
【数据库系统原理与设计】(六)SQL数据定义、更新及数据库编程
六. SQL数据定义、更新及数据库编程
6.1 SQL数据定义语言
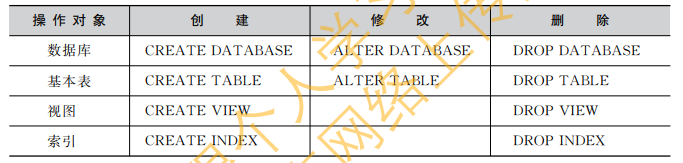
1. SQL数据定义语言DDL包括:
- 数据库的定义:创建、修改和删除
- 基本表的定义:创建、修改和删除视图的定义:创建和删除索引的定义:创建和删除
6.1.1 数据库的定义
1. 数据库的创建
-
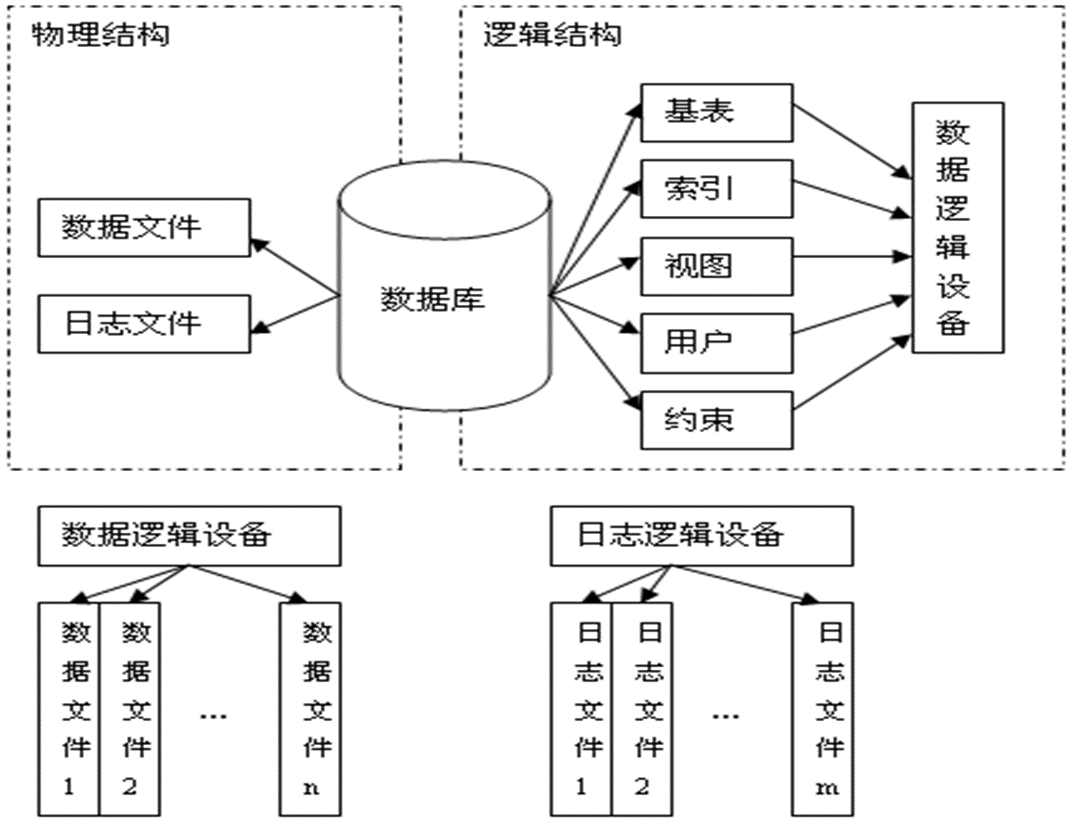
数据库作为一个整体存放在外存的物理文件中
- 物理文件(即磁盘文件)有两种:
- 数据文件,存放数据库中的对象数据
- 日志文件,存放用于恢复数据库的企业冗余数据
- 物理文件可以是多个,可以将一个或若干个物理文件设置为一个逻辑设备
- 数据库可以有多个逻辑设备,必须在定义数据库时进行定义
- 数据库的对象存放在逻辑设备上,由逻辑设备与物理文件进行联系,从而实现数据库的逻辑模式与存储模式的独立
-
个数据库创建在物理介质的一个或多个文件上,它预先分配了将要被数据库和事务日志所使用的物理存储空间
- 存储数据的文件叫做数据文件(data file)
- 存储日志的文件叫做日志文件(log file)
- 创建一个新的数据库时,仅创建了一个空壳,必须在这个空壳中创建对象(如表、索引、约束等),才能使用这个数据库
- 当创建了一个数据库,与该数据库相关的描述信息会存入到数据字典(即数据库系统表)
- 在创建数据库的时候,必须定义数据库的名字、磁盘文件(含数据文件、日志文件)的逻辑设备名(别名)和物理文件名
2. 创建数据库:
CREATE DATABASE <被创建数据库名> ON -- 指定数据库中的数据文件:主数据文件、用户数据文件 -- 定义主逻辑设备的数据文件 [PRIMARY] { <filespec> [, ... n ] } -- 定义用户逻辑设备组的数据文件 [, { FILEGROUP <filegroupName> {<filespec> [, ... n ]} [, ... n ]} ] ] -- 定义数据库日志逻辑设备的日志文件 [LOG ON { <filespec> [, ... n ] } ]
-- <filespec>描述磁盘文件(含数据文件和日志文件) <filespec> ::= 主要包含以下内容 ( [ NAME = <logicalFileName>, ] -- 逻辑文件名(即别名) FILENAME = '<osFileName>' -- 物理文件名 [, SIZE = <size> ] -- 磁盘文件初始大小 [, MAXSIZE = { <maxSize> | UNLIMITED } ] -- 最大可扩展大小 [, FILEGROWTH = <growthIncrement> ] ) -- 每次扩展的步长
eg:创建一个复杂的数据库TempDB
CREATE DATABASE TempDB ON -- 定义数据文件 PRIMARY --定义主逻辑设备的数据文件(共一个) ( NAME = TempDev, FILENAME = 'd:\TempData\TempDev.mdf' , --数据文件的物理文件名 SIZE = 5, FILEGROWTH = 2), FILEGROUP TempHisDev -- 定义第1个用户逻辑设备组1的数据文件(共一个) ( NAME = TempHisDev, FILENAME = 'd:\TempData\TempDev.mdf' , --用户逻辑设备(组1)的物理文件名 SIZE = 10, FILEGROWTH = 5) FILEGROUP TempHisDev1 -- 定义第2个用户逻辑设备组2的数据文件(共两个) ( NAME = TempHisDev1, FILENAME = 'd:\TempData\TempDev1.mdf' , --用户逻辑设备(组2)的第1个物理文件名 SIZE = 20, FILEGROWTH = 10), ( NAME = TempHisDev2, FILENAME = 'd:\TempData\TempDev2.mdf' , --用户逻辑设备(组2)的第2个物理文件名 SIZE = 20, FILEGROWTH = 10) LOG ON -- 定义数据库日志逻辑设备的日志文件(共两个) ( NAME = 'TempLogDev1', FILENAME = 'd:\TempData\TempLogDev1.ldf' , --第1个日志文件的物理文件名 SIZE = 5MB, FILEGROWTH = 2MB), ( NAME = 'TempLogDev2', FILENAME = 'd:\TempData\TempLogDev2.ldf' , --第2个日志文件的物理文件名 SIZE = 10MB, FILEGROWTH = 5MB)
3. 修改数据库:
(一次只能修改其中一个选项)
ALTER DATABASE <被修改的数据库名> -- 添加 数据文件/逻辑设备(组)/日志文件 到数据库 { ADD FILE {<filespec> [, ...n]} | ADD FILEGROUP <filegroupName> | ADD LOG FILE {<filespec> [, ... n]} -- 指定文件添加到<filegroupName>逻辑设备(组)中 [TO FILEGROUP <filegroupName>] -- 从数据库系统表中删除文件,并物理删除该文件 | REMOVE FILE <logicalFileName> -- 从数据库系统表中删除该逻辑设备(组),并删除其中所有数据文件 | REMOVE FILEGROUP <filegroupName> -- 指定要修改的 文件/逻辑设备(组)(包含文件名、大小、增长量、最大容量) | MODIFY FILE <filespec> | MODIFY FILEGROUP <filegroupName> <filegroupProperty> }
eg:修改TempDB数据库:将逻辑文件名(即别名)为TempHisDev1的磁盘文件的初始大小修改为20M
ALTER DATABASE TempDB MODIFY FILE ( NAME = TempHisDev1, SIZE = 20MB )
4. 删除数据库:
DROP DATABASE <被删除的数据库名>
6.1.2 基本表的定义
1. SQL中的基本数据类型:
-
整型:int (4B),smallint (2B),tinyint (1B);
-
实型:float,real (4B),decimal(p, n),numeric(p, n);
-
字符型:char(n),varchar(n),text(存放大文本数据);
-
2进制型:binary(n),varbinary(n),image(存储图象的数据类型);
-
逻辑型:bit,只能取0和1,不允许为空;
-
货币型:money (8B, 4位小数),small money (4B, 2位小数);
-
时间型:datetime (4B, 从1753.1.1开始),smalldatetime (4B, 从1900.1.1开始)
2. 创建基本表
CREATE TABLE <被创建的基本表名> ( <基本表中的列名1> <数据类型> [DEFAULT <defaultValue>] [null | NOT null], -- 为列设置缺省值,为列设置是否为空值 [ <基本表中的列名2> <数据类型> [DEFAULT <defaultValue>] [null | NOT null], … ] -- 为列设置缺省值,为列设置是否为空值 [ [CONSTRAINT <约束的名字1>] {UNIQUE | PRIMARY KEY} -- 指定某列取值唯一,主码 (<列名1> [, <列名2>…]) [ON <filegroupName>], ... ] -- 将数据库对象放在指定的逻辑设备(组)上 [ [CONSTRAINT <约束的名字2>] FOREIGN KEY (<列名1> [, <列名2>…] ) -- 外码 REFERENCE [<dbName>.owner.]<refTable> (<refColumn1> [, <refColumn2>… ]) [ON <filegroupName>], ... ] ) [ON <filegroupName>]
eg:建立学生成绩管理数据库中的5张基本表
CREATE TABLE Course (-- 创建课程表Course courseNo char(3) NOT NULL, --课程号 courseName varchar(30) UNIQUE NOT NULL, --课程名 creditHour numeric(1) DEFAULT 0 NOT NULL, --学分 courseHour tinyint DEFAULT 0 NOT NULL, --课时数 priorCourse char(3) NULL, --先修课程 /* 建立命名的主码约束和匿名的外码约束 */ CONSTRAINT CoursePK PRIMARY KEY (courseNo), FOREIGN KEY (priorCourse) REFERENCES Course(courseNo) -- 外码约束是匿名的 )
CREATE TABLE Class (-- 创建班级表Class classNo char(6) NOT NULL, --班级号 className varchar(30) UNIQUE NOT NULL, --班级名 institute varchar(30) NOT NULL, --所属学院 grade smallint DEFAULT 0 NOT NULL, --年级 classNum tinyint NULL, --班级人数 CONSTRAINT ClassPK PRIMARY KEY (classNo) ) CREATE TABLE Term (-- 创建学期表Term termNo char(3) NOT NULL, --学期号 termName varchar(30) NOT NULL, --学期描述 remarks varchar(10) NULL, --备注 CONSTRAINT TermPK PRIMARY KEY (termNo) ) CREATE TABLE Student (-- 创建学生表Student studentNo char(7) NOT NULL, --学号 studentName varchar(20) NOT NULL, --姓名 sex char(2) NULL, --性别 birthday datetime NULL, --出生日期 native varchar(20) NULL, --籍贯 nation varchar(30) DEFAULT ‘汉族’ NULL, --民族 classNo char(6) NULL, --所属班级 CONSTRAINT StudentPK PRIMARY KEY (studentNo), CONSTRAINT StudentFK FOREIGN KEY (classNo) REFERENCES Class(classNo) ) CREATE TABLE Score (-- 创建成绩表Score studentNo char(7) NOT NULL CHECK (studentNo LIKE '[0-9][0-9][0-9][0-9][0-9][0-9][0-9]'), --学号 courseNo char(3) NOT NULL , --课程号 termNo char(3) NOT NULL, --学期号 score numeric(5, 1) DEFAULT 0 NOT NULL , --成绩 /* 建立由3个属性构成的命名的主码约束 */ CONSTRAINT ScorePK PRIMARY KEY (studentNo, courseNo, termNo), /* 建立三个命名的外码约束 */ CONSTRAINT ScoreFK1 FOREIGN KEY (studentNo) REFERENCES Student(studentNo), CONSTRAINT ScoreFK2 FOREIGN KEY (courseNo) REFERENCES Course(courseNo), CONSTRAINT ScoreFK3 FOREIGN KEY (termNo) REFERENCES Term(termNo) )(上述5张基本表的创建都缺省了ON <filegroup_name>,建立的对象存放在主逻辑设备上)
eg:在MyTempDB数据库中建立TempTable表,存放在用户逻辑设备(组) TempBakDev上
CREATE TABLE TempTable ( xno char(3) NOT NULL, xname varchar(2) NOT NULL, -- 匿名定义主码约束,由系统对主码约束进行命名 PRIMARY KEY (xno) ) ON TempBakDev --指定所创建的基本表存放在给定逻辑设备上
3. 修改基本表
- 增加列(新增一列的值为空值)
ALTER TABLE <表名> ADD <列名> <数据类型>
- 增加约束
ALTER TABLE <表名> ADD CONSTRAINT <约束名>
- 删除约束
ALTER TABLE <表名> DROP <约束名>
- 修改列的数据类型
ALTER TABLE <表名> ALTER COLUMN <列名> <新的数据类型>
eg:在 MyTempDB 数据库中为TempTable 表增加一列
ALTER TABLE TempTable ADD xsex int DEFAULT 0
eg:在 MyTempDB 数据库中为 TempTable 表的 xname 列修改数据类型
ALTER TABLE TempTable ALTER COLUMN xname char(10)(基本表在修改过程中,不可以删除列,一次仅执行一种操作)
eg:在 MyTempDB 数据库中为 TempTable 表的 xname 列增加唯一约束
ALTER TABLE TempTable ADD CONSTRAINT UniqueXname UNIQUE (xname)
4. 删除基本表
- 在删除基本表的同时,也删除建立在该基本表上的所有索引、完整性规则、触发器和视图等
- 删除基本表时,系统会同时从数据字典(数据库系统表)中将该基本表的描述信息一起删除
DROP TABLE <表名> [RESTRICT | CASCADE] -- RESTRICT,则该基本表的删除有限制条件 -- CASCADE,则该基本表的删除没有限制条件
eg:删除TempTable表
DROP TABLE TempTable(SQL Server不支持 [RESTRICT | CASCADE] 选项,其删除的限制条件是在创建基本表时定义的)
6.1.3 索引的定义
- 索引由 <搜索码值,指针> 的记录构成,是加快数据检索的一种工具
- 一个基本表可以建立多个索引,从不同角度加快查询速度,但如果索引建立得较多,会给数据维护带来较大的系统开销
- 索引中的记录(称为索引项)按照搜索码值的顺序进行排列,但不改变基本表中记录的物理顺序
- 索引创建后,与该索引相关的描述信息会保存到数据字典中
- 数据库的索引一般按照B+树结构来组织,但也有Hash索引和位图索引等
- 索引的类型:
- 聚集
- 聚集索引按搜索码值的某种顺序(升/降序)来重新组织基本表中的记录(索引的顺序就是基本表记录存放的顺序)
- 聚集索引提高了查询速度,但不易数据修改(所以聚集索引的基本表一般仅执行查询操作)
- 每个基本表仅能建立一个聚集索引
- 非聚集(普通索引)
- 一个基本表可以建立多个普通索引
- 聚集
1. 建立索引
CREATE [UNIQUE] [CLUSTERED | NONCLUSTERED] INDEX <索引名称(唯一)> -- UNIQUE:建立唯一索引(要求索引属性或属性组上的取值必须唯一) -- CLUSTERED | NONCLUSTERED:建立聚集或非聚集索引(默认为非聚集索引) ON <表名> ( <列名1> [ASC | DESC] [, <列名2> [ASC | DESC] … ] ) -- ASC | DESC:为按升序还是降序建立索引(默认为升序) [ON <filegroupName>] -- 指定索引存放在哪个逻辑设备上,该逻辑设备必须是创建数据库时定义的,或通过修改已加入到数据库中的(默认将索引建立在主逻辑设备上)
eg:对班级表Class按所属学院建立非聚集索引InstituteIdx
CREATE NONCLUSTERED INDEX InstituteIdx ON Class(institute)
eg:在学生表Student中,首先按班级编号的升序,然后按出生日期的降序建立一个非聚集索引ClassBirthIdx
CREATE INDEX ClassBirthIdx ON Student(classNo, birthday DESC)
2. 删除索引
- 索引一旦建立,用户不需要管理它,由系统自动维护
- 可删除那些不经常使用的索引
DROP INDEX <索引名> ON <表名> -- 索引被删除时,系统会同时从数据字典(数据库系统表)中将该索引的描述信息一起删除
eg:删除班级表Class中建立的InstituteIdx索引
DROP INDEX InstituteIdx ON Class
6.2 SQL数据更新语言
- SQL数据更新语句包括三条
- 插入INSERT
- 删除DELETE
- 修改UPDATE
6.2.1 插入数据
- ① 插入一个元组(一个记录)
INSERT INTO <表名> [ (<列名1> [, <列名2> ... ] ) ] VALUES (<value1> [, <value2> ... ] ) -- 若表中属性没有对应列,系统自动取空值
- ② 插入子查询(多个元组/多个记录)
INSERT INTO <表名> [ ( <列名1> [, <列名2> ... ] ) ] <由 SELECT 语句引出的一个子查询>
eg:将一个新学生元组('0700006', '李相东', '男', '1991-10-21 00:00', '云南', '撒呢族', 'CS0701')插入到学生表Student中
INSERT INTO Student VALUES ( '0700006', '李相东', '男', '1991-10-21 00:00', '云南', '撒呢族', 'CS0701' )(表名Student后没有指定属性名,表示按照Student表定义的属性列的个数和顺序将新元组插入到Student表中)
eg:将一个新学生元组(姓名:章李立,出生日期:1991-10-12 00:00,学号:1500007)插入到学生表Student中
INSERT INTO Student(studentName, birthday, studentNo) VALUES ( '章李立', '1991-10-12 00:00', '0700007' )(按照指定属性的顺序和属性的个数,向学生表Student插入一个新元组,没有列出的属性列自动取空值NULL或默认值;
插入新元组时,数据的组织可不按照基本表结构定义的属性个数和顺序进行插入)
eg:将少数民族同学的选课信息插入基本表StudentNation中
-- 创建基本表StudentNation: CREATE TABLE StudentNation ( studentNo char(7) NOT NULL , --学号 courseNo char(3) NOT NULL , --课程号 termNo char(3) NOT NULL, --学期号 score numeric(5, 1) DEFAULT 0 NOT NULL --成绩 CHECK( score BETWEEN 0.0 AND 100.0), CONSTRAINT StudentNationPK PRIMARY KEY (studentNo, courseNo, termNo) ) --执行插入语句: INSERT INTO StudentNation SELECT * FROM Score WHERE studentNo IN ( SELECT studentNo FROM Student WHERE nation<>'汉族'
)
eg:将汉族同学的选课信息插入到StudentNation表中
INSERT INTO StudentNation(studentNo, courseNo, termNo) SELECT studentNo, courseNo, termNo FROM Score WHERE studentNo IN ( SELECT studentNo FROM Student WHERE nation='汉族' ) -- 成绩列自动取0值,而不是空值NULL(因为在定义基本表StudentNation时该列设置了默认值为0)
6.2.2 删除数据
- 删除语法:
DELETE FROM <表名> [WHERE <被删除元组所满足的条件>]
eg:删除学号为1600001同学的选课记录
DELETE FROM Score WHERE studentNo='1600001'
eg:删除选修了“高等数学”课程的选课记录
DELETE FROM Score WHERE courseNo IN ( SELECT courseNo FROM Course WHERE courseName='高等数学' )
eg:删除平均分在60到70分之间的同学的选课记录
DELETE FROM Score WHERE studentNo IN ( SELECT studentNo FROM Score GROUP BY studentNo HAVING avg(score) BETWEEN 60 AND 70 )
6.2.3 修改数据
- 修改语法:
UPDATE <表名> SET <列名1> = <expr1> [, <列名2> = <expr2> ... ] -- 用表达式的值代替属性列的值 [FROM {<表名1> | <queryName1> | <viewName1>} [AS] [<aliasName1>] [, {<表名2> | <queryName2> | <viewName2>} [AS] [<aliasName2>] ... ] [WHERE <被修改元组所满足条件>]
eg:将王红敏同学在151学期选修的002课程的成绩改为88分
UPDATE Score SET score=88 WHERE courseNo='002' AND termNo='151' AND studentNo IN ( SELECT studentNo FROM Student WHERE studentName='王红敏' )或者:
UPDATE Score SET score=88 FROM Score a, Student b WHERE a.studentNo=b.studentNo AND courseNo='002' AND termNo='151' AND studentName='王红敏'
eg:将注册会计16_02班的男同学的成绩都增加5分
UPDATE Score SET score=score+5 FROM Score a, Student b, Class c WHERE a.studentNo=b.studentNo AND b.classNo=c.classNo AND className='注册会计16_02班' AND sex='男'
eg:将学号为1600001同学的出生日期修改为1999年5月6日出生,籍贯修改为福州
UPDATE Student SET birthday='1999-5-6 00:00', native='福州' WHERE studentNo='0800001'
eg:将每个班级的学生人数填入到班级表的ClassNum列中
UPDATE Class SET classNum=sCount FROM Class a, ( SELECT classNo, count(*) sCount FROM Student GROUP BY classNo ) b WHERE a.classNo=b.classNo
注意:插入、删除和修改操作会破坏数据的完整性,如果违反了完整性约束条件,其操作会失败
6.3 视图
- 视图是虚表,是从一个或几个基本表(或视图)中导出的表
- 在数据字典(数据库系统表)中仅存放创建视图的语句,不存放视图对应的数据
- 当基本表中的数据发生变化时,从视图中查询出的数据也随之改变
- 视图实现了数据库管理系统三级模式中的外模式
- 基于视图的操作包括
- 查询
- 删除
- 受限更新
- 创建基于该视图的新视图
- 视图的主要作用:
- 简化用户的操作
- 使用户能以多种角度看待同一数据库模式
- 对重构数据库模式提供了一定程度的逻辑独立性
- 对数据库中的机密数据提供一定程度的安全保护
- 适当利用视图可以更清晰的表达查询
6.3.1 创建视图
- 创建语法:
CREATE VIEW <视图名(唯一)> [(<视图中列名1> [, <视图中列名2> ... ]) ] AS <subquery> -- 子查询不允许含有ORDER BY子句和DISTINCT短语 [WITH CHECK OPTION] -- 当对视图进行插入、删除和修改操作时,必须满足创建视图中的条件
eg:创建仅包含1999年出生学生的视图StudentView1999
CREATE VIEW StudentView1999 -- 省略了视图的列名,自动取查询出来的列名 AS SELECT * FROM Student WHERE year(birthday)=1999-- 创建视图中的条件 -- 没有使用WITH CHECK OPTION选项
-- 可插入不满足上面条件的数据(能插入98年的),但查询不出该数据
eg:创建仅包含1999年出生学生的视图StudentView1999Chk, 并要求在对该视图进行更新操作时,进行合法性检查(即保证更新操作要满足创建视图中的谓词条件)
CREATE VIEW StudentView1999Chk AS SELECT * FROM Student WHERE year(birthday)=1999 -- 创建视图中的谓词条件 WITH CHECK OPTION -- 修改/删除/插入操作,必须满足上面的条件(不能插入98年的)
eg:创建一个包含学生学号、姓名、课程名、获得的学分和相应成绩的视图ScoreView
CREATE VIEW ScoreView AS SELECT a.studentNo, studentName, courseName, creditHour, score FROM Student a, Course b, Score c WHERE a.studentNo=c.studentNo AND b.courseNo=c.courseNo AND score>=60 -- 成绩必须大于等于60分才能获得学分(如果某学生选修某门课程2次且都考试及格,则视图的查询结果中会出现2次)
eg:创建一个包含每门课程的课程编号、课程名称、选课人数和选课平均成绩的视图SourceView
CREATE VIEW SourceView(courseNo, courseName, courseCount, courseAvg) -- 使用聚合函数,必须为视图的属性命名,可在视图名的后面直接给出列名 AS SELECT a.courseNo, courseName, count(*), avg(score) FROM Course a, Score b WHERE a.courseNo=b.courseNo GROUP BY a.courseNo, courseName或者:
CREATE VIEW SourceView1 AS SELECT a.courseNo, courseName, count(*) courseCount, avg(score) courseAvg FROM Course a, Score b WHERE a.courseNo=b.courseNo GROUP BY a.courseNo, courseName
eg:创建一个包含每门课程的课程编号、课程名称、选课人数和选课平均成绩的视图SourceView2,要求该视图选课人数必须在5人以上
CREATE VIEW SourceView2 AS SELECT * FROM SourceView -- 基于视图 SourceView WHERE courseCount>=5 -- 创建视图中的条件
eg:创建一个包含学生学号、姓名和年龄的视图StudentAgeView
CREATE VIEW StudentAgeView AS SELECT studentNo, studentName, year(getdate())-year(birthday) age FROM Student
6.3.2 查询视图
- 查询视图的过程:
- 有效性检查(检查查询中涉及的基本表和视图是否存在)
- 从数据字典中取出创建视图的语句,将创建视图的子查询与用户的查询结合起来,转换成等价的对基本表的查询
- 执行改写后的查询
eg:在视图StudentView1999中查询CS1601班同学的信息
SELECT * FROM StudentView1999 -- 基于视图 StudentView1999 的查询 WHERE classNo='CS1601'
-- 系统首先进行有效性检查:判断视图StudentView1999是否存在 -- 如果存在,则从系统的数据字典中取出该创建视图的语句 -- 将创建视图中的子查询与用户的查询结合起来,转换为基于基本表的查询,即将视图StudentView1999的定义转换该查询为: SELECT * FROM Student WHERE year(birthday)=1999 AND classNo='CS1601' -- 然后系统执行改写后的查询
eg:在视图SourceView中查询平均成绩在80分以上的课程信息
SELECT * FROM SourceView -- 基于视图 SourceView 的查询 WHERE courseAvg>=80 -- 视图SourceView是一个基于聚合运算的视图,列是courseAvg,它是经过聚合函数运算的值 -- 由于在WHERE子句中,不允许对聚合函数进行运算,HAVING子句可以对聚合函数直接作用,系统会将该查询转换为如下的形式: SELECT a.courseNo, courseName, count(*) courseCount, avg(Score) courseAvg FROM Course a, Score b WHERE a.courseNo=b.courseNo GROUP BY a.courseNo, courseName HAVING avg(score)>=80
eg:在视图SourceView和课程表Course中查询课程平均成绩在75分以上的课程编号、课程名称、课程平均成绩和学分
SELECT a.courseNo, a.courseName, courseAvg, creditHour FROM Course a, SourceVIEW b WHERE a.courseNo=b.courseNo AND courseAvg>=75
6.3.3 视图更新
- 视图更新指通过视图来插入、删除和修改基本表中的数据
- 视图不实际存放数据,对视图的更新,最终要转换为对基本表的更新
- 对视图进行更新操作,其限制条件比较多
- 尽量不要对视图执行更新操作
eg:在视图StudentView1999中,将学号为'1600004' 同学的姓名修改为'张小立'
UPDATE StudentView1999 SET studentName='张小立' WHERE studentNo='1600004' -- 系统首先进行有效性检查:判断视图StudentView1999是否存在 -- 如果存在,则从系统的数据字典中取出该创建视图的语句 -- 将创建视图中的子查询与用户查询相结合,转换为对基本表的修改: UPDATE Student SET studentName='张小立' WHERE year(birthday)=1999 AND studentNo='1600004'
eg:在视图StudentView1999中将学号为'1600004'同学的出生年份由1999修改为2000
UPDATE StudentView1999 SET birthday='2000-05-20 00:00:00.000' WHERE studentNo='1600004' -- 在视图 StudentView1999Chk 中不能将出生年份修改为2000,因为该视图对修改操作进行了条件检查
eg:在视图StudentView1999中将学号为'1600006'的同学记录删除
DELETE FROM StudentView1999 WHERE studentNo='1600006' -- 系统将该操作转化为如下的操作: DELETE FROM Student WHERE year(birthday)=1999 AND studentNo='1600006' --创建视图中的谓词条件
eg:在视图SourceView中删除平均成绩大于80分的课程记录
DELETE FROM SourceView WHERE courseAvg>=80 -- 对于该操作,数据库管理系统拒绝执行 -- 因为视图SourceView中包含了聚合运算,系统无法将该视图转化为对基本表的操作(如果是行列子集视图(视图基于基本表创建且保留了主码属性),则可以对该视图进行更新操作;其它类型的视图,具体的数据库系统有具体的定义,一般不对其进行更新操作)
6.3.4 删除视图
- 删除语法:
DROP VIEW <视图名> [CASCADE] -- CASCADE为可选项,选择表示级联删除 --(如果该视图上还导出了其他视图,使用CASCADE级联删除语句,把该视图和由它导出的所有视图一起删除)
eg:删除视图 StudentView1991 及级联视图 SourceView
-- 删除视图StudentView1991: DROP VIEW StudentView1991 -- 级联删除视图SourceView: DROP VIEW SourceVIEW CASCADE
6.4 T-SQL语言简介
6.4.1 表达式
1. 变量
- 局部变量:@
- 全局变量:@@
- 常用的系统全局变量
- @@ERROR:事务成功时返回 0,否则返回最近一次的错误号
- @@ROWCOUNT:返回受上一语句影响的行数
- @@FETCH_STATUS:返回最近一次 FETCH 语句执行后的游标状态
- @@VERSION:返回 SQL Server 当前安装的日期、版本、处理器类型
- 变量的声明
DECLARE<@变量名><数据类型>
- 变量的赋值
-- 单个变量 SET <@变量名>=<expr>
-- 变量列表 SELECT <@变量名1>[= <expr | 列名1>] <@变量名2>[= <expr | 列名2>]
eg:在 ScoreDB 数据库中,查询 Score 表中的最高成绩,如果最高成绩大于95分,则显示“very good!”
USE ScoreDB GO DECLARE @score numeric SELECT @score = (SELECT max(score) FROM Score) IF @score > 95 PRINT'very good!'
2. 运算符
- 算术运算符:+,-,*,/ ,%(取余)
- 比较运算符:>,>=,<,<=,=,<>,!=
- 逻辑运算符:AND,OR,NOT
- 位运算符::&.(按位与),|(按位或),~(按位非),^(按位异或)
- 字符串连接运算符:+
- 赋值语句: SELECT(一次可给多个变量赋值),SET(一次仅能给一个变量赋值)
3. 显示表达式的值
SELECT <expr>[<aliasName>] <expr>[<aliasName>]
6.4.2 函数
1. 数学函数
- 主要包括绝对值函数 abs、随机数函数 rand、四舍五人函数 round、上取整函数 ceiling、下取整函数 floor、指数函数 exp、平方根函数 sqrt 等
2.字符串函数
- 对函数参数提供的 字符串(char / varchar)输入值执行操作,返回一个 字符串 / 数值

3. 日期和时间函数
- 对函数参数提供的 日期 / 时间 输入值执行操作,返回一个 字符串 / 数字 / 日期 / 时间值

4. 系统函数
- 返回信息
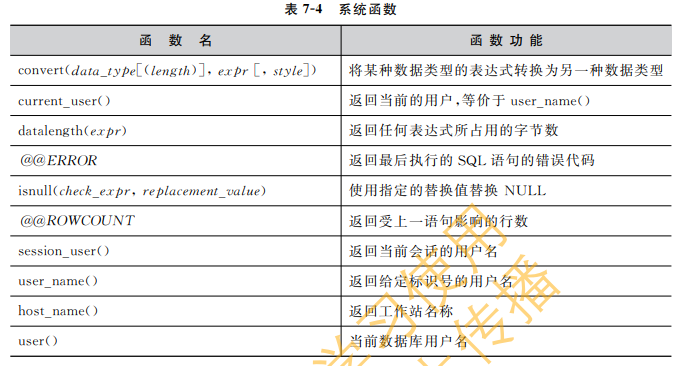
- convert 函数
convert( 数据类型[(可选参数)],expr[,(日期格式样式)]) -- 系统所提供的数据类型,包括bigint和sql_ _variant等 -- nchar .nvarchar、char、varchar、binary或varbinary 数据类型的可选参数 -- expr:任何有效的SQL Serve表达式 -- 日期格式样式:将datetime或smalldatetime数据转换为字符数据(nchar.nvarchar、char、varchar nchar或nvarchar 数据类型);或将float、real 、money或smallmoney数据转换为字符数据( nchar. nvarchar. char、varchar. nchar或nvarchar数据类型)
![]()
![]()
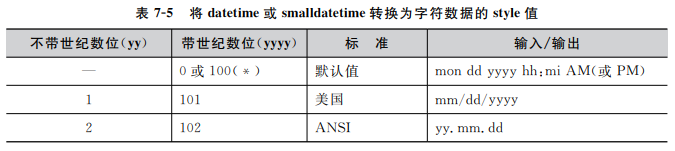
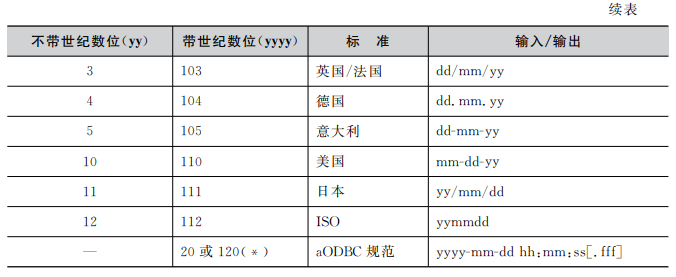
eg:将当前系统的时间按104格式输出
SELECT convert (char(20), getdate(), 104)
eg:获取 当前登录的用户名和主机名
SELECT user_ name(), host_ name()
- isnull 函数
isnull (check_ expr, replacement_ value) -- check_expr:将被检查是否为NULL的表达式,check_expr可以是任何类型的 -- replacement_ value: 在 check_ expr 为 NULL 时将返回的表达式,replacement_value 必须与 check_expr 具有相同的类型
eg: 在 ScoreDB 数据库中,查询 Score 表中学号 1500002 学生的平均成绩,如果成绩 score 列为空则用 60 分替换
USE ScoreDB GO SELECT avg (isnull (score, 60)) FROM Score WHERE studentNo= '1500002'
eg:在图书借阅数据库BookDB中查找读者“张小娟”所借图书的图书名,借阅日期、归还日期,如果没有归还,显示未还书
SELECT bookName, borrowDate, isnull (convert (char (10), returnDate, 120), '未还书') FROM Reader a, Borrow b, Book c WHERE a.readerNo= b. readerNo AND b. bookNo= c . bookNo AND reade rName= '张小娟'
6.4.3 流程控制语句
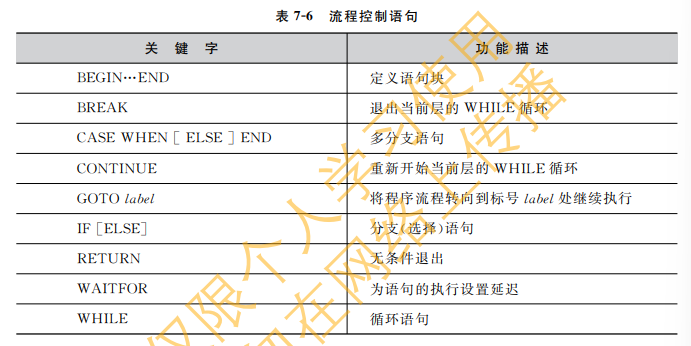
eg:在学生表 Student 中,如果有蒙古族学生,则显示“存在蒙古族的学生”
IF EXISTS (SELECT* FROM Student WHERE nation= '蒙古族') PRINT '存在蒙古族的学生'
eg:列出成绩表 Score 中的所有选课记录,要求根据学期号 termNo 的不同取值分别显示开课时间为 xx年下半年、xx年上半年、xx年暑期小学期,根据成绩 score 的不同取值分别显示等级为优良(80分及以上)、合格和不及格(小于60分)。如'152'显示为“16年上半年”
SELECT studentNo 学号,courseNo课程号, CASE right (termNo, 1) WHEN '1' THEN left (termNo, 2)+ '年下半年' WHEN '2' THEN str (convert (tinyint, left(termNo, 2))+1, 2)+ '年上半年' ELSE str (convert (tinyint, left (termNo, 2))+1, 2)+ '年暑期小学期' END 开课时间, CASE WHEN score>=80 THEN '优良' WHEN score>=60 THEN '合格' ELSE '不及格' END等级 FROM Score
eg:显示 100~200之间的素数
/* 对于一个正整数 n,如果除了 1 和自身之外没有其他因子,则该数就称为素数,也称为质数 **由于因子是成对出现的,因此,如果在 2 ~ sqrt(n) 之间找不到因子,则 n 就是索数 */ DECLARE @k int, @n int SET @n= 100 WHILE @ n<= 200 -- 寻找 100~ 200 之间的素数 BEGIN SET @k=2 WHILE @k<=sqrt(@ n) --在 2-sqpt (@ n) 之间找 @n 的因子 BEGIN IF @n % @k = 0 -- 表示@k是@n的一个因子,因此可以判断@n不是素数 BREAK -- 退出当前循环 SET @k=@ k+1 END IF @k>sqrt(@ n) --表示@n是素数,输出它 PRINT @n SET @n=@n+ 1 END -- 其中: --为单行注释符;/ */为多行注释符,注释的第- -行用/*开始,接下来的注释行用* *开始,最后一个注释行的末尾用* /结束注释
-----------
6.5 游标
6.6 存储过程
6.7 触发器
- 触发器是用户定义在关系表上的一类由事件驱动的存储过程,由服务器自动激活
- 在 SQL Server 中使用两个特殊的表用在触发器语言中
- deleted 表
- 存储DELETE和UPDATE语句执行时所影响的行的复制
- 在DELETE和UPDATE语句执行前被作用的行转移到deleted表中(将被删除的元组或修改前的元组值存人该表中)
- inserted 表
- 存储INSERT和UPDATE语句执行时所影响的行的复制
- 在INSERT和UPDATE语句执行期间,新行被同时加到inserted表和触发器作用的表中(将被插人的元组或修改后的元组值存人该表中,同时也更新触发器作用的基本表)
- 实际上,UPDATE命令是删除后紧跟着插人,旧行首先复制到deleted表中,新行同时复制到inserted表和触发器作用的基本表中
- deleted 表
- 触发器仅在当前数据库中生成,触发器有3种类型
- 插入:INSERT类型的触发器
- 删除:UPDATE类型的触发器
- 修改:DELETE类型的触发器
- 在触发器内不能使用如下的SQL命令
- ① 所有数据库对象的生成命令,如CREATE TABLE、CREATE INDEX等
- ② 所有数据库对象的结构修改命令,如ALTER TABLE、ALTER DATABASE等
- ③ 创建临时保存表
- ④ 所有DROP命令
- ⑤ GRANT和REVOKE命令
- ⑥ TRUNCATE TABLE命令
- ⑦ LOAD DATABASE和LOAD TRANSACTION命令
- ⑧ RECONFIGURE命令
6.7.1 创建触发器
CREATE TRIGGER <触发器名> ON <表名> FOR <INSERT | UPDATE | DELETE> -- INSERT类型的触发器是指当对指定表执行了插人操作时系统自动执行触发器代码 -- UPDATE类型的触发器是指当对指定表执行了修改操作时系统自动执行触发器代码 -- DELETE类型的触发器是指当对指定表StableName>执行了删除操作时系统自动执行触发器代码 AS <sql_statement> -- 触发动作的执行体(一段SQL语句块)
-- 触发执行体中通常会对该触发动作是否会破坏预设的数据库完整性和安全性等约束条件进行判断
-- 如果预设的数据库完整性和完全性等约束条件遭到破坏,则激活触发器的事件就会终正,触发器的目标表或触发器可能会影响的其他表不发生任何变化(执行事务的回滚操作)
6.7.2 修改触发器
ALTER TRIGGER <触发器名> ON <表名> FOR <INSERT | UPDATE | DELETE> AS <sql_statement>
6.7.3 删除触发器
DROP TRIGGER <触发器名>
未完待续...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号