kafka基础架构
1.基础概念#
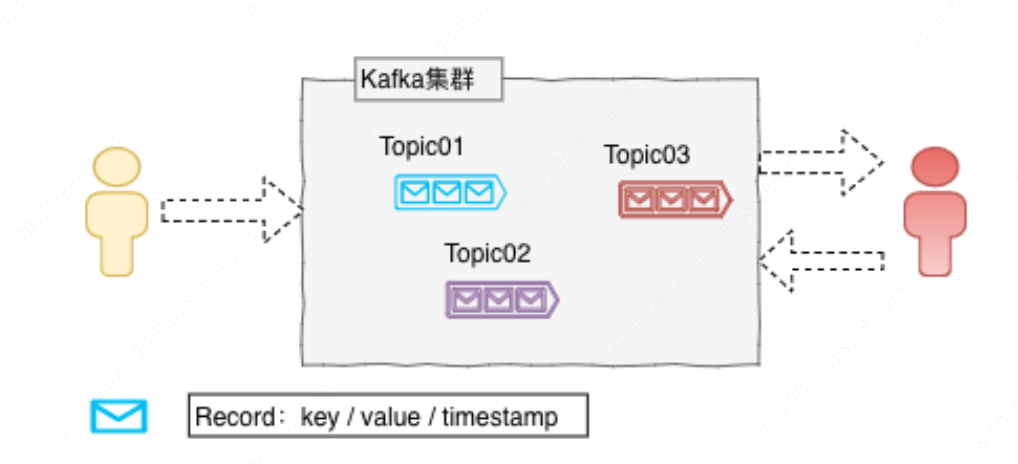
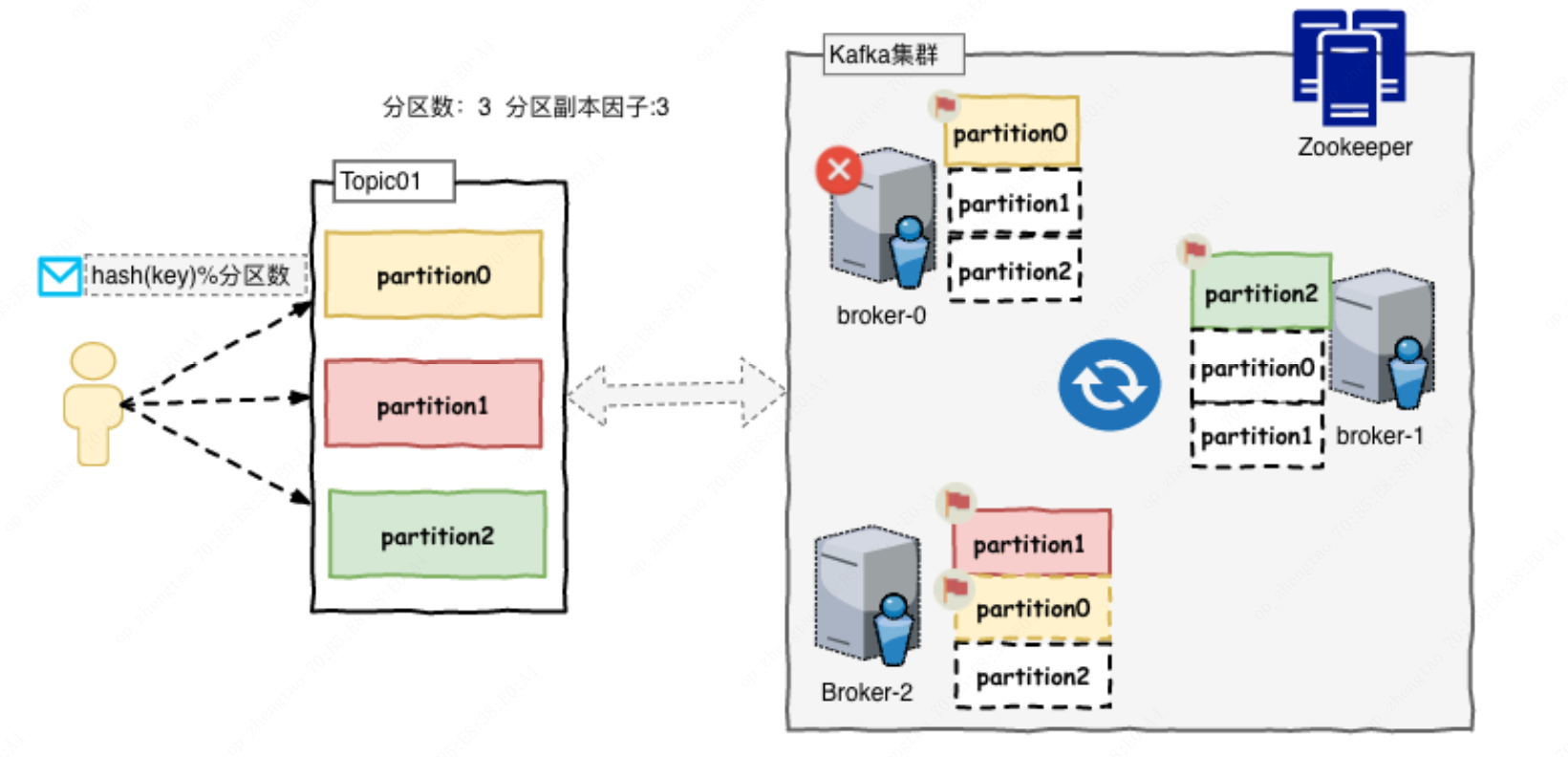
Kafka集群以Topic形式来管理Record,每一个Record属于一个Topic。每个Topic底层都会对应一组分区日志文件,用于持久化Topic中的Record。同时在Kafka集群中,Topic的每一个日志的分区都一定会有1个Borker担当该分区的Leader,其他的Broker担当该分区的Follower,Leader负责分区数据的读写操作,Follower负责同步该分区的数据。这样如果分区的Leader宕机,该分区的其他Follower会选取出新的Leader继续负责该分区数据的读写。其中集群的中Leader的监控和Topic的部分元数据是存储在Zookeeper中。
topic:可以理解为队列名称
record:记录/消息,每条record包含key,value,timestamp
borker:可以理解为安装kafka的服务器节点
leader:负责分区数据读写操作的节点
follower:负责同步分区数据的节点
partition(分区):可以理解为将一个Topic对应的日志文件拆分为多个文件,通过分区可以实现数据的海量存储和高吞吐量
replication(副本因子):表示每一个分区文件的备份
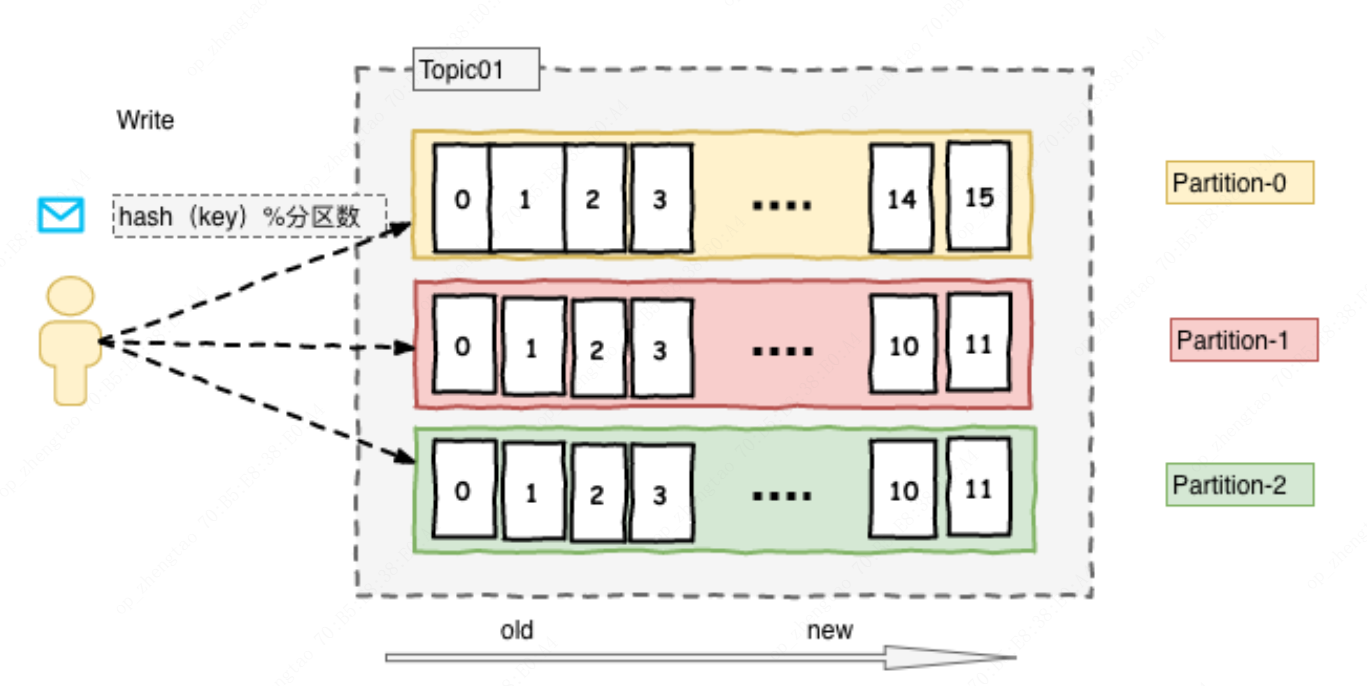
发送消息时分区分发策略:如果发送消息时没有key则默认为轮训,如果有key则通过(hash(key)%分区数)来得到对应的分区
每组日志分区是一个有序的不可变的的日志序列,分区中的每一个Record都被分配了唯一的序列编号称为是offset,Kafka 集群会持久化所有发布到Topic中的Record信息,该Record的持久化时间是通过配置文件指定,默认是168小时(log.retention.hours=168)。Kafka底层会定期的检查日志文件,然后将过期的数据从log中移除,由于Kafka使用硬盘存储日志文件,因此使用Kafka长时间缓存一些日志文件是不存在问题的
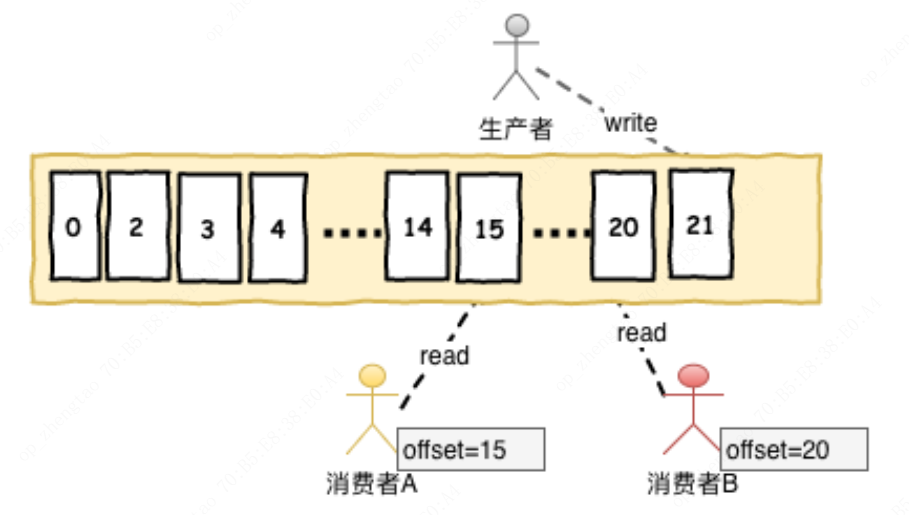
offset:偏移量,kafka消费者在对应分区上已经消费的消息数【位置】
producer(生产者):将数据发布到相应的Topic
consumer(消费者):负责消费Topic中的数据。在消费者消费Topic中数据的时候,每个消费者会维护本次消费对应分区的偏移量,消费者会在消费完一个批次的数据之后,会将本次消费的偏移量提交给Kafka集群,因此对于每个消费者而言可以随意的控制该消费者的偏移量。因此在Kafka中,消费者可以从一个topic分区中的任意位置读取队列数据,由于每个消费者控制了自己的消费的偏移量,因此多个消费者之间彼此相互独立。
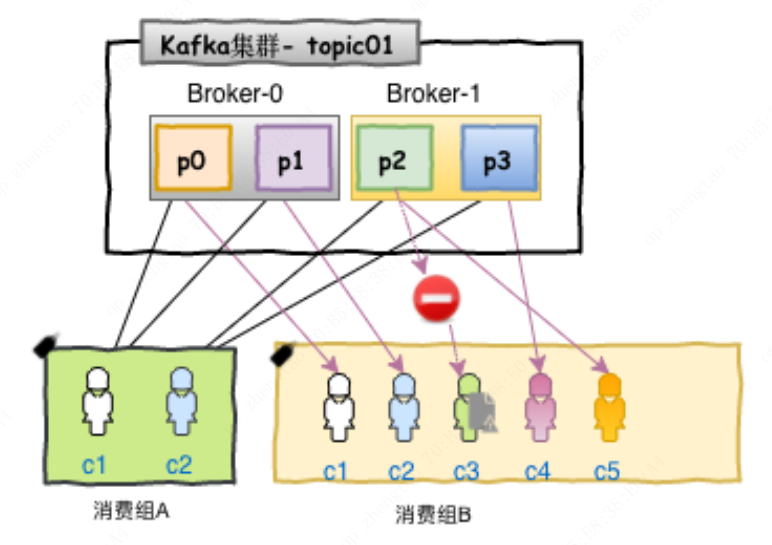
Consumer Group(消费者组):kafka通过消费者组方式去订阅topic,如果有多个消费者属于同一个消费者组去订阅了某个topic,该topic中的同一条消息同一时刻只能被该消费者组中的一个消费者消费(通过均分分区方式来保证同一时刻一个分区只能被分配给消费者组下的一个消费者)。消费者使用Consumer Group名称标记自己,并且发布到Topic的每条记录都会传递到每个订阅Consumer Group中的一个消费者实例。如果所有Consumer实例都具有相同的Consumer Group,那么Topic中的记录会在该ConsumerGroup中的Consumer实例进行均分消费;如果所有Consumer实例具有不同的ConsumerGroup,则每条记录将广播到所有Consumer Group进程。更常见的是我们发现Topic具有少量的Consumer Group,每个Consumer Group可以理解为一个“逻辑的订阅者”。每个Consumer Group均由许多Consumer实例组成,以实现可伸缩性和容错能力。这无非就是发布-订阅模型,其中订阅者是消费者的集群而不是单个进程。这种消费方式Kafka会将Topic按照分区的方式均分给一个Consumer Group下的实例,如果ConsumerGroup下有新的成员介入,则新介入的Consumer实例会去接管ConsumerGroup内其他消费者负责的某些分区,同样如果ConsumerGroup下的有其他Consumer实例宕机,则由该ConsumerGroup其他实例接管。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 周边上新:园子的第一款马克杯温暖上架
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?
· 使用C#创建一个MCP客户端