Saliency Guided Experience Packing for Replay in Continual Learning---阅读笔记
摘要:
本文是针对持续学习方法中的重放方法进行改进,重放方法的内存大小决定了优化性能。本文提出了新的经验重放的方法,通过查询显著性图来挑选经验存入内存,由显著性图引导,把对模型决策影响很大的输入图像的部分或者patch存入内存中,在学习一项新任务时,我们用适当的零填充来回放这些内存patch,以提醒模型其过去的决定。
1. Introduction
重放方法核心是模型把新样本和情景记忆中的样本联合起来进行优化。但是该方法的性能取决于情景记忆的内存大小,因此很多学者研究设计小情景记忆的高效经验重放,但是这些方法主要都由于过拟合造成了高的遗忘。在本文中提出了一个使用小的情景记忆在在线任务流上训练一个固定模型的持续学习算法,该方法称为“EPR” ,该方法把更多的过去信息的总结塞进到了内存中,通过减少过拟合提高内存重放的性能。
在各种可解释性技术中,显著性方法突出了模型认为在输入数据(图像)中对其最终决策很重要的部分。因此,本文假设只存储和回放图像的重要部分,这些重要部分可以有效地提醒网络过去的任务因此减少遗忘。因此,在EPR中,在学习每个任务后,不是存储整个图片而是通过使用显著性图来识别每个类中不同的图片的重要的patch然后存在情景记忆中。
在学习一项新任务时,我们从内存中检索这些patch,zero-pad它们与原始图像大小相匹配,并使用它们进行经验重放。
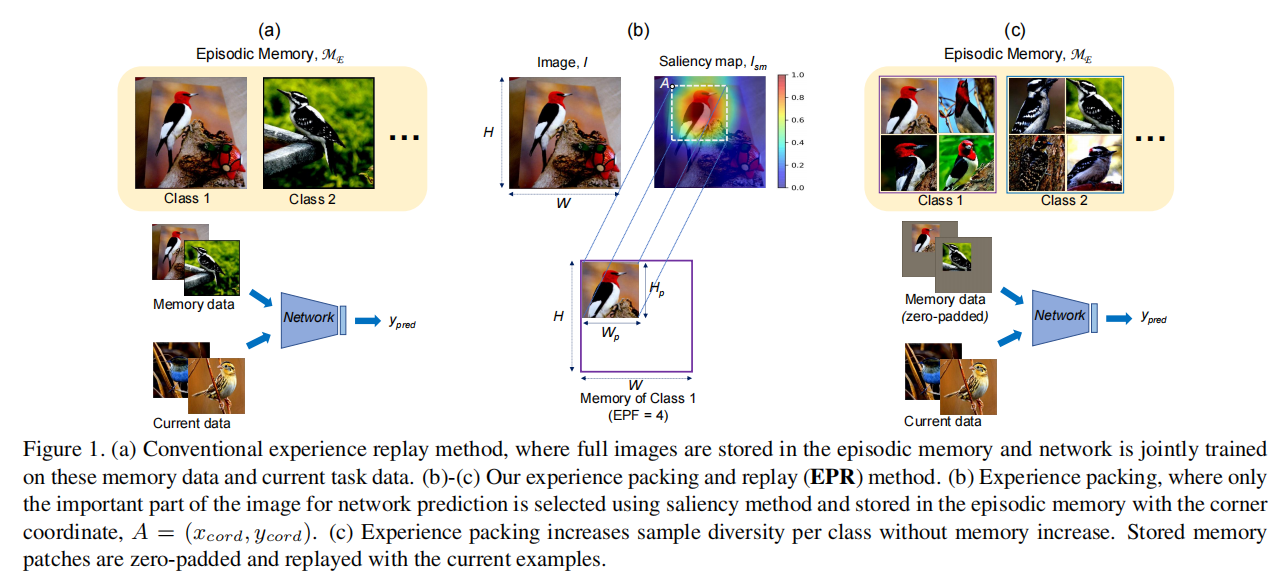
2. Related Works
3. Background and Notations
Continual Learning Protocol.
一个模型从一个有序的数据集序列中学习,\(D = {D_1,...,D_T}\)由T个任务组成,其中\(D_k={(I_i^k,t_i^k,y_i^k)_{i=1}^{n_k}}\) 是数据集的第k个任务。在这些数据集中的每个样例都由一个三元组构成,其中输入(\(I^k \in X\)) ,任务标识符(\(t^k \in T\)) ,目标向量(\(y^k \in Y^k\)). 在本实验中,使用前K个任务进行Cross-Validation 去设置持续学习算法的超参数,剩余的T-K个任务被用来进行训练和评估。在这个设置中,目标是学习一个神经网络,\(f_θ: X×T→Y\), 将任何输入对\((I,t)\)映射到目标输出\(y\),并在所有任务上保持性能.
Saliency Map Generation.
显著性方法根据输入中的相关特征为模型预测提供了可视化的解释。
例如:对于一个属于类别 \(c\) 的输入图像\(I\in\mathbb{R}^{W\times H\times C}\) ,这些方法会产生一个显著性图,\(I_{sm}\in\mathbb{R}^{W\times H}\) 通过将高强度值分配给有助于模型决策的相关图像区域,显著性图有以下公式得出:
在这项工作中,我们主要使用梯度加权的类激活映射(Grad-CAM)作为显著性方法。根据给定的模型预测,它基于反向传播到后面的卷积层的梯度来生成特定于类的显著性映射。
4. Experience Packing and Replay (EPR)
Experience Replay
Experience Packing Factor (EPF)
这里考虑\(n_{sc}\) 表示赋予每个类的内存槽数,一个槽可以存在一整个训练的图片。对于一个给定的图像\(I\in\mathbb{R}^{W\times H\times C}\) 和目标patch 尺寸\(I_p\in\mathbb{R}^{W_p\times H_p\times C}\) ,Experience Packing Factor (EPF)由以下比率定义:
EPF是整值的,它指的是任何特定类的给定内存槽\(n_{sc}\)的patch数量。
在我们的设计中,我们考虑了正方形图像(W = H)和patch(Wp = Hp),并将EPF设置为一个超参数。因此,对于一个给定的EPF,我们确定图像patch的大小为:
例如,要将4个patch(EPF= 4)塞进到1个内存插槽(\(n_{sc}\))中,patch的宽度应该为整个图像宽度的一半。
Memory Patch Selection and Storage
本文建议只存储该图像的重要部分(patch),并在重放时使用它来提醒网络它过去的决定。从完整图像的显著性图中识别出这些patchs。因此,在学习每个任务时,我们只将少数训练图像存储在一个小的、固定大小的FIFO“临时环缓冲区”,\(M_T\)中。在每个任务的结束,使用显著性图从这些图像中提取所需的patch数量,并将它们添加到内存\(M_E\)中。来自\(M_T\)的图像仅仅被用来patch选择,不用在后来的任务的经验重放上。一旦内存patch存储在\(M_E\)中,临时缓冲区\(M_T\)就会被释放,以便在下一个任务中重用。用\(f_{\theta}^{k}\) 表示训练任务k后的模型,对于每一个在\(M_T\)中的样例,都会产生对应的显著图,即公式(1)里的\(I_{sm}\) . 对于给定的\(n_{sc}\)和已经选好的EPF ,可以获得patch 的大小。然后,使用核尺寸和步长 average-pool 显著图,存储核(patch)对应的最大的平均池值的左上角坐标 (\(x_{cord},y_{cord}\))。换句话说,就是识别显著图上有着最大平均强度的区域。通过以下公式来获得内存patch:
在\(M_T\)中每个类保留的图像样本比在\(M_E\)中存储的图像patch的数量更多。本文将会使用在\(M_E\) 中的patch结合zero-padding进行重放,对这些patchs进行优先级排序,即在零填充后的接近正确的类预测的patch。因此,我们零填充每个图像patch,\(I_p\),并检查模型预测。首先,我们用模型中给出正确预测的patch来填充内存。然后,我们用模型的前3个预测中正确的类的patch来填充\(M_E\)中剩余的插槽。任何剩余的内存槽将从剩余的patch中填充,与模型预测无关。然后将每个选定的图像patch添加到\(M_E = M_E∪{(I_p,t^k,c,x_{cord},y_{cord})}\)中,在原始图像中包含任务ID、类标签和可定位的坐标。
Replay with Memory Patches.
由于存储在\(M_E\)中的patch比原始图像小,所以每次使用它们进行经验回放时,我们都零填充这些patch(图1(c))。当零填充时,我们使用坐标值(\(x_{cord},y_{cord}\))将这些patch放置在其原始图像的“精确”位置。
因此,重放将具有与当前任务的样本相同的维度。

5. Experimental Setup
Datasets:
- Split CIFAR
- Split miniImageNet
- Split CUB
Baselines:
- A-GEM
- MIR
- MER
- MEGA-I
- DER++
- ASER
- HAL
- ER-RING (experience replay with ring )
- reservoir (ER-Reservoir) buffer
- EWC (uses regularization)
- RRR (uses regularization)
Performance Metrics:
- ACC
- BWT
6. Results and Analyses
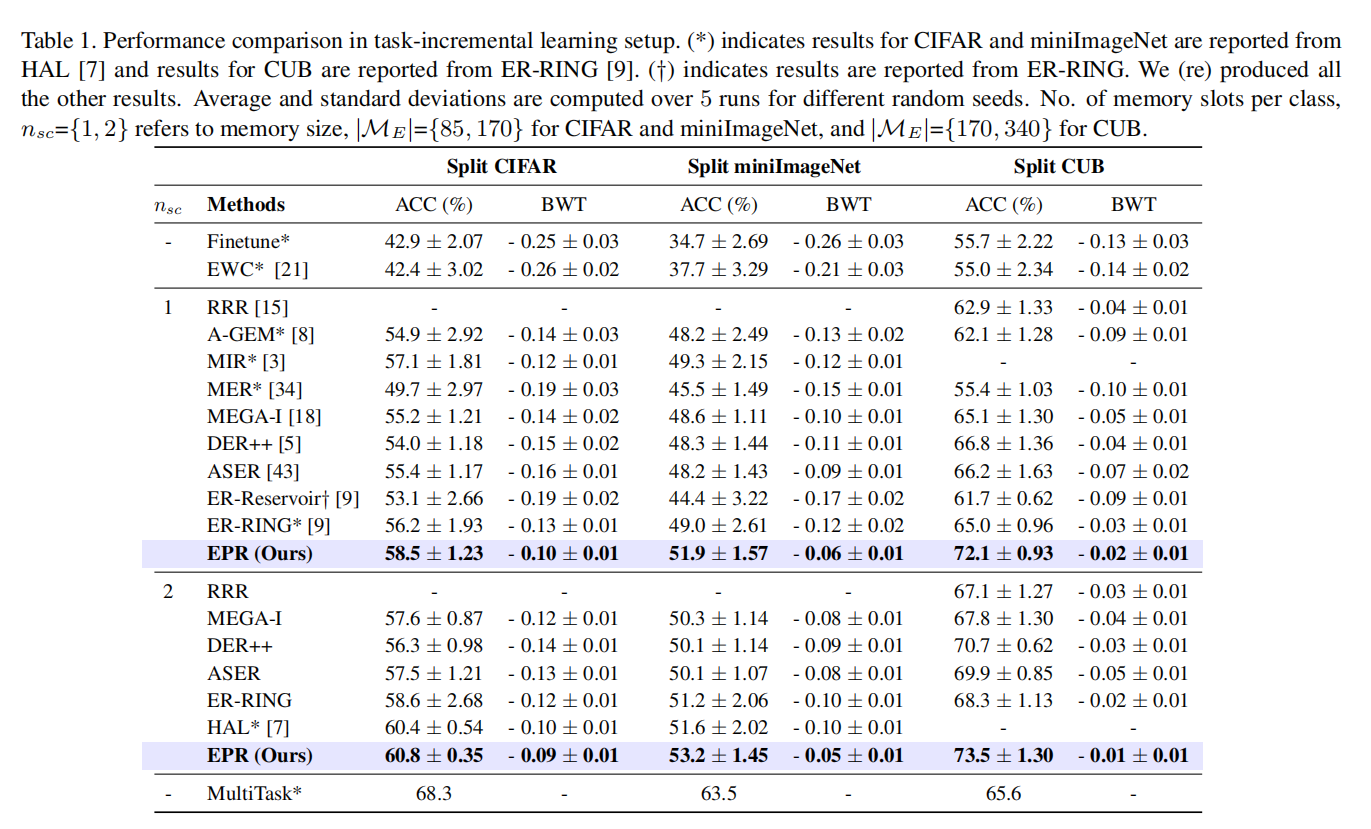
在表1中,我们比较了EPR和HAL,其中EPR还对每个类使用两个内存槽。在这种等情景记忆条件下,EPR比两个数据集的HAL具有更好的准确性和更低的遗忘率。在这种情况下(\(n_{sc} = 2\)),EPR的性能显著优于所有其他方法。对于所有的数据集,EPR中的遗忘量随着内存大小的增加而减少。
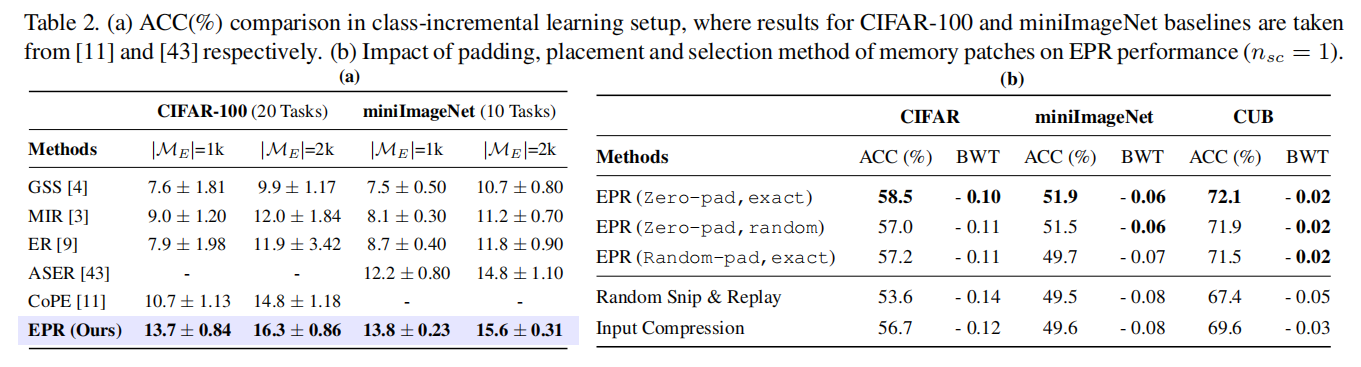
在所有数据集上,精确放置比随机放置略好一些。这表明,如果神经网络在重放过程中找到了原始位置的类识别特征,那么它对过去的任务的记忆会更好。对于所有的数据集,零填充比随机填充表现得更好(表2(b)),这表明完全去除背景信息可以更好地提醒网络过去的任务。因此,在我们所有的实验中,我们都使用了具有精确位置的零填充物
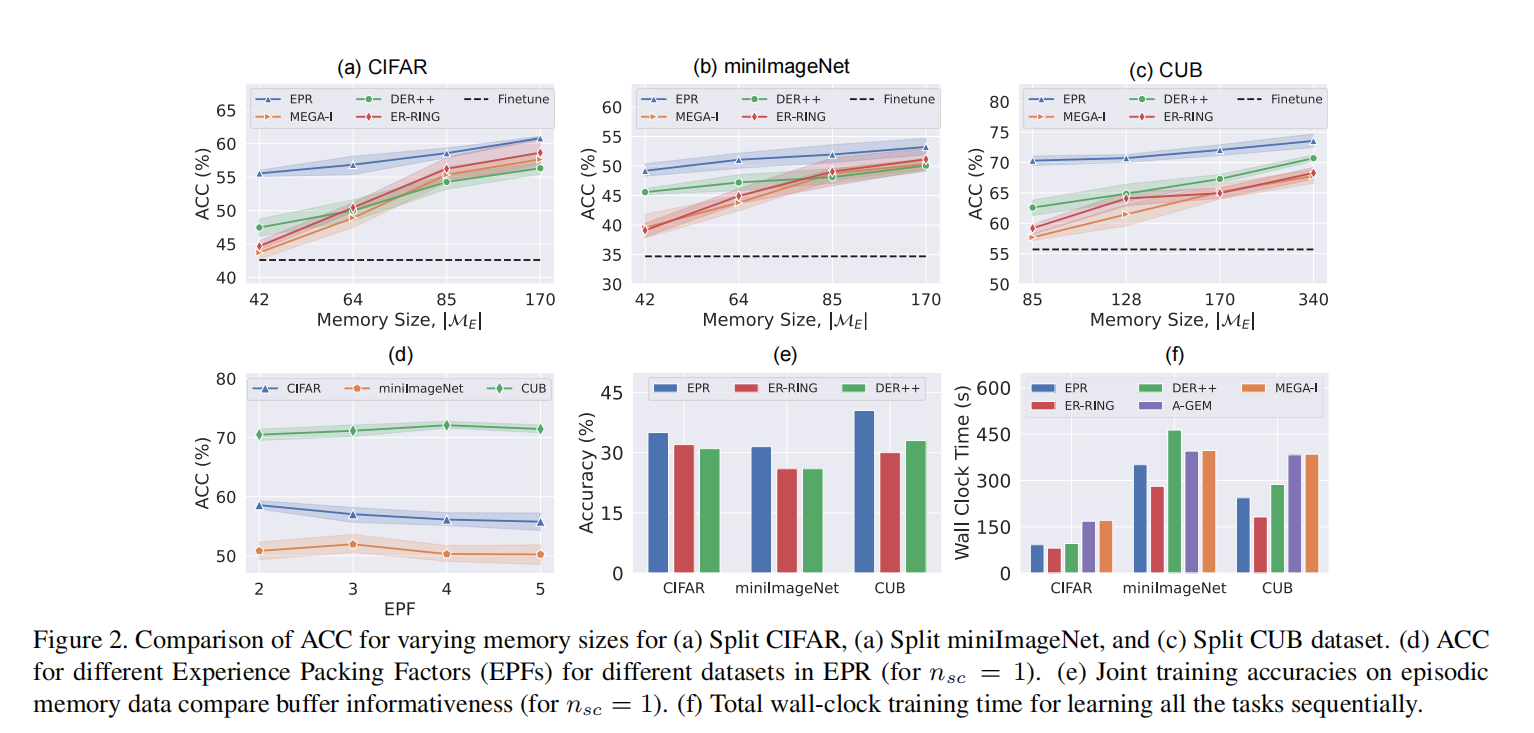

图3显示了我们实验中不同数据集的不同类的显著性映射。
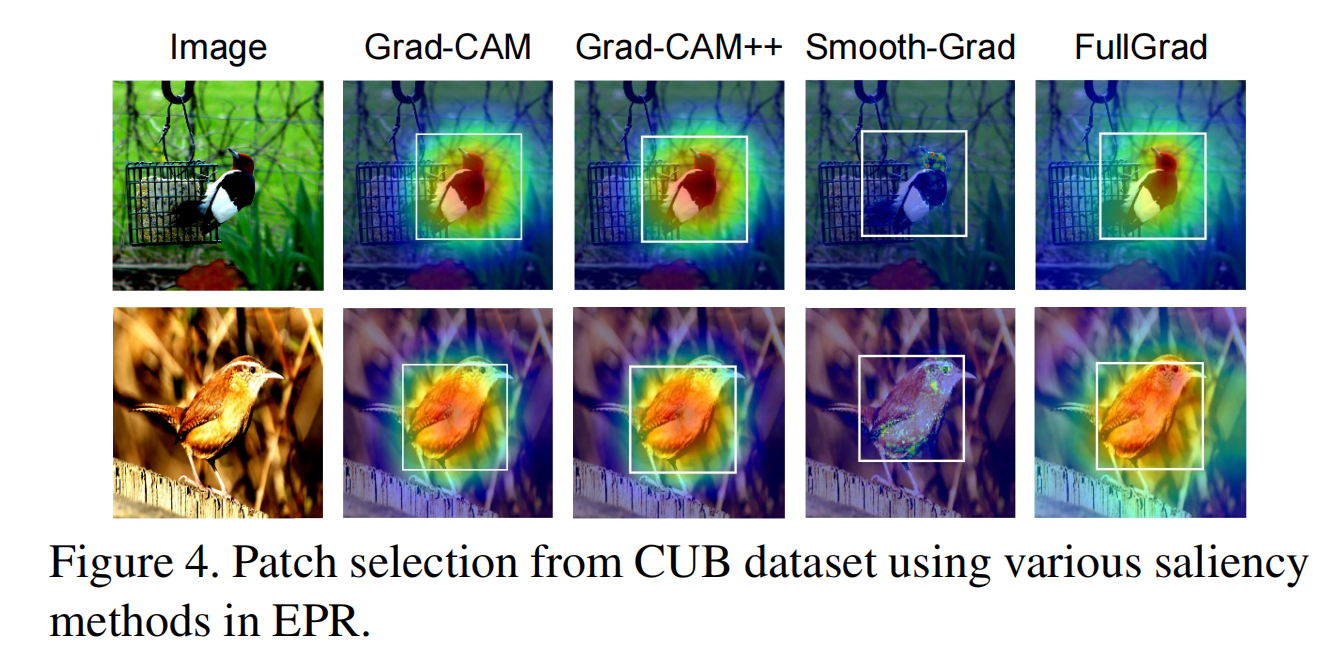
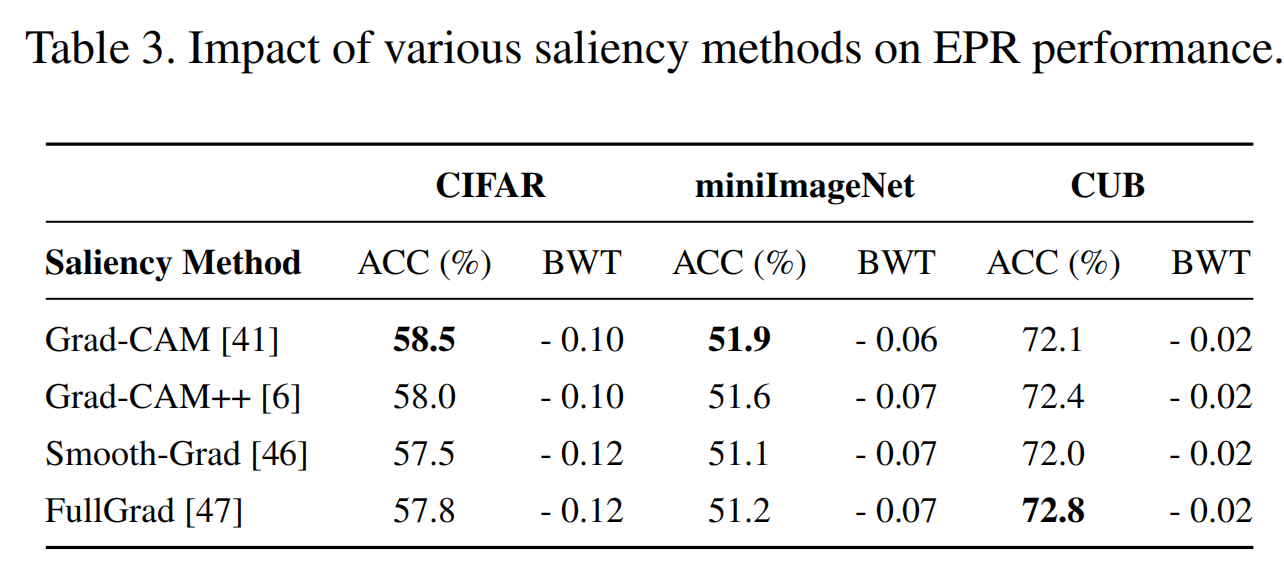
各种显著性方法对EPR性能的影响。
7. Conclusions
在本文中,我们提出了一种新的小情景记忆持续学习。利用显著性图,我们的方法识别出了输入图像中对模型预测很重要的部分。将这些patch,而不是完整的图像存储在内存中,并将它们与适当的零填充一起进行重放。因此,我们的方法将内存包含不同的经验,从而在不增加内存的情况下更好地捕获过去的数据分布。与SOTA方法在不同图像分类任务上的比较表明,该方法简单、快速,在遗忘量最少的情况下具有较好的精度。这项工作为未来的研究开辟了丰富的途径。首先,更好地理解模型的决策过程,利用显著性方法更好地进行特征定位,将提高记忆patch的质量,从而提高体验回放。其次,可以探索新的patch重放技术,以进一步减少内存过拟合。最后,未来的研究可以探索我们的概念在其他领域的可能应用,如在强化学习.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号