MoCo V2:MoCo系列再升级
何凯明从 CVPR 2020 上发表的 MoCo V1(Momentum Contrast for Unsupervised Visual Representation Learning),到前几天挂在arxiv上面的 MoCo V3(An Empirical Study of Training Self-Supervised Visual Transformers),MoCo一共走过了三个版本。
今天介绍 MoCo 系列第二版 MoCo v2 就是在 SimCLR 发表后结合了 SimCLR 优点的图像自监督学习方法,MoCo v1 和 v2 是针对 CNN 设计的,而 MoCo v3 是针对 Transformer 结构设计的,反映了 MoCo 系列对视觉模型的普适性。
[TOC]
MoCo V2 的改进
在 SimCLR v1 发布以后,MoCo的作者团队就迅速地将 SimCLR 的两个提点的方法移植到了 MoCo 上面,想看下性能的变化,也就是 MoCo v2。结果显示,MoCo v2 的结果取得了进一步的提升并超过了 SimCLR v1,证明 MoCo 系列方法的地位。因为 MoCo v2 文章只是移植了 SimCLR v1 的技巧而没有大的创新,所以作者就写成了一个只有2页的技术报告,还有长长的一页引用了大量文章。
有兴趣的读者可以参考MoCo V2的文章,Improved Baselines with Momentum Contrastive Learning。
MoCo V2 之前的相关工作
动量对比(MoCo V1)表明,无监督预训练可以在多个检测和分割任务中超过其图像监督的预训练,而 SimCLR 进一步减少了无监督和监督预训练表示之间的线性分类器性能差距。
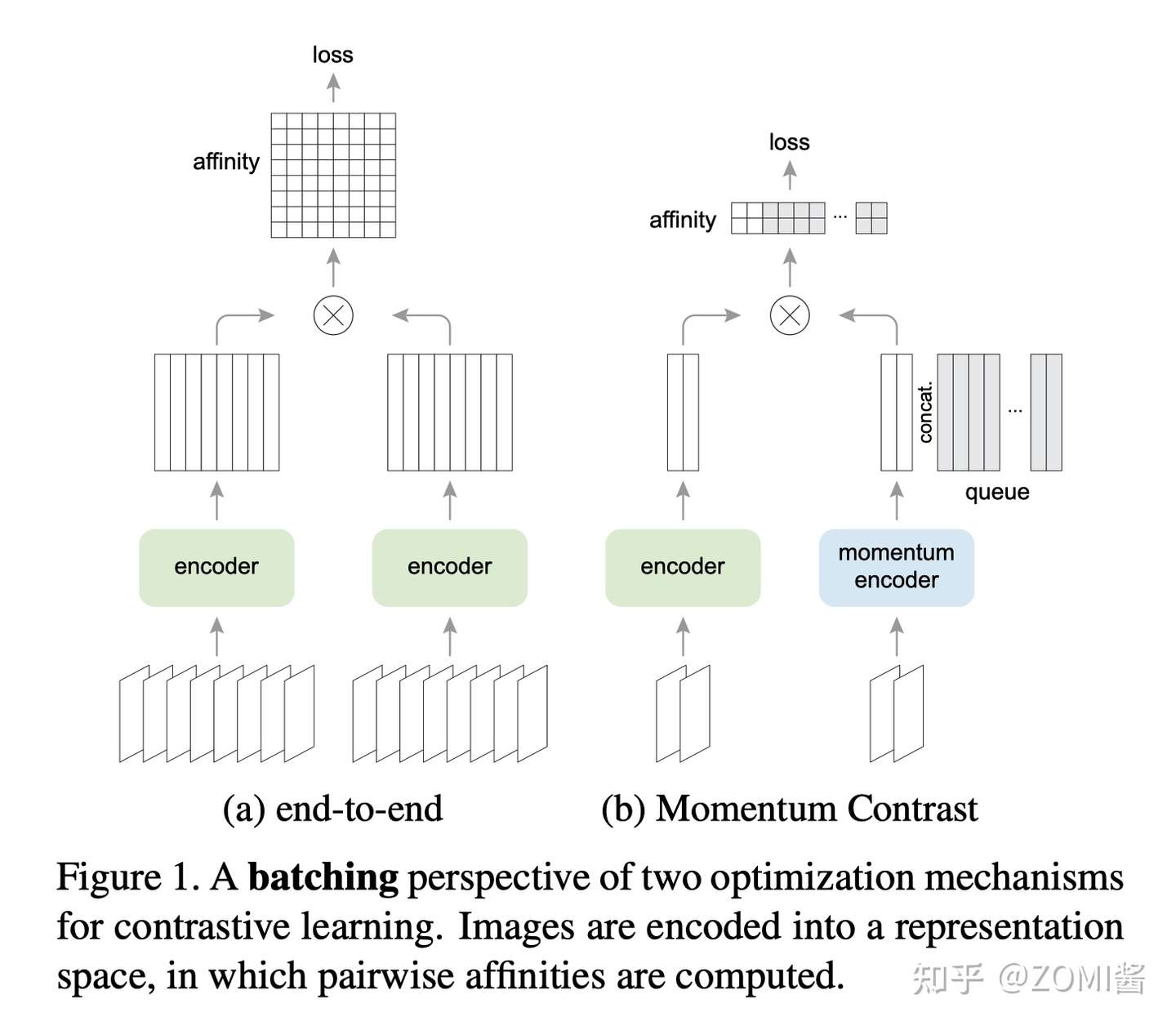
SimSLR仍然采用端到端的方法,如图(a)的方式,不过在三个方面改进了实例识别的端到端变体:(i)一个更大的批(4k或8k),可以提供更多的负样本;(ii)用MLP头替换输出fc投影头;(iii)更强的数据增强。
在 SimCLR 中具体的来说,就是使用强大的数据增强策略,额外使用了 Gaussian Deblur 的策略和使用巨大的 Batch size,让自监督学习模型在训练时的每一步见到足够多的负样本 (negative samples),这样有助于自监督学习模型学到更好的 visual representations。
使用预测头 Projection head。在 SimCLR 中,Encoder 得到的2个 visual representation再通过Prediction head 进一步提特征,预测头是一个 2 层的 MLP,将 visual representation 这个 2048 维的向量 h_i, h_j 进一步映射到 128 维隐空间中,得到新的representation z_i, z_j。利用表征向量 z_i, z_j 去求 Contrastive loss 完成训练,训练完毕后扔掉预测头,保留 Encoder 用于获取 visual representation。
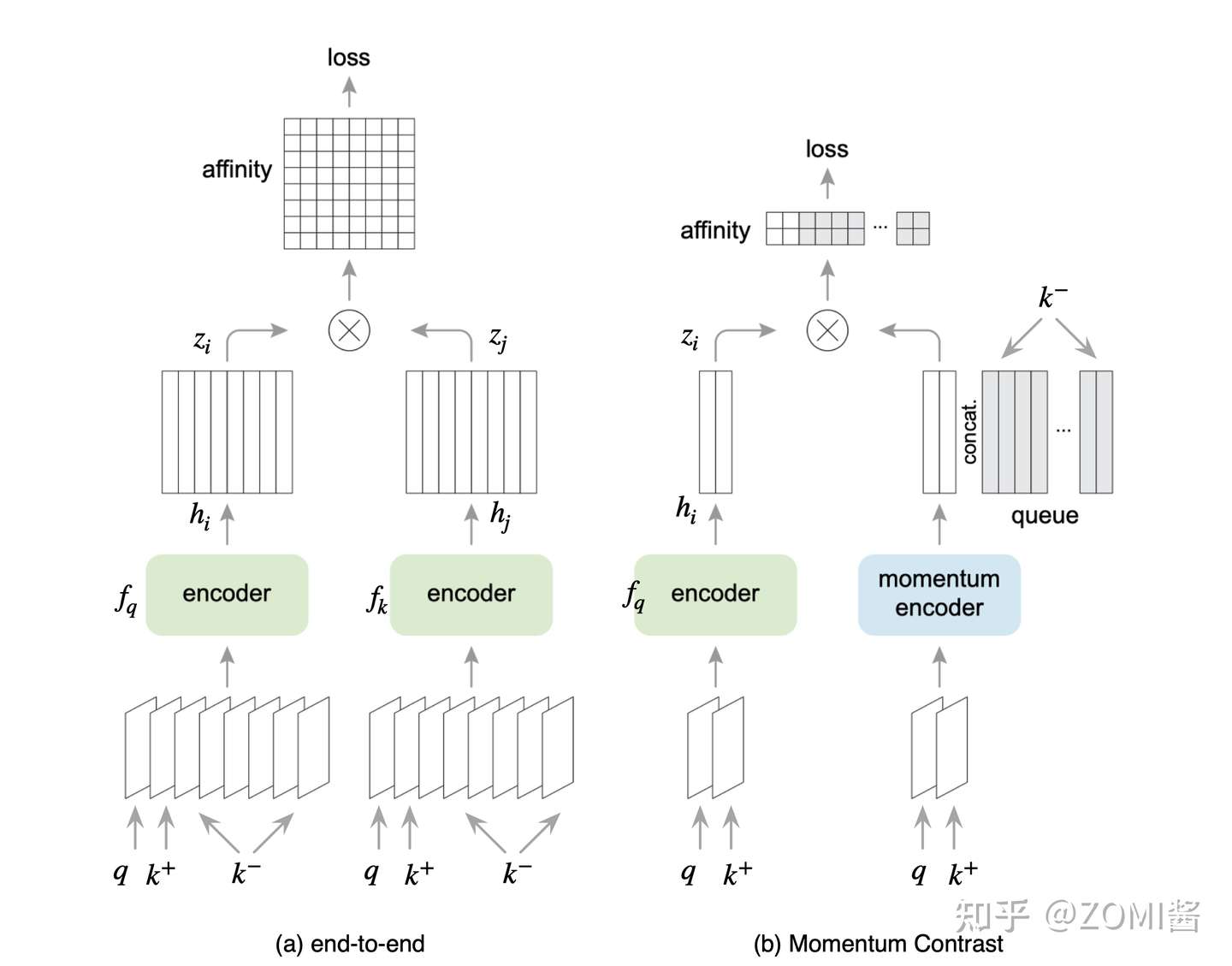
我们继续根据 end-to-end 的方法来继续展开。图中 End-to-end 的方法:一个Batch的数据假设有 N 张 image,这里面有一个样本 query q 和它所对应的正样本 k+, q 和 k+ 来自同一张图片的不同的 Data Augmentation,这个Batch剩下的数据就是负样本 (negative samples)。接着将这个 Batch 的数据同时输入给2个架构相同但参数不同的 Encoder f_q 和 Encoder f_k。然后对两个 Encoder的输出使用 Contrastive loss 损失函数使得 query q 和正样本 k+ 的相似程度尽量地高,使得 query q 和负样本 k- 的相似程度尽量地低,通过这样来训练Encoder f_q 和 Encoder f_k,这个过程就称之为自监督预训练。训练完毕后得到的 Encoder 的输出就是图片的 visual representation。
End-to-end 方法的缺点是:因为 Encoder f_q 和 Encoder f_k 的参数都是通过反向传播来更新的,所以 Batch size 的大小不能太大,否则 NPU 显存就不够了。Batch size 的大小限制了负样本的数量,也限制了自监督模型的性能。SimCLR 是 Google 提出的,有庞大的TPU集群加持,肯定不愁吃不愁穿,但是普通老百姓肯定不能这样。
MoCo V2 直接上实验
回到今天的主角身边,MoCo v2 的亮点是不需要强大的 Google TPU 加持,仅仅使用 8-GPU 就能超越 SimCLR v1 的性能。v2 将 SimCLR的两个提点的方法 (a 使用预测头 b 使用强大的数据增强策略) 移植到了 MoCo v1上面,实验如下。
训练集:ImageNet 数据集。
评价手段:
- Linear Evaluation:Encoder (ResNet-50) 的参数固定不动,在Encoder后面加分类器(具体就是一个FC层+softmax激活函数),使用全部的 ImageNet label 只训练分类器的参数,而不训练 Encoder 的参数)。看最后 Encoder+分类器的性能。
- VOC 目标检测 使用 Faster R-CNN 检测器 (C4 backbone),在 VOC 07+12 trainval set 数据集进行 End-to-end 的 Fine-tune。在 VOC 07 test 数据集进行 Evaluation。
使用预测头
预测器 Projection head 分类任务的性能只存在于自监督的预训练过程,在 Linear Evaluation 和下游任务中都是被去掉的。MoCo V1 的 Encoder 简单使用了 ResNet50,然后输出通过 L2-norm 处理得到最后的输出。在 MoCo V2 中把 ResNet 中输出与1000分类相关的FC层换成了两层的 FC + Relu,隐藏层为2048维。
Linear Evaluation 结果如下图:

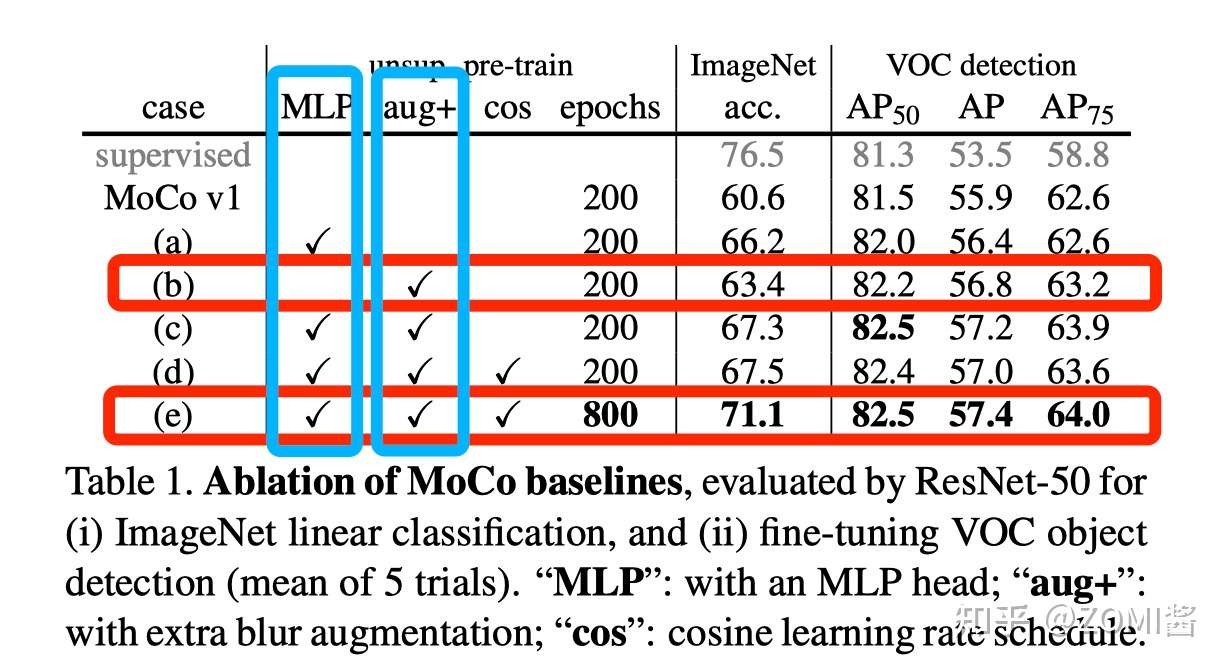
图中的 τ 就是损失函数对应的 τ 。在使用预测器且 τ=0.07 时精度从 from 60.6% to 62.9%。
数据增强策略
对数据增强策略,作者在 MoCo v1 的基础上又添加了 blur augmentation,发现更强的色彩干扰作用有限。只添加 blur augmentation 就可以使得 ImageNet 分类任务的性能从 60.6% 增长到 63.4%,再加上预测头 Projection head 就可以使性能进一步涨到67.3%。
小结
MoCo v2 把 SimCLR 中的两个主要提升方法:1)使用强大的数据增强策略,具体就是额外使用了 Gaussian Deblur 的策略;2)使用预测头 Projection head 到 MoCo 中,并且验证了 SimCLR 算法的有效性。最后 MoCo v2 的结果更优于 SimCLR v1,证明 MoCo 系列自监督预训练方法的高效性。
引用
[1] Hadsell, Raia, Sumit Chopra, and Yann LeCun. "Dimensionality reduction by learning an invariant mapping." 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'06). Vol. 2. IEEE, 2006.
[2] Chen, Ting, et al. "A simple framework for contrastive learning of visual representations." International conference on machine learning. PMLR, 2020.
[3] He, Kaiming, et al. "Momentum contrast for unsupervised visual representation learning." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
[4] Chen, Xinlei, et al. "Improved baselines with momentum contrastive learning." arXiv preprint arXiv:2003.04297 (2020).

 浙公网安备 33010602011771号
浙公网安备 33010602011771号