第三次寒假作业
爬虫实战:爬取豆瓣热评
| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/Freshman/ |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/Freshman/homework/11734 |
| 作业目标 | <学习爬虫,并养成使用Git 进行源代码管理的习惯> |
| 作业源代码 | <> |
| 学号 | <212003180> |
前期准备工作
首先是了解如何采集数据我通过以下几个博主的分享对网络爬虫有了初步的了解
Python网络爬虫数据采集实战:基础知识
一个简单的网站爬虫教程,让你了解爬虫的步骤,爬虫网页数据采集
Python爬虫入门教程!手把手教会你爬取网页数据
开始数据采集需要的开发平台和环境
windows
pycharm
对于新人来说安装各种各样的模块就是一大关,我们一般都是通过Pycharm或者PIP安装的,但是在安装时总是会提示错误,如下:
有些图忘记保存了🤣
这里附上我解决这些问题所用的方法:
刚开始因为不知道Pycharm上的库要重新安装,所以一直在用pip安装但是一直不行,提示我要更新pip,
在网上找了各种方法都没用,后来我就试着把我的3.8的版本换成3.9的终于欧克了。
在pycharm上有些库也安装不了,我用的这个方法解决的
python成功安装jieba库,但是pycharm中无法识别jieba的解决方法
爬虫实战:爬取豆瓣热评
爬取对象:你好,李焕英
一、抓取网页数据
第一步要对网页进行访问,使用的是requests库。代码如下
# requests响应
r = requests.get(url=url, headers=head)
# 设置编码
r.encoding = "utf-8"
html = r.text
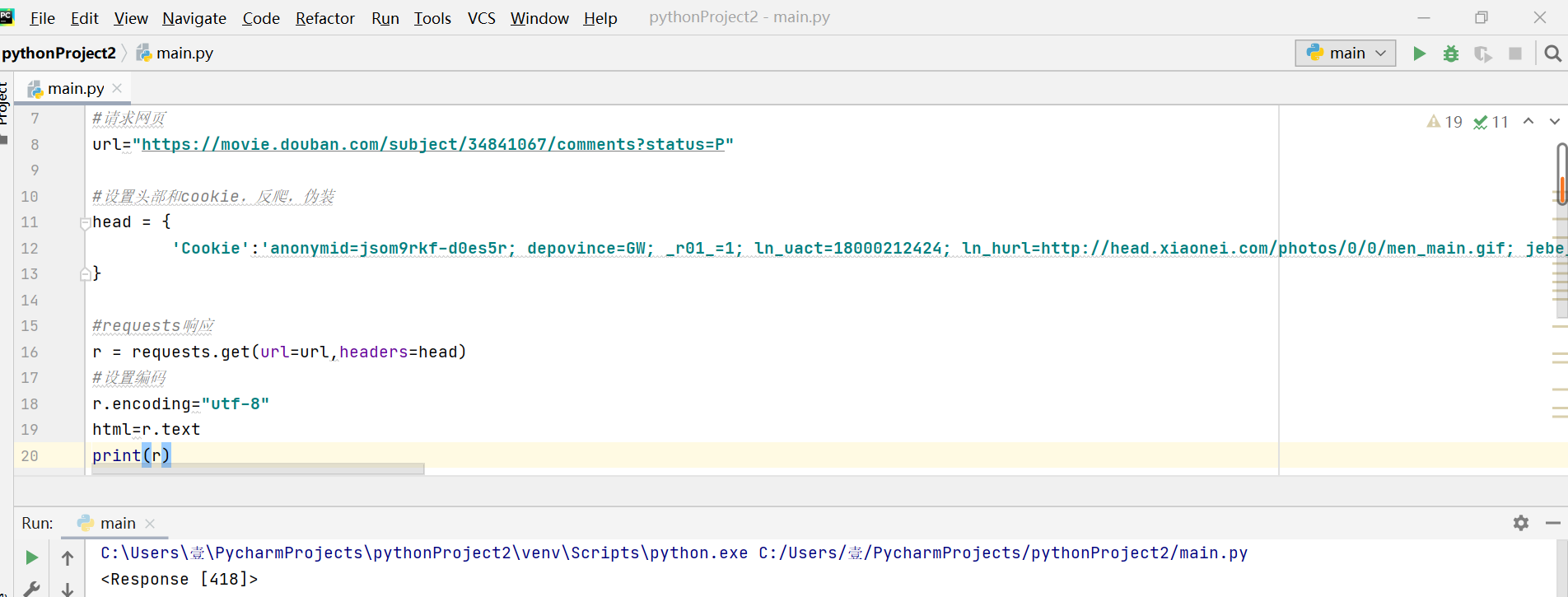
遇到这种情况print(r)得到<Response [418]>请求成功的话应该是<Response [200]>
百度了解到这是所访问的网站有反爬机制
但是我已经伪装了啊
百度得到的建议 选择先 登陆 豆瓣网站,再更新网站元素(F5刷新),再次复制Cookies
print(r)
第二步,需要对得到的html代码进行解析,得到里面提取我们需要的数据。
对目标网站进行分析
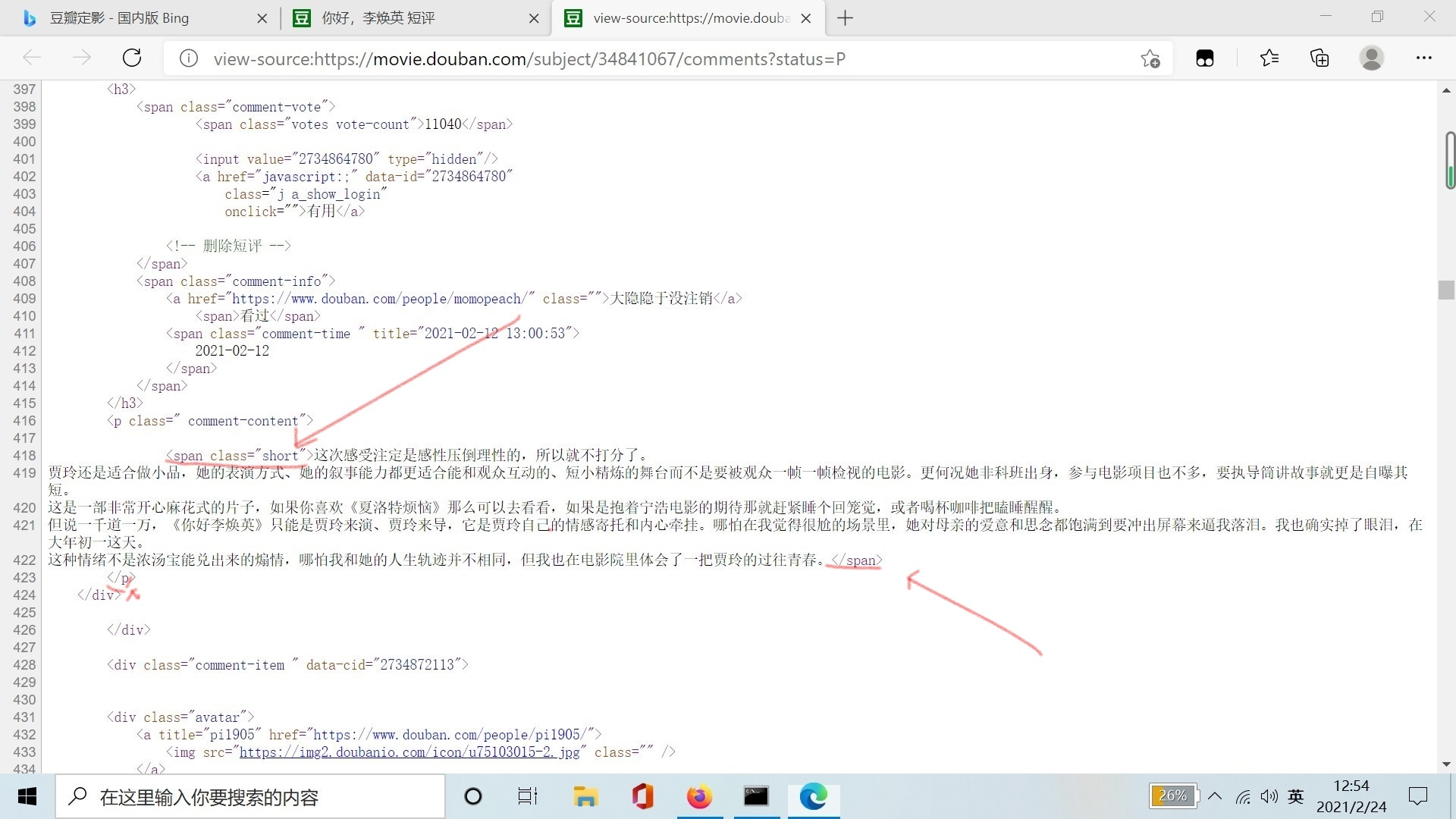
发现短评存放在<span class="short">和</span>之间,所以需要爬取其里边的内容。
正则表达式筛选(提取所需要信息)notice_types = re.findall(r'<span class="short">(.*?)</span>', html)
提取到这一页的评论信息

但是这只是第一页的信息,我们分析前几页的 url
https://movie.douban.com/subject/34841067/comments?start=20&limit=20&status=P&sort=new_score
https://movie.douban.com/subject/34841067/comments?start=40&limit=20&status=P&sort=new_score
https://movie.douban.com/subject/34841067/comments?start=60&limit=20&status=P&sort=new_score
发现每翻一页 start= 就增加 20
所以通过改变 start 的值就可以爬取多个网页了
这里使用采用 for 循环语句控制页数
for i in range(1, page + 1):
url = 'https://movie.douban.com/subject/34841067/comments?start=%s&limit=20&sort=new_score&status=P' \
% ((i - 1) * 20)
打印下 url 发现有多个url被打印出来,成功
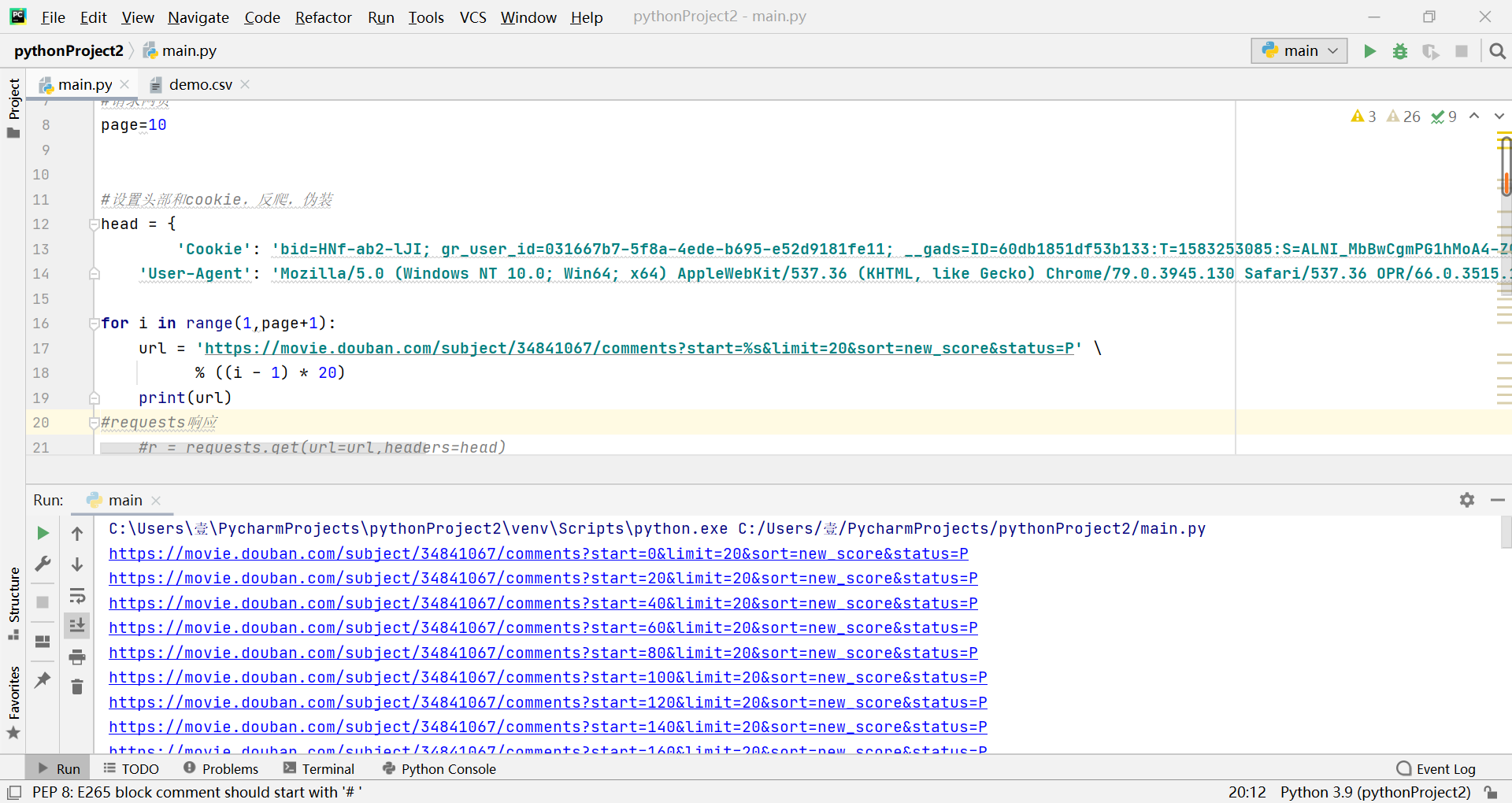
数据已经提取成功,接下来要进行词频统计,所以先要进行中文分词操作。在这里我使用的是结巴分词。
comments = []
with open('demo.csv','r',encoding="utf-8")as csvfile:
data = csvfile.readlines()
for item in data:
#print(item)
comments.append(item)
comment_after_split = jieba.cut(str(comments))
words = ' '.join(comment_after_split)
三、用词云进行显示
代码如下:
import jieba
import os
def drwawordcloud(title, savapath='/images'):
if not os.path.exists(savapath):
os.mkdir(savapath)
wc = WordCloud(font_path='simkai.ttf',background_color='white', max_words=20000, width=1920, height=1080'))
#根据文本生成词云
wc.generate_from_text(words)
filepath = savapath + '/'+title + ',png'
wc.to_file(filepath)
drwawordcloud('demo')
获取词云后发现有好多无效词
我们需要进行下数据清洗
先到这,还不会数据清洗😶,后面再更新。
更新来了
lastwords = ''
for word in comment_after_split: # for循环遍历分词后的每个词语
if word not in stopwords and len(word) > 1: # 判断分词后的词语是否在停用词表内,且len长度是否大于1
if word != '\t':
lastwords += word
lastwords += "/"
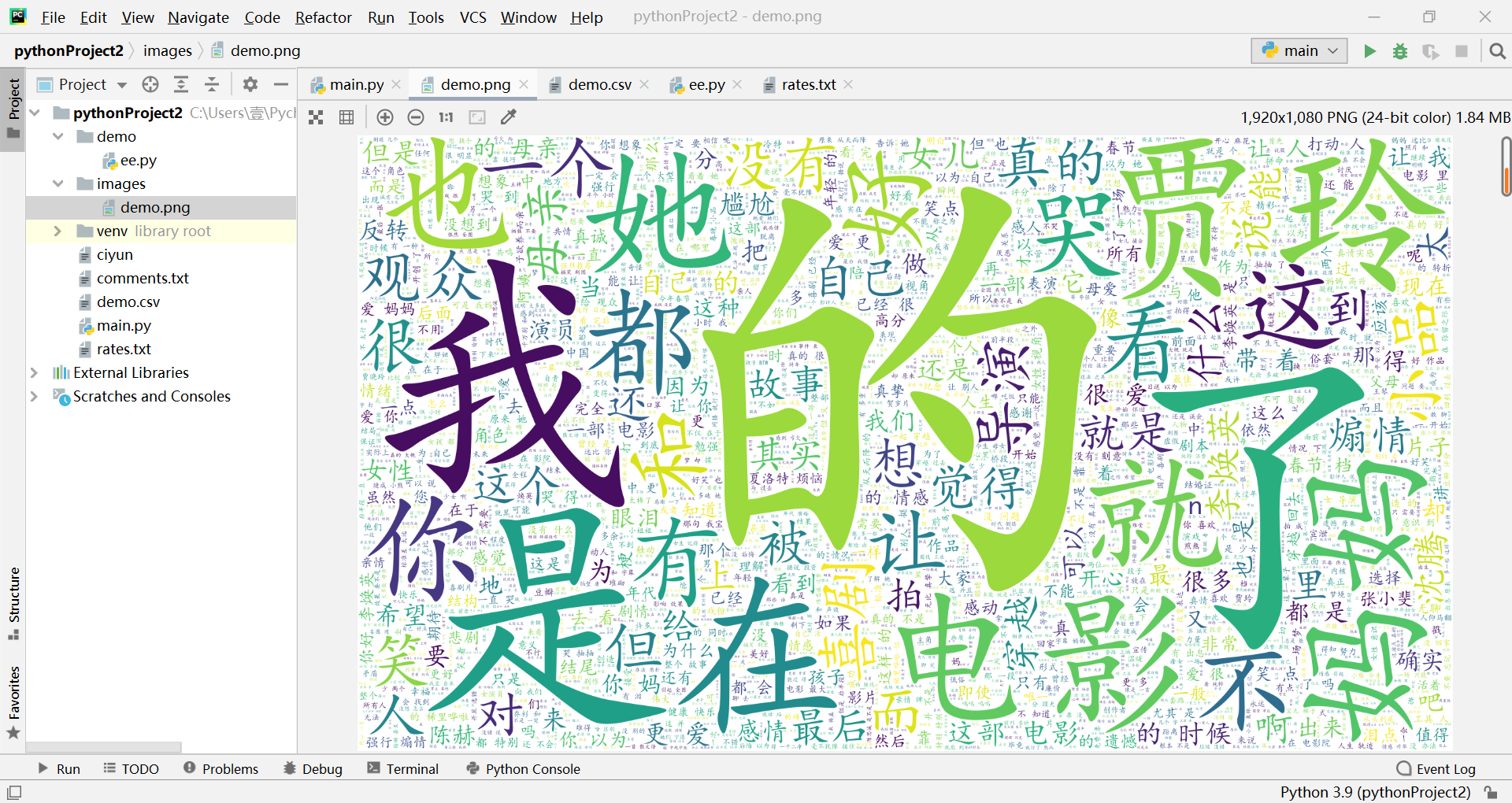
清洗后再生成的词云

完整的代码
import csv
import requests
import re
# 设置头部和cookie,反爬,伪装
head = {
'Cookie': 'bid=HNf-ab2-lJI; gr_user_id=031667b7-5f8a-4ede-b695-e52d9181fe11; __gads=ID=60db1851df53b133:T=1583253085:S=ALNI_MbBwCgmPG1hMoA4-Z0HSw_zcT0a0A; _vwo_uuid_v2=DD32BB6F8D421706DCD1CDE1061FB7A45|ef7ec70304dd2cf132f1c42b3f0610e7; viewed="1200840_27077140_26943161_25779298"; ll="118165"; __yadk_uid=5OpXTOy4NkvMrHZo7Rq6P8VuWvCSmoEe; ct=y; ap_v=0,6.0; push_doumail_num=0; push_noty_num=0; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1583508410%2C%22https%3A%2F%2Fwww.pypypy.cn%2F%22%5D; _pk_ses.100001.4cf6=*; dbcl2="131182631:x7xeSw+G5a8"; ck=9iia; _pk_id.100001.4cf6=17997f85dc72b3e8.1583492846.4.1583508446.1583505298.',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36 OPR/66.0.3515.115'}
# 请求网页
page = 10
for i in range(1, page + 1):
url = 'https://movie.douban.com/subject/34841067/comments?start=%s&limit=20&sort=new_score&status=P' \
% ((i - 1) * 20)
#print(url)
# requests响应
r = requests.get(url=url, headers=head)
# 设置编码
r.encoding = "utf-8"
html = r.text
# 正则表达式筛选(提取所需要信息)
notice_types = re.findall(r'<span class="short">(.*?)</span>', html)
#print(notice_types)
with open('demo.csv', 'a', newline="", encoding="utf-8-sig")as csvfile:
writer = csv.writer(csvfile)
writer.writerow(notice_types)
import os
from wordcloud import WordCloud
import jieba
comments = []
with open('demo.csv', 'r', encoding="utf-8") as csvfile: # 打开存储了评论的文本
data = csvfile.readlines() # 读取文本数据
for item in data:
# print(item)
comments.append(item)
comment_after_split = jieba.lcut(str(comments)) #jieba分词
with open('stop_words.txt', 'r', encoding="utf-8") as f: # 打开停用词文本
stopwords = f.readlines() # 读取停用词文本数据
lastwords = ''
for word in comment_after_split: # for循环遍历分词后的每个词语
if word not in stopwords and len(word) > 1: # 判断分词后的词语是否在停用词表内
if word != '\t':
lastwords += word
lastwords += ""
print(lastwords)
# 创建文件夹images
def drwawordcloud(title, savapath='./images'):
if not os.path.exists(savapath):
os.mkdir(savapath)
#词云的样式
wc = WordCloud(font_path='simkai.ttf', background_color='white', max_words=20000, width=1920, height=1080)
# 根据文本生成词云
wc.generate_from_text(lastwords)
filepath = savapath + '/' + title + '.png'
wc.to_file(filepath)
drwawordcloud('demo')
参考资料:
Python网络爬虫数据采集实战:基础知识
一个简单的网站爬虫教程,让你了解爬虫的步骤,爬虫网页数据采集
Python爬虫入门教程!手把手教会你爬取网页数据
中文分词后去除停用词


