zookeeper实现分布式锁的原理和一个小例子
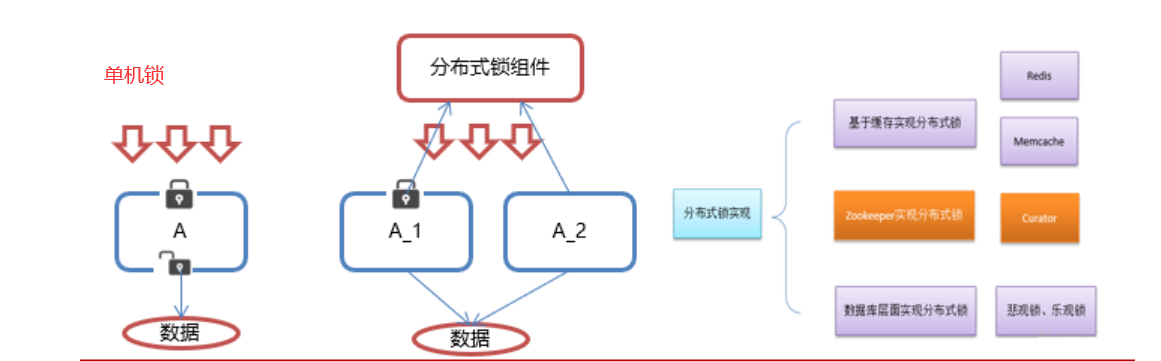
•在我们进行单机应用开发,涉及并发同步的时候,我们往往采用synchronized(同步)或者Lock的方式来解决多线程间的代码同步问题,这时多线程的运行都是在同一个JVM之下,没有任何问题。
•但当我们的应用是分布式集群工作的情况下,属于多JVM下的工作环境,跨JVM之间已经无法通过多线程的锁解决同步问题。
•那么就需要一种更加高级的锁机制,来处理这种跨机器的进程之间的数据同步问题——这就是分布式锁。
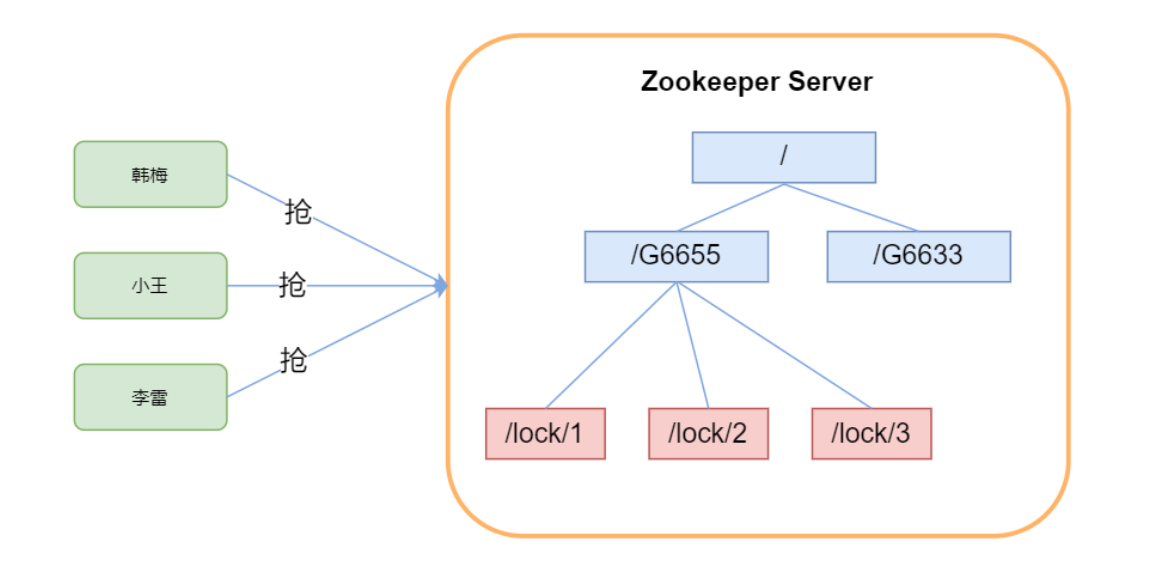
核心思想:当客户端要获取锁,则创建节点,使用完锁,则删除该节点
-
-
然后获取lock下面的所有子节点,客户端获取到所有的子节点之后,如果发现自己创建的子节点序号最小,那么就认为该客户端获取到了锁。使用完锁后,将该节点删除。
-
如果发现自己创建的节点并非lock所有子节点中最小的,说明自己还没有获取到锁,此时客户端需要找到比自己小的那个节点,同时对其注册事件监听器,监听删除事件。
-
在Curator中有五种锁方案:
- InterProcessSemaphoreMutex:分布式排它锁(非可重入锁)
- InterProcessMutex:分布式可重入排它锁
- InterProcessReadWriteLock:分布式读写锁
- InterProcessMultiLock:将多个锁作为单个实体管理的容器
- InterProcessSemaphoreV2:共享信号量
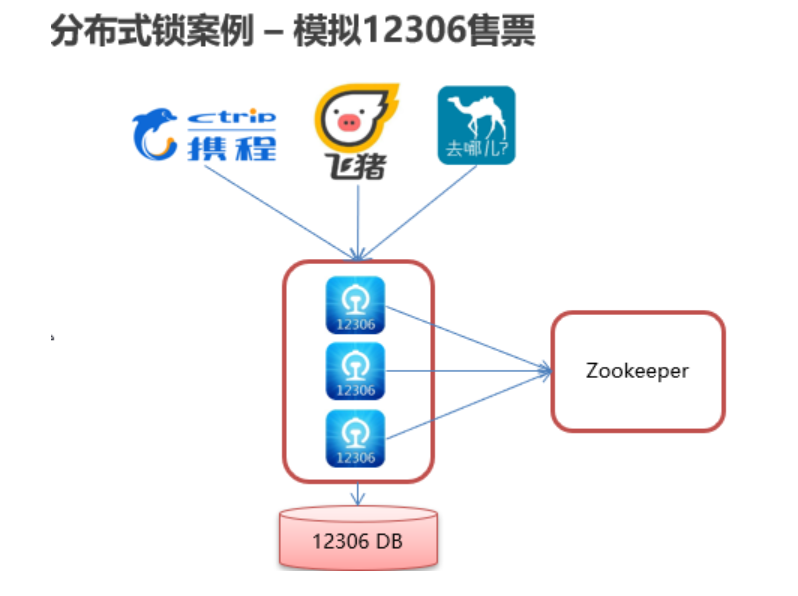
使用分布式可重入排它锁-InterProcessMutex模拟12306售票过程:
public class Ticket12306 implements Runnable{ private int tickets = 10;//数据库的票数 private InterProcessMutex lock ; @Override public void run() { while(true){ //获取锁 try { lock.acquire(3, TimeUnit.SECONDS); if(tickets > 0){ System.out.println(Thread.currentThread()+":"+tickets); Thread.sleep(100); tickets--; } } catch (Exception e) { e.printStackTrace(); }finally { //释放锁 try { lock.release(); } catch (Exception e) { e.printStackTrace(); } } } } }
迎风少年

 浙公网安备 33010602011771号
浙公网安备 33010602011771号