scrapy之五大核心组件
scrapy之五大核心组件
scrapy一共有五大核心组件,分别为引擎、下载器、调度器、spider(爬虫文件)、管道。
爬虫文件的作用:
a. 解析数据
b. 发请求
调度器:
a. 队列
队列是一种数据结构,拥有先进先出的特性。
b. 过滤器
过滤器适用于过滤的,过滤重复的请求。
调度器是用来调度请求对象的。
引擎:
所有的实例化的过程都是由引擎来做的,根据那到的数据流进行判断实例化的时间。
处理流数据
触发事物
scrapy五大核心组件之间的工作流程:
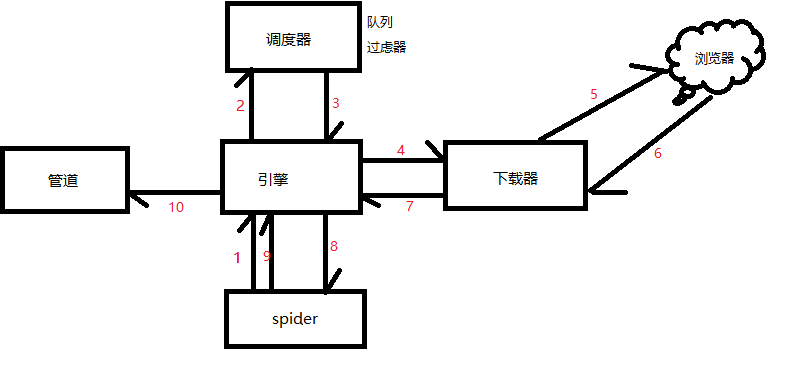
scrapy框架得的五大组件之间的工作流程上图所示:
当我们执行爬虫文件的时候,这五大组件就已经开始工作了 。其中,
1 首先,我们最原始的起始url是在我们爬虫文件中的,通常情况系,起始的url只有一个,当我们的爬虫文件执行的时候,首先对起始url发送请求,将起始url封装成了请求对象,将请求对象传递给了引擎,引擎就收到了爬虫文件给它发送的封装了起始URL的请求对象。我们在爬虫文件中发送的请求并没有拿到响应(没有马上拿到响应),只有请求发送到服务器端,服务器端返回响应,才能拿到响应。
2 引擎拿到这个请求对象以后,又将请求对象发送给了调度器,队列接受到的请求都放到了队列当中,队列中可能存在多个请求对象,然后通过过滤器,去掉重复的请求
3 调度器将过滤后的请求对象发送给了引擎,
4 引擎将拿到的请求对象给了下载器
5 下载器拿到请求后将请求拿到互联网进行数据下载
6 互联网将下载好的数据发送给下载器,此时下载好的数据是封装在响应对象中的
7 下载器将响应对象发送给引擎,引擎接收到了响应对象,此时引擎中存储了从互联网中下载的数据。
8 最终,这个响应对象又由引擎给了spider(爬虫文件),由parse方法中的response对象来接收,然后再parse方法中进行解析数据,此时可能解析到新的url,然后再次发请求;也可能解析到相关的数据,然后将数据进行封装得到item,
9 spider将item发送给引擎,
10 引擎将item发送给管道。
其中,在引擎和下载中间还有一个下载器中间件,spider和引擎中间有爬虫中间件,
下载器中间件
可以拦截请求和响应对象,请求和响应交互的时候一定会经过下载中间件,可以处理请求和响应。
爬虫中间件
拦截请求和响应,对请求和响应进行处理。
0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号