DyTox Transformers for Continual Learning with DYnamic TOken eXpansion----阅读笔记
摘要:
深度网络架构努力不断学习新任务而不忘记以前的任务。最近的一个趋势表明,基于参数扩展的动态体系结构可以在持续学习中有效地减少灾难性遗忘。然而,现有的方法存在一些弊端:
(1)通常需要在测试时使用一个任务标识符;
(2)需要进行复杂的调优来平衡不断增长的参数;
(3)几乎没有在任务之间共享任何信息。
因此,它们很难在没有大量开销的情况下扩展到大量的任务。
在本文中,我们提出了一种基于专用编解码器框架的transformer架构。编码器和解码器在所有任务之间都是共享的。通过对特殊tokens的动态扩展,我们将解码器网络的每个正向专用于任务分布。本方法的优点:
(1)我们的策略可以扩展到大量的任务,但由于严格控制参数的扩展,内存和时间开销可以忽略不计。
(2)这种有效的策略不需要任何超参数调优来控制网络的扩展。
我们的模型在CIFAR100上取得了优异的结果,并在大规模的ImageNet100和ImageNet1000上取得了最先进的性能,同时比并发动态框架具有更少的参数。
1. Introduction
越来越多的努力来解决灾难性遗忘。最近的工作动态地扩展网络架构或重新安排其内部结构。但是在测试时,他们需要知道测试样本所属的任务,以便知道应该使用哪些参数。DER和Simple-DER通过学习不同子组参数产生的所有嵌入连接的单一分类器,放弃了对这个任务标识符的需要。但是,这些策略在处理大量任务时会了巨大的内存开销,因此需要复杂的修剪作为后处理。
为了提高持续学习框架的易用性,我们的目标是设计一个动态可扩展的表示,它拥有以下三个属性:随着任务数量的增长,
(1)有限的内存开销,
(2)有限的时间开销,
(3)在面对未知的(潜在的大)任务时,没有设置特定的超参数提高健壮性。
2. Related work
Continual learning :
模型解决了旧类的灾难性遗忘。在计算机视觉中,大多数应用于大规模数据集的持续学习策略都使用rehearsal学习:在训练期间保留了有限数量的旧类的训练数据。这些数据通常以原始形式(例如,像素)保存,但也可以压缩,或修剪以减少内存开销;另一些则只存储一个模型来生成过去类的新样本。此外,大多数方法的目的都是限制在学习新类时模型中的变化。这些约束可以直接应用于权值、中间特征、预测概率或梯度。所有这些基于约束的方法都使用相同的静态网络架构,它们不会随着时间的推移而发展,通常是ResNet、LeNet 或小型MLP。
Continual dynamic networks :
相比之下,我们的论文和其他论文专注于设计动态架构,最好地处理不断增长的训练分布,特别是通过动态创建(子)成员,每个成员专门从事一个特定的任务。不幸的是,以前的方法通常要求在测试时使用样本的任务标识符来选择正确的参数子集。我们认为,这在现实生活中,新的样本可能来自任何任务。最近,DER 提出了一种动态扩展,为每个任务添加一个新的特征提取器。然后,所有提取器的嵌入将被连接并输入到一个统一的分类器中,从而在测试时不需要使用任务标识符。为了限制参数数量的爆炸式增长,他们在使用HAT 过程完成每个任务后,积极地修剪每个模型。不幸的是,剪枝是对超参数敏感的。因此,超参数在每个实验中都有不同的调整:例如,以10步或50步学习一个数据集,使用不同的超参数。虽然是不可行的,但也是不现实的,因为在真正的持续情况下,类的数量是不预先知道的。Simple-DER 也使用多个提取器,但其修剪方法不需要任何超参数;相反的是,Simple-DER控制的参数增长较少(比基本模型高2.5倍)。相比之下,我们提出了一个致力于持续学习的框架,该框架无缝地实现了任务动态策略,对所有设置都有效,没有任何依赖于设置的修改,而且几乎没有内存开销。我们与TreeNets 类似,共享了早期的类不可知的层,并基于变压器架构建立了我们的策略。
Transformers :
最初被引入机器翻译,与现在著名的self-attention。虽然最初的transformer是由编码器层和解码器层组成的,但后来从BERT开始的transformer使用了一系列相同的编码器块。然后,ViT 提出利用像素块作为标记,将transformer应用于计算机视觉。最近的多项工作,包括DeiT、CaiT、ConVit和Swin ,通过架构和培训程序的修改改进了ViT。提出了一种通用的架构,其输出使用特定的学习标记适应不同的模式,并使用少量的潜在标记减少其计算。尽管在各种基准上都很成功,但据我们所知,transformer还没有被考虑为持续的计算机视觉。然而,我们使用transformer架构并不是为了其本身,而是因为transformer的内在特性;特别是,开创性的编码器/解码器框架允许我们构建一个具有强大的对抗灾难性遗忘能力的高效架构。
3. DyTox transformer model
我们的目标是以固定的步骤T学习一个统一的模型,它将越来越多的类进行分类。
模型框架图:

3.1. Background
vision transformer有三个主要组件:patch tokenizer、由自注意块组成的编码器以及分类器。
Patch tokenizer :
将固定大小的输入\(RGB\)图像裁剪成\(N\)个等维的斑块,然后用一个线性层投影到一个维度\(D\)上。裁剪和投影,是通过一个单一的二维卷积进行操作的,其核大小等于它的步幅大小。结果张量 $x_0 \in R^{N \times D} $ 经过一个学习到的class token \(c_{class} \in R^D\) 扩展成一个形状为 \(R^{(N+1)\times D}\) ,然后再加上学习到的位置嵌入形成最终的一个向量。
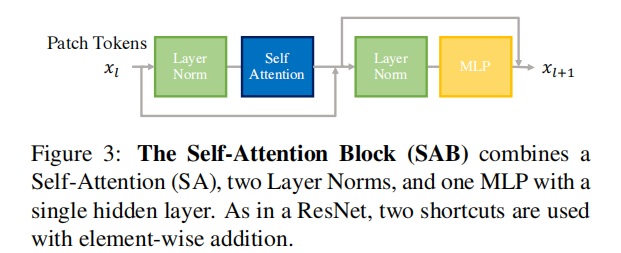
Self-Attention (SA) based encoder:
token被输入到transformer块堆栈,我们在这里表示为自我注意力块(SAB):
我们对每个SAB重复L次这些操作。
Classififier:
在原始的vision transformer(ViT)中,一个名为“类标记”的学习向量被附加到令牌器后面的patch tokenizer中。这个特殊的类标记,在所有SAB后处理时,被给予一个具有softmax激活的线性分类器来预测最终的概率。然而,最近的工作,如CaiT ,建议只在最终或倒数第二个SAB中引入类标记,以提高分类性能。
3.2. Task-Attention Block (TAB)
与以前的transformer架构相反,我们没有class token,而是我们昵称的“task token”;第i个任务的学习的token表示为\(θ_i\)。此特殊的token将只在最后一个块中添加。为了利用这个task token,我们定义了一个新的注意层,我们称之为任务-注意层。它首先将由最终SAB产生的patch tokens \(x_L\)与task token \(θ_i\) 拼接起来:
受Touvron等人的Class-Attention的启发,给出Task-Attention (TA):
其中,d为嵌入维数,h为注意头数。
与经典的自我注意相反,任务注意只从任务标记\(θ_i\)中定义其查询(\(Q_i\)),而没有使用patch tokens \(x_L\)。
Task-Attention Block(TAB)是SAB的一个变体,其中attention是Task-Attention(TA):
总的来说,我们的新架构可以总结出来为:重复SAB模块和单个的TA块TAB结束组成:
最终的嵌入\(e_i\)被提供给一个由\(Norm_c\)和一个由\({W_c,b_c}\)参数化的线性投影组成的分类器clf:
3.3. Dynamic task token expansion
我们在前一节中定义了我们的基本网络,由一系列SAB组成,并由一个TAB结束。如前所述,TAB有两个输入:从图像中提取的补丁标记\(x_L\)和一个学习到的任务标记\(θ_i\)。现在,我们将详细介绍在每一步中,我们的框架是如何在持续的情况下发展的。
在第一步中,只有一个任务标记\(θ_1\)。在每个新步骤中,我们通过创建一个新的任务token来扩展我们的参数空间,因此,在t步骤之后,我们有t个任务token。给定一个图像\(x\) , 我们的模型将它标记为\(x_0\),并通过多个SAB处理它:输出补丁标记\(x_L\)。最后,我们的框架通过TAB的任务:每个TAB向前传递都使用不同的任务令牌\(θ_i\)执行,导致不同的特定任务的转发,每个都产生特定任务的嵌入\(e_i\):
我们不是将所有嵌入连接在一起,并将它们提供给一个分类器,而是利用特定于任务的分类器。
每个分类器\(clf_i\)都由一个\(Norm_i\)和一个由\({W_i,b_i}\)参数化的线性投影组成,它将其特定于任务的嵌入\(e_i\)作为输入,并返回:
激活函数是sigmoid函数。与softmax激活相比,元素sigmoid型激活减少了最近类的过度自信。因此,该模型得到了更好的校准,这是连续模型的一个重要属性。损失是双交叉熵。独立分类器范式结合sigmoid型激活和二值交叉熵损失,明确地排除了任务嵌入的后期融合,从而产生更专门的分类器。
The overall structure of the DyTox strategy
DyTox策略的总体结构如图2所示。我们也会在Algo1中展示,在学习完任务t后的测试时正向通过的伪代码。重要的是,测试图像可以属于之前看到的任何任务{1…t}。我们的动态任务令牌扩展比朴素参数扩展更有效,因为朴素参数扩展将为每个新任务创建整个网络的新副本。
(1)我们的扩展仅限于每个新任务的一个新任务token,它只有d = 384个新参数。与总模型大小(≈1100万参数)相比,这一点很小。因此,内存开销几乎为空。
(2)执行计算密集型的块(即SAB)只有一次,尽管你学习了多个任务。相比之下,TAB有许多有任务的转发。然而,这导致了最小的开销,因为任务注意的数量是线性复杂度是w.r.t的,而自注意是二次的。因此,时间开销是次线性的。

Context
从BERT 开始并继续使用ViT 的transform范式是基于编码器+分类器结构的。不同的是,我们的动态框架偏离是原始transformer的编码器/解码器结构的复兴:编码器是为所有输出共享的(在内存和执行中)。解码器参数也是共享的,但它的执行是特定于任务的,每个正向类似于从专家的混合中选择的特定于任务的专家。此外,多任务基于文本的转换器有自然语言标记作为任务的指示器(,在我们的视觉上下文中,我们使用我们定义的任务标记作为指示器。
Losses
我们的模型有三个损失训练: (1)分类损失\(L_{clf}\),二值交叉熵,(2)应用于概率的知识蒸馏 \(L_{kd}\),(3)散度损失\(L_{div}\)。
蒸馏损失有助于减少遗忘。更复杂的蒸馏损失可以进一步改善结果。散度损失的灵感来自DER的“辅助分类器”,使用当前最后一个任务的嵌入et来预测(|Ct | + 1)概率:当前最后一个任务的类Ct和一个额外的类,表示通过排练遇到的所有以前的类。该分类器在测试时被丢弃,并鼓励任务标记之间有更好的多样性。总损失为:
5. Conclusion
本文提出了一种基于transformer架构的持续学习动态策略DyTox。在我们的模型中,自我注意层在所有任务中共享,我们添加了特定于任务的标记,通过一个新的任务-注意层来实现任务专用的嵌入。这种体系结构允许我们用很少的内存开销动态地处理新任务,并且不需要复杂的超参数调优。我们的实验表明,我们的框架可以扩展到像ImageNet1k这样的大型数据集,具有最先进的性能。此外,当考虑到大量的任务(即CIFAR100 50步)时,我们的参数数量就会合理地增加,这与以前的动态策略相反。
局限性:真正的持续学习的目标是学习几乎无限数量的任务与低遗忘。目前还没有一种方法能够做到这一点。因此,遗忘对于持续学习还没有得到解决,但我们的模型是朝着这个方向向前迈进了一步。
更广泛的影响:机器学习模型往往带有偏见,一些class的表现较低。研究持续学习中的遗忘提供了关于不同班级之间表现差异的见解。我们的任务专用模型可以帮助减少这些偏见。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号