关于Java中的常量优化机制
常量优化机制
在给一个变量赋值的时候,如果“=”的右边全部是常量(包括final关键字定义的常量在内)那么在编译阶段会把右边的结果赋值给左边的变量,
如果范围不超过左边的变量类型的范围(或者说属于左边的范围)那么就会赋值成功如果超过就会赋值失败。
右边如果存在变量,则不会触发常量优化机制。
Java中的常量优化机制针对数据类型byte,short,char,String
首先给出一张基本数据类型的范围图:


其中JAVA常量优化的有char,short,byte,String;
举例说明:
1 public static void main(String[] args) { 2 byte b=1; 3 byte c=2; 4 byte d=1+2;//编译通过正常执行 5 // byte e=b+c;//编译出错 6 byte e=(byte)(b+c);//强转之后不会出错 7 8 9 }
- 第4行代码:byte d=1+2;因为等号右边全部都是常量,所以就根据常量优化机制就等同于byte d=3;而3并不超过byte的取值范围,所以赋值成功。
- 第5行代码,因为等号右边含有变量b和c,而在编译时变量b和c在赋值的过程中类型会提升为int类型:
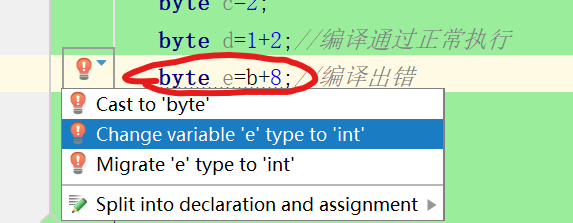
所以会出现为类型转化错误。如下图:

- 如上图等号右边只有单个变量时也会出现同样的错误。
- 如果变量被final关键字修饰,则作用相当于常量:
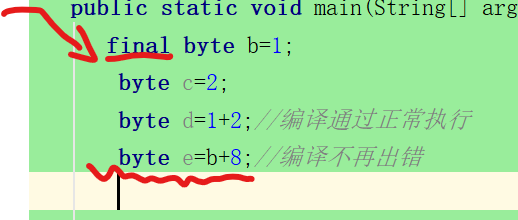
所以常量优化机制一定是针对常量的,如果有变量参与那么就不会触发常量优化机制。
另外byte,short的变量在赋值运算的时候类型会上升为int类型:

关于String的字符串常量池
String是Java开发中十分频繁被用到的类,所以java对String做了最大限度的优化,虽然是一个类,但是却和byte,short,char一样拥有自己的常量池。
先看几个String的例子:

常量优化机制的主要思想就是:如果“=”右边的内容全部都是常量(包括final关键字修饰的常量),那么在编译时期就可以运算出右边的结果,其实际就是把右边的结果赋值给左边。!!!!
那么就可以解释:上面的代码中s1="abc";此时在字符串常量池中就会存在"abc"的字符串,而s4="a"+"bc";因为等于号的右边全部都是常量,所以在编译时期就会运算出右边的结果赋值给左边,实际上就等于:
s4="abc";而因为"abc"在字符串常量池中已经存在,所以会把常量池中"abc"的引用赋值给s4,所以s4==s1比较地址值是相同的。
但是s1==(s2+s3)因为等于号右边存在变量s2和s3所以在有字符串变量和"+"的时候实际上在底层是调用的StringBuilder的append()方法进行拼接,然后调用toString();方法再变成String字符串,放在堆内存中,并不在字符串常量池,所以s1==(s2+s3)的结果是false。
看下面的代码:
1 public static void main(String[] args) { 2 String s1 = "abc1"; 3 String s2 = "abc" + 1; 4 String s3 = "abc1.1"; 5 String s4 = "abc" + 1.1; 6 String s5 = "abctrue"; 7 String s6 = "abc" + true; 8 System.out.println(s1 == s2);//true 9 System.out.println(s3 == s4);//true 10 System.out.println(s5 == s6);//true 11 12 13 }
我们可以看出:只要字符串在前,后面使用+拼接的任何长量都可以被视为加了双引号的字符串常量,然后根据字符串常量优化机制把右边的结果算出来比较字符串常量池中是否存在,不存在就添加,存在就把常量池中的引用赋值给变量

这段代码的运行结果为false:
String s8=1+2+3+"abc";因为字符串在后面所以1+2+3会先进行计算,计算结果再与"abc"进行拼接也就是"6abc";
所以结果为false;
参考博文:
https://blog.csdn.net/weixin_43465312/article/details/102640123

 浙公网安备 33010602011771号
浙公网安备 33010602011771号