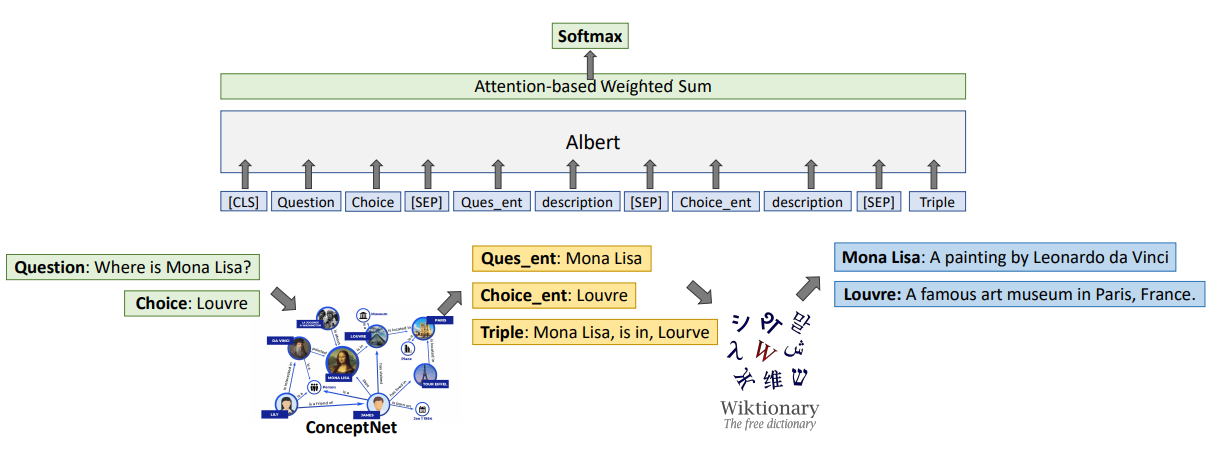
1 Knowledge Retrieval
KCR 方法找 $$e_q$$ 到 $$e_c$$ 的边,如果存在直接的边则直接选择;否则取出 N 个包含 $$e_c$$ 的三元组,对每个三元组评分:
三元组权重 $$w_j$$ ( 由 ConceptNet 提供 ),关系类型权重 $$t_{r_j}$$。关系类型权重 $$t_{r_j} = \frac{N}{N_{r_j}}$$,即所有三元组的数量和这种关系三元组的数量之比。
2 Contextual Information
对于每个向量,选择其在 Wkitionary 的第一个结果的定义。
通过如下顺序进行匹配:a) 原始形式,b) lemma form by Spacy, c) base word
e.g. takes notes 找不到,但是 lemma 形式 take notes 在里面有,如此便得到其描述 To make a record of what one hears or observes for future reference.
我们找到了所有实体的描述,问题和选择的概念的描述用 $$d_q$$ 和 $$d_c$$ 描述。
最后,以 $$[CLS]Qc_i[SEP]e_q:d_q[SEP]e_c:d_c[SEP]triple$$ 格式输入 Albert。
3 Reasoning
在 Albert 的输出($$x_0,...,x_m$$)后面接上一个基于注意力的权重求和以及一个 softmax 层来生成 question-choice 对的相关分数。
