
[官方培训] 01/02-虚幻引擎的实时渲染基础(上)(下) | 陈拓 Epic
传送门:
[官方培训]01-实时渲染基础上 | 陈拓 Epic_哔哩哔哩_bilibili
[官方培训]02-实时渲染基础下 | 陈拓 Epic_哔哩哔哩_bilibili
一. 实时渲染概述
1.1 实时渲染简介
- 实时渲染(Real-Time Rendering,RTR):在计算机上快速生成图像的过程,这种反应和渲染的循环以足够快的速度发生,致使看不到单帧图像,沉浸在动态过程中
- RTR 流程的本质是:管理性能损耗和画面质量的平衡(实时渲染在不渲染任何东西的时候,达到最高性能)
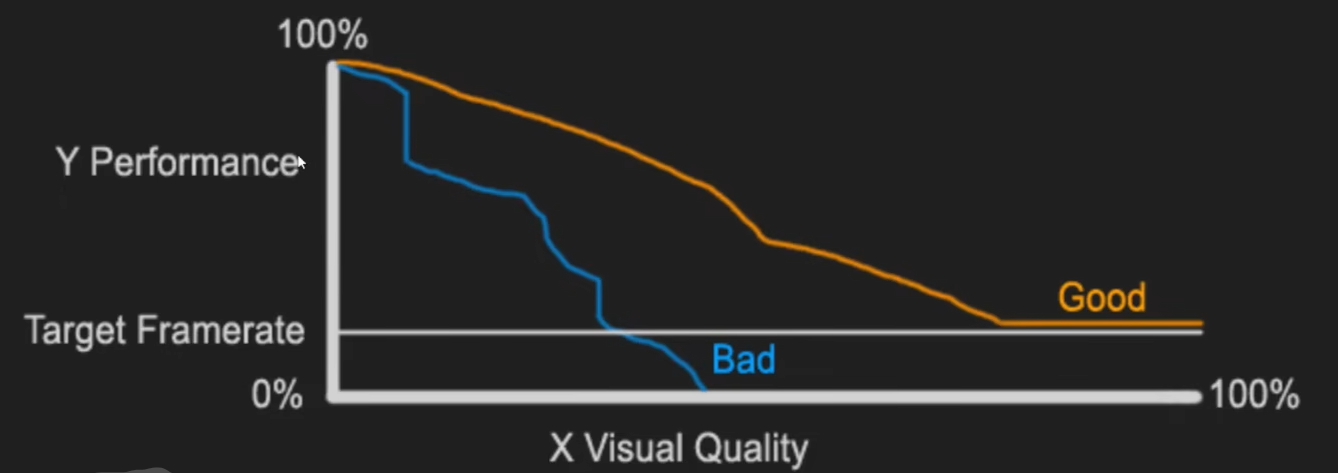
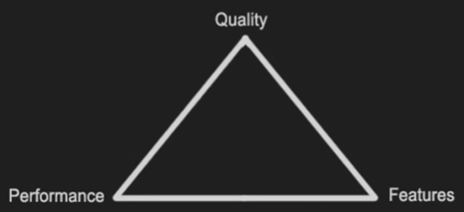
- 重点是要平衡三者:
- Performance 性能(运行流畅度)
- Quality 质量(画面好坏)
- Features 特性
- 利用实时渲染实现真实感是十分复杂的
- 所有环节需要尽可能高效
- 流程标准限制严格(如:限制图像分辨率)
- 将一部分工作分配到预先计算环节(如:烘焙)
- 需要多种方案混合工作
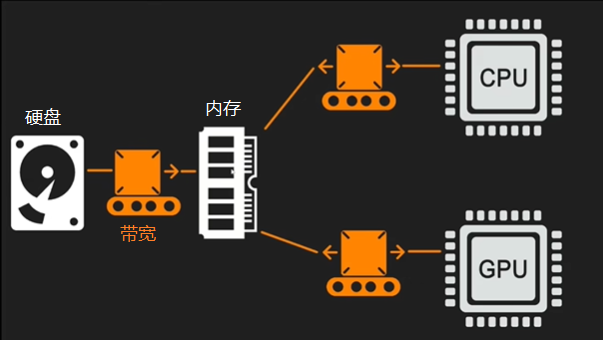
1.2 CPU和GPU
- CPU(Central Processing Unit - 中央处理器):主要功能是解释计算机指令以及处理计算机软件中的数据
- GPU(Graphics Processing Unit - 图形处理器):主要处理计算机中与图形计算有关的工作,并将数据更好地呈现在显示器中
- 二者负责处理渲染的不同部分,但大多时候是同步的,二者互相影响,有可能成为对方的瓶颈,因此需要知道双方的工作负荷是如何分配的,从而将高负荷的工作转移到低负荷上,进行合理的分配措施
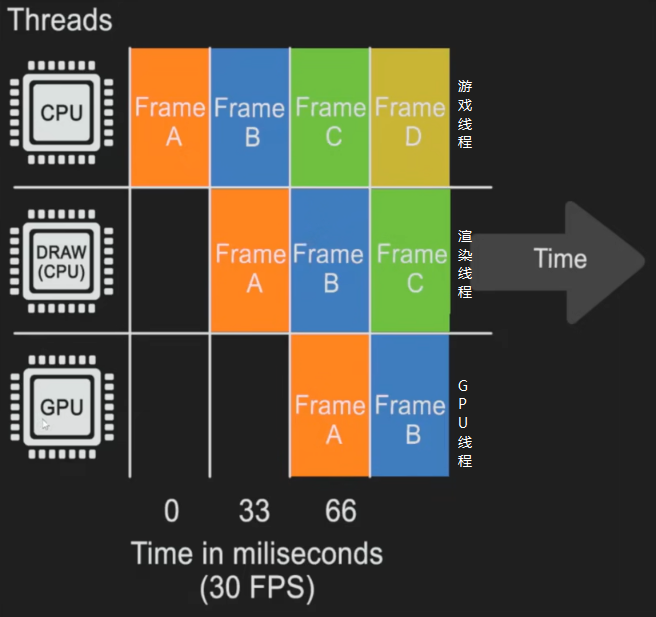
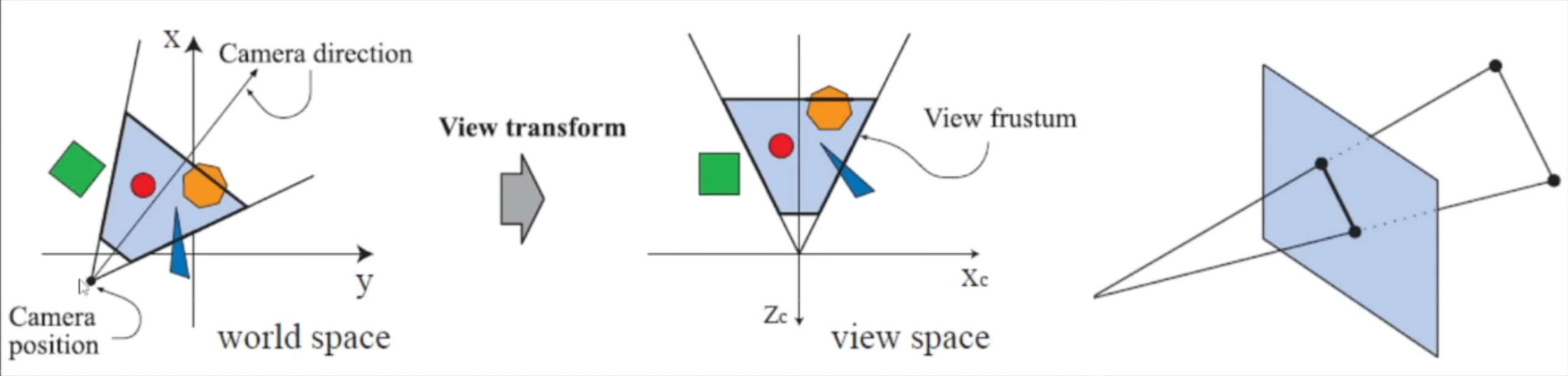
二. 渲染流程
- 此处实时渲染大部分用到的是延迟渲染(前向渲染以移动平台居多,如:手机)
- 虚幻引擎在运行时,处于多线程并行执行的状态,而与渲染息息相关的有如下 3 个线程:
- 一般渲染流程:
- 准备场景数据
- 加载模型:Mesh、Material、Shader、Texture(硬盘 --> 内存 --> 显存)
- 摄像机(位置、朝向、视锥体)
- 光源(位置、类型等参数信息)
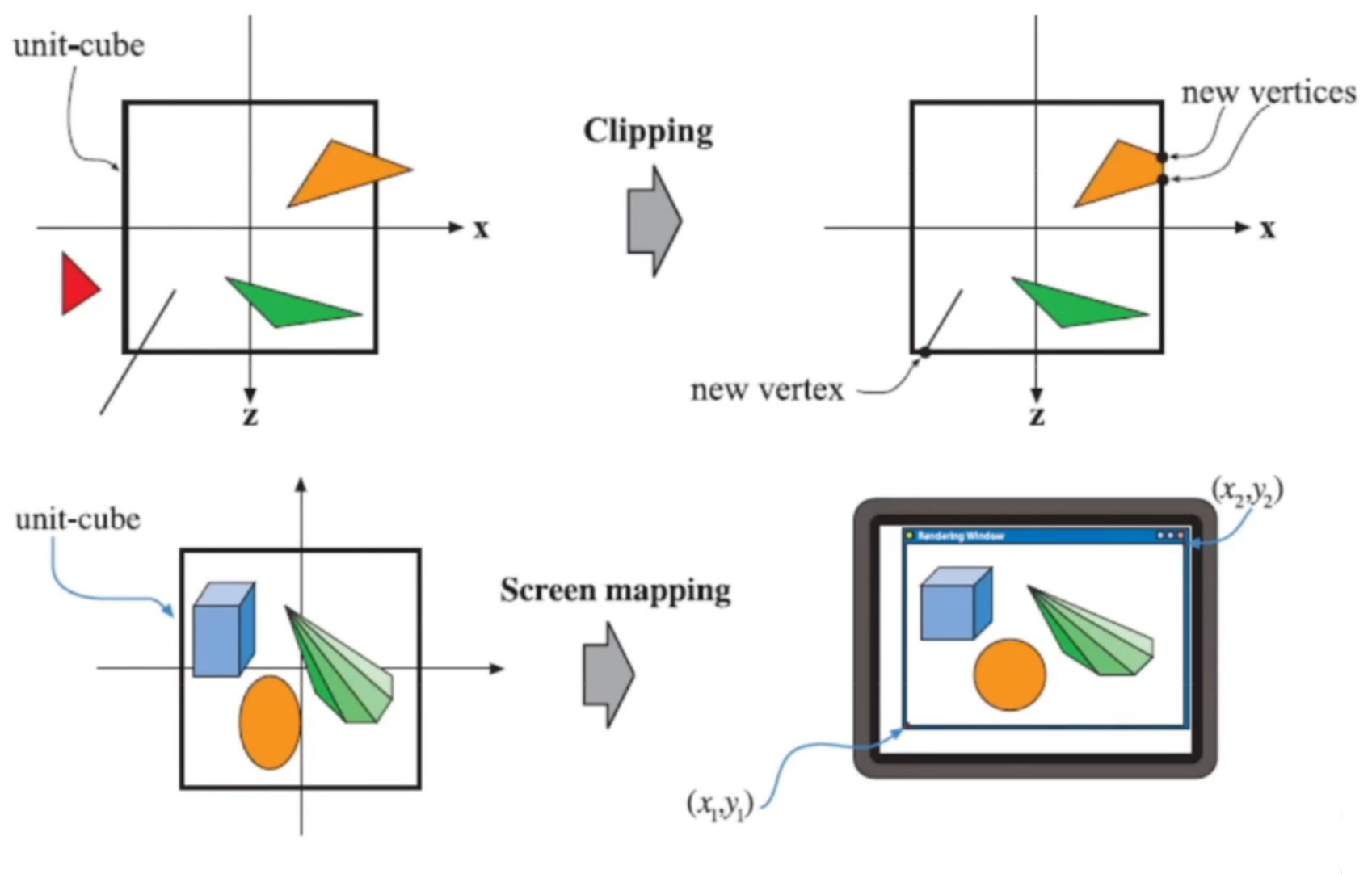
- 裁剪和剔除
- 视锥裁剪
- 背面剔除
- 遮挡剔除 (Occlusion Culling)
- 计算模型视图矩阵
- 设置渲染状态
- 包括 Shader、Texture、Material、Light 内部定义的各种状态等
2.1 第0帧 - 0毫秒 - 游戏线程(CPU)
- 开始渲染前,需要知道参与渲染的物体所在位置
- 游戏线程执行所有逻辑计算、物体变换,以及与物体位置变换相关的逻辑
- 动画
- 模型 / 物体位置
- 物理
- AI
- 生成 / 销毁,隐藏 / 显示
2.2 第1帧 - 33毫秒 - 渲染线程(大部分在CPU)
- 需要知道画面里有哪些参与渲染的物体,及其可视性(只渲染画面可见的内容)
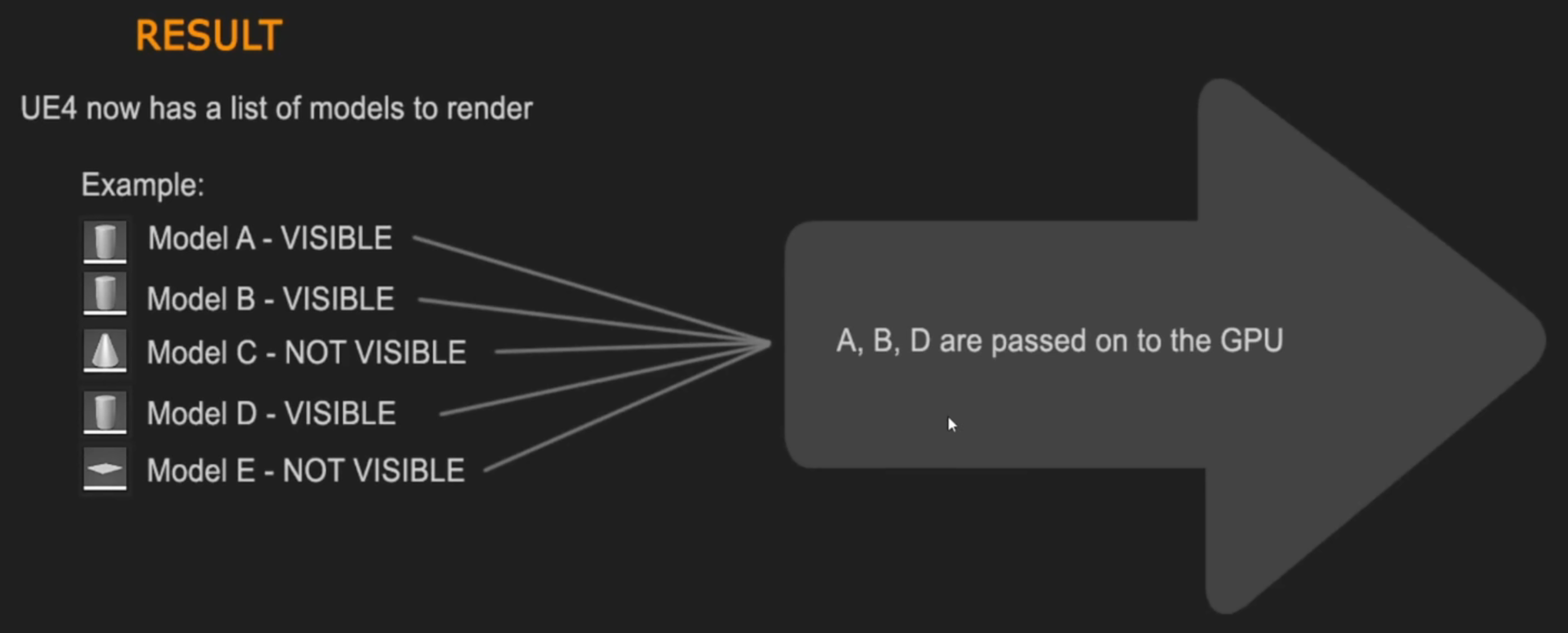
- 这部分工作,大都在 CPU 上计算,也有一部分在 GPU 上计算
- 遮挡过程:建立一个可见物体的列表(逐物体剔除不在画面的物体,而非逐三角形),四种处理过程:
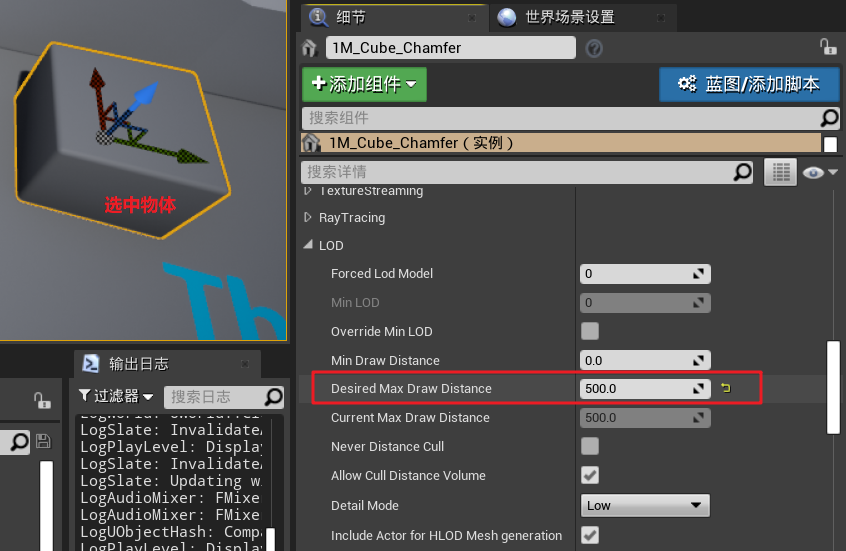
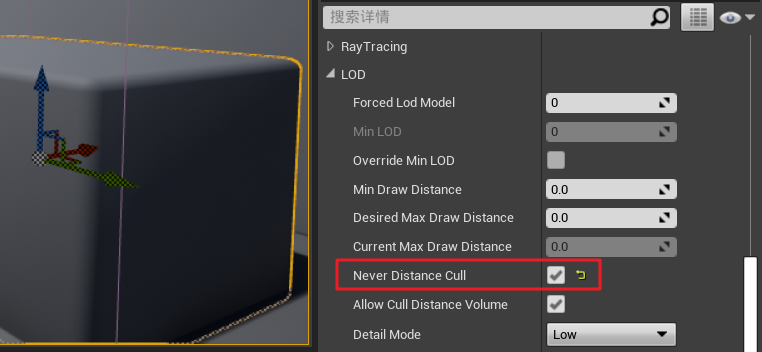
- ① 距离剔除:根据物体与相机的距离,决定是否剔除(默认未开启)
- 选中物体,设置 “距离剔除”,即超过 500cm 则剔除,不渲染不显示

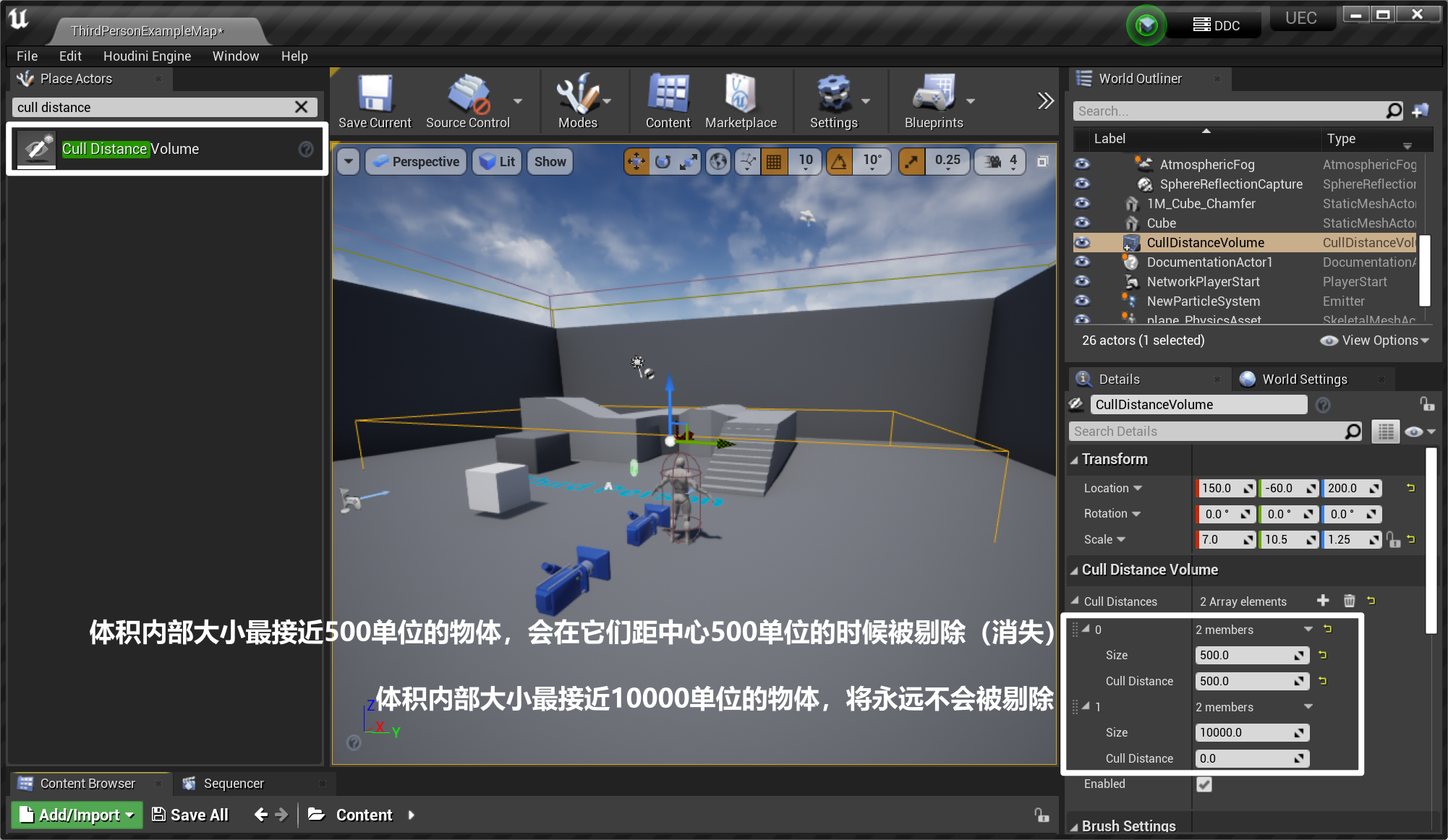
- 使用 “剔除距离体积 Cull Distance Volume”整体剔除物体,并设置属性(0-500,剔除距离500;500-10000,剔除距离500;10000以上,剔除距离0,注意:剔除距离指距相机的距离)
- 设置物体永不剔除
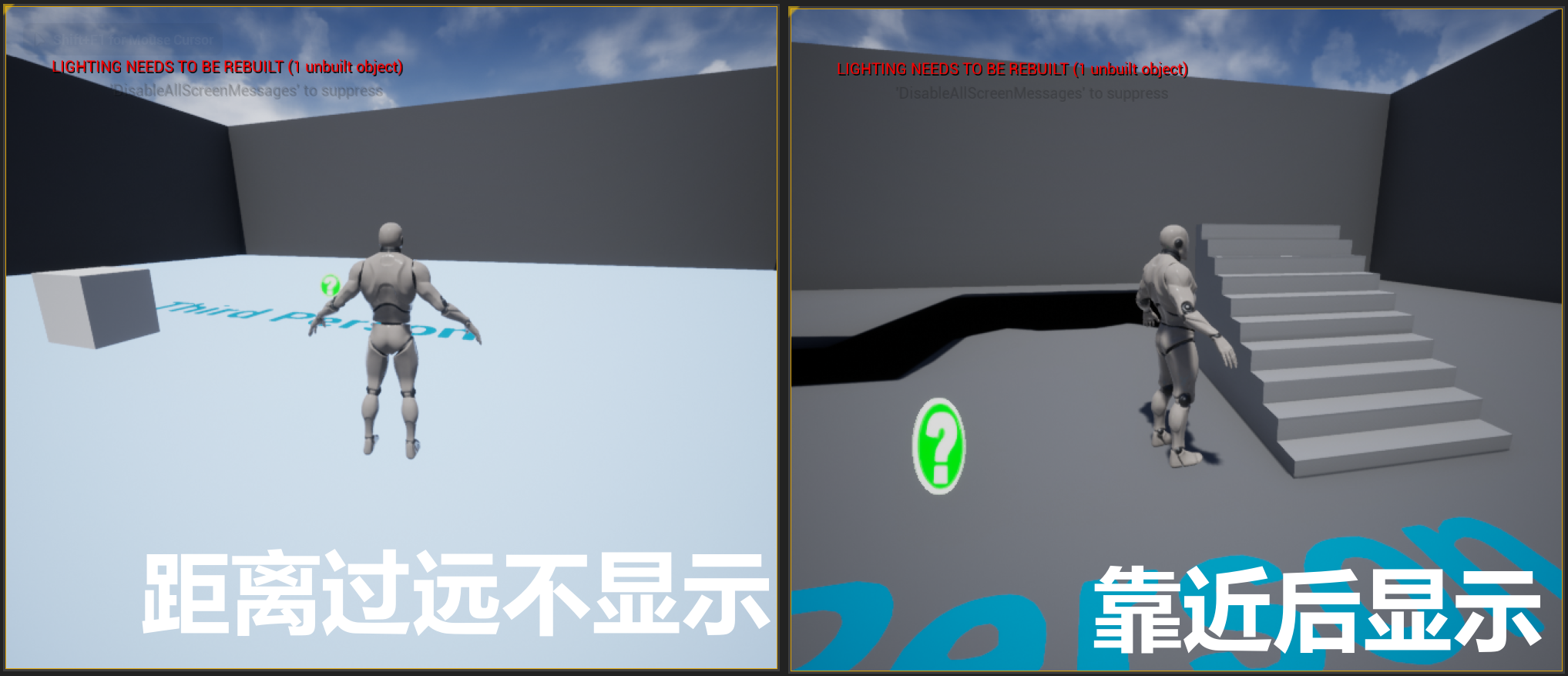
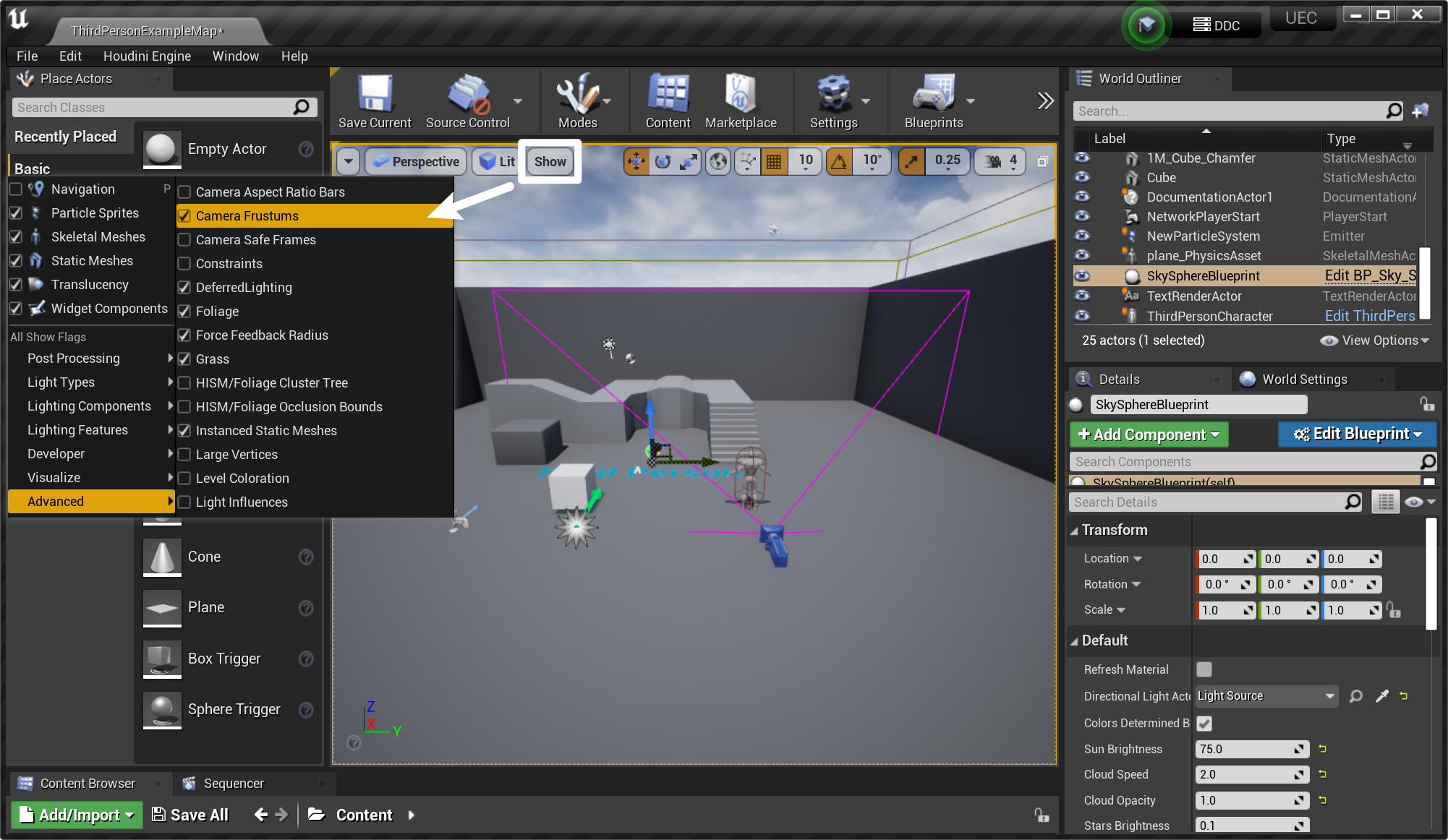
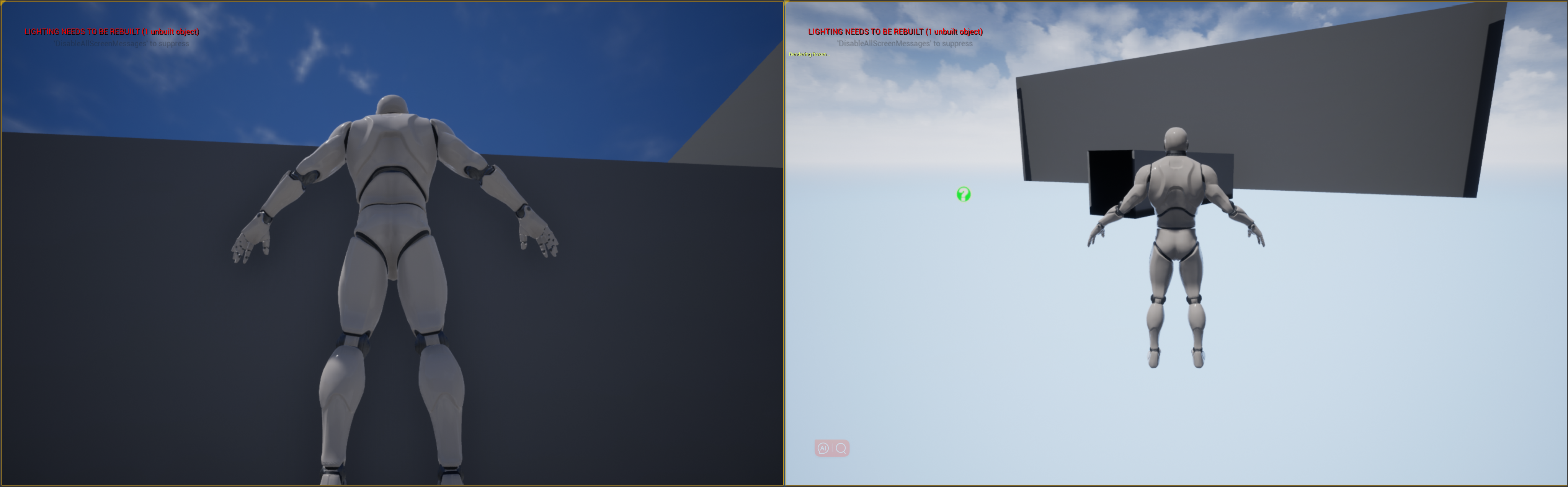
- ② 视锥剔除:根据物体是否在视锥内,决定是否剔除
- 打开相机视锥
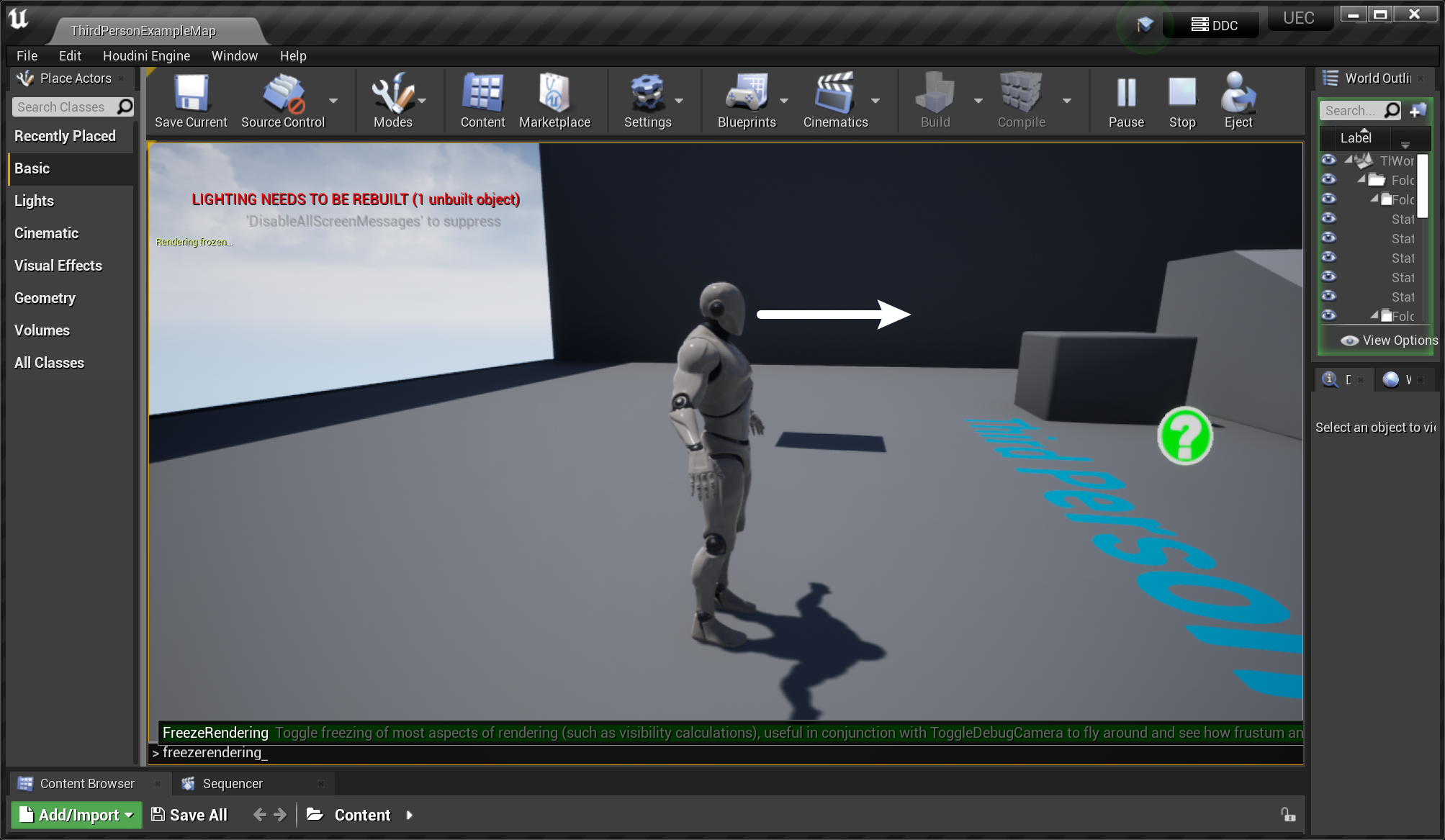
- 运行时,
~调出命令栏,FreezeRendering冻结视窗,ToggleDebugCamera跳出摄像机自由观察,可以看到只渲染了(角色)相机视锥范围内的物体
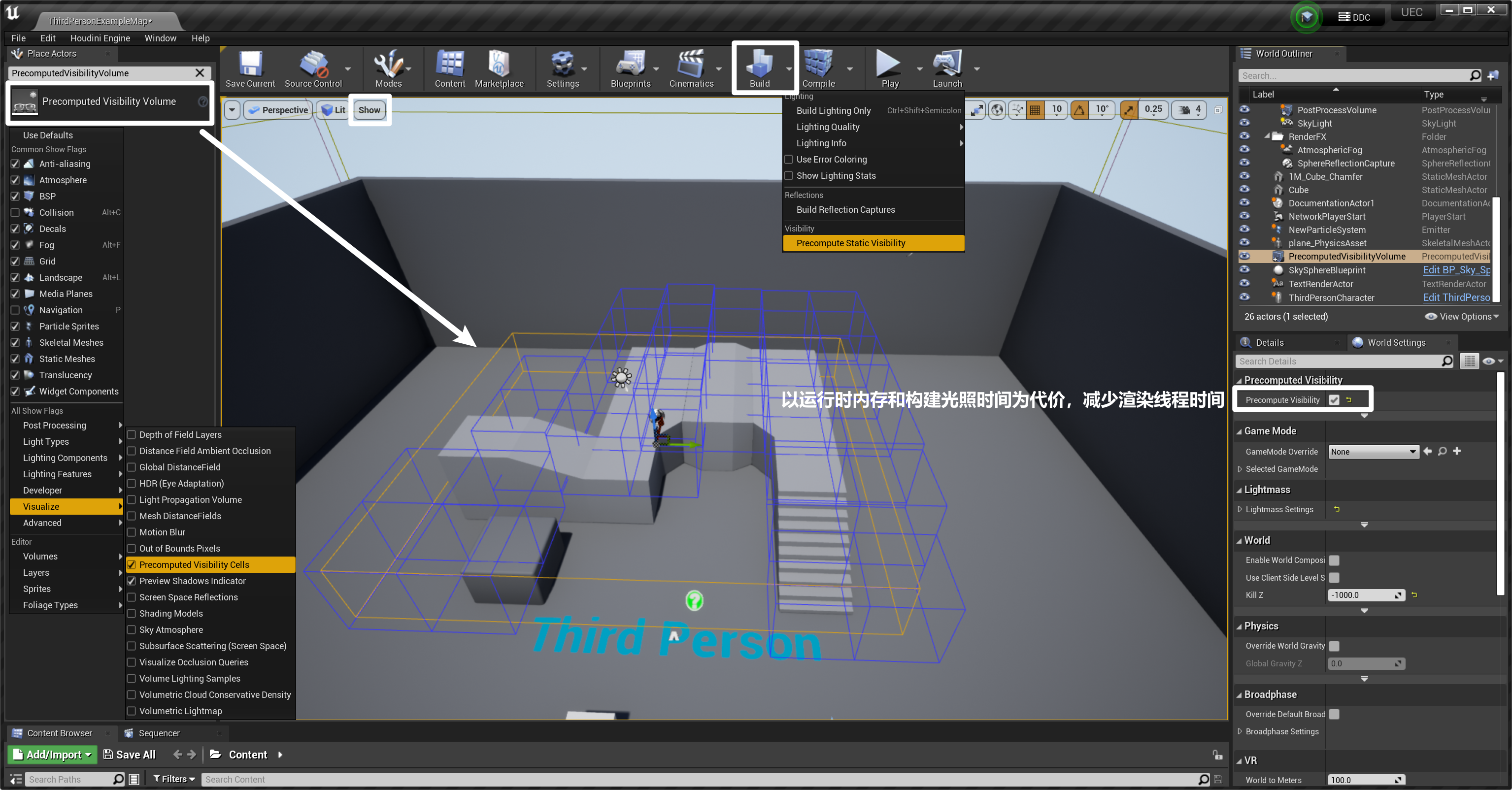
- ③ 预计算可见性:将可见性结果提前计算好并存储下来
- 放置“预计算可视性体积 PrecomputedVisibilityVolume”,勾选 Precompute Visibility 后,构建预计算静态可视性光照,打开预计算可视单元后,可以看到场景中的蓝色方块,这存储着预计算的可视信息
- 因此,使用预计算可视性体积,会在运行时占用更多内存去存储这些信息
- ④ 遮挡剔除:性能消耗最大,最后执行
- 同理视锥剔除,被遮挡的物体被剔除(被遮挡的物体可交互,但没被渲染出来)
- 遮挡过程的性能提示:
- 需要始终设置距离剔除,以提高性能
- 大于 1 万个物体时,对性能会有较大影响
- 大部分情况下,CPU 是瓶颈,有时也会是 GPU
- 遮挡在大型开发世界的作用比较小
- 所有物体都会被遮挡(包括粒子,会根据包围盒判断是否被遮挡)
- 大的物体很难被遮挡,因此 GPU 渲染会消耗更多时间
2.3 第2帧 - 66毫秒 - 几何体渲染(GPU)
- GPU 此时已经拿到了需要渲染的物体及其位置信息,为了防止像素重复绘制造成的资源浪费,需要找出优先被渲染的模型
- ① Prepass / Early Z Pass
- 在渲染场景之前,先获取目标场景的深度图,进而获得每个需要渲染的物体会被遮挡的部分(不需要渲染的部分)

- ② DrawCall
- GPU 开始渲染,在 CPU 通过 DrawCall 调用 GPU,每次 GPU 绘制完,都需要从渲染线程中拿新指令进行下一次的绘制,因此会有较大的性能开销
- DrawCall 是指渲染时在特定 Pass 中采用的单一处理过程,通常可以理解为绘制拥有相同属性的一组多边形

- 切换材质非常影响性能开销,GPU 渲染时,引擎会根据材质对物体进行排序,相同材质在同一批次里绘制

- DrawCall 数量对性能的影响大于三角形(模型面数)的数量

- 运行时,
~调出命令栏,通过Stat RHI查看运行统计数据,一般 DrawCall 在 2000-3000 为合理范围,5000 以上略高,移动端在几百为合理
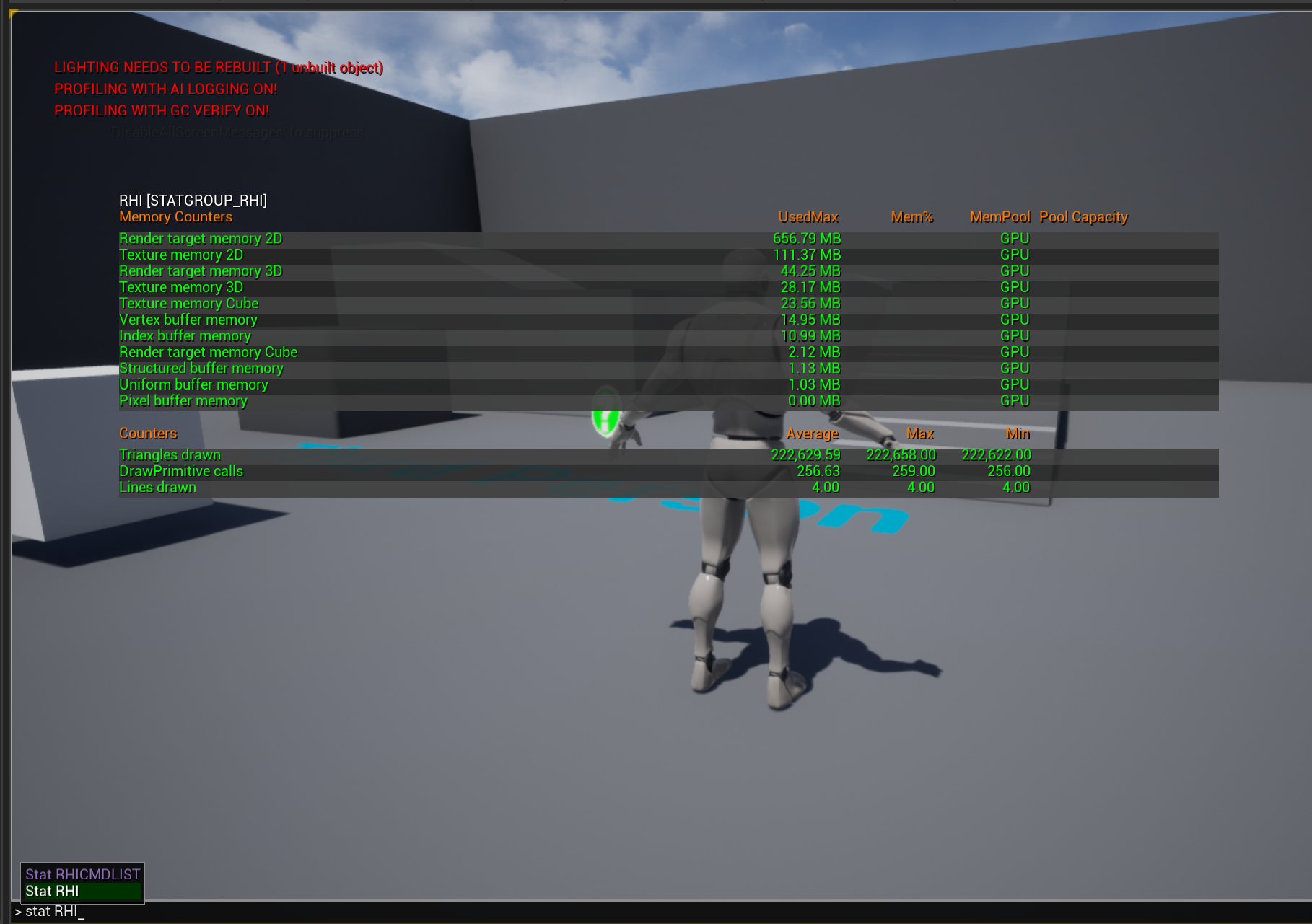
- 场景增加物体,则会增加 DrawCall 数量,但增加相同物体时,不影响 DrawCall 性能消耗(引擎默认打开,
r.MeshDrawCommands.DynamicInstancing 0手动关闭则影响 DrawCall 性能消耗)

- DrawCall 的性能提示:
- DrawCall 数量比多边形数量对性能的影响更大
- 引擎自带一些 DrawCall 消耗,无法清零
- Modular Meshes
- 使用 Instancing 降低 DrawCall
- Level Of Detail(LOD):降低模型面数
- HLOD:动态的将几个 Mesh 合并为一个,需要预先计算好
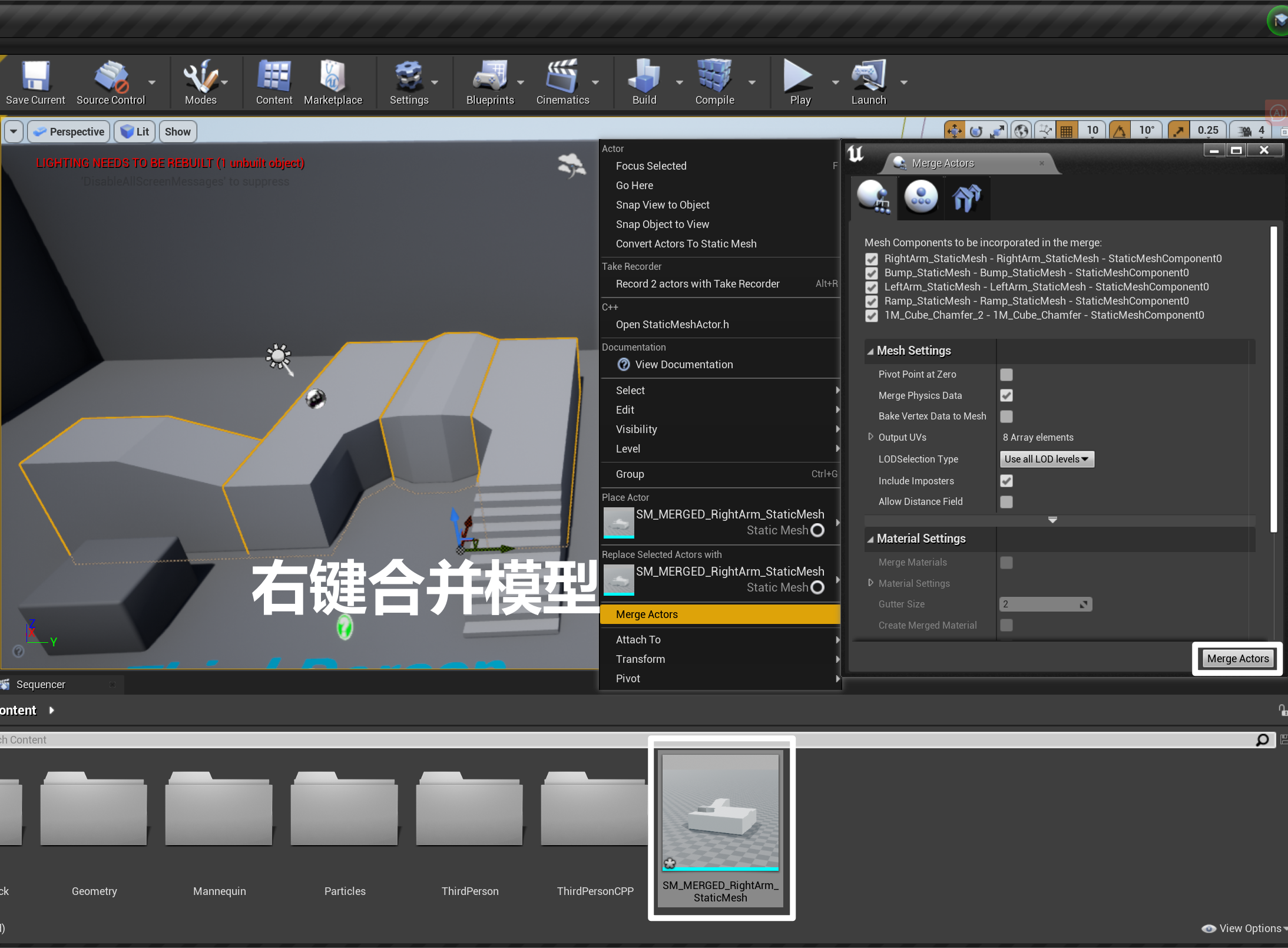
- 为降低 DrawCall 消耗,可以合并模型(将多个模型合并为一个,而非在一个蓝图中放置多个 Component),但会因此带来副作用:
- 遮挡检测性能更差
- 计算碰撞性能更差
- 占用更多内存
- ③ Shader
- Shader 是一小段在 GPU 上执行计算的代码(CPU 无法处理如此海量数据),GPU 上有许多不同的Shader:Vertex、Pixel、Compute等
- Shader 系统经过了高度优化,是整个渲染的核心,运行非常高效(流水线执行)
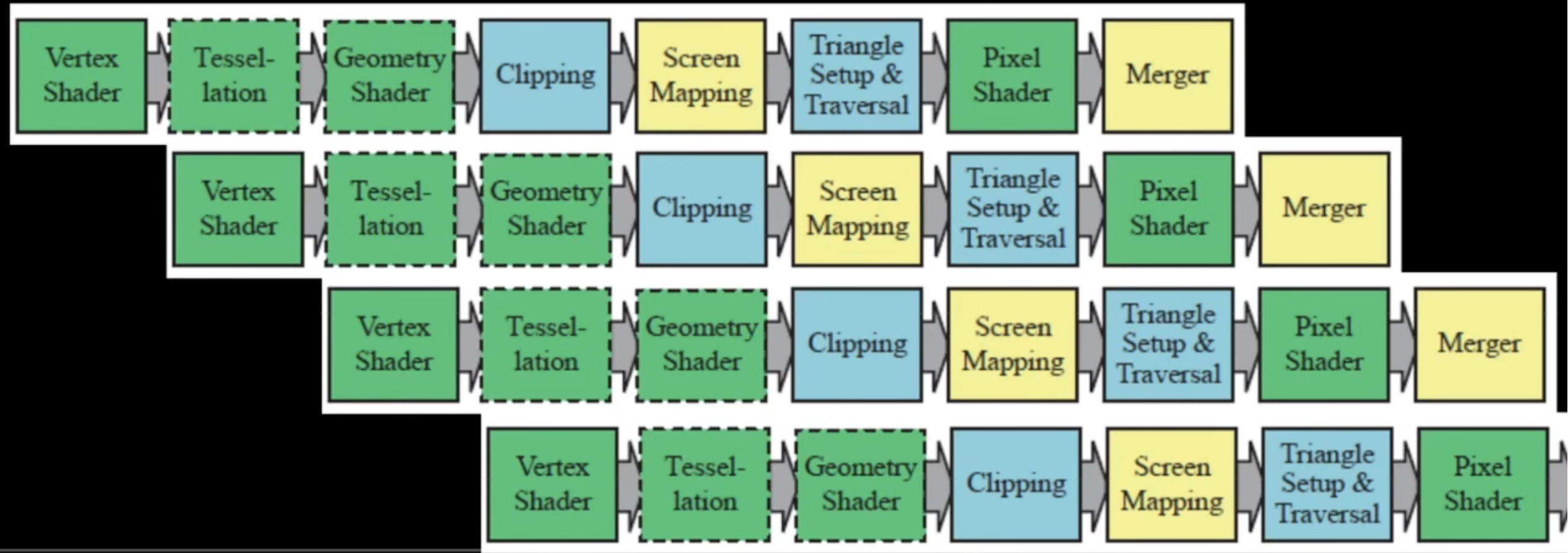
- Vertex Shader 是渲染过程的第一步(Vertex Shader 并不直接修改模型,只是视觉效果),主要处理以下3个:
- 转换空间坐标(局部坐标 - 世界空间 - 投影空间)
- 处理顶点着色( CPU 无法察觉顶点着色器对顶点数据的修改,因此物理和碰撞不受影响,
ShowFlag.Collision查看碰撞体)

- 应用世界坐标偏移(World Position Offset,WPO)

- 顶点着色器的性能提示:
- 动画越复杂,性能越差
- 顶点越多,性能越差
- 高精度模型最好使用简单的 Vertex Shader
- 对远距离的物体禁用顶点动画
- ④ Nanite
- Nanite 是 UE5 新推出的虚拟几何体系统,采用高度压缩的数据格式,支持细节流送和自动处理 LOD(无需手动),可以直接导入电影级品质的美术资源
- 能启用就启用 Nanite,可以快速渲染,占用内存和磁盘空间更小
- 但仍有缺陷:不支持骨骼动画 Skeletal Animation、变形目标 Morph Targets、自定义深度或模板、半透明材质、材质的世界位置偏移 World Position Offset
2.4 第2帧 - 66毫秒 - 光栅化和G-Buffer(GPU)
- GPU 此时得到每个物体的变换数据、投影顶点及必要的着色数据,下一步是找到这些三角形内部需要渲染的像素点,该过程叫做光栅化
- 光栅化按照 Drawcall 的顺序逐次调用
- 在远处观察一个有 10 万面的模型,即使最终只占画面中的一个像素,GPU 仍会处理这个 10 万面的数据
- 由于硬件设计的原因,在计算一个像素时,还需要同时计算其周边 2*2 的像素,因此导致 Overshading 问题
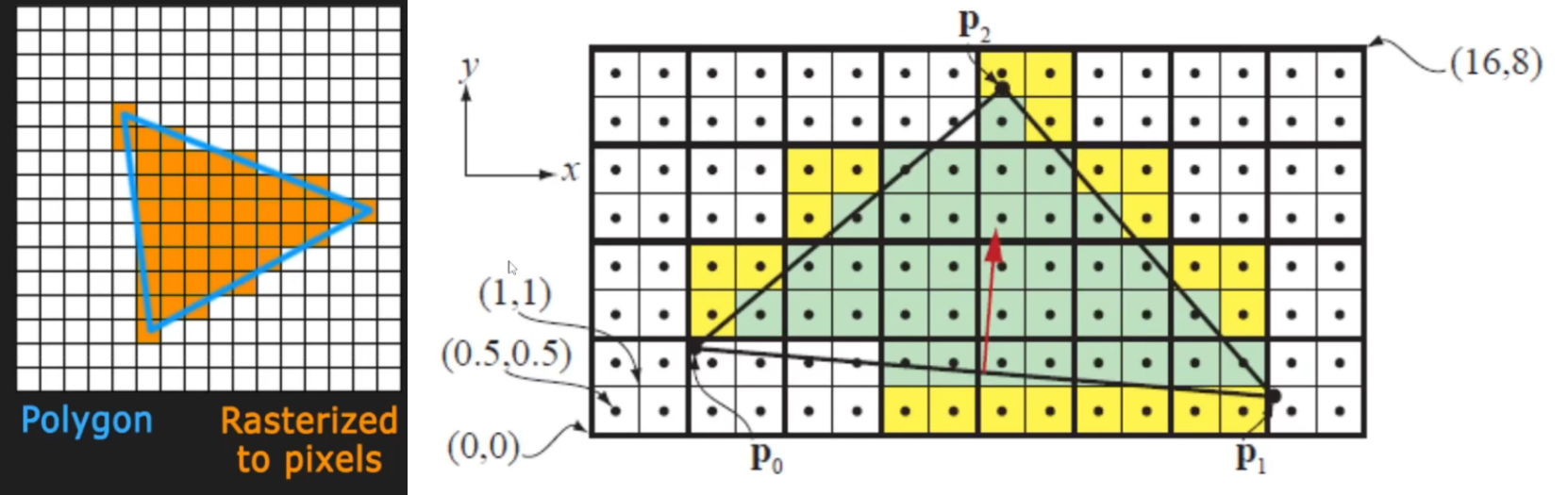
- Overshading:指屏幕上的像素被着色的次数,最理想情况下,屏幕上的每个像素都只被着色计算一次,但物体外轮廓不可避免的会被计算多次

- 光栅化和 Overshading 的性能提示:
- 多边形越密集,渲染开销越大
- 从更远处观察物体,多边形密度会增加,因此可以使用 LOD 或者远距离剔除,来减少这部分开销
- PixelShader 越复杂,Overshading 的开销也越大
- 非常细长的三角形也会造成比较严重的 Overshading(物体外轮廓处的 Overshading 严重)
- 随后,将物体表面信息储存到一系列的图像中,这些图像成为 G-Buffer
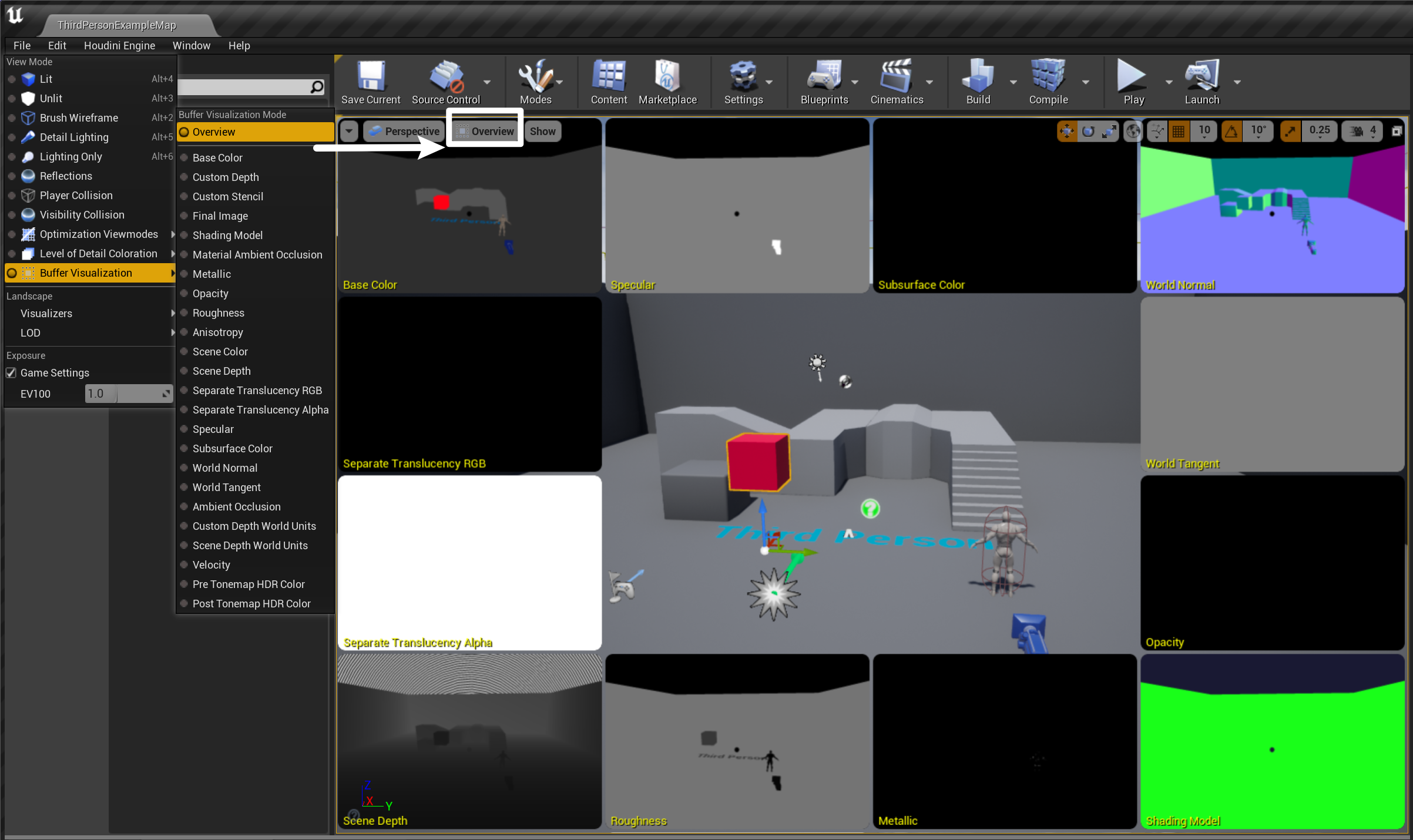
- G-Buffer 可以用于合成各种信息,最终用于渲染输出,引擎中目前使用了 6 张 G-Buffer,存储消息如下:
- GBufferA.rgb:世界法线 World Normal,每个物体的 G-Buffer 数据都存储在 alpha 通道
- GBufferB.rgba:金属 Metallic、镜面 Specular、粗糙度 Roughness、模型阴影 ShadingModellD
- GBufferC.rgb:GBufferAO 存储在 alpha 通道的基础颜色 BaseColor
- GBufferD:自定义数据
- GBufferE:预计算阴影 precomputed shadow factors
- GBufferF:输出 RGB 的 WorldTangent、alpha 通道的各项异性 Anisotropy

- 在项目中打开 Buffer Visualization - Overview
- 可以使用 Custom Depth 作为 Mask 输出
- 在项目设置中,开启 Custom Depth-Stencil Pass
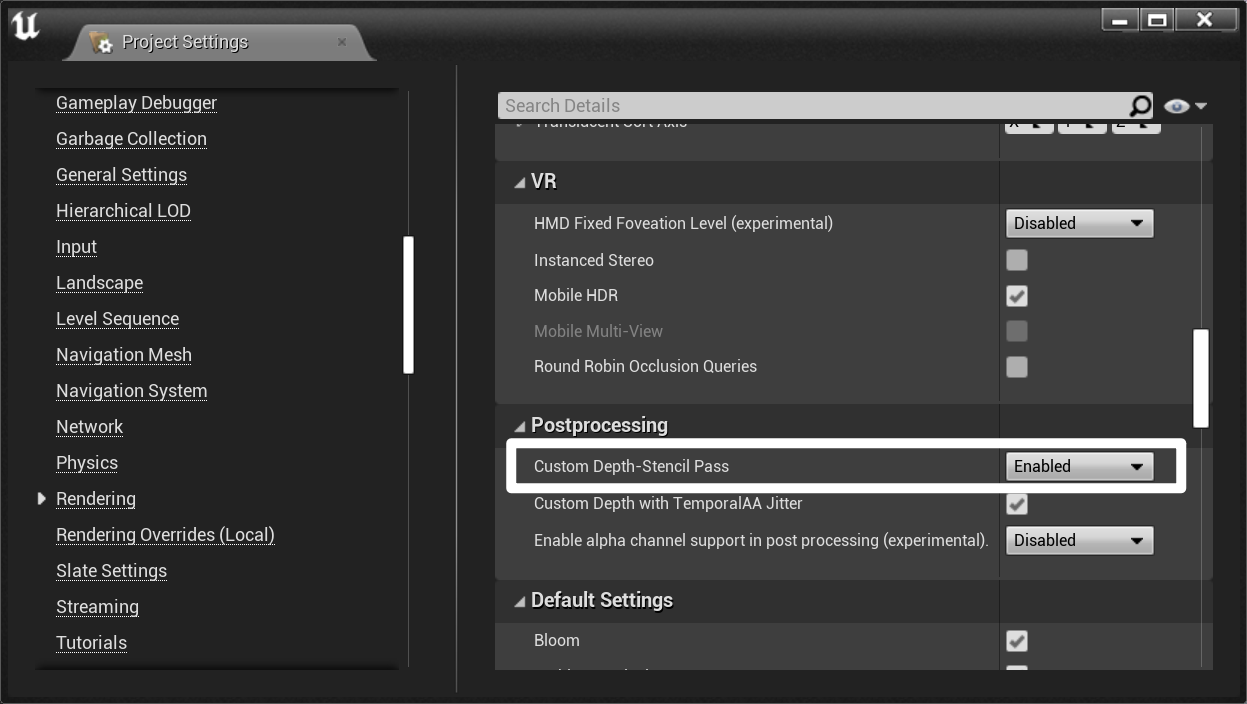
- 选中目标,勾选 Render CustomDepth Pass,并打开高分辨率截图 High Resolution Screenshot,启用“使用自定义深度做蒙版 Use custom depth as mask”
- 也可以使用 MovieRenderQueue 输出其他 G-Buffer,或 Object ID 用于合成
- G-Buffer 的性能提示:
- G-Buffer 会占用很多内存和带宽,因此需限制 G-Buffer 的数量
2.5 纹理
- 纹理在导入时会被压缩,可以大大减少 GPU 显存占用
- 不同平台有不同的纹理压缩方式,Windows 通常使用 BC 算法
- 法向贴图使用了特殊的压缩方式,只保留的 RG 通道
- Shader 中对采样纹理数量有限制
- 纹理的分辨率主要影响内存和带宽,而非着色
- 为了减少锯齿并加快渲染速度,需要使用 Mipmap(从第 0 级开始,下一级的长宽都是 1/2)
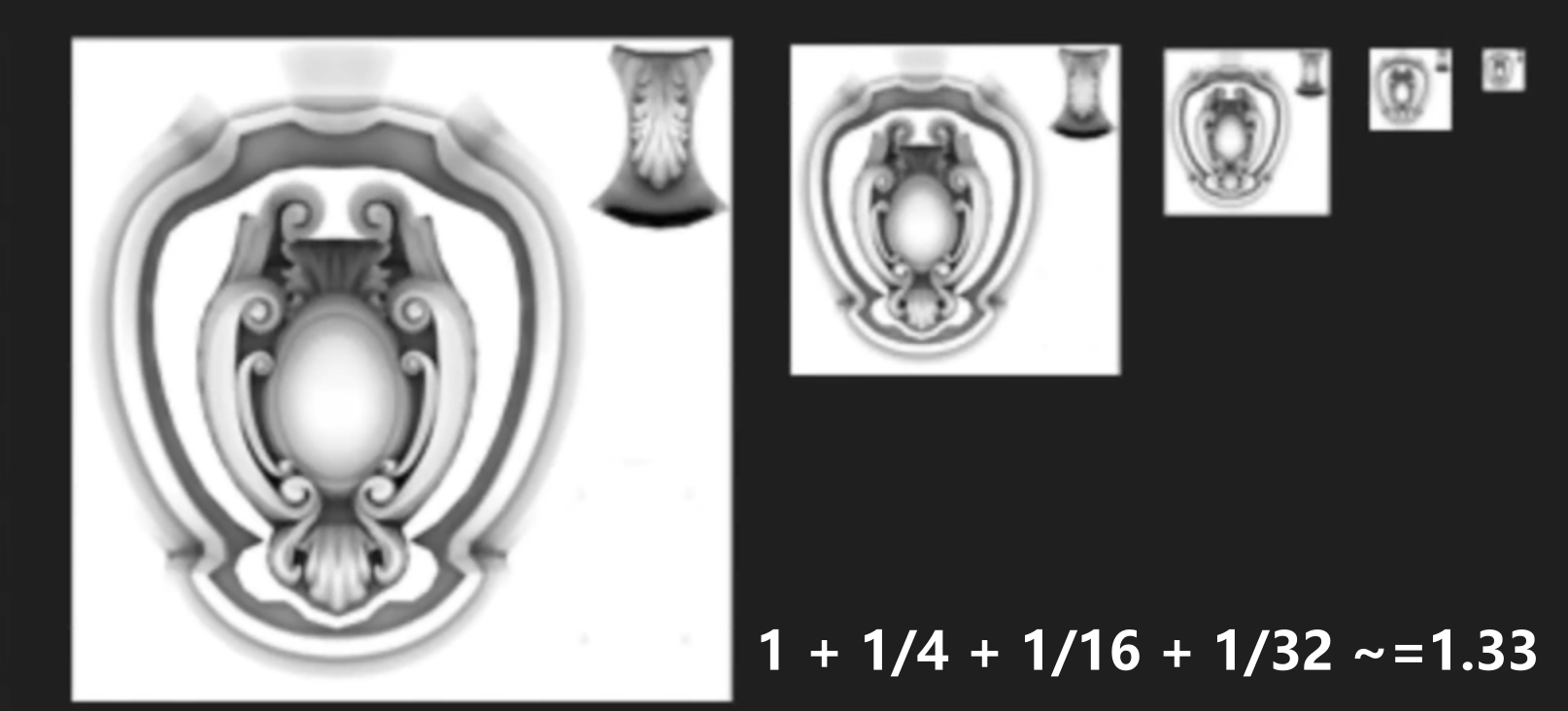
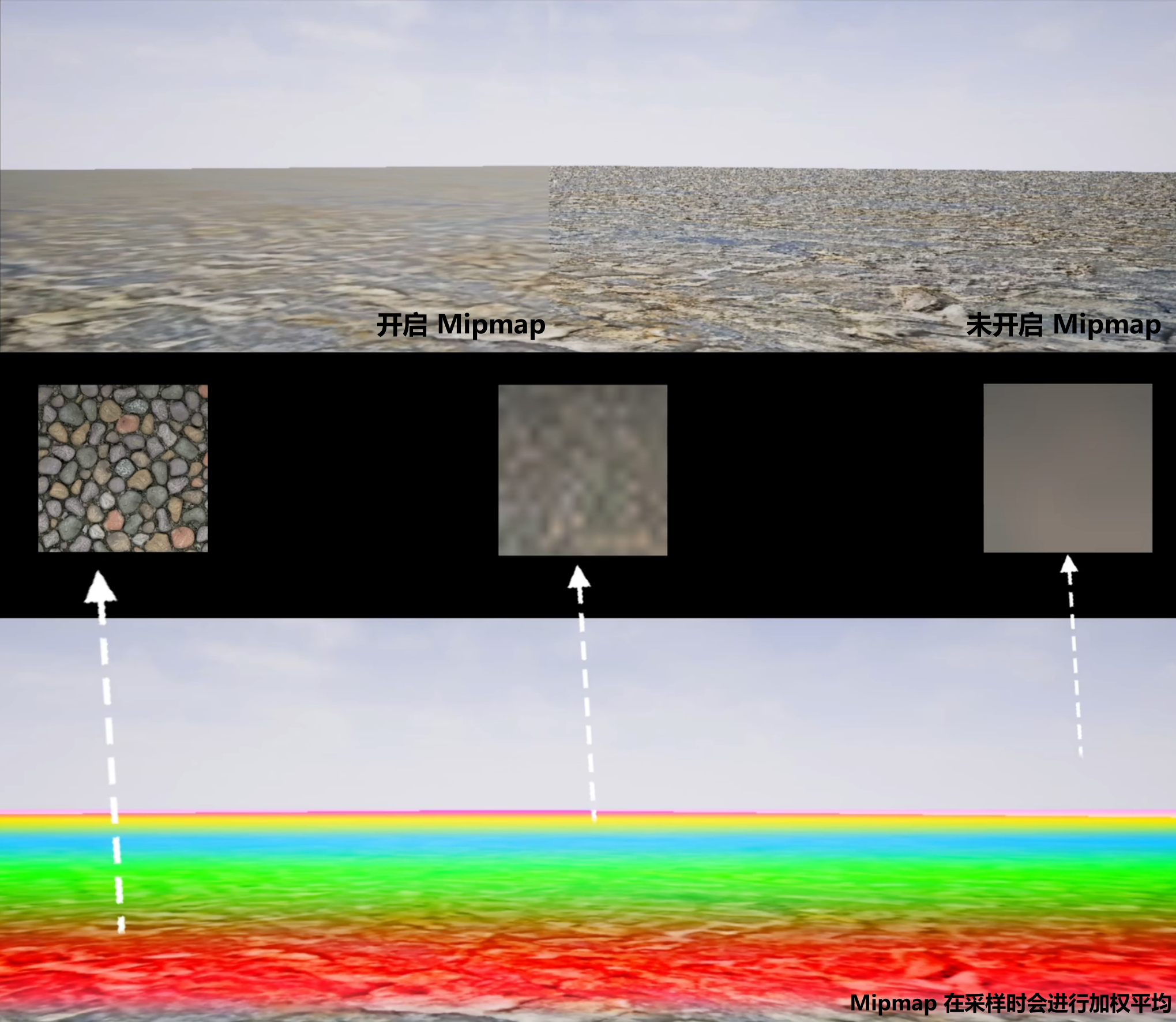
- 尽量开启 Mipmap,Mipmap 在向下采样时会进行加权平均,远处的采样会使用低像素纹理,使纹理整体过渡平滑
- 纹理的尺寸需要为 2 的幂次方(128、256、512、1024、2048、4096...),长方形贴图的长宽满足 2 的幂次方(边长不是 2 的幂次方的贴图无法生成 Mipmap 和进行纹理流送)
- UI 贴图可以不需要 Mipmap
- 贴图在引擎中的设置
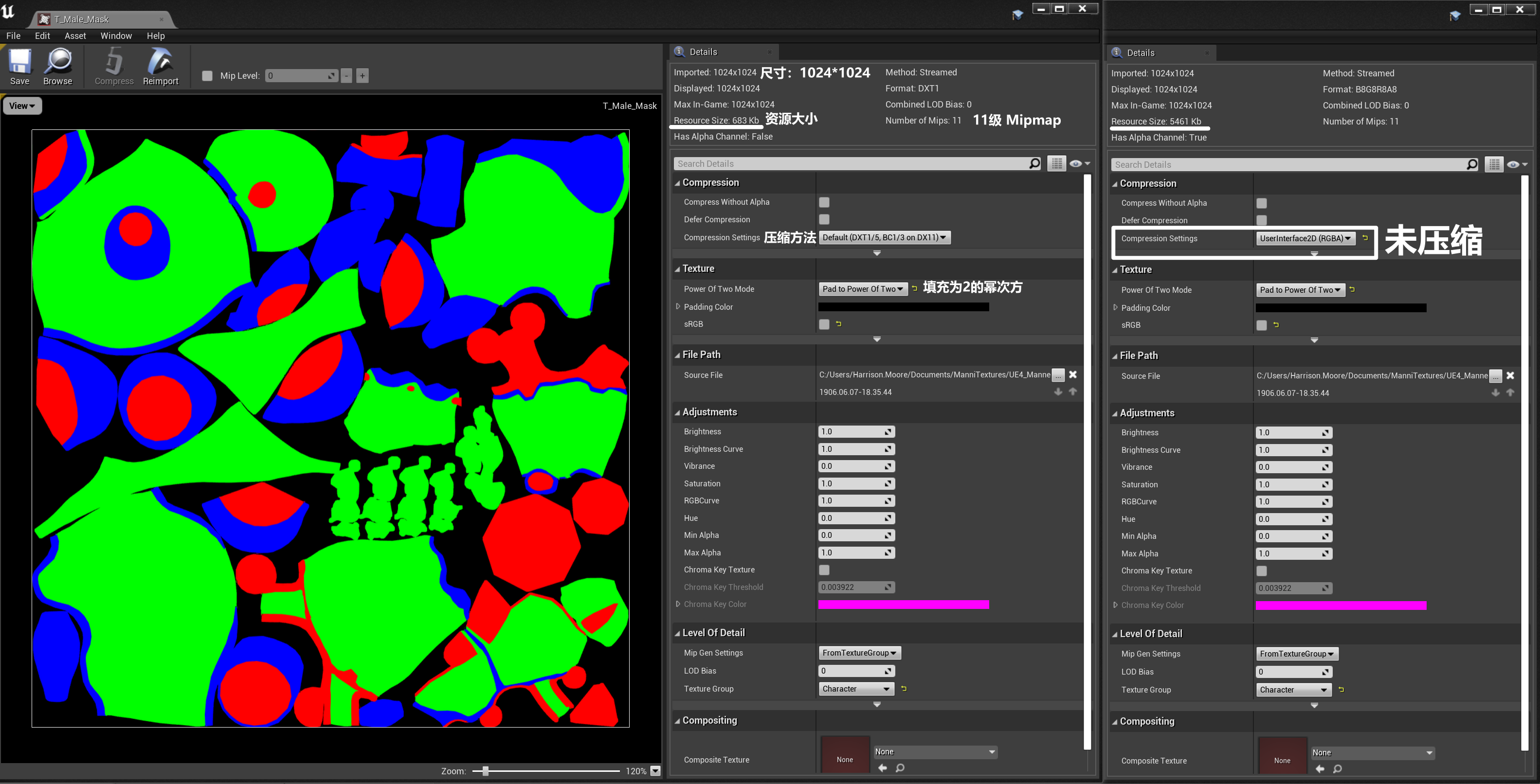
2.6 像素着色器和材质
- 像素着色器(Pixel Shader)与顶点着色器(Vertex shader)类似,是在 GPU 上执行的程序,可以同时执行大量的简单计算,用于修改像素的颜色,对于渲染管线极为重要
- 像素着色器(Pixel Shader)是材质系统的底层实现,同时也实现了光照、雾、后期等与效果相关的处理

- 像素着色器(Pixel Shader)以 Shader Language 书写,不同的平台使用不同的 Shader Language(如:在 Windows 平台上使用 HLSL),引擎会进行自动转换

- 材质管线很大一部分是 PBR(Physical Based Rendering 基于物理的渲染),UE中几乎所有的模型都是使用 PBR 模型进行渲染的,基于 G-Buffer 的合成工作流限制
- PBR 使用 Specular 高光 / Metallic 金属度 / Roughness 粗糙度,来描述一种材质属性
- PBR 是一种统一着色模型(几乎所有模型、图像、材质的底层都建立在相同的着色器上,以达到最快的效率),可以通过修改参数来表现许多不同材质(可预测性)
- 使用 Optimization Viewmodes - Shader Completely & Quads 查看 Shader 复杂度
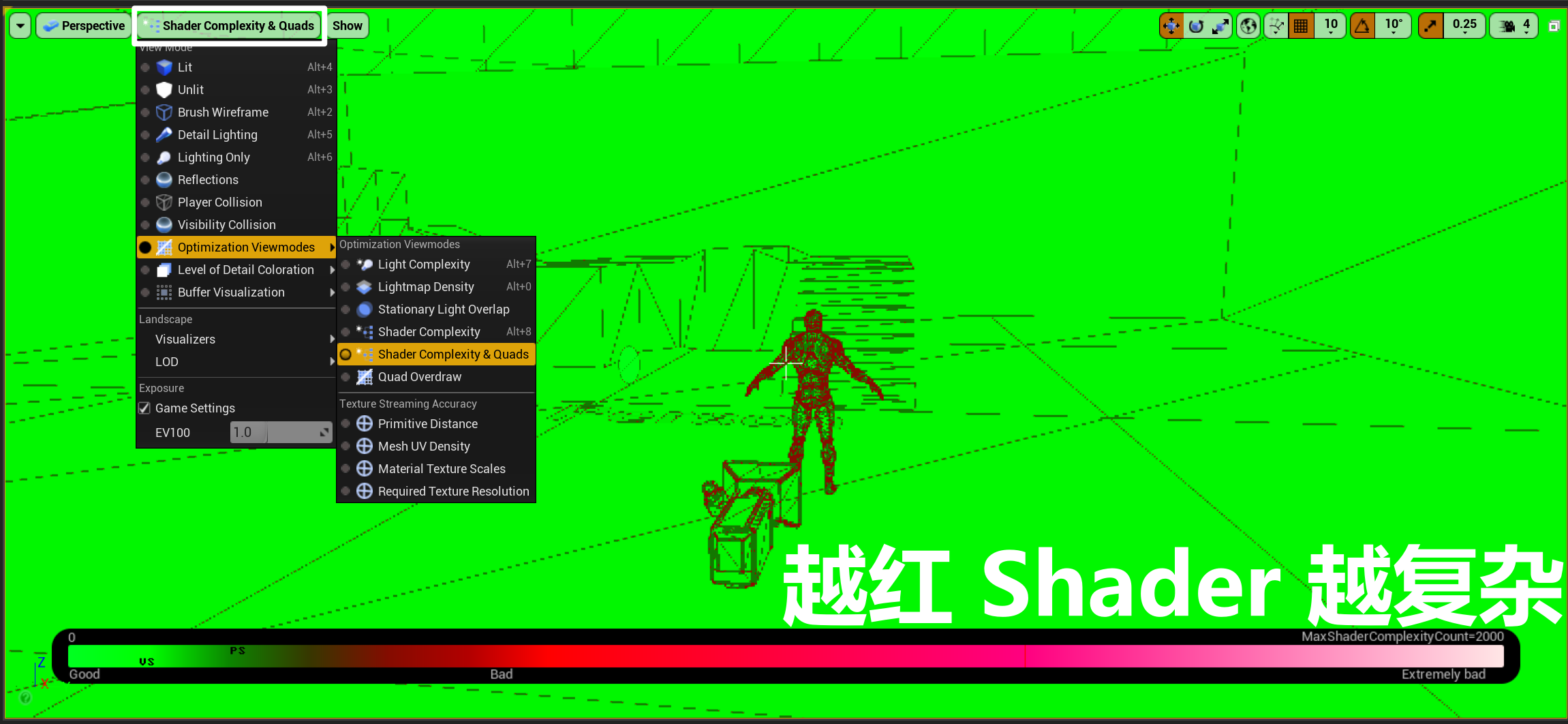
- 材质性能提示
- 每个材质的纹理采样器有最大使用限制(16个),DX11 可以使用共享采样器(最多可以使用 128 张纹理)
- 纹理尺寸过大(影响内存)会导致短暂的卡顿,但不会降低帧率
- 像素着色器会对性能有非常大的影响,可以通过优化材质编辑器中的指令数,来优化像素着色器的执行时间
- 屏幕输出的分辨率越大,复杂材质对性能的影响也越大
三. 反射
- 有时呈现的效果是使用了多种反射机制进行组合的结果
3.1 反射捕获
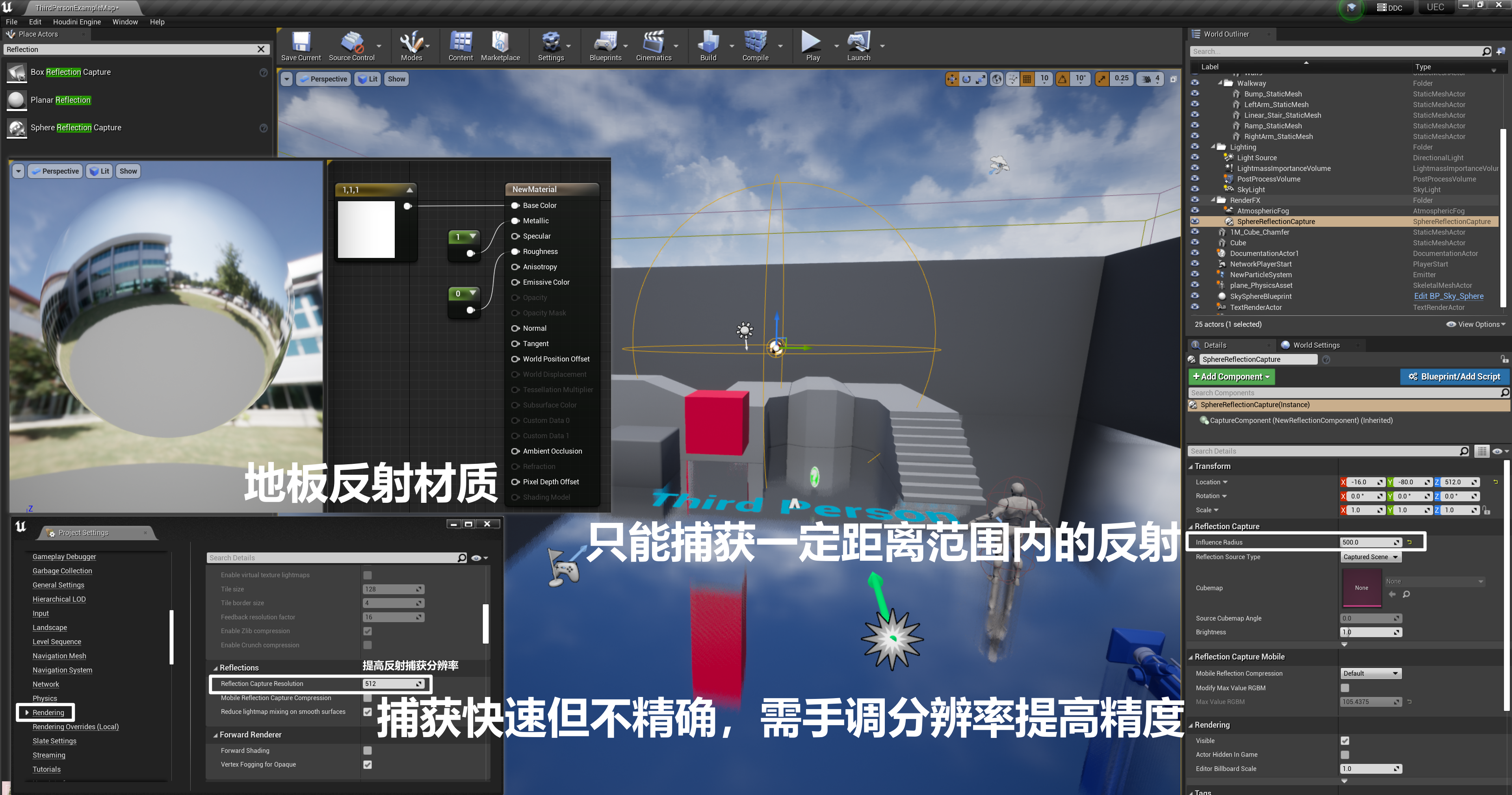
- 在指定位置放置 Reflection Capture,就可以捕获一张 Cubemap,在渲染时,以该 Cubemap 作为光源,进行反射计算(需要预计算、快速但不精确、只能捕获一定距离范围内的物体)
- 反射捕获的反射计算,与天光类似。如果场景中有多个反射捕获球,则会出现重复捕获(重复计算像素)的情况,使性能消耗变大
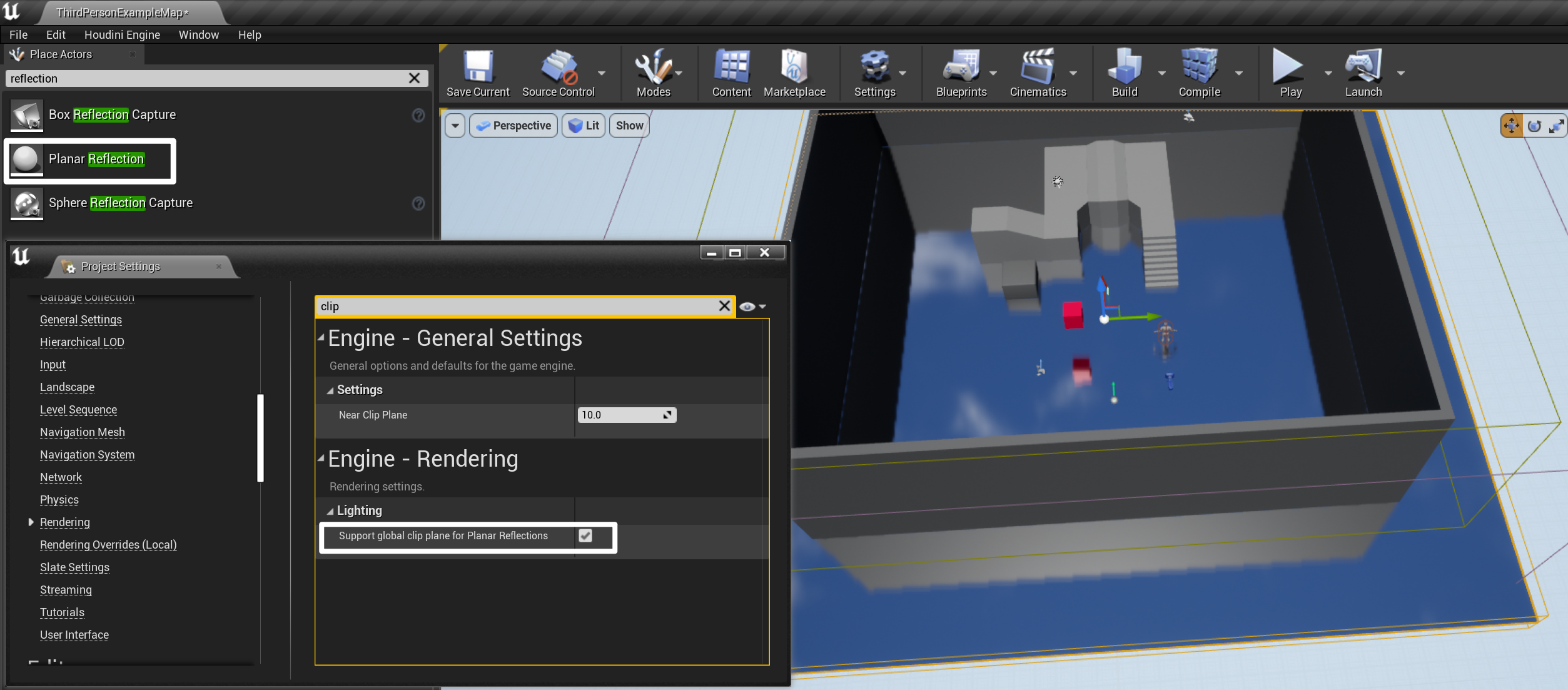
3.2 平面反射
- 平面反射不常见,仅使用在需要精确反射的指定平面上
- 在某些设置下可能会有很大的性能损耗,适合需要精准反射的表面(如:镜子),本质上是相机每帧获取
- 删除场景中自带的反射捕获 Reflection Capture,将默认的屏幕空间反射
r.SSR.Quality 0置零,在场景中放置平面捕获 Planar Reflection 包裹地面,开启 Support global clip plane for Planar Reflection
3.3 屏幕空间反射
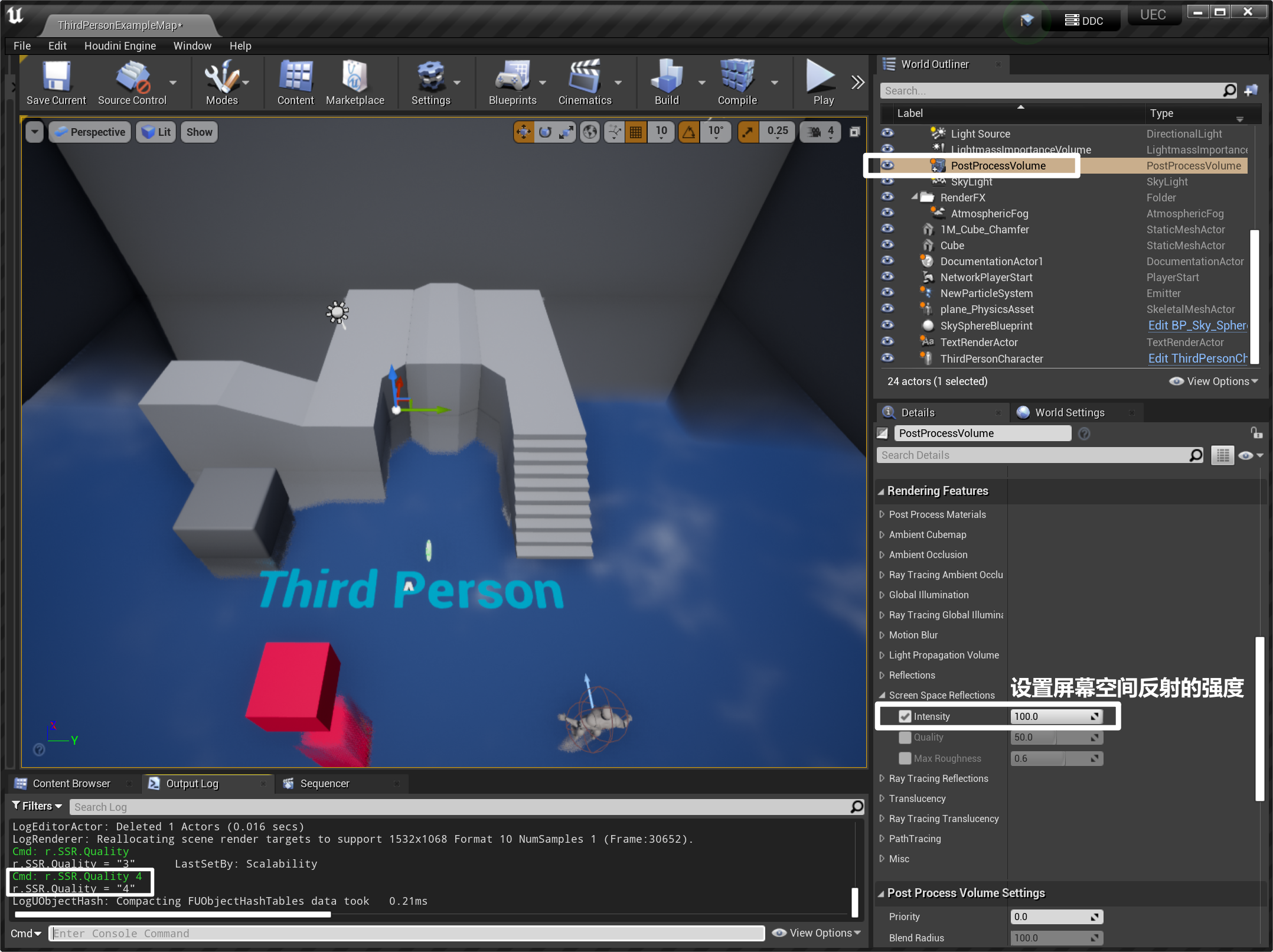
- 唯一默认开启的反射系统 SSR,对任何物体都有影响,准确,有噪点,性能损耗大,只反射视野内可见的物体(SSR 是根据现有的 G-Buffer 和 RayMarch 的算法进行计算的,G-Buffer 中没有的数据则不进行绘制)
- 清除上一节中测试的平面捕获 Planar Reflection,打开屏幕空间反射
r.SSR.Quality 4,在 PostProcessVolume 中设置屏幕空间反射的强度
3.5 反射性能提示
- 反射的性能提示:
- 未经 Cook,反射捕获会在打开关卡的时候进行,导致加载变慢
- 反射捕获区域如果有重叠,会导致多次着色从而性能变差
- 反射捕获的分辨率可以在系统设置中调节
- 天空光为整个关卡提供了低成本的反射捕获
- 必要时才使用平面反射的实时捕获和 SSR
四. 光照和阴影
- 光照
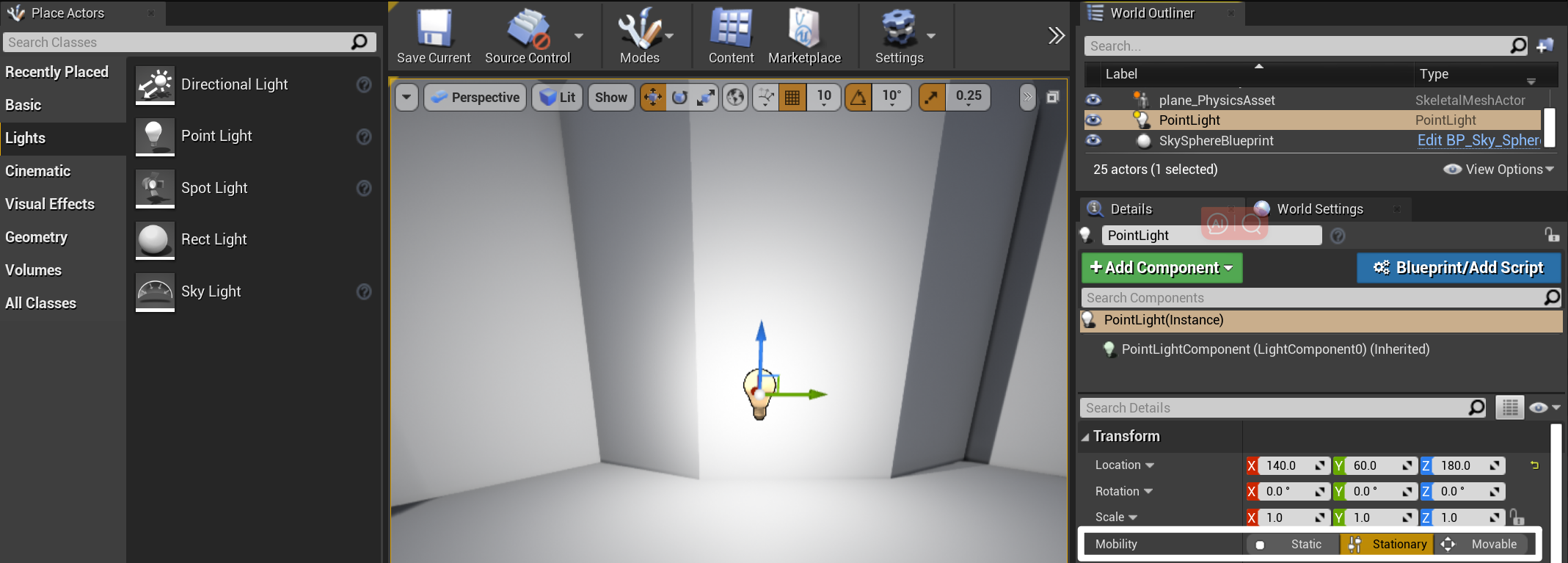
- 静态光源(Static Light):运行时不能以任何方式改变,仅在光照贴图中进行计算,一旦处理完成,不会再有进一步的性能影响,可移动对象不能够和静态光源进行交互
- 可移动光源(Movable Lights):产生完全动态的光照和阴影,产生的光照不会烘培到光照贴图中,也不会产生间接光照效果
- 固定光源(Stationary Lights):保持固定位置不变的光源,可修改亮度和颜色,在运行时更改仅仅会影响直接光照,间接光照(反射)是通过 Lightmass 进行预计算的,所以不会更改
- 阴影渲染过程

4.1 静态光照和阴影
4.1.1 Lightmap
- 部分光照、阴影的计算会在预计算阶段完成,在 Runtime 与实时光照结合
- 静态光源可以处理辐射(间接光照)和全局光照,主要通过 Lightmap 实现:
- Lightmap 是一张烘焙了光照和阴影的贴图,在计算光照时,与 BaseColor 相乘

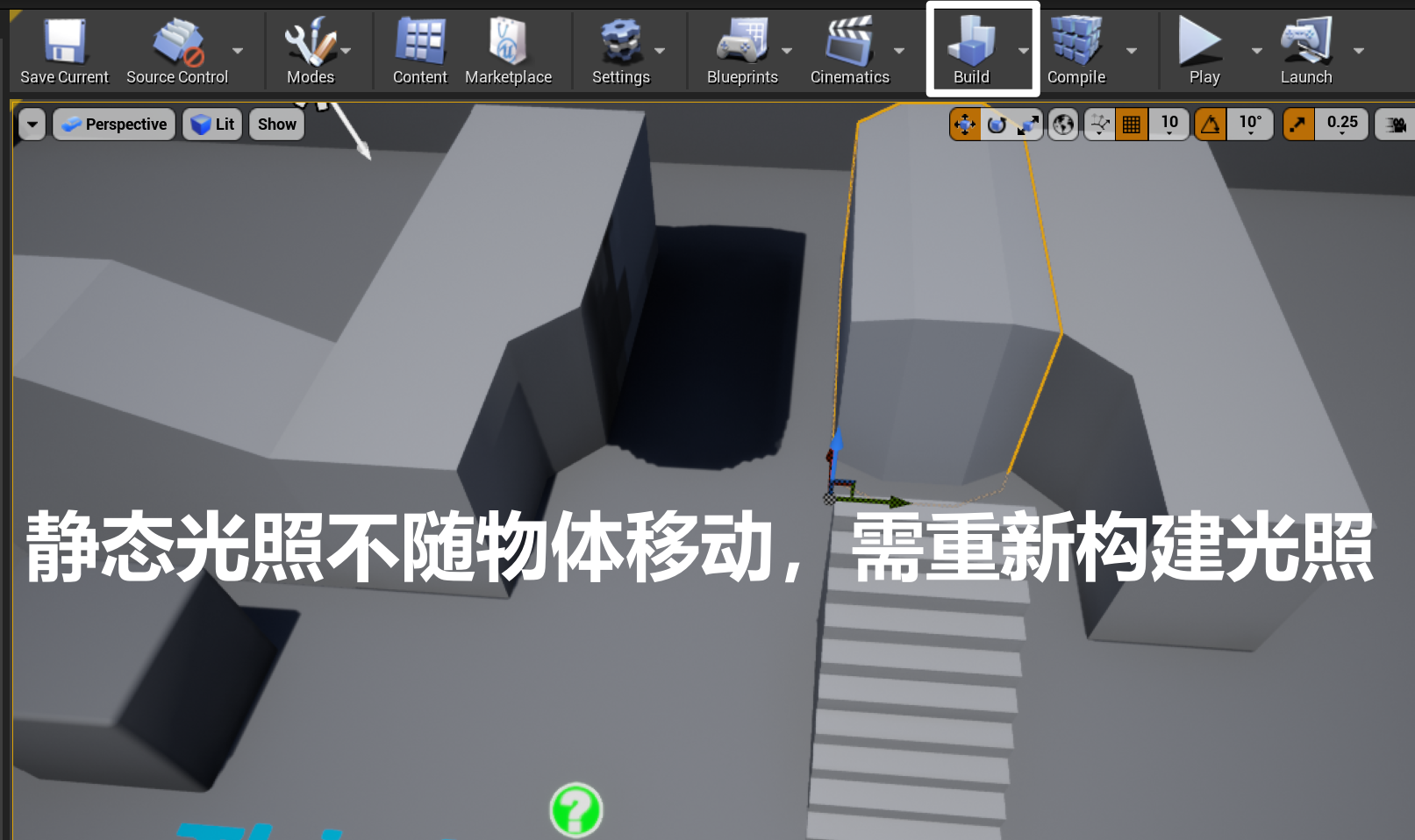
- UE 中,使用 Lightmass 独立程序(Lightmass 会生成表面光照贴图,用于表现静态对象上的间接光照,Lightmass 由引擎编辑器在烘焙时调用,支持网络分布式渲染)生成 Lightmap(左图),多张 Lightmap 合并到 atlas 中,可以逐个 Mesh 调整 Lightmap 密度

- 一旦烘培完成,运行时静态阴影无法跟随物体移动,每次修改光照和静态物体,需要重新构建光照
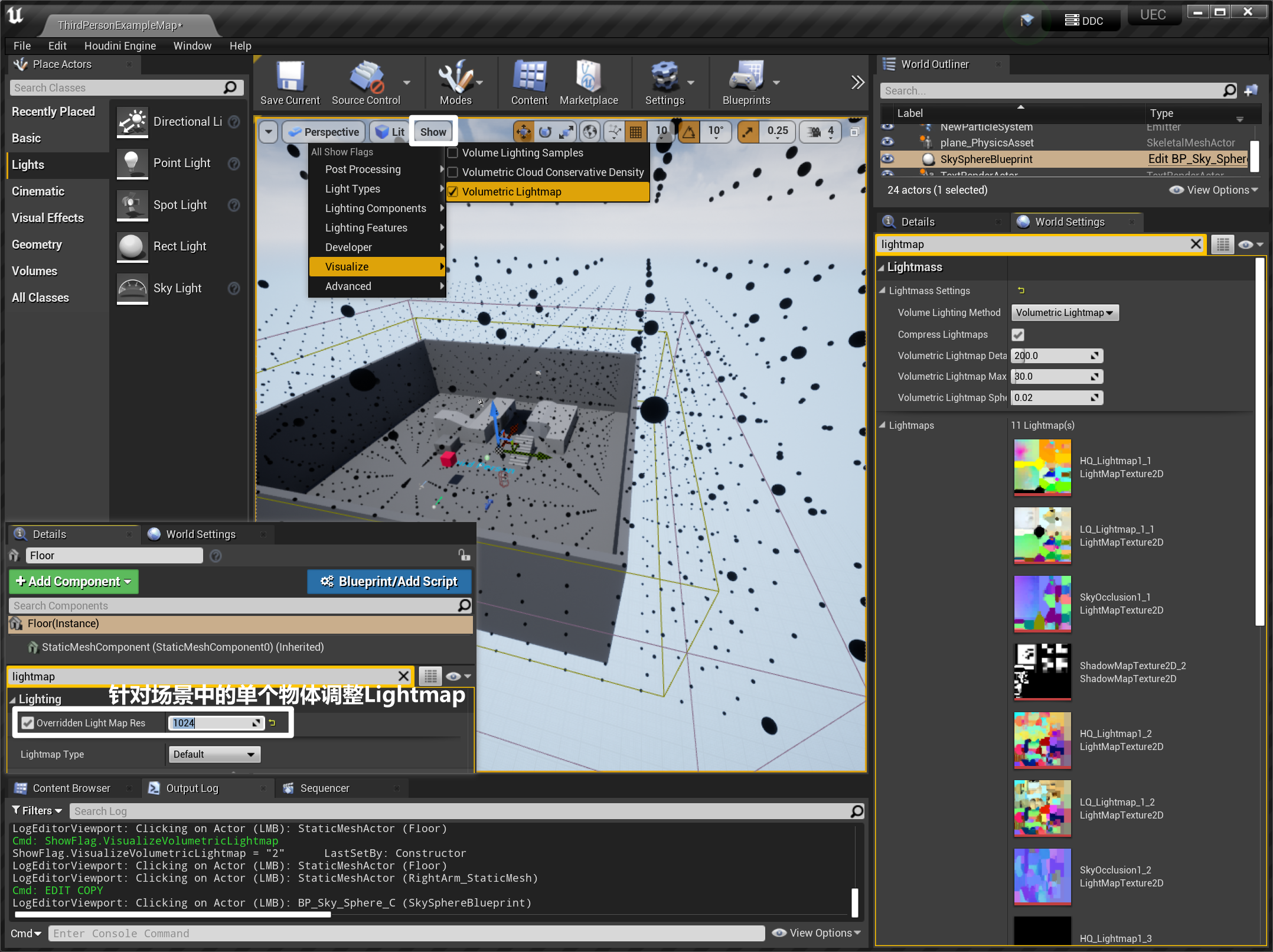
4.1.2 Volumetric Lightmap
- Volumetric Lightmap 体积光照贴图:存储动态对象(如:角色)所有点的预计算光照,运行时用于动态对象的间接光照的插值

- 可以通过
ShowFlag.VisualizeVolumetricLightmap显示场景中的 Volumetric Lightmap,也可以手动开启 - 场景中出现的每个小圆球采样点,相当于一个个光源,只影响范围内的动态物体
- 场景中的 Volumetric Lightmap 可以在世界设置中的 Lightmap 查看,也可以独立调试
- GPU Lightmass
4.1.3 静态光照和阴影的性能提示
- 静态光照和阴影的性能提示:
- 静态阴影在编译器下预计算(需要时间),并将信息存储在 Lightmap 中,运行时计算高效,但占内存
- 静态光照总是以完全相同的速度渲染,无论有多少静态光源,烘焙之后的渲染速度是一样的
- 烘焙速度会受以下几点影响:
- Lightmap 分辨率
- 模型、光源数量
- 烘焙选项(可通过设置选项提高渲染质量)
- 光照影响范围
- 光照和阴影的质量取决于 Lightmap 的分辨率和 UV 分布
- 由于 UV 布局,光照可能出现接缝
- Lightmap 分辨率有上限,模型过大可能效果不佳
- Lightmap 分辨率会影响内存,但不影响帧率
- 模型需要 Lightmap UV,因此需要额外的步骤去处理
4.2 动态光照和阴影
- 动态光照使用 Pixel Shader 像素着色器计算
- 点光源使用球形模型进行渲染(只渲染球投影内的像素)
- 方向光源则进行全屏光照渲染
- 如果相机距光源很近,而光源实际上并没有照亮很多物体,因此可以使用光源剔除进渲染计算,常用的光源剔除有:
- Tile
- Cluster
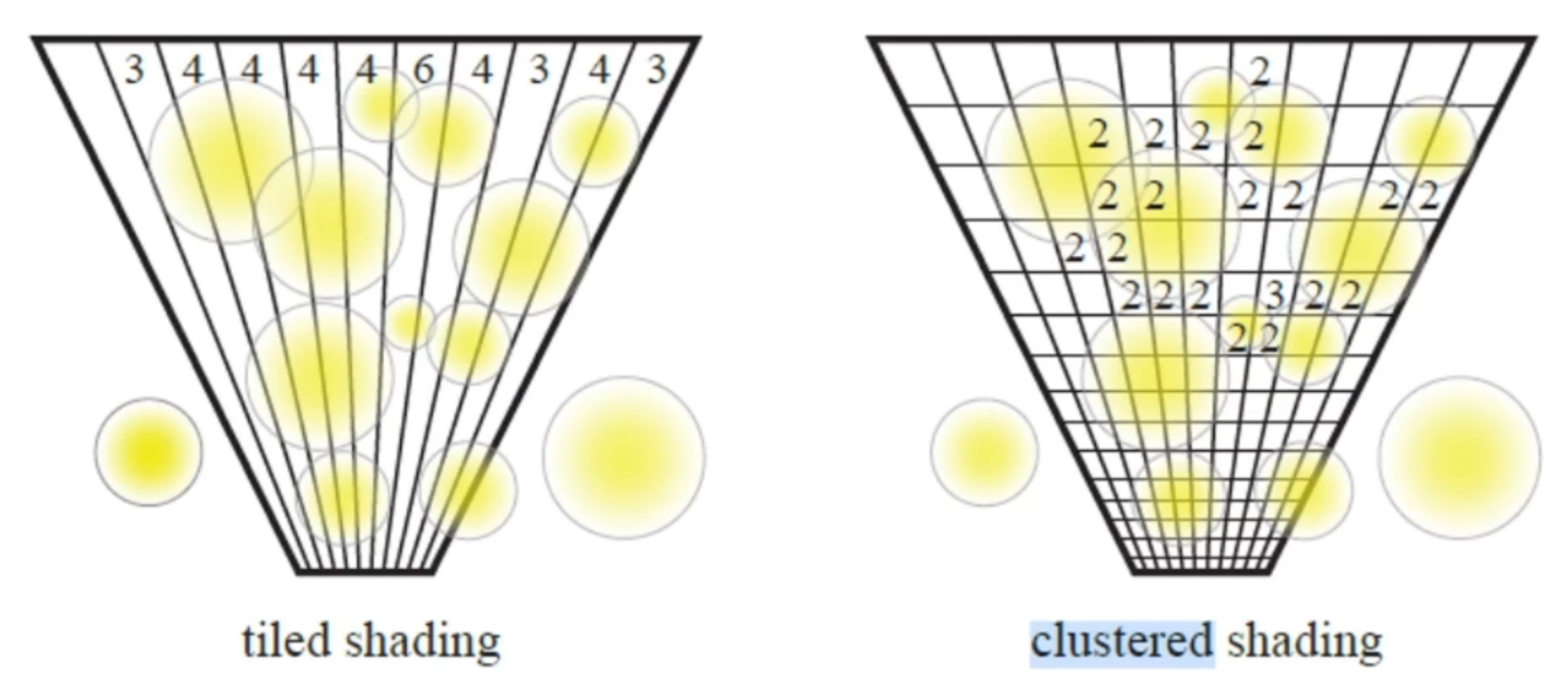
- 动态阴影:
- 常规动态阴影
- 级联阴影
- 逐对象阴影
- 距离场阴影
4.2.1 常规动态阴影
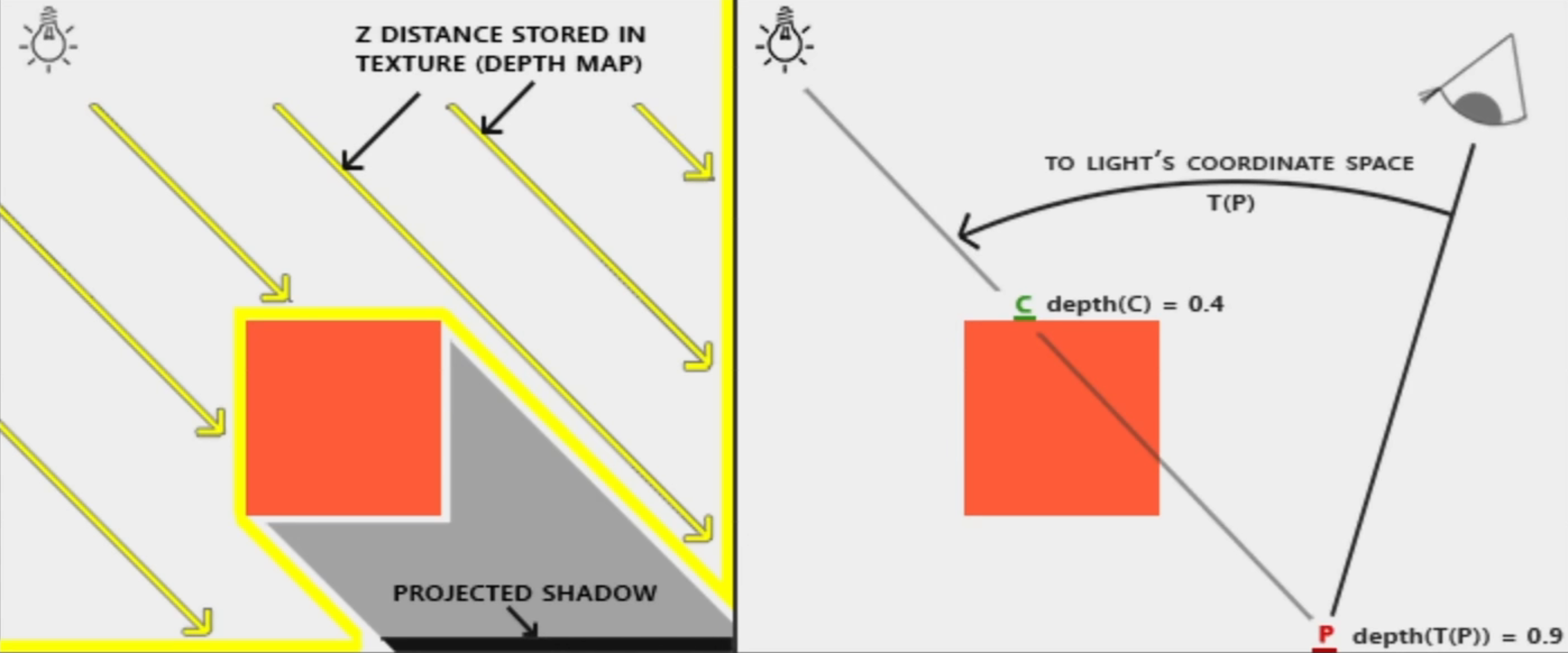
- 阴影是光线被阻挡的结果,阴影能使场景更加真实,并感知空间位置关系。UE 使用“阴影映射”进行阴影渲染:以光的位置为视角进行渲染,则可见范围内的物体被照亮,得到物体与光源的距离信息,并存储到深度 Buffer 中,以此来渲染场景中的光照和阴影
- 如:要渲染 P 点,通过矩阵将 P 点转换到光源坐标下,得到 P 点距光源的距离(0.9),而以光源为起点,距离最近的点是 C 点(0.4),则可得:P 点被 C 点遮挡,P 点位于阴影中
- 引擎中的阴影贴图

- 根据相机视角的深度图 + 光源视角的深度图,得到阴影 Mask(左图),并将其应用到渲染过程中,绘制出人物和阴影

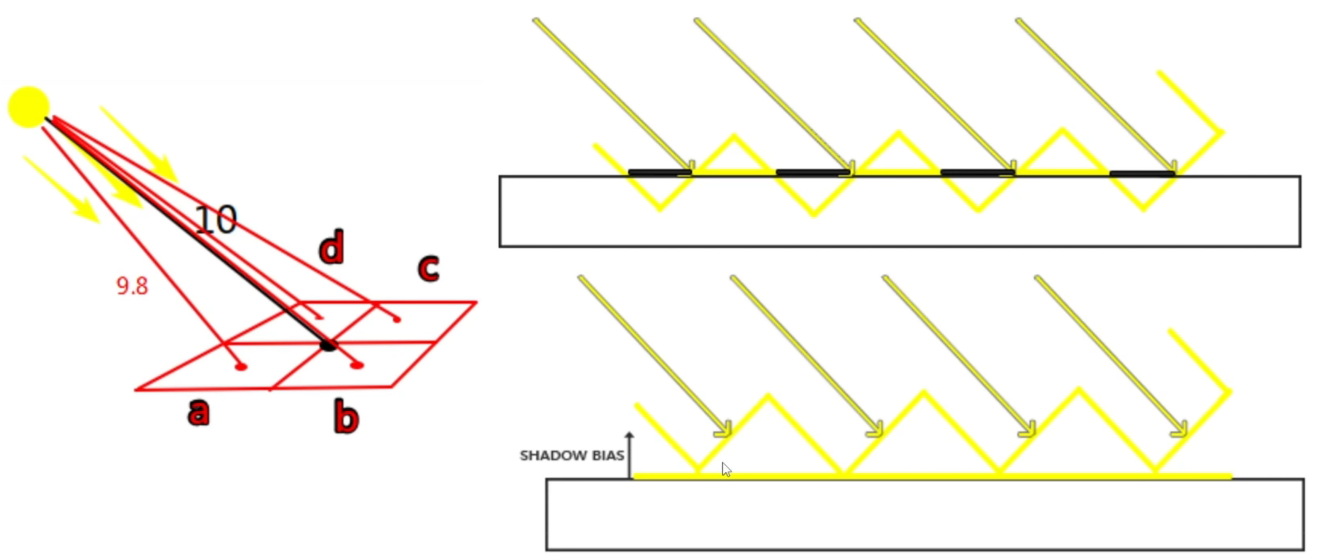
- 阴影失真 Shadow Acne:材质出现摩尔纹

- 阴影失真是由于阴影贴图的分辨率不够造成的,如左图:假设采样在格子正中心深度值为 10,由于光源位置会导致 a、b、c、d 计算的深度不一(本来应该一样亮),a、d 值小则亮,b、c 值大则暗,从而交替出现上面明暗交错的条纹
- 在《Learn OpenGL》第35章中的图示如右,没看懂
- 通过增加偏移,使之消失
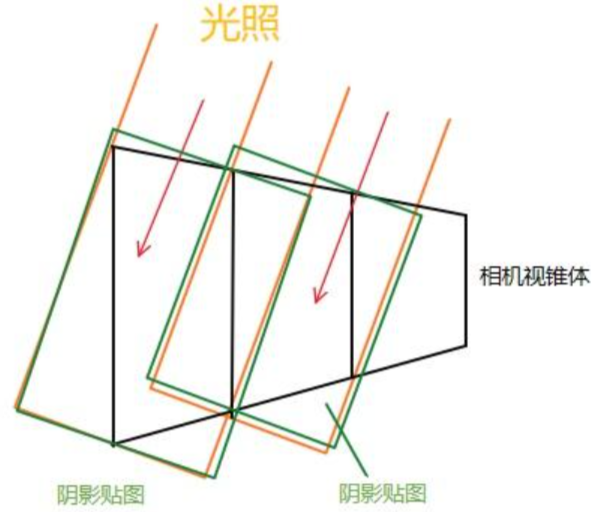
4.2.2 Cascaded Shadow 级联阴影
- 区别于传统阴影贴图将所有物体渲染在一张贴图中的方法(近距离物体的分辨率不够)
- 级联阴影分割视锥,使用多张不同精细度的阴影贴图(近相机的使用精细的阴影贴图,远离相机的使用粗糙的阴影贴图),保证渲染效率
4.2.3 逐对象阴影
- 针对可移动的物体,使用逐对象阴影

- 逐对象阴影为固定光源(光源位置固定,颜色/强度 可变),既保证了分辨率,又保证了贴图使用率

4.2.4 距离场阴影
- 距离场阴影:根据参数不同,可以生成不同的软阴影,不需要针对模型运行阴影 Pass

- 距离场可以理解为空间函数,定义了任意点到场景中其他点的最短距离,通过计算光源与场景中物体相切的临界点,得到阴影区和半影区(软阴影)
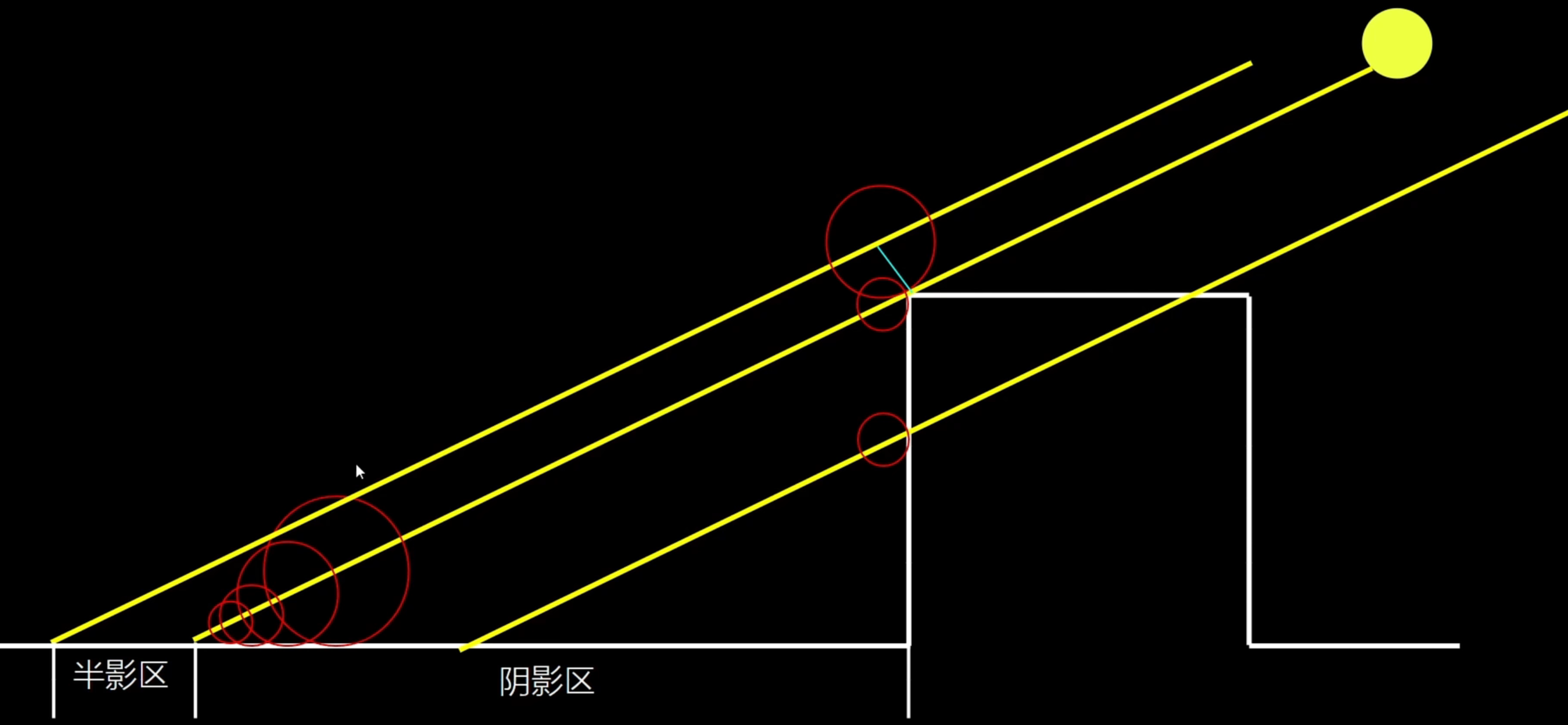
- 因为需要直接光照,光源需要为固定或可移动
- 目前,距离场阴影只对静态网格体有效,需离线生成 Mesh Distance Field(UE4 中默认关闭,UE5 默认开启)
- 优先级:CSM > DFS > Traditional Shadow
- 运行会实时生成 Global Distance Field,然后是 Ray Marching
4.2.5 其他阴影
- Contact Shadow:对于小的物体有较好的细节
- Capsule Shadow:用简化的模型来染阴影
4.2.6 动态光照和阴影的性能提示
- 动态光照和阴影的性能提示:
- 渲染阴影的性能损耗大,通常需要降低渲染质量来补偿
- 动态光照不会对大部分的内容产生辐射或全局光照
- 动态光照不会生成“真正的”软阴影,只是模拟软阴影的效果来实现
- 动态光照在场景中看起来更“真实”(闪烁等,光线非常锐利)
- 动态光照在延迟渲染中性能损耗相对少,但是在前向渲染中损耗大
- 像素越多性能越慢(光源距离相机越近,受影响的像素越多,性能也就越慢)
- 光源半径需要尽可能小,避免重叠进行多次着色计算
4.3 Lumen 和 VSM
- UE5 全动态全局光照和反射系统 Lumen 以及阴影解决方案 VSM
- Lumen 使用了全动态的间接光照管线,这意味着场景里的几何体、材质、光源属性都可以实时修改,因此 Lumen 大大减少了烘焙时间
- UE4 中,主要通过直接光照来实现动态光照,很难计算间接光照(都是粗略估算或基于烘焙的全局光照),处理全局光照需要巨大的计算量,而实时全局光照的计算就更困难了
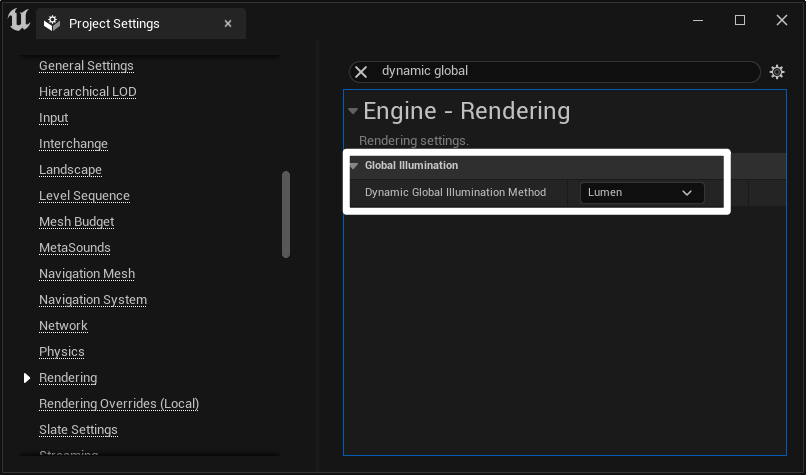
- UE5 默认打开 Lumen,UE4 打开 Lumen 的选项设置:
- 开启动态 GI 方法 Dynamic Global IIIumination Method:Lumen
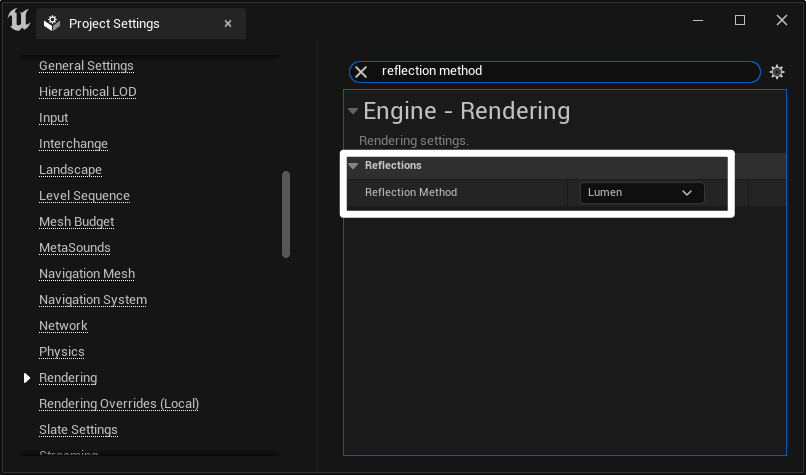
- 开启反射方式 Reflection Method:Lumen
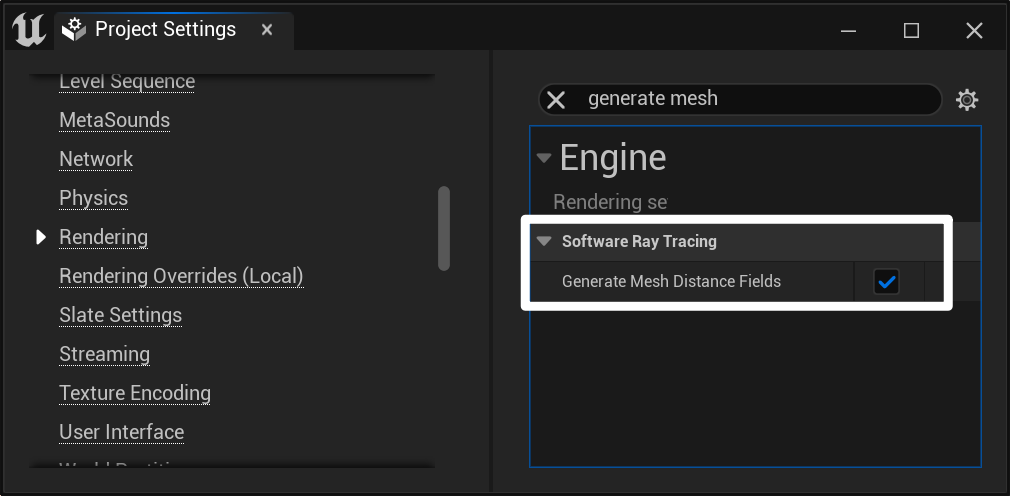
- 开启 MDF 生成 Generate Mesh Distance Fields
- Lumen 支持的新特性:
- Color bleeding:被照物体表面的颜色可以影响周围物体表面的颜色,以提供逼真光照基础细节

- Soft indirect shadow:间接软阴影,场景中没有受到间接光照的物体依然投下阴影

- Multi-bounce indirect illumination:多重反射间接照明,Lumen 通过追踪前一帧的光照来计算当前帧的光照

- Emissive materical:自发光材质
- Skylight emissive:天空光自发光
- Lumen 原理说明:
- 光线追踪是处理全局光照最常用的方法,通过追踪光线来模拟光线和物体相交时的效果,并生成图像。在光线追踪中,全局光照需要大量的追踪来生成间接漫反射、软阴影、二次反射等等

- Lumen 使用了混合的追踪方法:首先追踪屏幕上的光线,只追踪屏幕光线无法覆盖全部的场景,Lumen大量使用了硬件加速的光线追踪

- 为了支持老设备,Lumen 通过有向距离场来生成简化场景来加速追踪,因此也提供了光线追踪的软件方案

- 由于直接采样追踪到的三角形会有巨大消耗,Lumen 通过采样表面缓存的方式,加速计算光照结果
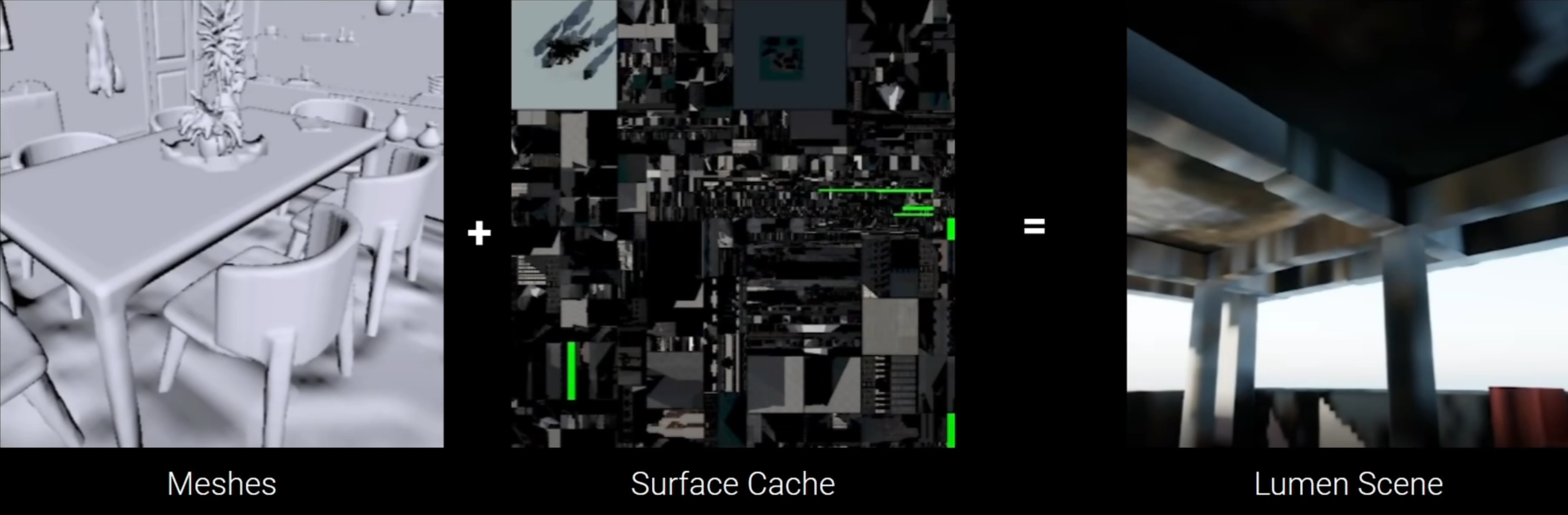
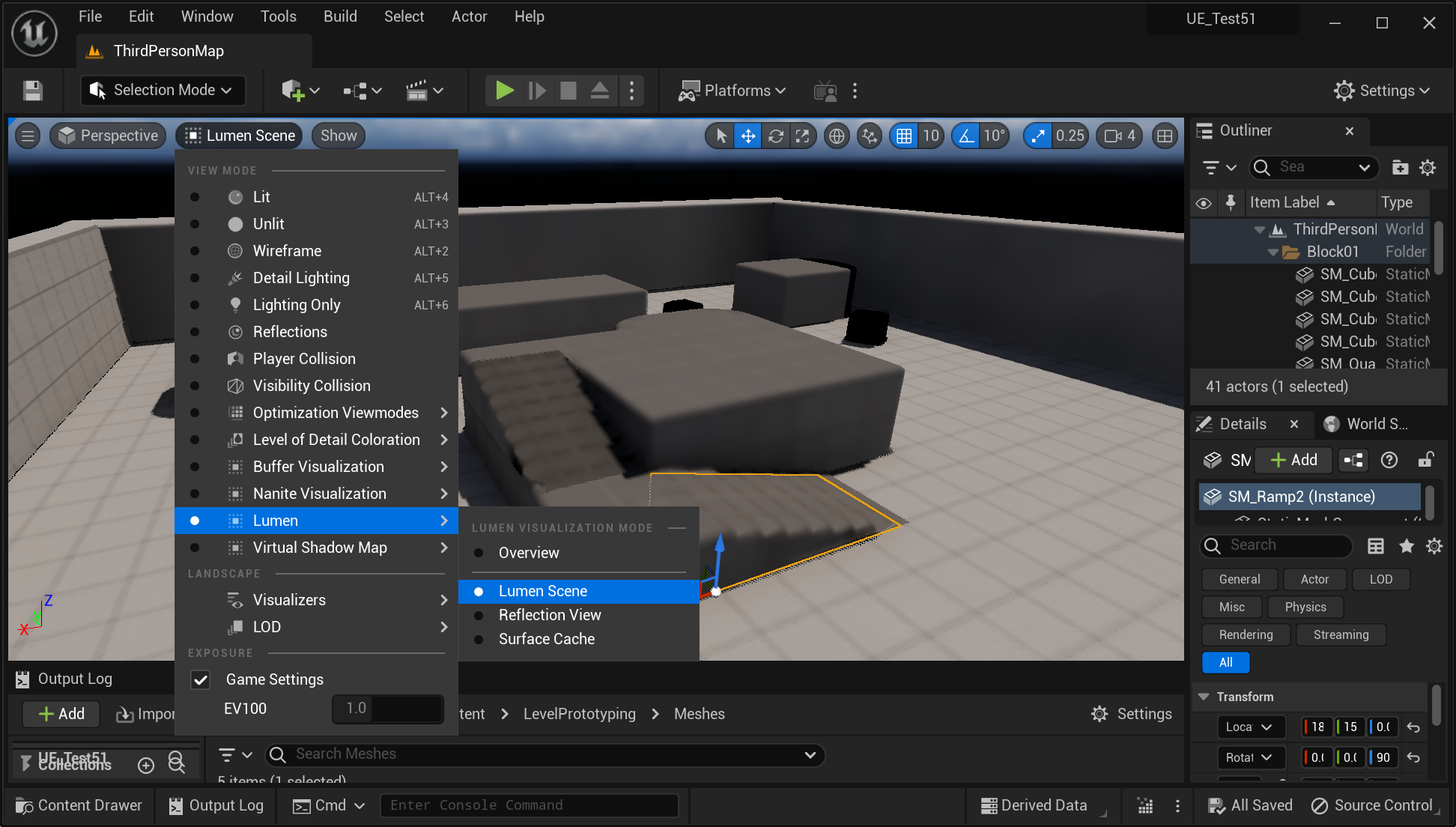
- 开启 Lumen Scene,获取 Lumen 光线追踪器所视内容
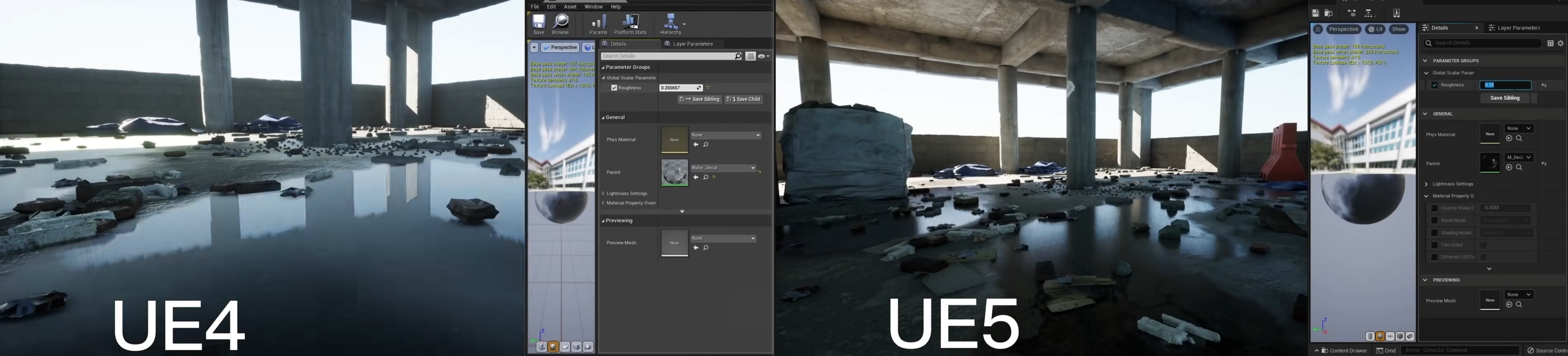
- Lumen 通过 Lumen Scene 数据生成全局光照、阴影、反射等,因此 Lumen Scene 也可以被直接用来计算场景反射,而不用在场景中放置“反射捕获”

- 在 UE4 的屏幕空间反射和光线追踪反射中,粗糙材质会被直接忽略,但 Lumen 会为粗糙材质计算出更好的反射结果(在项目中一旦启用了 Lumen,就会取代屏幕空间反射和光线追踪反射)
4.4 半透明材质
- 延迟渲染管线难以处理半透明材质,一般是在前向渲染管线中完成半透明物体的渲染,然后将前向渲染结果与延迟渲染结果合并
- 半透明材质的渲染放在渲染流程后半段(渲染排序也会增加性能的损耗),是实时渲染中的性能影响因素之一
- 多层半透明平面平行,像素被多次渲染,穿过一层透明平面则减轻一层渲染消耗(像素被多层半透明材质覆盖时,重叠层数越多,性能损耗越大)

4.5 后期处理
- 后期处理是在渲染流程最后阶段应用的视觉特效,很大程度上依赖于像素着色器,通过合成实现(再度使用 G-Buffer 来计算效果):
- Bloom
- DOF
- Lensflare
- Vignette
- Tonemapping
- Motion Blur
- Exposure
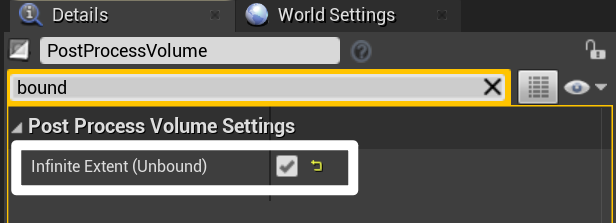
- 通过在场景中放置 Post Process Volume,实现后期处理效果
- 当相机在 Post Process Volume 范围内时,后期处理才会生效,也可以通过设置无穷大的范围,使后期处理一直生效
- Sphere Mask 节点
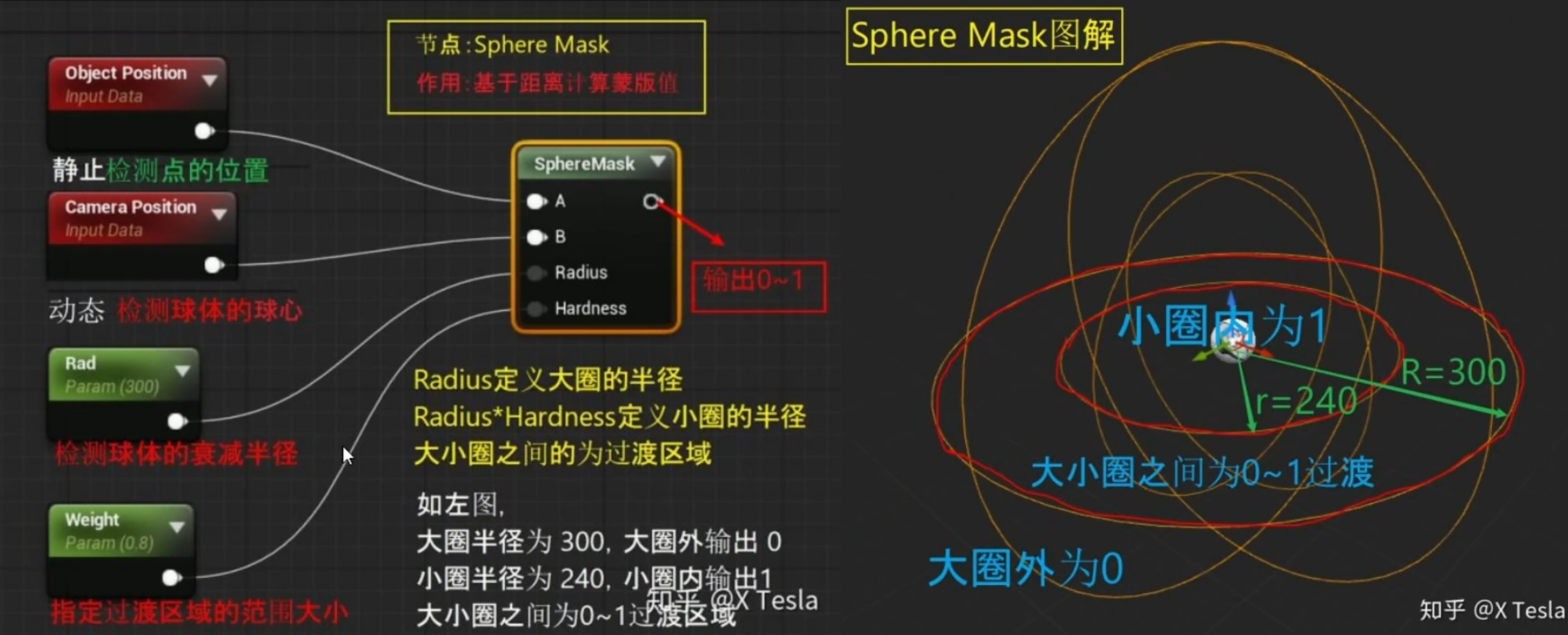
- 后期材质
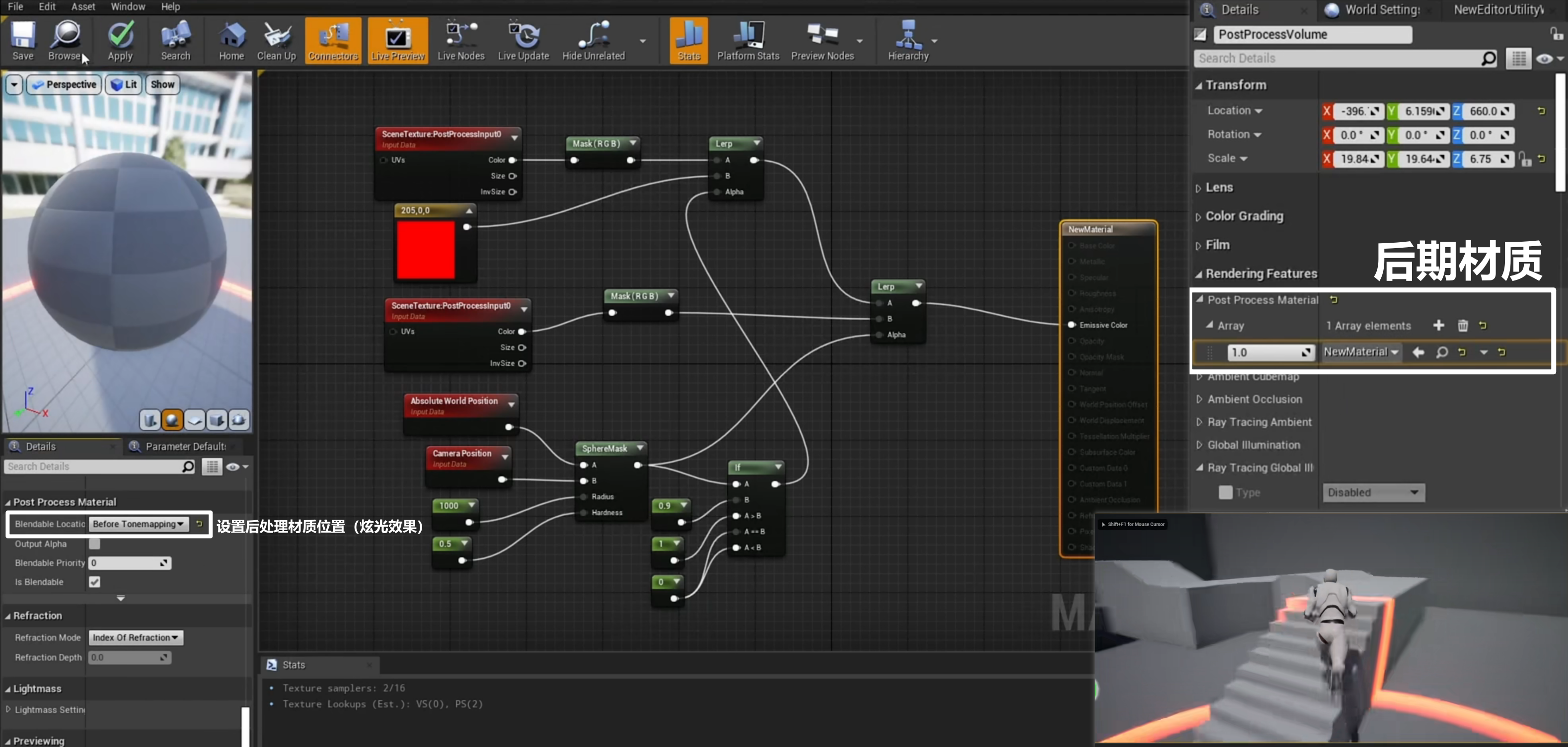
4.6 实时 Ray Tracing
- Ray Tracing:追踪从相机生成的光线,在场景中多次反弹的过程(光线的生成和反弹符合物理规律)
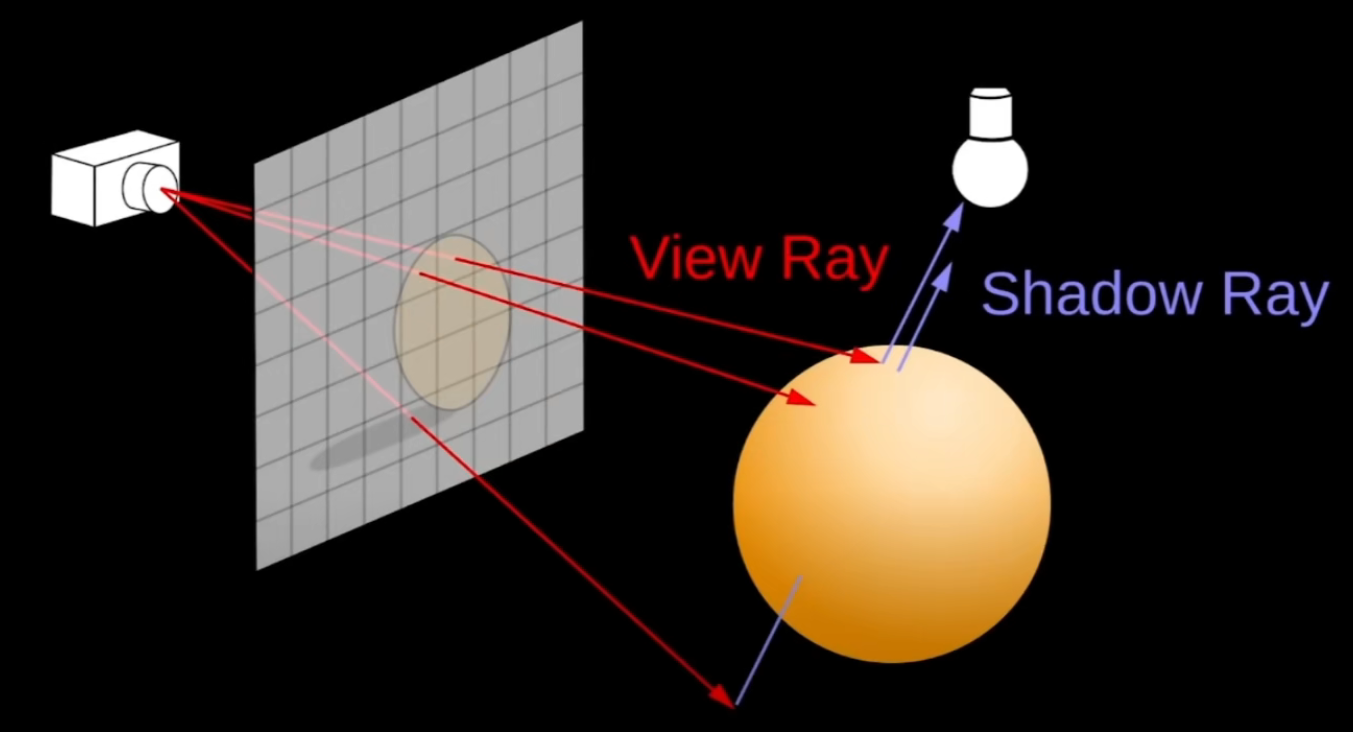
- 从相机射出的光线相交与场景中一点,判断点与光源连接后是否被物体阻挡,从而得到:点是否处于阴影中或点是否需要根据法线反射
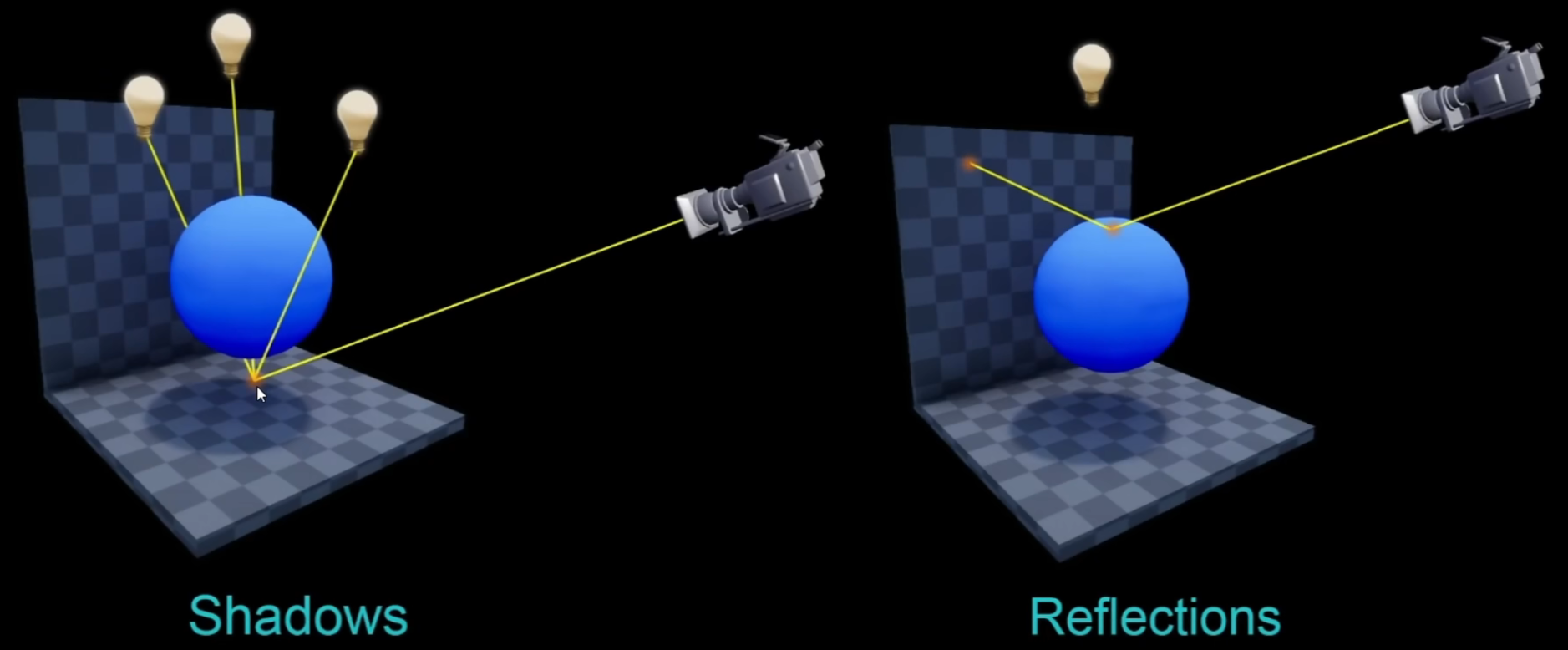
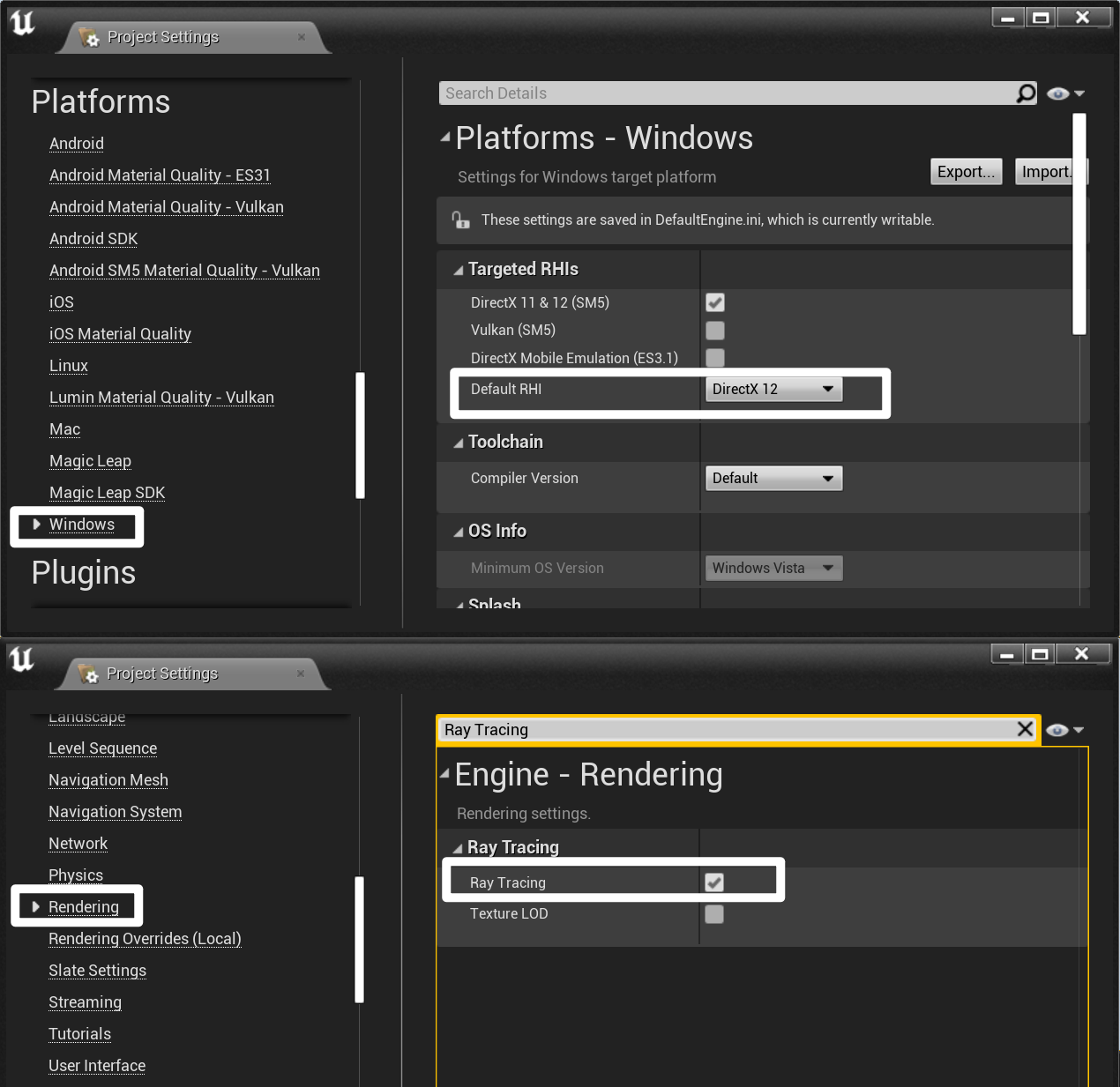
- 使用 Ray Tracing:设置 RHI 为 DirectX 12,并开启 Ray Tracing
五. 性能调试
- 虚幻中常用的性能调试方法:
- Stat 命令
- GPU Visualizer
- Unreal Insight
- Frontend session
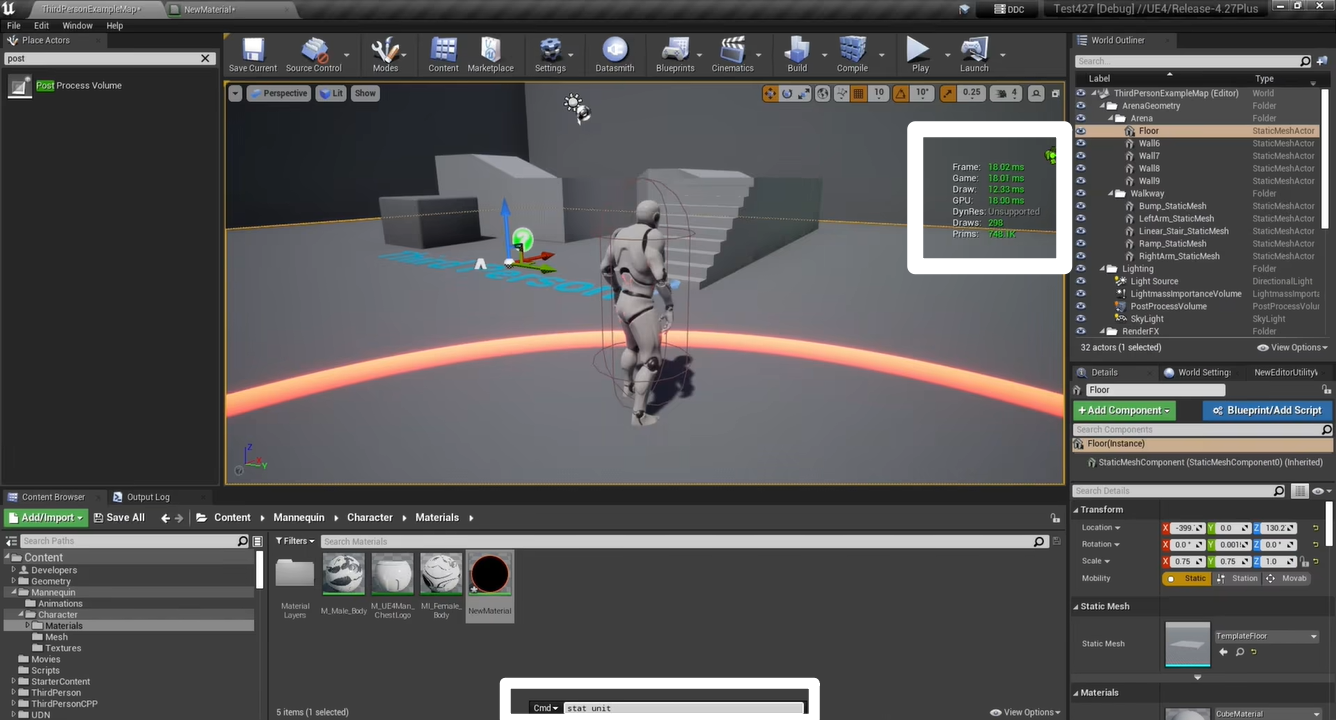
- 性能调试:首先通过
Stat Unit查看不同线程执行的速率,找到瓶颈
- 如上所示,Game 是19,Draw 是12,GPU 是19
- 则 Game 线程和 GPU 线程是瓶颈)
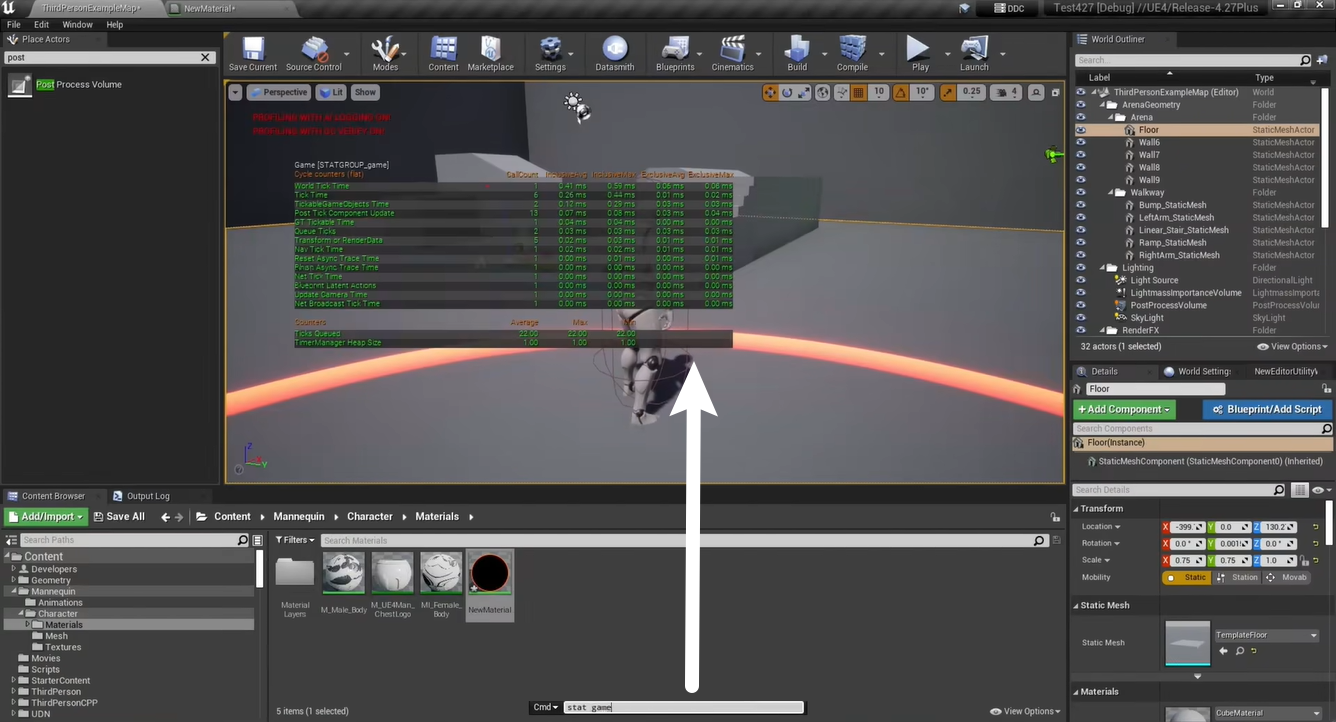
- 通过
Stat Game查看 Game 线程执行时间
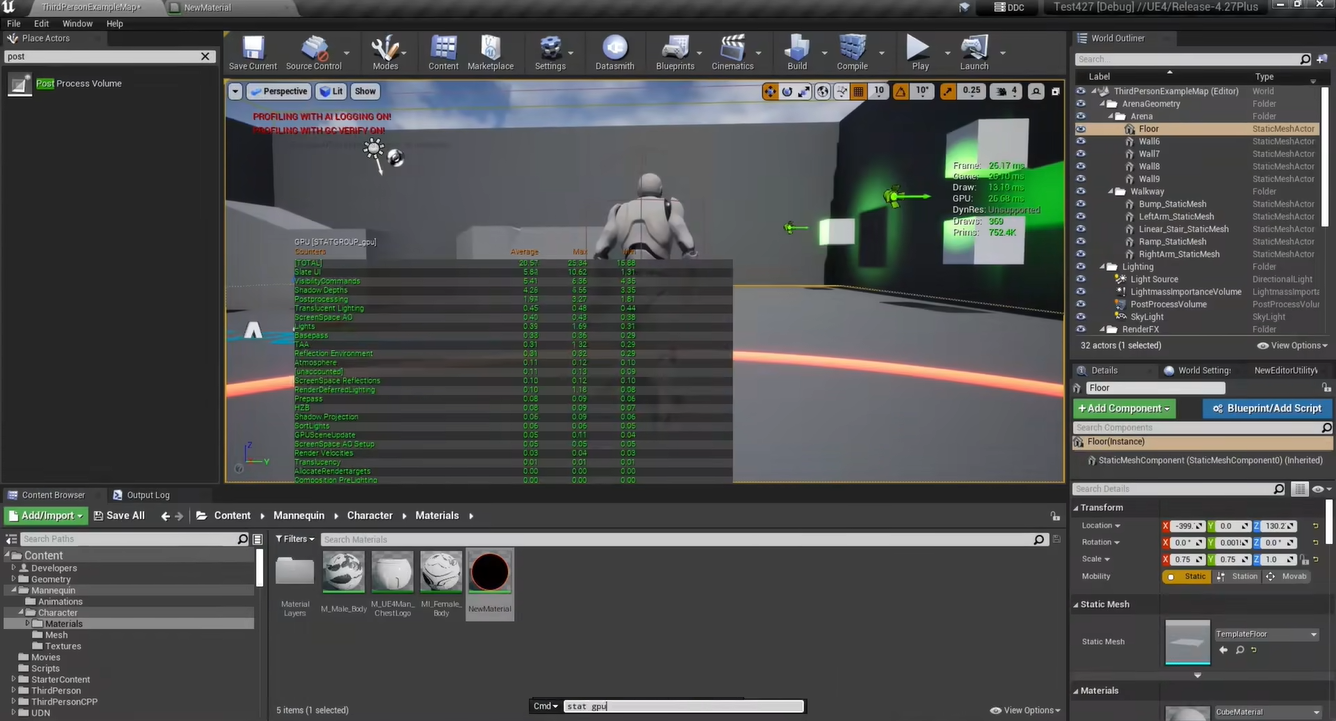
- 通过
Stat GPU查看 GPU 线程中的瓶颈
- 通过快捷键
ctrl+shift+,打开 GPU Visualizer,查看各环节耗时情况
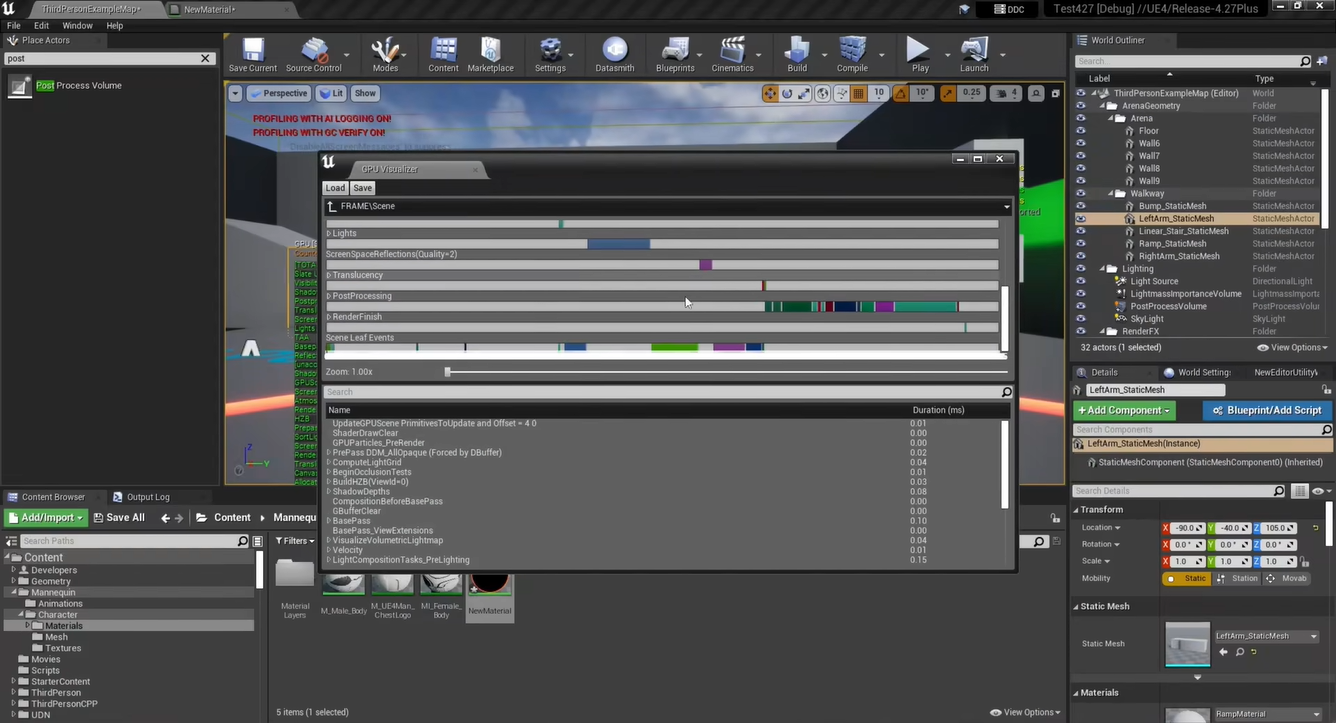
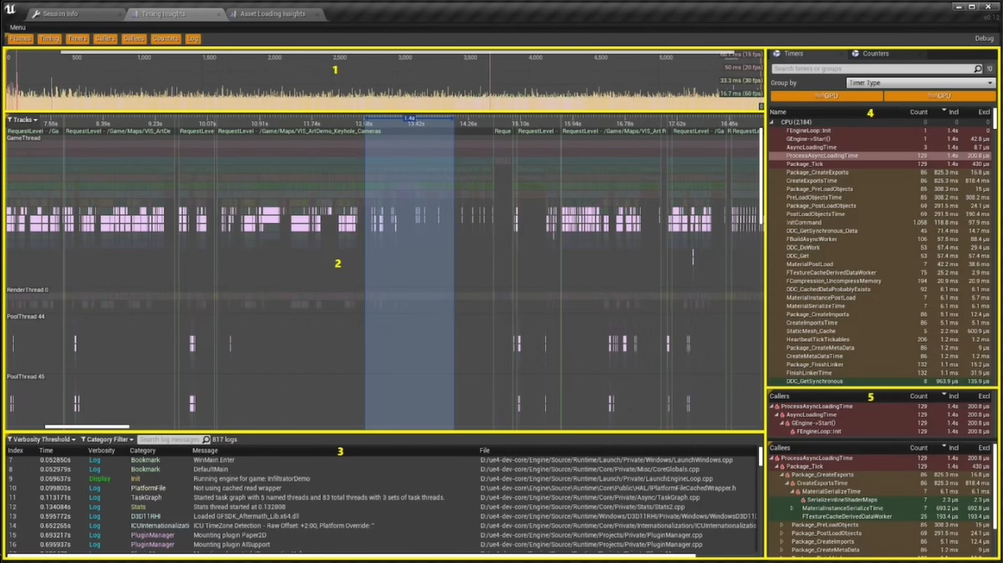
- Unreal Insight 工具:是一个独立的可执行程序,可以帮助开发者识别瓶颈,用于性能优化,还可以用于收集,分析和显示引擎发出的数据(如:各函数运行的时间/次数、当前帧率、不同线程使用情况)
- Unreal Insight 可以轻松添加用户自己的分析数据,且对项目执行的影响非常低


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek “源神”启动!「GitHub 热点速览」
· 我与微信审核的“相爱相杀”看个人小程序副业
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· C# 集成 DeepSeek 模型实现 AI 私有化(本地部署与 API 调用教程)
· spring官宣接入deepseek,真的太香了~