
学习进度笔记(六)
这次实验很困难,尤其是sbt部分,因为要在外网上下东西,很慢。
这次实验因为恢复了快照,下载了spark、scala、sbt等

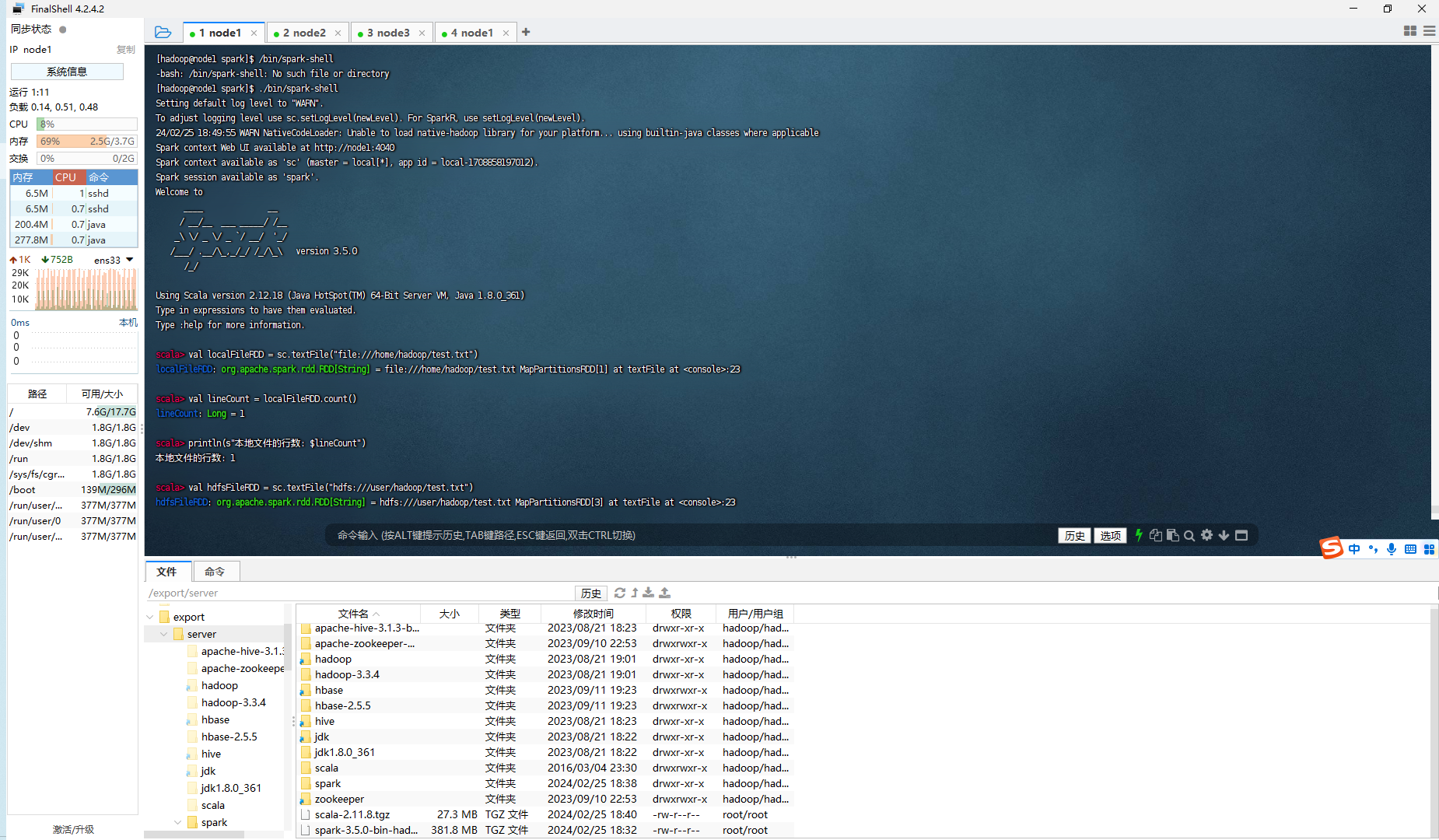
首先启动 spark-shell
$ spark-shell
val localFileRDD = sc.textFile("file:///home/hadoop/test.txt")
val lineCount = localFileRDD.count()
println(s"本地文件的行数: $lineCount")
在 spark-shell 中读取 HDFS 系统文件"/user/hadoop/test.txt",然后,统计出文件的行数:
// 读取 HDFS 文件并计算行数
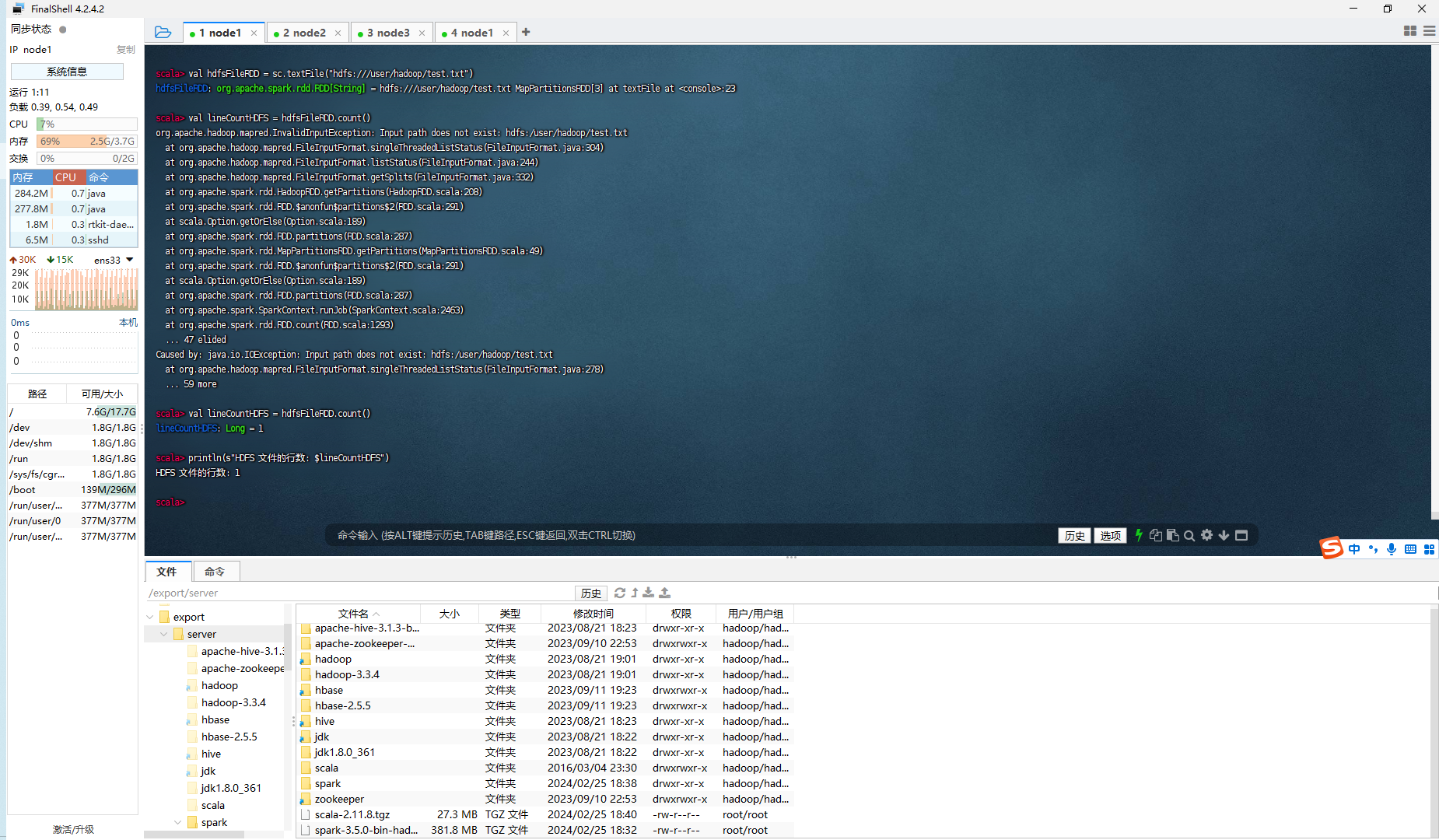
val hdfsFileRDD = sc.textFile("hdfs:///user/hadoop/test.txt")
val lineCountHDFS = hdfsFileRDD.count()
println(s"HDFS 文件的行数: $lineCountHDFS")


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Ollama——大语言模型本地部署的极速利器
· 使用C#创建一个MCP客户端
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· Windows编程----内核对象竟然如此简单?
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用