

深度学习-情感分析
数据准备
现在我们手中有一批影评数据(IMDB 数据集),影评被分为两类:正面评价与负面评价。我们需要训练一个情感分析模型,对影评文本进行分类。
这个问题本质上还是一个文本分类问题,研究对象是电影评论类的文本,我们需要对文本进行二分类。下面我们来看一看训练数据。
IMDB(Internet Movie Database)是一个来自互联网电影数据库,其中包含了 50000 条严重两极分化的电影评论。数据集被划分为训练集和测试集,其中训练集和测试集中各有 25000 条评论,并且训练集和测试集都包含 50% 的正面评论和 50% 的消极评论。
如何用 Torchtext 读取数据集
Torchtext 是一个包含常用的文本处理工具和常见自然语言数据集的工具包。我们可以类比之前学习过的 Torchvision 包来理解它,只不过,Torchvision 包是用来处理图像的,而 Torchtext 则是用来处理文本的。
安装 Torchtext 同样很简单,我们可以使用 pip 进行安装,命令如下:
pip install torchtext
torchtext.datasets.IMDB 函数有两个参数,其中:
- root:是一个字符串,用于指定你想要读取目标数据集的位置,如果数据集不存在,则会自动下载;
- split:是一个字符串或者元组,表示返回的数据集类型,是训练集、测试集或验证集,默认是 (‘train’, ‘test’)。
torchtext.datasets.IMDB函数的返回值是一个迭代器,这里我们读取了 IMDB 数据集中的训练集,共 25000 条数据,存入了变量 train_iter 中。
import torchtext
train_iter = torchtext.datasets.IMDB(root='./data', split='train')
next(train_iter)
数据处理 pipelines
读取出了数据集中的评论文本和情绪分类,我们还需要将文本和分类标签处理成向量,才能被计算机读取。
处理文本的一般过程是先分词,然后根据词汇表将词语转换为 id。
Torchtext 为我们提供了基本的文本处理工具,包括分词器“tokenizer”和词汇表“vocab”。我们可以用下面两个函数来创建分词器和词汇表。get_tokenizer 函数的作用是创建一个分词器。
将文本喂给相应的分词器,分词器就可以根据不同分词函数的规则完成分词。例如英文的分词器,就是简单按照空格和标点符号进行分词。
build_vocab_from_iterator 函数可以帮助我们使用训练数据集的迭代器构建词汇表,构建好词汇表后,输入分词后的结果,即可返回每个词语的 id。
创建分词器和构建词汇表的代码如下。首先我们要建立一个可以处理英文的分词器 tokenizer,然后再根据 IMDB 数据集的训练集迭代器 train_iter 建立词汇表 vocab。
# 创建分词器
tokenizer = torchtext.data.utils.get_tokenizer('basic_english')
print(tokenizer('here is the an example!'))
'''
输出:['here', 'is', 'the', 'an', 'example', '!']
'''
# 构建词汇表
def yield_tokens(data_iter):
for _, text in data_iter:
yield tokenizer(text)
vocab = torchtext.vocab.build_vocab_from_iterator(yield_tokens(train_iter), specials=["<pad>", "<unk>"])
vocab.set_default_index(vocab["<unk>"])
print(vocab(tokenizer('here is the an example <pad> <pad>')))
'''
输出:[131, 9, 40, 464, 0, 0]
'''
在构建词汇表的过程中,yield_tokens 函数的作用就是依次将训练数据集中的每一条数据都进行分词处理。
另外,在构建词汇表时,用户还可以利用 specials 参数自定义词表。上述代码中我们自定义了两个词语:“
vocab.set_default_index(vocab["<unk>"])在默认情况下,未在词汇表的数据的索引被设置为词汇表中<unk> 索引。
这意味着如果有一个单词不在词汇表中由于每条影评文本的长度不同,不能直接批量合成矩阵,因此需通过截断或填补占位符来固定长度。
为了方便后续调用,我们使用分词器和词汇表来建立数据处理的 pipelines。文本 pipeline 用于给定一段文本,返回分词后的 id。标签 pipeline 用于将情绪分类转化为数字,即“neg”转化为 0,“pos”转化为 1。
# 数据处理pipelines
text_pipeline = lambda x: vocab(tokenizer(x))
label_pipeline = lambda x: 1 if x == 'pos' else 0
print(text_pipeline('here is the an example'))
'''
输出:[131, 9, 40, 464, 0, 0 , ... , 0]
'''
print(label_pipeline('neg'))
'''
输出:0
'''
生成训练数据
有了数据处理的 pipelines,接下来就是生成训练数据,也就是生成 DataLoader。
这里还涉及到一个变长数据处理的问题。我们在将文本 pipeline 所生成的 id 列表转化为模型能够识别的 tensor 时,由于文本的句子是变长的,因此生成的 tensor 长度不一,无法组成矩阵。这时,我们需要限定一个句子的最大长度。例如句子的最大长度为 256 个单词,那么超过 256 个单词的句子需要做截断处理;不足 256 个单词的句子,需要统一补位,这里用“/”来填补。
上面所说的这些操作,我们都可以放到 collate_batch 函数中来处理。
它负责在 DataLoad 提取一个 batch 的样本时,完成一系列预处理工作:包括生成文本的 tensor、生成标签的 tensor、生成句子长度的 tensor,以及上面所说的对文本进行截断、补位操作。所以,我们将 collate_batch 函数通过参数 collate_fn 传入 DataLoader,即可实现对变长数据的处理
# 生成训练数据
import torch
import torchtext
from torch.utils.data import DataLoader
from torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def collate_batch(batch):
max_length = 256
pad = text_pipeline('<pad>')
label_list, text_list, length_list = [], [], []
for (_label, _text) in batch:
label_list.append(label_pipeline(_label))
processed_text = text_pipeline(_text)[:max_length]
length_list.append(len(processed_text))
text_list.append((processed_text+pad*max_length)[:max_length])
label_list = torch.tensor(label_list, dtype=torch.int64)
text_list = torch.tensor(text_list, dtype=torch.int64)
length_list = torch.tensor(length_list, dtype=torch.int64)
return label_list.to(device), text_list.to(device), length_list.to(device)
train_iter = torchtext.datasets.IMDB(root='./data', split='train')
train_dataset = to_map_style_dataset(train_iter)
num_train = int(len(train_dataset) * 0.95)
split_train_, split_valid_ = random_split(train_dataset,
[num_train, len(train_dataset) - num_train])
train_dataloader = DataLoader(split_train_, batch_size=8, shuffle=True, collate_fn=collate_batch)
valid_dataloader = DataLoader(split_valid_, batch_size=8, shuffle=False, collate_fn=collate_batch)
我们一起梳理一下代码的流程,一共是五个步骤。
- 利用 torchtext 读取 IMDB 的训练数据集,得到训练数据迭代器;
- 使用 to_map_style_dataset 函数将迭代器转化为 Dataset 类型;
- 使用 random_split 函数对 Dataset 进行划分,其中 95% 作为训练集,5% 作为验证集;4. 生成训练集的 DataLoader;
- 生成验证集的 DataLoader。
到此为止,数据部分已经全部准备完毕了,接下来我们来进行网络模型的构建。
模型构建
RNN 自身的结构问题,在进行反向传播时,容易出现梯度消失或梯度爆炸。LSTM 网络在 RNN 结构的基础上进行了改进,通过精妙的门控制将短时记忆与长时记忆结合起来,一定程度上解决了梯度消失与梯度爆炸的问题。我们使用 LSTM 网络来进行情绪分类的预测。
模型的定义如下。
# 定义模型
class LSTM(torch.nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers, bidirectional,
dropout_rate, pad_index=0):
super().__init__()
self.embedding = torch.nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_index)
self.lstm = torch.nn.LSTM(embedding_dim, hidden_dim, n_layers, bidirectional=bidirectional,
dropout=dropout_rate, batch_first=True)
self.fc = torch.nn.Linear(hidden_dim * 2 if bidirectional else hidden_dim, output_dim)
self.dropout = torch.nn.Dropout(dropout_rate)
def forward(self, ids, length):
embedded = self.dropout(self.embedding(ids))
packed_embedded = torch.nn.utils.rnn.pack_padded_sequence(embedded, length, batch_first=True,
enforce_sorted=False)
packed_output, (hidden, cell) = self.lstm(packed_embedded)
output, output_length = torch.nn.utils.rnn.pad_packed_sequence(packed_output)
if self.lstm.bidirectional:
hidden = self.dropout(torch.cat([hidden[-1], hidden[-2]], dim=-1))
else:
hidden = self.dropout(hidden[-1])
prediction = self.fc(hidden)
return prediction
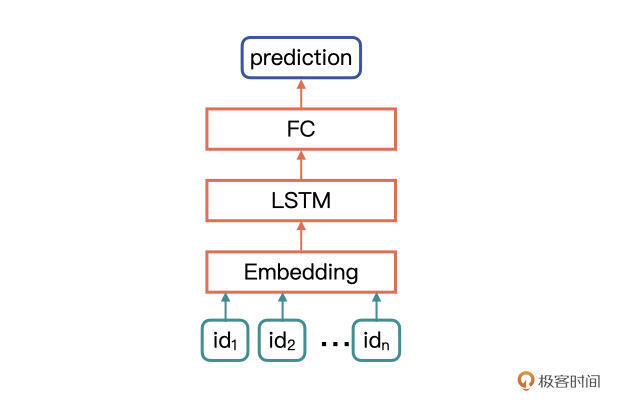
网络模型的具体结构,首先是一个 Embedding 层,用来接收文本 id 的 tensor,然后是 LSTM 层,最后是一个全连接分类层。其中,bidirectional 为 True,表示网络为双向 LSTM,bidirectional 为 False,表示网络为单向 LSTM。
模型训练与评估
vocab_size = len(vocab)
embedding_dim = 300
hidden_dim = 300
output_dim = 2
n_layers = 2
bidirectional = True
dropout_rate = 0.5
model = LSTM(vocab_size, embedding_dim, hidden_dim, output_dim, n_layers, bidirectional, dropout_rate)
model = model.to(device)
由于数据的情感极性共分为两类,因此这里我们要把 output_dim 的值设置为 2。
接下来是定义损失函数与优化方法,代码如下。在之前的课程里也多次讲过了,所以这里不再重复。
lr = 5e-4
criterion = torch.nn.CrossEntropyLoss()
criterion = criterion.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
# 计算 loss 的代码如下
import sys
import numpy as np
def train(dataloader, model, criterion, optimizer, device):
model.train()
epoch_losses = []
epoch_accs = []
for batch in tqdm.tqdm(dataloader, desc='training...', file=sys.stdout):
(label, ids, length) = batch
label = label.to(device)
ids = ids.to(device)
length = length.to(device)
prediction = model(ids, length)
loss = criterion(prediction, label) # loss计算
accuracy = get_accuracy(prediction, label)
# 梯度更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_losses.append(loss.item())
epoch_accs.append(accuracy.item())
return epoch_losses, epoch_accs
def evaluate(dataloader, model, criterion, device):
model.eval()
epoch_losses = []
epoch_accs = []
with torch.no_grad():
for batch in tqdm.tqdm(dataloader, desc='evaluating...', file=sys.stdout):
(label, ids, length) = batch
label = label.to(device)
ids = ids.to(device)
length = length.to(device)
prediction = model(ids, length)
loss = criterion(prediction, label) # loss计算
accuracy = get_accuracy(prediction, label)
epoch_losses.append(loss.item())
epoch_accs.append(accuracy.item())
return epoch_losses, epoch_accs
tqdm.tqdm :这段代码使用了tqdm库中的 tqdm()函数来显示PyTorch数据加载器(dataloader)的进度条。这可以让您在训练模型时实时跟踪进度,并知道训练还需要多长时间才能完成。
具体地说,这行代码会将dataloader传递给tqdm()函数,将描述文本设置为“training...”,并将输出文件设置为标准输出流(sys.stdout)。然后,它将返回一个可迭代对象(iterator),您可以在循环中使用该对象来遍历数据加载器并显示进度条。
请注意,此代码是在Python中使用的,因此必须先在代码中导入tqdm和sys库:
可以看到,这里训练过程与验证过程的 loss 计算,分别定义在了 train 函数和 evaluate 函数中。
主要区别是训练过程有梯度的更新,而验证过程中不涉及梯度的更新,只计算 loss 即可。
模型的评估我们使用 ACC,也就是准确率作为评估指标,计算 ACC 的代码如下。
def get_accuracy(prediction, label):
batch_size, _ = prediction.shape
predicted_classes = prediction.argmax(dim=-1)
correct_predictions = predicted_classes.eq(label).sum()
accuracy = correct_predictions / batch_size
return accuracy
最后,训练过程的具体代码如下。包括计算 loss 和 ACC、保存 losses 列表和保存最优模型。
best_valid_loss = float('inf')
train_losses = []
train_accs = []
valid_losses = []
valid_accs = []
for epoch in range(n_epochs):
train_loss, train_acc = train(train_dataloader, model, criterion, optimizer, device)
valid_loss, valid_acc = evaluate(valid_dataloader, model, criterion, device)
train_losses.extend(train_loss)
train_accs.extend(train_acc)
valid_losses.extend(valid_loss)
valid_accs.extend(valid_acc)
epoch_train_loss = np.mean(train_loss)
epoch_train_acc = np.mean(train_acc)
epoch_valid_loss = np.mean(valid_loss)
epoch_valid_acc = np.mean(valid_acc)
if epoch_valid_loss < best_valid_loss:
best_valid_loss = epoch_valid_loss
torch.save(model.state_dict(), 'lstm.pt')
print(f'epoch: {epoch+1}')
print(f'train_loss: {epoch_train_loss:.3f}, train_acc: {epoch_train_acc:.3f}')
print(f'valid_loss: {epoch_valid_loss:.3f}, valid_acc: {epoch_valid_acc:.3f}')
我们还可以利用保存下来 train_losses 列表,绘制训练过程中的 loss 曲线,或使用第 15 课讲过的可视化工具来监控训练过程。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南