Pulsar
Pulsar
为什么要学习Apache Pulsar
什么是云原生
- DevOps:指的就是开发和运维不再是分开的两个团队,而是你中有我,我中有你的一个团队。
- 微服务:指是应用需要具备低耦合+高内聚。
- 持续交付:指的在不影响用户使用服务的前提下,频繁将新功能发布给用户使用,当然这一点也是云原生中比较难以达到的。
- 容器化:指的是在运维的时候,不需要再关心每个服务所使用的技术栈,每个服务都被无差别的封装在容器中,可以被无差别的管理和维度,比如目前docker和k8s。
Apache Pulsar基本介绍
Apache Pulsar是一个云原生企业级的发布订阅(pub-sub)消息系统。
Apache Pulsar的功能与特性:
- 多租户模式;
- 灵活的消息系统;
- 云原生架构;
- segmented Sreams(分片流);
- 支持跨地域复制;
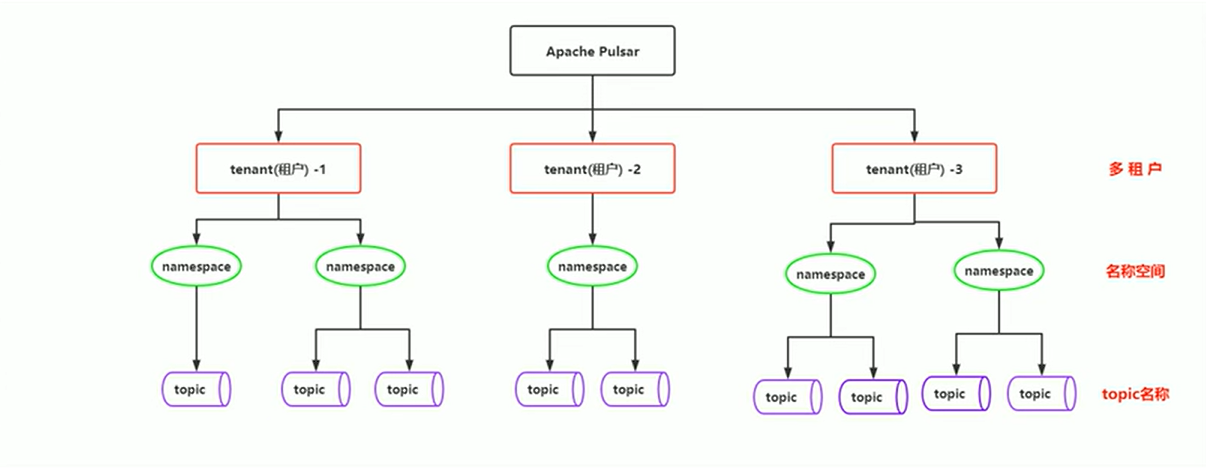
多租户模式
- 租户和命名空间(namespace)是Pulsar支持多租户的两个核心概念。
- 在租户级别,Pulsar为特定的租户预留合适的存储空间、应用授权和认证机制。
- 在命名空间级别,Pulsar有一系列的配置策略(policy),包括存储配额、流控制、消息过期策略和命名空间之间的隔离策略。
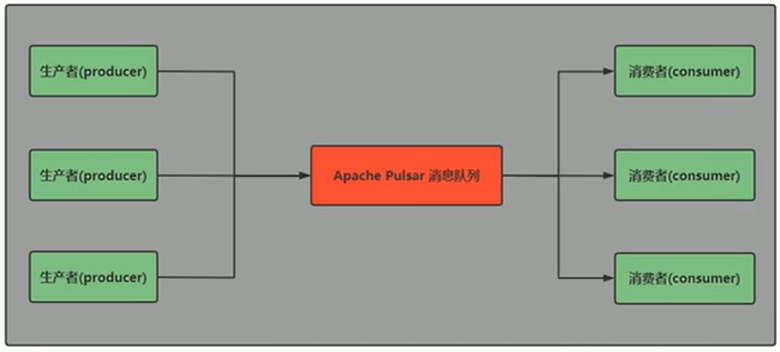
灵活的消息系统
- Pulsar做了队列模型和流模型的统一,在Topic级别只需要保存一份数据,同一份数据可多次消费。以流式、队列等方式计算不同的订阅模型,大大提升了灵活度。
- 同时Pulsar通过事务采用Exactly-Once(精准一次)在进行消息传输过程中,可以确保数据不丢不重。
消息队列模式
流模式
云原生架构
- Pulsar使用计算与存储分离的云原生架构,数据从Broker搬离,存在共享存储内部。上层是无状态的Broker,复制消息分发和服务;下层是持久化的存储层Bookie集群。Pulsar存储是分片的,这种架构可以避免扩容时受限制,实现数据的独立扩展和快速恢复。
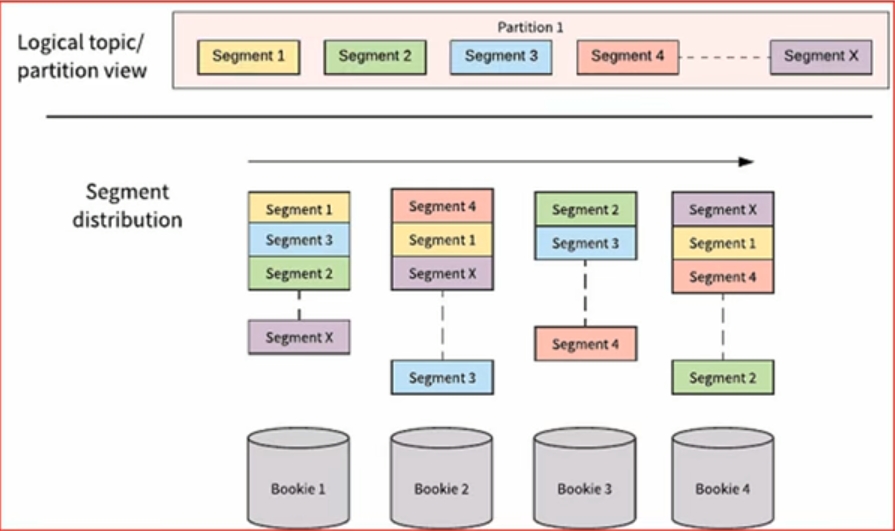
segmented Sreams(分片流)
- Pulsar将无界的数据看作是分片的流,分片分散存储在分层存储(tiered storage)、BookKeeper集群和Broker节点上,而对外提供一个统一的、无界数据的视图。其次,不需要用户显式迁移数据,减少存储成本并保持近似无限的存储。
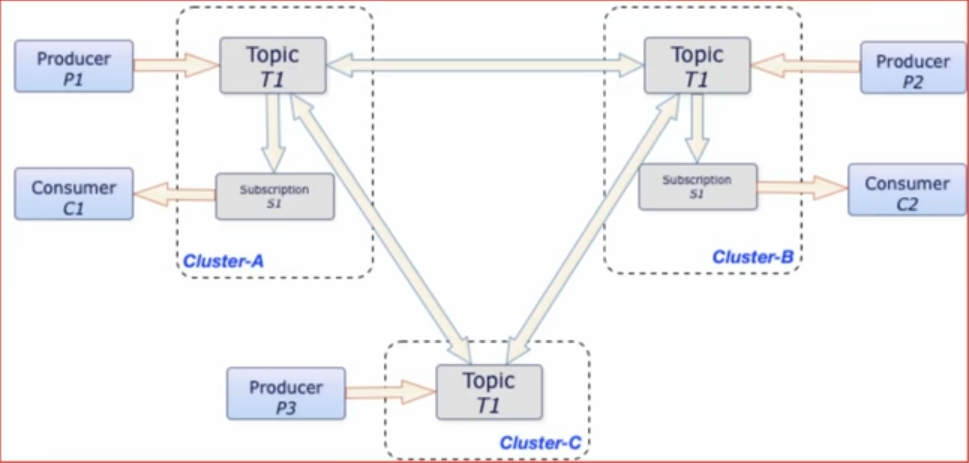
支持跨地域复制
- Pulsar中的跨地域复制是将Pulsar中持久化的消息在多个集群间备份。在Pulsar 2.4.0中新增了复制订阅模式(Replicated-subscriptions),在某个集群失效的情况下,该功能可以在其他集群恢复消费者的消费状态,从而达到热备模式下消息服务的高可用。
Apache Pulsar组件介绍
层级存储
- Infinite Stream:以流的方式永久保存原始数据;
- 充分的容量不再受限制;
- 充分利用云存储或者现有的廉价存储(例如HDFS);
- 数据统一表征:客户端无需关心数据究竟存储在哪里;
Pulsar IO(Connector)连接器
- Pulsar IO分为输入(Input)和输出(Output)两个模块,输入代表数据从哪里来,通过Source实现数据输入。输出代表数据要往哪里去,通过Sink实现数据输出。
- Pulsar提出了Connector(也称为Pulsar IO),用于解决Pulsar与周边系统的继承问题,帮助用户高效完成工作。
- 目前Pulsar IO支持非常多的连接继承操作:例如:HDFS、Spark、Flink、Flume、ES、HBase等。

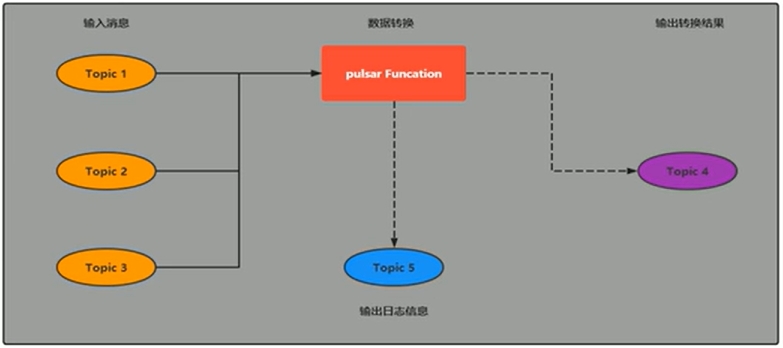
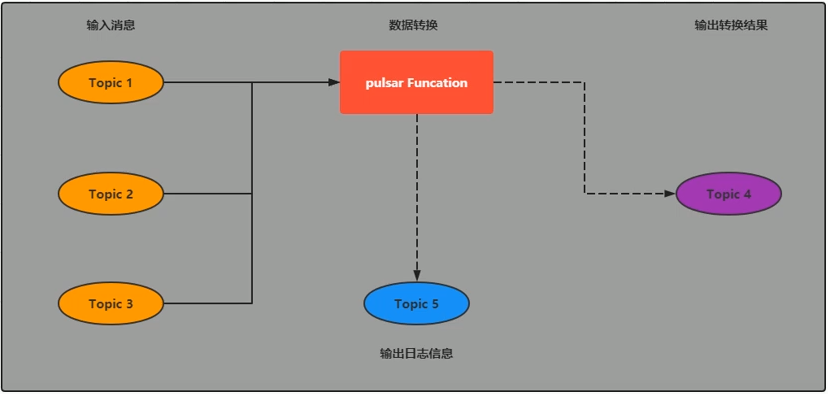
Pulsar Functions(轻量级计算框架)
- Pulsar Functions是一个轻量级计算框架,可以给用户提供一个部署简单、运维简单、API简单的FASS(Function as a Service)平台。Pulsar Functions提供基于事件的服务,支持有状态与无状态的多语言计算,是对复杂的大数据处理框架的有力补充。
- Pulsar Functions的设计灵感来自于Heron这样的流处理引擎,Pulsar Functions将会拓展Pulsar和整个消息领域的未来。使用Pulsar Functions,用户可以轻松地部署和管理Function,通过Function从Pulsar topic读取数据或者生成新数据到Pulsar topic。
Pulsar和kafka的对比
- 模型概念
- Kafka:producer -- topic -- consumer group -- consumer
- Pulsar: producer -- topic -- subscription -- consumer
- 消费模式
- Kafka:主要集中在流(Stream)模式,对单个partition是独占消费,没有共享(Queue)的消费模式;
- Pulsar:提供了统一的消息模型和API。流(Stream)模式 -- 独占和故障切换订阅方式;队列(Queue)模式 -- 共享订阅的方式
- 消息确认(ack)
- Kafka:使用偏移量offset;
- Pulsar:使用专门的cursor管理。累计确认和Kafka效果一样;提供单条或选择性确认;
- 消息保留
- Kafka:根据设置的保留期来删除消息,有可能消息没被消费,过期后被删除,不支持TTL;
- Pulsar:消息只有被所有订阅消费后才删除,不会丢失数据。也支持设置保留期,保留被消费的数据,支持TTL。
Apache Kafaka和Apache Pulsar都有类似的消息概念。客户端通过主题与消息系统进行交互。每个主题都可以分为多个分区。然而,Apache Pulsar和Apache Kafka之间的根本区别在于Apache Kafka是以分区为存储中心,而Apache Pulsar是以Segment为存储中心。
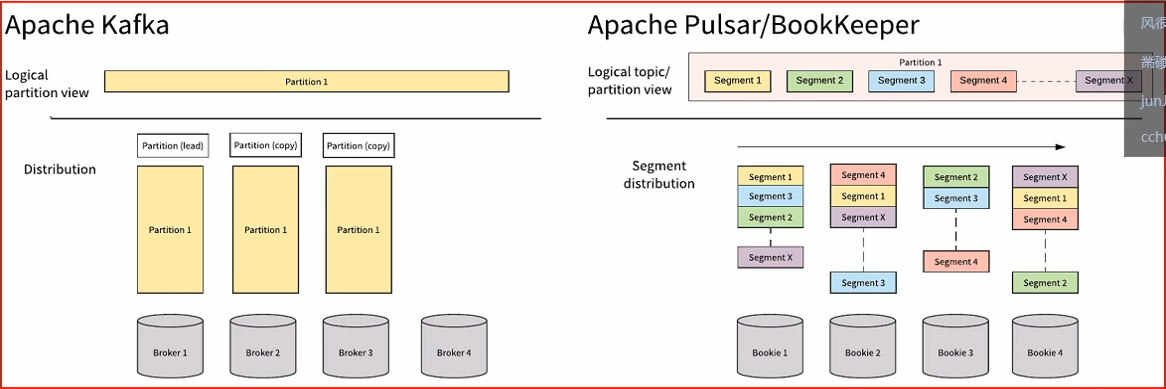
对比总结:
Apache Pulsar将高性能的流(Apache Kafka所追求的)和灵活的传统队列(RabbitMQ所追求的)结合到一个统一的消息模型和API中。Pulsar使用统一的API为用户提供一个支持流和队列的系统,且具有同样的高性能。
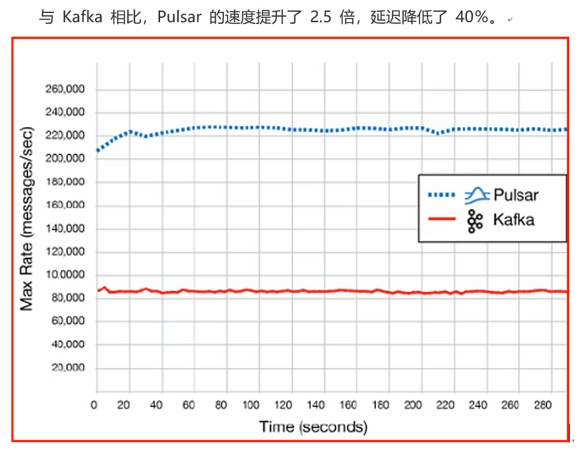
性能对比:
Pulsar表现出色的就是性能,Pulsar的速度比Kafka快得多,美国德克萨斯州一家名为GigaOm(https://gigaom.com/) 的技术研究和分析公司对Kafka和Pulsar的性能对了比较,并证实了这一点。
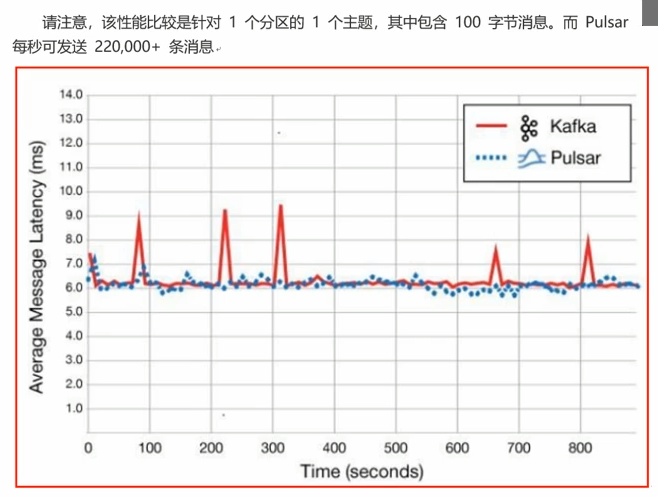
扩展说明:Kafka目前存在的痛点
- Kafka很难进行扩展,因为Kafka把消息持久化在broker中,迁移主题分区时,需要把分区的数据完全复制到其他broker中,这个操作非常耗时。
- 当需要通过更改分许大小获得更多存储空间时,会与消息索引产生冲突,打乱消息顺序。因此,如果用户需要保证消息的顺序,Kafka就变得非常棘手了。
- 如果分区副本不处于ISR(同步)状态,那么leader选取可能会紊乱。一般的,当原始主分区出现故障时,应该有一个ISR副本本征用,但是这个点并不能完全被保证。若在设置中并未规定只有ISR副本可被选为leader时,选出一个处于非同步状态的副本作为leader,这比没有broker服务该partition的情况更糟糕。
- 使用Kafka时,你需要根据现有的情况并充分考虑未来的增量计划,规划broker、主题、分区和副本的数量,才能避免Kafka扩展导致的问题。这是理想状况,实际情况很难规划,不可避免的会出现扩展需求。
- Kafka集群的分区再均衡会影响相关生产者和消费者的性能。
- 发生故障时,Kafka主题无法保证消息的完整性(特别是遇到第3点中的情况,需要扩展时极有可能丢失消息)。
- 使用Kafka需要和offset打交道,这点让人很头痛,因为broker并不维护consumer的消费状态。
- 如果使用率很高,则必须尽快删除就的消息,否则就会出现磁盘空间不够用的问题。
- 众所周知,Kafka元神的跨地域复制机制(MirrorMaker)有问题,机试只在两个数据中心也无法正常使用跨地域复制。因此,甚至Uber都不得不创建另一套结局啊方案来解决这个问题,并将其称为uReplication(https://eng.uber.com/ureplicator/)。
- 想要进行实时数据分析,就不得不选用第三方工具,如Apache Strom、Apache Heron或Apache Spark。同时,你需要保证这些第三方工具足以支撑传入的流量。
- Kafka没有原生的多租户功能来实现租户的完全隔离,他是通过使用主题授权等安全功能来完成的。
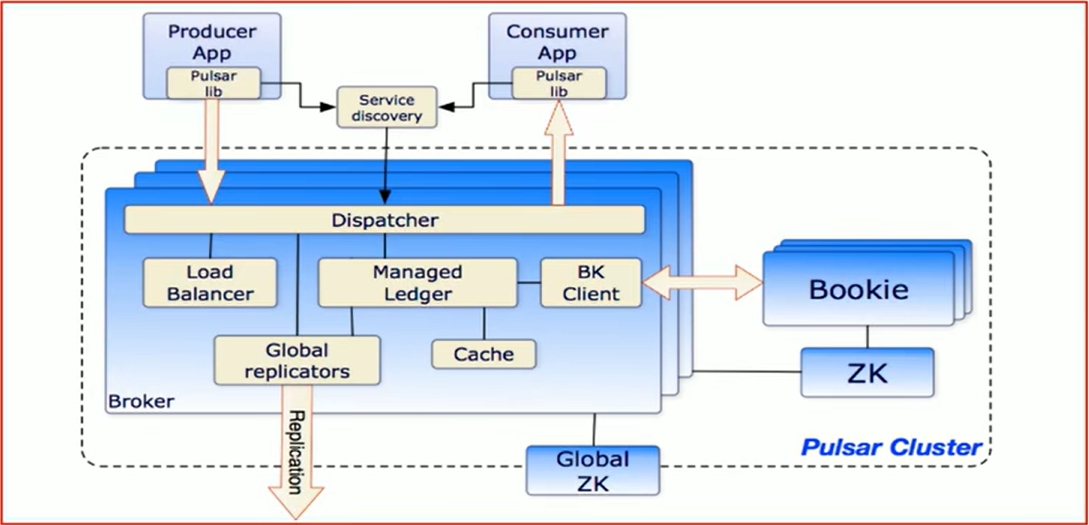
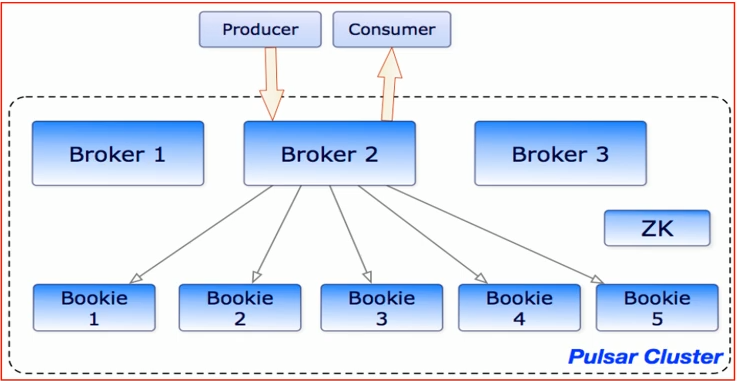
Apache Pulsar集群架构
基本架构介绍
单个Pulsar集群由以下三部分组成:
- 多个broker负责处理和负载均衡producer发出的消息,并将这些消息分派给consumer;Broker与Pulsar配置存储交互来处理相应的任务,并将消息存储再Bookkeeper示例中(又称bookies);Broker依赖Zookeeper集群处理特定的任务,等等。
- 多个bookie的BookKeeper集群负责消息的持久化存储。
- 一个zookeeper集群,用来处理多个Pulsar集群之间的任务调度。
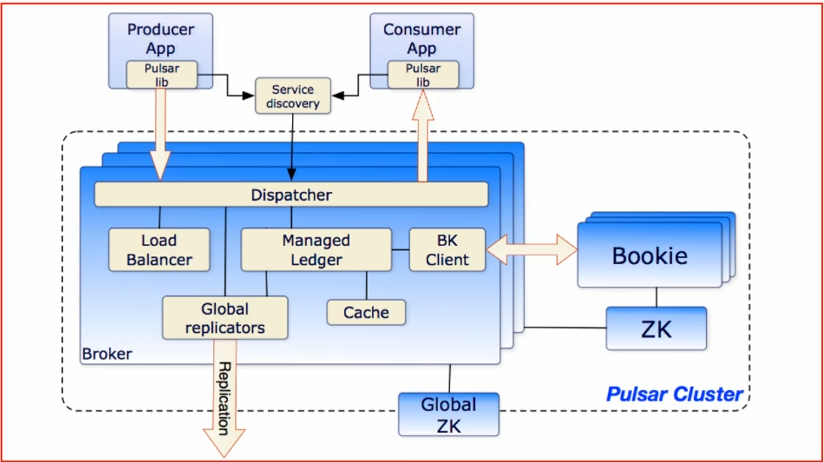
Brokers介绍
Pulsar的broker是一个无状态组件,主要负责运行另外的两个组件:
- 一个HTTP服务器,他暴露了REST系统管理接口以及在生产者和消费者之间进行Topic查找的API。
- 一个调度分发器,他是异步的TCP服务器,通过自定义二进制协议应用于所有相关的数据传输。
出于性能考虑,消息通常从Managed Ledger缓存中分派出去,除非积压超过缓存大小。如果积压的消息对于缓存来说太大了,则Broker将开始从BookKeeper那里读取Entries(Entry同样时BookKeeper中的概念,相当于一条记录)。
最后,为了支持全局Topic异地复制,Broker会控制Replicators追踪本地发布的条目,并把这些条目用java客户端重新发布到其他区域。
Zookeeper的元数据存储
Pulsar使用Apache Zookeeper进行元数据存储、集群配置和协调。
- 配置存储:存储租户,命名域和其他需要全局一致的配置项;
- 每个集群都有自己独立的Zookeeper保存集群内部配置和协调信息,例如归属信息,Broker负载报告,BookKeeper ledger信息(这个是BookKeeper本身所依赖的)等等。
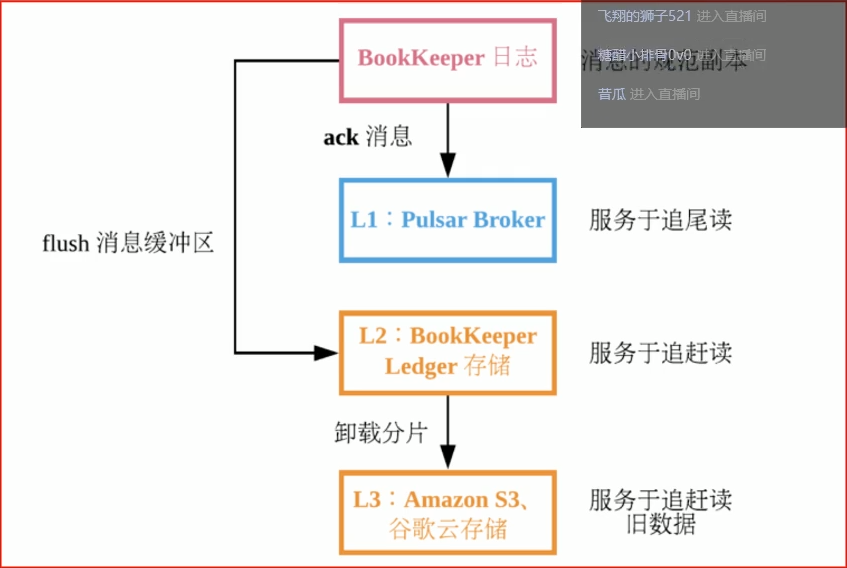
基于bookkeeper持久化存储
Apache Pulsar为应用程序提供有保证的信息传递,如果消息成功到达Broker,就认为其预期到达了目的地
为了提供这种保证,未确认送达的消息需要持久化存储直到他们被确认送达。这种消息传递通常称为持久消息传递。在Pulsar内部,所有消息都被保存并同步N份,例如,2个服务器保存四份,每个服务器上都有镜像的RAID存储。Puldar用Apache BookKeeper作为持久化存储。BookKeeper是一个分布式的预写日志(WAL)系统,有如下几个特性特别适合Pulsar的应用场景:
- 使用Pulsar能够利用独立的日志,成为ledgers。可以随着时间的推移为topic创建多个Ledgers
- 它为处理顺序消息提供了非常有效的存储;
- 保证了多系统挂掉时Ledgers的读取一致性;
- 提供不同的Bookies之间均匀的IO分布的特性;
- 它在容量和吞吐量方面都具有水平伸缩性。能够通过增加bookies立即增加容量到集群中,并提升吞吐量;
- Bookies被设计成承载数千的并发读写的ledgers。使用多个磁盘设备(一个用于日志,另一个用于一般存储),这样Bookies可以将读写操作的影响对于写操作的延迟分隔开。
Ledger是一个之追加的数据结构,并且只有一个写入器,这个写入器负责多个BookKeeper存储节点(就是Bookies)的写入。Ledger的条目会被复制到多个Bookies。Ledgers本身有着非常简单的语义: - Pulsar Broker可以创建ledger,添加内容到ledger和关闭ledger。
- 当一个ledger被关闭后,除非明确的要写数据或者是因为写入器挂掉导致ledger关闭,ledger只会以只读模式打开。
- 最后,当ledger中的条目不在有用的时候,整个ledger可以被删除(ledger分布是跨Bookies的)。
Pulsar代理
Pulsar客户端和Pulsar集群交互的一种方式就是直连Pulsar brokers。然而,在某些情况下,这种直连既不可行也不可取,因为客户端并不知道broker的地址。例如在云环境或者k8s以及其他类似的系统上面运行Pulsar,直连brokers就基本上不可能了。
Pulsar proxy为这个问题提供了一个解决方案,为所有的broker提供了一个网关,如果选择运行了Pulsar Proxy。所有的客户都会通过这个代理而不是直接与brokers通信。
Apache Pulsar可视化监控部署
由于目前传智教育中采用Pulsar主要还是已于多Linux节点方式进行部署,故本次主要为各位提供也是多台linux服务器上构建集群方案,对于Pulsar在k8s、Docker、AWS等部署操作,后续推送给大家。
Apache Pulsar相关使用操作
多租户模式
- 获取租户列表
cd /exprot/server/brokers/bin
./pulsar-admin tenants list
- 创建租户
cd /exprot/server/brokers/bin
./pulsar-admin tenants create my-tenant
- 删除租户
注意:在删除的时候,如果库下已经有名称空间,是无法删除的,需要先删除名称空间
cd /exprot/server/brokers/bin
./pulsar-admin tenants delete my-tenant
Pulsar的名称空间
- 在指定的租户下创建名称空间
cd /exprot/server/brokers/bin
./pulsar-admin namespaces create test-tenant/test-namespace
- 获取名称空间相关的配置策略
cd /exprot/server/brokers/bin
./pulsar-admin namespaces policies test-tenant/test-namespace
- 获取指定租户下所有的名称空间
cd /exprot/server/brokers/bin
./pulsar-admin namespaces list test-tenant
- 删除名称空间
cd /exprot/server/brokers/bin
./pulsar-admin namespaces delete test-tenant/test-namespace
Pulsar的topic相关操作
Pulsar提供持久化与非持久化两种topic。持久化topic是消息发布、消费的逻辑端点。持久化topic地址的命名格式如下:persistent://tenant/namespace/topic
非持久化topic应用在仅消费时发布消息与不需要持久化保证的应用程序。通过这种方式,它通过删除持久化消息的开销来减少消息发布延迟。非持久化topic地址的命名格式如下:non-persistent://tenant/namespace/topic
- 创建Topic
# 方式一:创建一个没有分区的topic
bin/pulsar-admin topics create persistent://my-tenant/my-namespace/my-topic
# 方式二:创建一个有分区的topic
bin/pulsar-admin topics create-partitioned-topic persistent://my-tenant/my-namespace/my-topic -- partitions 4
注意:不管是有分区还是没有分区,创建topic后,如果没有任何操作,60s后Pulsar会认为topic不是活动的,会自动进行删除,以避免生成垃圾数据
相关的配置:
Brokerdeleteinactivetopicsenabenabled:默认值为true,表示是否启动自动删除
BrokerDeletenactiveTopicsFrequencySeconds:默认为60s,表示检测未活动的时间
- 列出房前某个名称空间下的所有topic
./pulsar-admin topics list my-tenant/my-namespace
- 更新topic操作
我们可以针对所有分区的topic去更新其分区的数量
./pulsar-admin topics update-partitioned-topic persistent://my-tenant/my-namespace/my-topic --partitions 8
- 删除topic操作
删除没有分区的topic:
./pulsar-admin topics delete persistent://my-tenant/my-namespace/my-topic
删除有分区的topic
./pulsar-admin topics delete-partition-topic persistent://my-tenant/my-namespace/my-topic
- 查询某个topic被哪个broker进行代理执行
pulsar-admin topics lookup persistent://test-tenant/ns1/tp1
作用:
一个namespace最终只能被一个broker所代理,那么当这个空间下的topic越来越多,此时broker的压力就会增加,后续可以基于对这个namespace进行bundle切分处理,基于此命令可以看出当前这个topic被那个broker管辖
基于Python操作Pulsar(原生、schema、KOP)
原生
import pulsar
class PulsarProdecerTest(object):
"""生产者"""
def __init__(*args, **kwargs):
self.client = pulsar.Client('pulsar://localhost:6650')
self.producer_ = None
def producer(self, topic, message, *args, **kwargs):
self.producer_ = self.client.create_producer(topic)
self.producer_.send(message.encode('utf-8'))
def __exit__(self, *args, **kwargs):
self.producer_.close()
self.client.close()
class PulsarConsumerTest(object):
"""消费者"""
def __init__(self, *args, **kwargs):
self.client = pulsar.Client('pulsar://localhost:6650')
self.consumer_ = None
def consumer(self, topic, subscription_name, *args, **kwargs):
self.consumer_ = self.client.subscribe(topic, subscription_name)
while True:
msg = self.consumer.receive()
try:
print(msg)
self.consumer_.acknowledge(msg)
except Exception as e:
self.consumer_.negative_acknowledge(msg)
def __exit__(self, *args, **kwargs)
self.client.close()
schema
可以自定义类来传递数据,不需要再转换成json格式
KOP
兼容Kafka,可以使不改变Kafka代码结构的情况下将数据推送到Pulsar里。
Pulsar connector连机器(与flume和flink集成)
Pulsar Flink Connector 是Apache Pulsar和Apache Flink(数据处理引擎)的集成,它允许Flink从Pulsar读取数据,并向Pulsar写入数据

认证
如果需要进行token认证,则需要如下定义
client = pulsar.Client(
'pulsar://localhost:6650',
authentication=AuthenticationToken('eyJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJKb2UifQ.ipevRNuRP6HflG8cFKnmUPtypruRC4fb1DWtoLL62SY'))
并确保broker.conf中配置如下:
# 启用认证和鉴权
authenticationEnabled=true
authorizationEnabled=true
authenticationProviders=org.apache.pulsar.broker.authentication.AuthenticationProviderToken
# 设置Broker 自身的认证。 Used when the broker connects to other brokers, either in same or other clusters
brokerClientTlsEnabled=true
brokerClientAuthenticationPlugin=org.apache.pulsar.client.impl.auth.AuthenticationToken
brokerClientAuthenticationParameters={"token":"eyJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ0ZXN0LXVzZXIifQ.9OHgE9ZUDeBTZs7nSMEFIuGNEX18FLR3qvy8mqxSxXw"}
# Or, alternatively, read token from file
# brokerClientAuthenticationParameters={"file":"///path/to/proxy-token.txt"}
brokerClientTrustCertsFilePath=/path/my-ca/certs/ca.cert.pem
# If this flag is set then the broker authenticates the original Auth data
# else it just accepts the originalPrincipal and authorizes it (if required).
authenticateOriginalAuthData=true
# If using secret key (Note: key files must be DER-encoded)
tokenSecretKey=file:///path/to/secret.key
# The key can also be passed inline:
# tokenSecretKey=data:;base64,FLFyW0oLJ2Fi22KKCm21J18mbAdztfSHN/lAT5ucEKU=
# If using public/private (Note: key files must be DER-encoded)
# tokenPublicKey=file:///path/to/public.key
proxy.conf中配置如下:
# For clients connecting to the proxy
authenticationEnabled=true
authorizationEnabled=true
authenticationProviders=org.apache.pulsar.broker.authentication.AuthenticationProviderToken
tokenSecretKey=file:///path/to/secret.key
# For the proxy to connect to brokers
brokerClientAuthenticationPlugin=org.apache.pulsar.client.impl.auth.AuthenticationToken
brokerClientAuthenticationParameters={"token":"eyJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJ0ZXN0LXVzZXIifQ.9OHgE9ZUDeBTZs7nSMEFIuGNEX18FLR3qvy8mqxSxXw"}
# Or, alternatively, read token from file
# brokerClientAuthenticationParameters={"file":"///path/to/proxy-token.txt"}
# Whether client authorization credentials are forwared to the broker for re-authorization.
# Authentication must be enabled via authenticationEnabled=true for this to take effect.
forwardAuthorizationCredentials=true
才能保证token认证开关是打开的,否则在关闭情况下,穿不穿token都唔那个收到生产者的消息。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App
· 张高兴的大模型开发实战:(一)使用 Selenium 进行网页爬虫