数据结构基础
数据结构基础
数据结构
数据结构是指相互之间存在着一种或者多种关系的数据元素的集合和该集合中数据元素之间的关系组成。
简单来说,数据结构就是设计数据以何种方式组织并存储在计算机中。比如列表、集合与字典等都是一种数据结构。
‘程序 = 数据结构 + 算法’
数据结构按照其逻辑结构可分为线性结构、树结构、图结构。
线性结构
数据结构中的元素存在一对一的相互关系。例如列表等。
列表
在其他编程语言中称为‘数组’,是一种基本的数据结构类型。也被叫做顺序表。
顺序表在其他编程语言中又被称为数组。
数组在创建之初就已经确定了大小,一旦被创建,则不可变;而且数组只能存放同一种数据类型的数据。而python中的列表则是可变的,可以一直的追加元素;其可以存各种各样的数据类型的数据。
列表可以存储不同数据类型是因为列表存储的是每一个元素的存储空间的起始地址。如图:
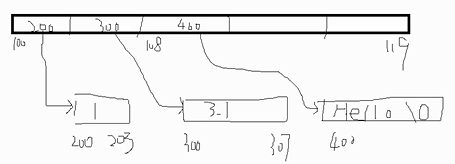
列表的变长是因为当其存储满了以后,重新创建一个原列表大小一倍的列表,将原来的列表复制一遍重新存储进去,然后将原来的列表占据的空间释放。
数组
系统32位、64位系统控制总线的的宽度。也可以理解为寻址能力。
32位系统的最大寻址能力是4Gb。
数据要求存储数据类型一样是为了方便存储,例如存储数字时,没位数字占一定大小的空间,可以使用 起始内存地址 + 数字 * 4 的结果来存储,方便计算,当数据类型不一样时,每种数据类型占据的大小不一样,无法这样存储数据,导致无法存储。
栈
通常说的堆栈实际上指的就是栈。
栈是一个数据集合,可以理解为只能在一端进行插入或删除操作的列表。

特点
后进先出(last-in,first-out)
栈顶
只能从栈顶进行数据的压栈或者出栈。见上图。
栈底
见上图。
基本操作
进栈(压栈)
push
出栈
pop
取栈顶
gettop
python的实现
不需要自己定义,使用列表结构即可。
进栈函数:append
出栈函数:pop
查看栈顶函数:li[-1]
列表的出栈顺序有多少种可能?卡特兰数
应用
括号匹配问题
给一个字符串,其中包含小括号、中括号、大括号,求该字符中的括号是否匹配。
def brace_match(s):
'''
DFS 深度优先搜索
''' stack = [] dic = {')': '(', ']': '[', '{': '{'} for ch in s: if ch in {'(', '[', '{'}: stack.append(ch) elif len(stack) == 0: print('缺少左括号') return False elif stack[-1] == dic[ch]: stack.pop() else: print('左右括号不匹配') if len(stack) > 0: print('缺少右括号') return False else: return True print(brace_match())
迷宫问题
给一个二维列表,表示迷宫(0表示通道,1表示围墙)。给出爽啊,求一条做出迷宫的路径。
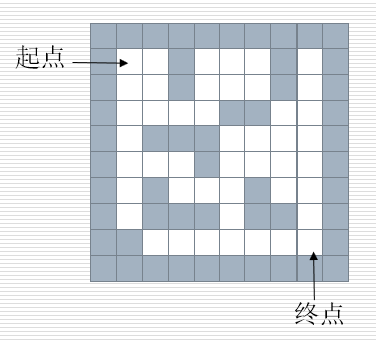
解决思路
在一个迷宫节点(x, y) 上,可以进行四个方向的探查:
maze[x - 1][y], maze[x + 1][y], maze[x][y - 1], maze[x][y + 1]
思路
从一个节点开始,任意找下一个能走的点,当找不到能走的点,退回上一个点寻找是否有其他方向的点。
方法
创建一个空栈,首先将入口位置进栈。当栈不空时循环:
获取栈顶元素,寻找下一个可走的相邻方块,如果找不到可走的相邻方块,说明当期位置是死胡同进行回溯(就是将当前位置出栈,看前面的点是否还有别的出路)
实现代码:
maze = [ [1,1,1,1,1,1,1,1,1,1], [1,0,0,1,0,0,0,1,0,1], [1,0,0,1,0,0,0,1,0,1], [1,0,0,0,0,1,1,0,0,1], [1,0,1,1,1,0,0,0,0,1], [1,0,0,0,1,0,0,0,0,1], [1,0,1,0,0,0,1,0,0,1], [1,0,1,1,1,0,1,1,0,1], [1,1,0,0,0,0,0,0,0,1], [1,1,1,1,1,1,1,1,1,1] ] dirs = [ lambda x, y: (x - 1, y), # 上 lambda x, y: (x, y + 1), # 右 lambda x, y: (x + 1, y), # 下 lambda x, y: (x, y - 1), # 左 ] def solve_maze_with_stack(x1, y1, x2, y2): stack = [] stack.append((x1, y1)) maze[x1][y1] = 2 # 表示已经走过的路 while len(stack) > 0: cur_node = stack[-1] if cur_node == (x2, y2): print(stack) return True for d in dirs: next_x, next_y = d(*cur_node) if maze[next_x][next_y] == 0: stack.append((next_x, next_y)) maze[next_x][next_y] = 2 break else: stack.pop() print('没有路') return False solve_maze_with_stack(1, 1, 8, 8)
队列
队列是一个数据集合,仅允许在列表的一段进行插入,另一端进行删除。
进行插入的一端称为队尾,插入动作称为进队或入队。
进行删除的一端称为对头,删除动作称为出队

特点
先进先出(First-in,First-out)
双向队列
队列的两端都允许进行进队和出队操作。
实现队列
线型实现
创建办列表,进行进行出队,当前边浪费的空间太多时,就重新复制一个列表,将原队列中的内容复制进去。
环型实现
使用环型列表,一个个写进去,当写满了就重写创建一个大一倍的环型列表,将原队列中的值赋进去。出栈时采用(m-11)%n n为圆形列表的大小,11位圆形列表的最大索引。m为低多少个数。
两个栈实现队列
class Queue: def __init__(self): self.stack1 = [] self.stack2 = [] def push(self, item): self.stack1.append(item) def pop(self): if len(self.stack2) == 0: while len(self.stack1) > 0: self.stack2.append(self.stack1.pop()) return self.stack2.pop() q = Queue() q.push(1) q.push(2) print(q.pop()) q.push(3) print(q.pop()) q.push(4) print(q.pop())
Python自带的队列
from collections import deque
# deque为双向队列
q = deque()
# 进队
q.append(1)
q.append(2)
# 出队
q.popleft()
应用
模拟实现Linux中的tail
tail
list(deque(open(文件路径, 'r'), 5))
迷宫问题
思路
从一个节点开始,寻找所有下面能继续走的点。继续寻找,直到找到出口。
方法
创建一个空队列,将起点位置进队。在队列不为空时循环:
出队一次。如果放弃那位置为出口,则结束算法;否则找出当前方块的4个相邻方块中可走的方块,全部进队。
from collections import deque maze = [ [1,1,1,1,1,1,1,1,1,1], [1,0,0,1,0,0,0,1,0,1], [1,0,0,1,0,0,0,1,0,1], [1,0,0,0,0,1,1,0,0,1], [1,0,1,1,1,0,0,0,0,1], [1,0,0,0,1,0,0,0,0,1], [1,0,1,0,0,0,1,0,0,1], [1,0,1,1,1,0,1,1,0,1], [1,1,0,0,0,0,0,0,0,1], [1,1,1,1,1,1,1,1,1,1] ] dirs = [ lambda x, y: (x - 1, y), # 上 lambda x, y: (x, y + 1), # 右 lambda x, y: (x + 1, y), # 下 lambda x, y: (x, y - 1), # 左 ] def solve_maze_with_queue(x1, y1, x2, y2): q = deque() path = [] q.append((x1, y1, -1)) maze[x1][y1] = 2 while len(q) > 0: cur_node = q.popleft() path.append(cur_node) if cur_node[:2] == (x2, y2): # 终点 # for i, v in enumerate(path): # print(i, v) real_path = [] i = len(path) - 1 while i >= 0: real_path.append(path[i][:2]) i = path[i][2] real_path.reverse() print(real_path) return True for d in dirs: next_x, next_y = d(cur_node[0], cur_node[1]) if maze[next_x][next_y] == 0: q.append((next_x, next_y, len(path) - 1)) # path列表n-1位置的点是它的父亲(它的前一个位置) maze[next_x][next_y] = 2 print('无路') return False solve_maze_with_queue(1, 1, 8, 8)
链表
链表是和顺序表相对应的。
链表中每一个元素都是一个对象,每一个对象称为一个节点,包含有数据域key和指向下一个节点的指针next。通过各个节点之间的相互连接,最终串联成一个链表。
创建表节点
class Node: def __init__(self, key): self.key = key self.next = None
链表的实现
头插法
带头节点的链表
class Node: def __init__(self, key): self.data = key self.next = None def create_link_list_head(li): head = Node(None) for num in li: p = Node(num) p.next = head.next head.next = p return head def traverse_link_list(head): p = head.next while p: print(p.data) p = p.next head = create_link_list_head([1, 2, 3, 4, 5]) traverse_link_list(head)
不带头节点的链表
class Node: def __init__(self, key): self.data = key self.next = None def create_link_list_head_2(li): head = None for num in li: p = None(num) p.next = head head = p return head def traverse_link_list_2(head): p = head while p: print(p.data) p = p.next head = create_link_list_head_2([1, 2, 3, 4, 5]) traverse_link_list_2(head)
链表在插入和删除的操作上明显快于顺序表。
链表的内存可以更灵活的分配
链表这种链式存储的数据结构对树和图的结构有很大的启发性。
哈希表
哈希表一个通过哈希函数来计算数据存储位置的数据结构,通常支持如下操作:
insert(key, value):插入键值对(key, value)
get(key):如果存在键为key的键值对则返回其value,否则返回空值。
delete(key):删除键为key的键值对
直接寻址表:key为k的元素放到k位置上
改进直接寻址表:哈希(Hashing)
构建大小为m的寻址表T
key为k的元素放到h(k)位置上
h(k)是一个函数,将其域U映射到表T[0, 1, ..., m-1]
哈希表(Hash Table,又称为散列表),是一种线性表的存储结构,哈希表有一个直接寻址表和一个哈希函数组成。哈希函数h(k)将元素关键字作为自标量,返回元素的存储下标。
简单的哈希函数:
除法哈希:h(k) = k mod m
乘法哈希:h(k) = floor(m(kA mod 1)) o < A <1
假设有一个长度为7的数组,哈希函数h(k) = k mod 7,元素介个{14, 22, 3, 5}的村相互方式如下图。

哈希冲突
由于哈希表的大小是有限的,而要存储的值的总数量是无限的,因此对于任何哈希函数,都会出现两个不同的元素映射到同一个位置上,这种情况叫做哈希冲突。
比如:h(k) = k mod 7, h(0) = h(7) = h(14) = ...
开放寻址法
开放寻址法:如果哈希函数返回的位置已经有值,则可以向后探查新的位置来存储这个值。
线性探查:如果位置i被占用,则探查i+1, i+2, ...
二次探查:如果位置i被占用,则探查i+12, i-12, i+22, i-22, ...
二度哈希:有n个哈希函数,当使用第1个哈希函数h1发生冲突时,则尝试使用h2, h3, ...
拉链法
哈希表每个位置都连接一个链表,当冲突发生时,冲突的元素将被加到该位置链表的最后。
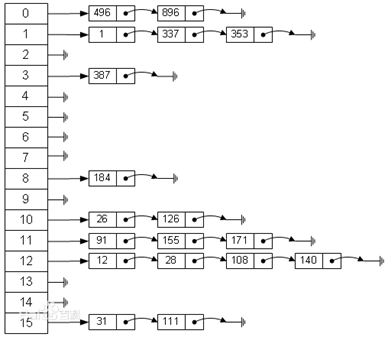
直接寻址表
当关键字的全域U比较小时,直接寻址是一种简单而有效的方法。

直接寻址方法缺点:
当域U很大时,需要消耗大量内存,很不实际。
如果域U很大而实际出现的key很少,则大量空间被浪费。
无法处理关键字不是数字的情况。
树结构
数据结构中的元素存在一对多的相互关系。
二叉树
二叉树的链式存储
将二叉树的节点定义为一个对象,节点之间通过类似链表的连接方式来连接。
节点定义
class BiTreeNode: def __init__(self, data): self.data = data self.lchild = None self.rchild = None
二叉树的遍历
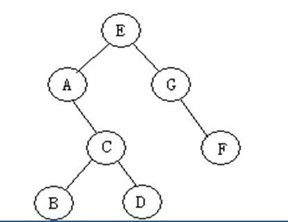
前序遍历(深度优先)
EACBDGF
中序遍历(深度优先)
ABCDEGF
左孩子回去打印
后序遍历(深度优先)
BDCAFGE
俩孩子都回去打印
层次遍历(广度优先)
EAGCFBD
二叉搜索树
二叉搜索树是一棵二叉树且满足性质:设x是二叉树的一个节点。如果y是x左子树的一个节点,那么y.key ≤ x.key;如果y是x右子树的一个节点,那么y.key ≥ x.key。

查询和插入的时间复杂度都是O(logn)。
图结构
数据结构中元素存在多对多的相互关系。例如地图、好友关系等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号