
PHP 文件操作
计应134(实验班) 郑寿奎
一、文件处理
1打开文件
格式:
resource fopen(string filename,string mode[, bool use_include_path]);
参数filename是要打开的包含路径的文件名可以使相对路径,也可以是绝对路径,mode是打开文件的方式,
use_include_path是否希望服务器在这个路径(配置文件php.ini中指定一个路径)下打开指定的文件
mode的取值列表:
r 只读 只能读
r+ 读写 写入会覆盖原有内容
w 只写 只能写
w+ 读写 如果文件已存在,那么就会删除所有文件的内容,不存在则创建
x 谨慎写 写模式打开文件,创建一个文件从头开始写,存在不会打开文件返回false,PHP将会产生一个警告
x+ 谨慎写 读/写模式打开文件,功能同上
a 追加 文件指针指向尾文件,从末尾开始追加,如果文件不存在,则创建文件
a+ 追加 文件指针指向头文件,功能同上
b 二进制 二进制模式
t 文本
2关闭文件
格式:
bool fclose(resource handle);
3从文件中读取数据
1)读取整个文件readfile()、file()、file_get_contents()
(1)readfile()函数
格式: int readfile(string filename)
读入一个文件并将其写入到输出缓冲,错误返回false
这个函数不需要打开/关闭文件,也不需要echo、print等输出语句,直接写入文件路径即可
(2)file()函数
格式: array file(string filename)
读取整个文件的内容,将内容按行存放到数组中,包括换行符在内。读取错误返回false
(3)file_get_contents()函数
格式: string file_get_contents(string filename[,int offset[, int maxlen]])
将整个文件的内容(filename)读入到一个字符串中。
参数offset和maxlen,将从参数offset所知道的位置开始读取长度为maxlen的一个字符串。读取错误返回false
对三个函数的区别代码如下:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta http-equiv="Content-Type" content="text/html; charset=gb2312" /> <title>读取整个文件</title> <style type="text/css"> <!-- body,td,th { font-size: 12px; } body { margin-left: 10px; margin-top: 10px; margin-right: 10px; margin-bottom: 10px; } --> </style></head> <body> <table border="1" cellspacing="0" cellpadding="0"> <tr> <td width="250" height="25" align="right" valign="middle" scope="col">使用readfile()函数读取文件内容:</td> <td height="25" align="center" valign="middle" scope="col"> <?php readfile('tm.txt'); ?> </td> </tr> <tr> <td height="25" align="right" valign="middle">使用file()函数读取文件内容:</td> <td height="25" align="center" valign="middle"> <?php $f_arr = file('tm.txt'); foreach($f_arr as $cont){ echo $cont."<br>"; } ?></td> </tr> <tr> <td width="250" height="25" align="right" valign="middle" scope="col">使用file_get_contents()函数读取文件内容:</td> <td height="25" align="center" valign="middle" scope="col"> <?php $f_chr = file_get_contents('tm.txt'); echo $f_chr; ?></td> </tr> </table> </body> </html>
其中tm.txt的内容如下图:

运行结果如下图:
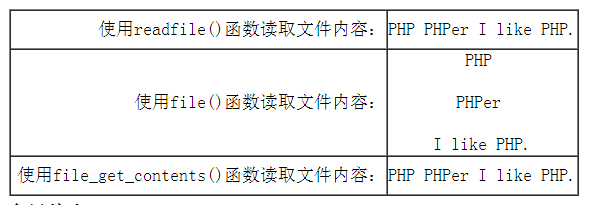
2)读取一行数据fgets()和fgetss()
(1)fgets()函数
格式:string fgets(resource handle[ , int length])
用于一次读取一行数据
参数handle是被读取的文件,length是要读取的数据长度
(2)fgetss()函数
格式:string fgetss(resource handle[ , length[, string allowable_tags]])
用于读取一行数据。同时这个函数会过滤掉被读取内容中的html和php标记
可以使用allowable_tags参数来控制哪些标识不会被过滤
这二个函数区别代码如下:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta http-equiv="Content-Type" content="text/html; charset=gb2312" /> <title>fgets和fgetss的区别</title> <style type="text/css"> <!-- body,td,th { font-size: 12px; } body { margin-left: 10px; margin-top: 10px; margin-right: 10px; margin-bottom: 10px; } --> </style></head> <body> <table border="1" cellspacing="0" cellpadding="0"> <tr> <td height="30" align="right" valign="middle" scope="col">使用fgets函数:</td> <td height="30" align="center" valign="middle" scope="col"> <?php $fopen = fopen('fun.php','rb'); while(!feof($fopen)){ echo fgets($fopen); } fclose($fopen); ?> </td> </tr> <tr> <td height="30" align="right" valign="middle">使用fgetss函数:</td> <td height="30" align="center" valign="middle"> <?php $fopen = fopen('fun.php','rb'); while(!feof($fopen)){ echo fgetss($fopen); } fclose($fopen); ?> </td> </tr> </table> </body> </html>
fun.php内容如下图:
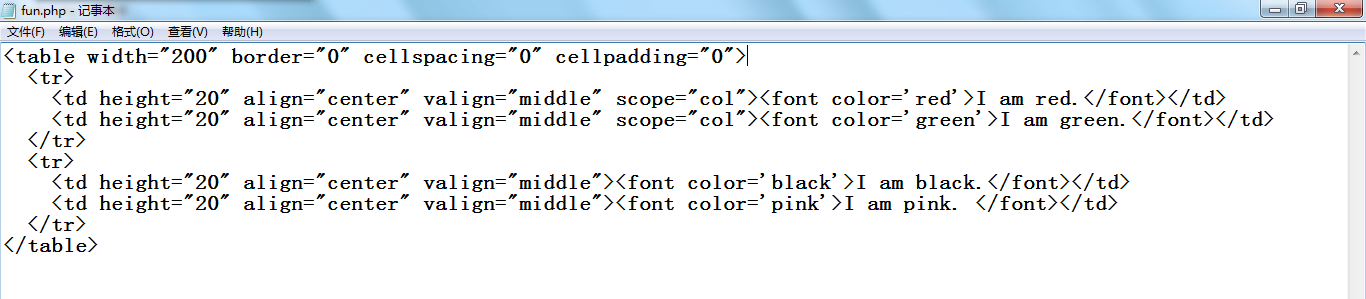
运行结果如下图:

3)读取一个字符fgetc()
格式: string fgetc(resource handle)
读取一个字符,读取完的时候返回false
对文件某一个字符进行查找、替换时,需要针对性地对某个字符进行读取可以使用
使用代码:
<?php $fopen = fopen('03.txt','rb'); //打开文件 while(false !== ($chr = fgetc($fopen))){ //fgetc()读取一个字符,判断是否读取完 echo $chr; //输出 } fclose($fopen); //关闭文件 ?>
03.txt内容如下图:

运行结果如下图:

4)读取指定长度的字串fread()
格式:string(resource handle,int length)
length是指定要读取的字节数
当复制大文件的时候可以用这个读取
<?php $filename = "04.txt"; //要读取的文件 $fp = fopen($filename,"rb"); //打开文件 echo fread($fp,32); //读取指定的字节数 echo "<p>"; echo fread($fp,filesize($filename)); //输出其余文件的内容 ?>
用fread()函数对大文件读写达到复制的效果
<?php $a=fopen("fread.txt","rb"); //打开读取数据的文件 大数据 $b=fopen("fwrite.txt","wb"); //打开写入数据的文件 空的 do{ $c=fread($a,8192); //每次读写819字节 if(!$c){ //判断是否为空,为空即读取完了 break; //跳出整个do...while....循环 }else{ fwrite($b,$c); //写入 把$c里的数据写入到$b文件里去 } }while(true); fclose($a); //关闭文件 fclose($b); //关闭文件 ?>
4将数据写入文件
(1)fwrite()函数
语法格式:int fwrite(resource handle, string string [, int length])
参数handle是打开的文件,string是要写入的数据,length为可选项,写入的长度
(2)file_put_contents()函数
语法格式:int file_put_contents(string filename, string data[ ,int flags])
参数filename是包括路径的文件名,data为要写入的数据
5常用的操作文件函数
bool copy(string path1,string path2) 将文件从path1复制到path2
bool rename(string filename1,string filename2) 把1重命名为2
bool unlink(string filename) 删除文件
int fileatime(string filename) 返回最后一次被访问的时间
int filemtime(string filename) 返回最后一被修改的时间 date('Y-m-d H:i:s',filename('1.txt'))
int filesize(string filename) 取得文件的大小(bytes)
string realpath(string filename) 返回绝对路径
array stat(string filename) 返回一个数组,包括文件的相关信息
array pathinfo(string name [,int options]) 返回一个数组,包含文件name的路径信息。有dirname、basename和extension。可以通过options设置要返回的信息。默认为返回全部
$arr=pathinfo(包含路径的文件名);
foreach($arr as $method =>$value)
{echo $method.":".$value}
二、目录处理
1打开目录
resource opendir(string path)
参数path是一个合法的目录路径
2关闭目录
void closedir(resource handle)
参数handle为opendir()函数打开的一个目录指针
3浏览目录
array scandir(string directory [,int sorting_order])
返回一个数组,包含directory中的所有文件和目录,sorting_order为排序方式,默认为按字母升序排序
例:
<?php //$path = 'D:\PHP\AppServ\www\sl\13\6'; $path=realpath('');//等价于上面一句 获取当前文件所在目录 if(is_dir($path)){ //判断文件名是否为目录 $dir = scandir($path); //使用scandir()函数获取 foreach($dir as $value){ echo $value."<br>"; //循环输出所有信息 } }else{ echo "目录路径错误!"; } ?>
4常用的目录操作函数
bool mkdir(string pathname) 新建一个指定的目录
bool rmdir(string dirname) 删除所指定的目录,该目录必须为空
string getcwd(void) 取得当前工作的目录
bool chdir(string directory) 改变当前目录为directory
float disk_free_space(string directory) 返回目录中的可用空间(bytes)
float disk_total_space(string directory) 返回目录的总空间大小(bytes)
string readdir(resource handle) 返回目录中的下一个文件的文件名
void rewinddir(resource handle) 将指定的目录重新指定到目录的开头
