学习进度笔记(十八)
今天学习了关于爬虫知识的内容。
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做。
在csdn上学习到可以使用PYTHON爬虫比较简单。
我们还需要一些库来支持爬虫的运行(有些库Python可能自带了)
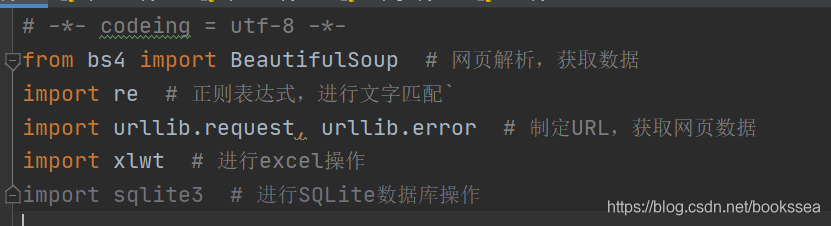
教程中爬取的内容是:电影详情链接,图片链接,影片中文名,影片外国名,评分,评价数,概况,相关信息。
大体流程分三步走:
1. 爬取网页
2.逐一解析数据
3. 保存网页
.逐一解析数据
解析数据这里我们用到了 BeautifulSoup(靓汤) 这个库,这个库是几乎是做爬虫必备的库,无论你是什么写法。
下面就开始查找符合我们要求的数据,用BeautifulSoup的方法以及 re 库的
正则表达式去匹配,
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,标售规则 影片详情链接的规则
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S)
findTitle = re.compile(r'<span class="title">(.*)</span>')
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
findJudge = re.compile(r'<span>(\d*)人评价</span>')
findInq = re.compile(r'<span class="inq">(.*)</span>')
findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
匹配到符合我们要求的数据,然后存进 dataList , 所以 dataList 里就存放着我们需要的数据了。
最后一个流程:
3.保存数据
# 3.保存数据
saveData(datalist,savepath) #2种存储方式可以只选择一种
# saveData2DB(datalist,dbpath)
- 1
- 2
- 3
- 4
保存数据可以选择保存到 xls 表, 需要(xlwt库支持)
也可以选择保存数据到 sqlite数据库, 需要(sqlite3库支持)
这里我选择保存到 xls 表 ,这也是为什么我注释了一大堆代码,注释的部分就是保存到 sqlite 数据库的代码,二者选一就行
保存到 xls 的主体方法是 saveData (下面的saveData2DB方法是保存到sqlite数据库):
def saveData(datalist,savepath):
print("save.......")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) #创建workbook对象
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) #创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
for i in range(0,8):
sheet.write(0,i,col[i]) #列名
for i in range(0,250):
# print("第%d条" %(i+1)) #输出语句,用来测试
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j]) #数据
book.save(savepath) #保存
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
创建工作表,创列(会在当前目录下创建),
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) #创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
- 1
- 2
- 3
然后把 dataList里的数据一条条存进去就行。
最后运作成功后,会在左侧生成这么一个文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号