

【数据库系统原理与设计】(五)关系数据理论与模式求精
五. 关系数据理论与模式求精
5.1 问题提出
1. 数据冗余导致的问题:
- 冗余存储:信息被重复存储,导致浪费大量存储空间
- 更新异常:当重复信息的一个副本被修改,所有副本都必须进行同样的修改。因此当更新数据时,系统要付出很大的代价来维护数据库的完整性,否则会面临数据不一致的危险
- 插入异常:只有当一些信息事先已经存放在数据库中时,另外一些信息才能存入数据库中
- 删除异常:删除某些信息时可能丢失其它信息
2. 模式分解导致的问题
- 将一个关系模式分解为较小关系模式集可解决冗余问题。但由此可能产生两个新的问题:
- 什么样的关系模式需要进一步分解为较小的关系模式集?
- 根据范式要求决定(后面讨论)
- 是否所有的模式分解都是有益的?
- 实例
- 什么样的关系模式需要进一步分解为较小的关系模式集?
- 模式分解存在的问题
- 有损分解:两个分解后的关系通过连接运算还原得到的信息与原来关系的信息不一致
- 丢失依赖关系
3. 一个“好”的关系模式应该是:
- 数据冗余尽可能少(即数据共享尽可能高)
- 不发生插入异常、删除异常、更新异常等问题
- 模式分解时,分解后的模式应具有无损连接、 保持依赖等特性
5.2 函数依赖定义
1. 函数依赖
- α函数确定β , 或β函数依赖于α,记作 α→β

- α→β 函数依赖图:

- 函数依赖是指关系模式r(R)的所有关系实例均要满足的约束条件
- 函数依赖是语义范畴的概念,只能根据数据的语义来确定函数依赖,是不能够被证明的
- 数据库设计者可以对现实世界作强制的规定
- 码约束是函数依赖的一个特例
2. 平凡与非平凡函数依赖
- 若 α→β,但 β¢(不属于)α,则称 α→β 是非平凡函数依赖。否则,若β属于α, 则称 α→β 是平凡函数依赖

- 平凡与非平凡函数依赖图:

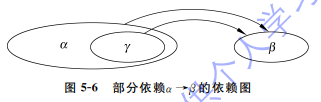
3. 完全函数依赖和部分函数依赖

- 部分 α→β 依赖图:
4. 传递函数依赖


5.3 范式
- 基于函数依赖理论,关系模式可分成
- 第一范式(1NF):所有属性都是原子的
- 第二范式(2NF):不存在非主属性对候选码的部分依赖
- 第三范式(3NF):不存在非主属性对候选码的传递依赖
- Boyce-Codd范式(BCNF)
- 这几种范式的要求一个比一个严格,它们之间的联系为:

- 满足BCNF范式的关系一定满足3NF范式,满足3NF范式的关系一定满足2NF范式,满足2NF范式的关系一定满足1NF范式
5.3.1 第一范式(1NF) ——码

- 第一范式的目标是:将基本数据划分成称为实体集或表的逻辑单元,当设计好每个实体后,需要为其指定主码
- 关系数据库的模式至少应是第一范式
5.3.2 第二范式(2NF) ——全部是码


- 第二范式的目标:将只部分依赖于候选码(即依赖于候选码的部分属性)的非主属性移到其他表中
- 2NF范式虽然消除了由于非主属性对候选码的部分依赖所引起的冗余及各种异常,但并没有排除传递依赖
5.3.3 第三范式(3NF) ——仅仅是码

- 第三范式的目标:去掉表中不直接依赖于候选码的非主属性
- 所有的非主属性应该直接依赖于(即不能存在传递依赖,这是3NF的要求)全部的候选码(即必须完全依赖, 不能存在部分依赖,这是2NF的要求)
5.3.4 Boyce-Codd范式(BCNF)

- 从函数依赖角度可得出,一个满足BCNF的关系模式必然满足下列结论:( 如果 α→β 非平凡, 则 α 是r(R)的一个超码)
- 所有非主属性都完全函数依赖于每个候选码;
- 所有主属性都完全函数依赖于每个不包含它的候选码;
- 没有任何属性完全函数依赖于非候选码的任何一组属性。


- 3NF与BCNF范式的区别在于第3个条件

- 3NF与BCNF比较:
- BCNF比3NF严格。
- 3NF存在数据冗余和异常问题,而BCNF是基于函数依赖理论能够达到的最好关系模式。
- BCNF范式分解是无损分解,但不一定是保持依赖分解;而3NF分解既是无损分解,又是保持依赖分解
5.4 函数依赖理论
5.4.1 函数依赖集闭包


5.4.2 属性集闭包

*5.4.3 正则覆盖
(略...宛如天书)
5.4.4 无损连接分解


5.4.5 保持依赖分解

5.5 模式分解算法
- 数据库设计目标为(基于函数依赖):BCNF、无损连接、保持依赖
- 如果不能同时达到这3个目标,就需要根据实际应用需求在 BCNF 和 3NF 中做出选择
5.5.1 BCNF分解算法

*5.5.2 3NF分解算法

- 该算法能保证3NF分解是无损连接分解和保持依赖分解
- 该算法是基于F的正则覆盖Fc中的函数依赖集进行的
- 一方面正则覆盖可能有多个,另一方面算法执行的结果是依赖于Fc中函数依赖的考虑顺序,因此分解结果可能不唯一
5.6 数据库模式求精
- 基于函数依赖理论的模式求精步骤:
- ①确定函数依赖
- 根据需求分析得到的数据需求,确定关系模式内部各属性之间以及不同关系模式的属性之间存在的数据依赖关系
- ②确定关系模式所属范式
- 按照数据依赖关系对关系模式进行分析,检测是否存在部分依赖或传递依赖,以确定该模式属于第几范式
- ③分析是否满足应用需求
- 按照需求分析得到的数据处理要求,分析现有模式是否满足应用需求,并决定是否需要进行模式合并或分解
- ④模式分解
- 根据范式要求(是选择BCNF还是3NF),运用规范化方法将关系模式分解成所要求的关系模式
- ⑤模式合并
- 在分解过程中可能进行模式合并。如当查询经常涉及到多个关系模式的属性时,系统将经常进行连接操作,而连接运算的代价是相当高的。此时,可考虑将这几个关系合并为一个关系。
- ①确定函数依赖
- END -


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本