Continual Learning with Lifelong Vision Transformer----阅读笔记
Continual Learning with Lifelong Vision Transformer----阅读笔记
摘要:
在本文中,我们提出了一种新的基于注意力的框架 Lifelong Vision Transformer(LVT),以实现更好的稳定性-可塑性权衡的持续学习。具体的,LVT提出了一种任务间的注意力机制,可以吸收以前任务的信息以及减缓了重要注意力在先前任务和当前任务之间的漂移。LVT设计了一种双分类器结构,独立注入新的表示以避免灾难性干扰,并以平衡的方式积累新知识和以前的知识,以提高整体性能。此外,我们提出了一种置信度感知的内存更新策略,以加深对之前任务的印象。大量的实验结果表明,我们的方法在持续学习基准上以更少的参数达到了最先进的性能
1. Introduction
灾难性遗忘:
危害:
稳定性可塑性困境:
任务增量学习:
类增量学习:
无论是基于正则化的方法、基于演练的的方法还是基于蒸馏的方法都是基于或者被设计用于卷积神经网络CNN,都没有充分利用最近新出现的非常有潜力的vision transformers.
Vision Transformers最近在某些基于自我注意机制的计算机视觉任务上表现出了优越性.
在这项工作中,我们提出了一个新的框架,Lifelong Vision Transformer(LVT),它在持续学习中发挥了注意机制的优势,实现了更好的稳定性-可塑性权衡。我们提出了一种任务间的注意机制来获得注意映射,该机制通过计算self-queries和带有注意力偏置的可学习的外部键的相似性来获得注意映射。
LVT提出利用两种分类器:使用注入分类器向模型中注入新的任务表示,减少对以往任务的干扰;积累分类器侧重于以平衡的方式整合先前的知识和新的知识,以提高整体性能。
本文的主要贡献有四个方面:
(1)我们提出了一种新的基于注意力的框架 Lifelong Vision Transformer(LVT),以实现更好的稳定和可塑性权衡的持续学习。LVT包含一种任务间注意机制,巩固先前的知识,减轻对先前任务的遗忘。
(2)LVT提出了一种新的双分类器结构,可以独立地注入新的任务表示,避免灾难性的干扰,并以一种平衡的方式积累新的和以前的知识。
(3)我们提出了了一种置信度感知的内存更新策略,以加深对之前任务的印象。
(4)大量的实验结果表明,我们的方法在持续学习基准上以更少的参数达到了最先进的性能。
2. Related Work
2.1. Continual learning
Rehearsal-based methods:重放存储在有限内存中的先前任务的范例子集来防止灾难性遗忘。
(1)Experience Replay(ER)通过将之前的任务范例与当前的任务数据交织,联合优化网络参数。
(2)ERT 通过平衡抽样策略和偏差控制进一步改善了ER。
(3)GSS 引入了一个基于梯度的采样,以在内存缓冲区中存储最佳选择的范例。
(4)HAL 用一个额外的目标来补充经验回放,保持对过去任务的一些锚点的预测的完整。
(5)GEM 和AGEM 利用情景记忆来计算之前的任务梯度来约束当前的更新步骤。
(6)iCaRL 训练一个最近的类平均分类器,同时通过自蒸馏损失项在以后的任务中保持表示。
(7)DER++ 混合了排练和蒸馏损失,以重新训练过去的经验,并达到最先进的性能。
(8)RM 提出了一种利用不确定性和数据增强的抽样策略。
Other Approaches
(1)基于正则化的方法试图估计每个网络参数对先验任务的重要性,并惩罚在新任务学习过程中重要参数的变化。
(2)基于结构的方法在新任务的到来时扩展网络,并保持与之前任务相关的子网络参数不变。然而,大多数基于结构的方法在推理过程中都需要任务标识,以便将不同的参数集分配给不同的任务。
(3)基于标签的方法从带有标签关系的顺序数据中对流式标签进行建模。
本文提出的方法属于基于排练的方法。
2.2. Vision Transformers
Transformer首先在中被提出用于机器翻译任务,从那时起,变压器架构已经成为自然语言处理(NLP)任务的最先进的模型. Transformer中的核心组件是注意力模块,它从整个输入序列中聚合信息。最近,Vision Transformer(ViT)开发了一个纯Transformer架构,可在数据足够大时用于图像分类。在此之后,许多工作已经致力于提高Vision Transformer的数据效率和模型效率。一个流行的研究方向是探索将显式卷积或卷积的特性集成到Transformer架构中。CoaT设计了一个通信-注意模块来实现具有卷积的相对位置嵌入。LeViT用池化的金字塔取代了Transformer的均匀结构来学习类似卷积的特征。CCT 通过序列池策略和使用卷积,消除了对类标记和位置嵌入的需求。
然而,目前的Vision Transformer并不能直接用于建模一系列任务;现有的为cnn设计的连续学习算法可能也不是Vision Transformer的最佳算法。为此,我们提出了Lifelong Vision Transformer(LVT),其任务间注意力设计用于持续学习,并获得比其他Transformer和CNN基线更好的性能。
3. Methodology
3.1. Problem Setup
一个持续学习问题被分成一系列的 \(T\) 个监督学习任务\(T_t\),对于任务\(T_t\),输入样本\(x∈X_t\)和相应的真实标签\(y∈Y_t\) 来源于独立同分布的\(D_t\)。模型的标签空间都是所有观察到的类\(U_{i=1}^{t}y_i\),并且期望模型对所有类都有很好的预测。该模型以顺序的方式一次观察一个任务,因此联合优化所有观察到的类是不可行的,但少量的数据可以存储在有限的内存M中,以备将来排练。
3.2. Lifelong Vision Transformer (LVT)
我们提出了基于注意力的Lifelong Vision Transformer(LVT),以有效缓解持续学习的灾难性遗忘。图2描述了该框架的概述。LVT的主要组成部分如下:
(1)终身转换块中的任务间注意隐含地将先前的任务信息吸收到注意映射中,并根据先前观察到的任务的重要性降低了注意映射的学习速度。
(2)双分类器:注入分类器在模型中注入新的任务表示,避免了灾难性干扰;积累分类器以一种平衡的方式整合了过去和新的知识,以提高稳定性和可塑性的权衡。
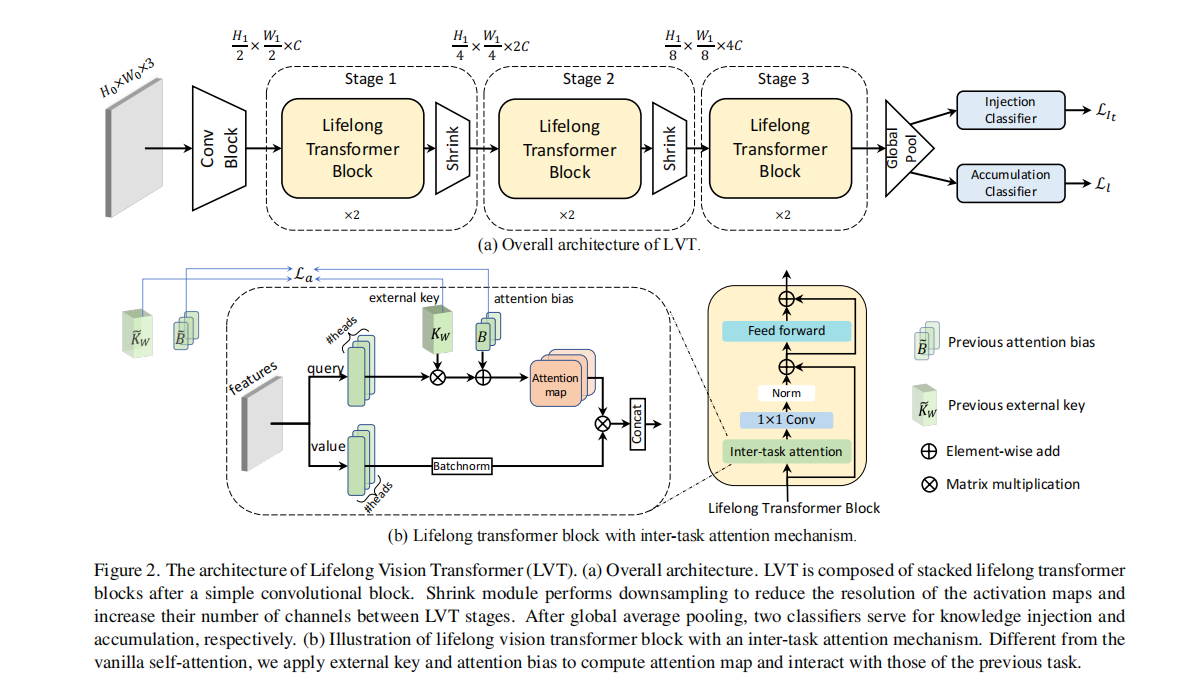
3.2.1 Inter-task Attention Mechanism.
不像vanilla自注意力机制计算q值和k值,我们提出的任务间注意力机制通过计算q值和一个可学习的带有注意力偏置B的外部键\(K_W\)来获得注意力映射。此外,与自我注意相比,任务间注意可以节省参数的数量。当任务发生变化时,\(K_W\)和\(B\)的重要权重通过防止它们在未来任务中的变化而得到巩固,从而避免了对过去任务的灾难性遗忘。
注意力模块更改后的计算公式;
外部关键\(K_W\)和注意偏差B不依赖于当前特征的输入,可以通过端到端方式进行优化,可以捕获之前任务的信息。
此外,可学习参数外部密钥\(K_W\)和注意偏差B通过正则化函数与之前的任务相互作用,以保持注意映射的稳定性,减少遗忘。
具体来说,我们计算当前参数(\(K_W\)和\(B\))与最后一个任务对应的参数之间的加权ℓ1范数
在学习新任务过程中,梯度幅度越大,参数的重要性程度越大。因此,更重要的参数将受到更大的惩罚。我们证明了当新任务的到来时,惩罚注意力映射的变化有助于保留之前任务的信息。值得一提的是,这种损失类似于基于正则化的方法中使用的Fisher信息,它在防止遗忘的同时允许LVT学习新的任务表示
3.2.2 Dual-classifier Structure
大多数基于排练的方法使用相同的分类器来学习新任务,并在内存M中回放以前的数据,这可能会导致新任务和以前任务之间的灾难性干扰。为了解决这个问题,LVT提出利用一种新的双分类器结构,在不受干扰的情况下独立地注入新的表示方式,并以一种平衡的方式积累新的和以前的知识。
Injection Classifier.
首先,我们引入了注入分类器,设g (x)为在分类器之前从LVT的主干输出的样本x的特征。当当前的任务数据到达时,我们利用来自一个独立的注入分类器的输出来计算一个分类损失:
\(f_I\)为注入分类器;\(l\)为交叉熵损失。
注入分类器只对当前的任务数据进行训练,而不参与推理阶段。将当前任务的表示从该分类器注入到LVT的主干中,以减少对之前任务的干扰。此外,由于注入分类器专注于当前任务的好处,\(L_{It}\)还可以用于计算等式(2)中的重要性权值以及对等式 (8)的置信度.
Accumulation Classifier.
然后,我们引入积累分类器如下。由于注入分类器主要进行对当前任务的表示学习,我们采用积累分类器,通过平衡地整合以往和新知识,重点提高稳定性-可塑性的权衡。积累分类器在推理阶段用于输出预测。
在学习新任务的过程中,排练有限的记忆数据是保持先前知识的关键方法。我们通过最小化来重播存储在内存缓冲区中的具有地面真实标签的示例:
\(f_A\)为积累分类器。我们通过计算从内存缓冲区采样的批次的梯度来近似期望。
dark knowledge可以通过蒸馏损失获得:
\(D_{KL}\)表示\(KL\)的散度。我们可以设置softmax的温度来产生合适的软标签(目标)。此外,积累分类器还需要一个来自当前任务数据的监督信号。由于有助于学习当前任务表示的注入分类器,我们可以灵活地调整\(f_A\)中当前任务的权重,以保持新旧类之间的平衡。基于此,我们给出了积累分类器的损失:
α和β是平衡知识巩固的系数;r (t)是相对于到目前为止观察到的任务数量,目的是随着时间的推移减少当前任务的权重,更加注意对抗遗忘。
总的来说,LVT中使用的总损失是等式之和(2), Eq.(3),和等式 (6):
3.3. Confidence-aware Memory Update
基于排练的方法的一个关键问题是,当新的任务到来时,如何更新记忆范例?大多数方法采用蓄水池抽样算法或集合采样来更新内存,其中蓄水池抽样以相同的概率从输入流中随机抽取样本,集合存储接近各类特征均值的样本。
在这项工作中,我们设计了一个基于LVT的注入分类器的置信感知采样,以将令人印象深刻的样本存储在有限的内存中。我们认为,被选择要存储的范例应该具有其类的独特特征,即它们可以通过模型进行准确的区分。与大脑中的记忆类似,回忆这些令人印象深刻的例子可以进一步巩固先前的知识,以便持续学习。为了选择令人印象深刻的样本,我们提出了一个简单而有效的抽样,以存储其类中置信度最高的样本。
给定内存容量M,我们为每个类分配K=M/|C|个范例,其中C是迄今为止观察到的类集。在当前任务Tt与一组类Ct结束时,我们将每个类的样本x放入模型中,并从注入分类器中得到对数z。我们可以通过以下方法得到每个样本的置信度评分ρ:
我们为每个类选择置信度最高的K个样本ρ。这些范例不仅代表了它们对应的类,而且对其他类具有区别性。我们根据对应的ρ值按降序存储样本,其中按顺序排列较早的样本中,ρ的值越高。内存更新还包括删除前一个类的范例,我们将前一个类的范例数量按升序减少到K。
4. Experiment
4.1. Experimental Setup and Implementation
Datasets: CIFAR-100数据集包含100个类,每个类有500个训练图像和100个测试彩色图像。TinyImageNet包括200个类,其中包括10万张用于训练的图像和10,000张用于验证的图像。ImageNet100 包含从ILSVRC 中随机选择的100个类,平均分辨率为469×387。它包括大约12万张用于训练的图像和5000张用于验证的图像。
Baselines:我们比较了LVT与最先进的和成熟的方法,包括8种基于排练的方法(ER,GEM ,AGEM ,GSS ,FDR,HAL,ERT ,和RM ),两种利用知识蒸馏的方法( iCaRL 和DER++ ).此外,我们还比较了SOTA Vision Transformers(ViT 、LeViT 、CoaT 和CCT )与持续学习的排练策略。我们进一步提供了一个通过联合训练所有任务而得到的上界(联合)和一个简单地执行SGD而没有任何遗忘对策的下界。
Metrics: 准确性 遗忘程度
4.2. Comparison to State-of-the-Art Methods
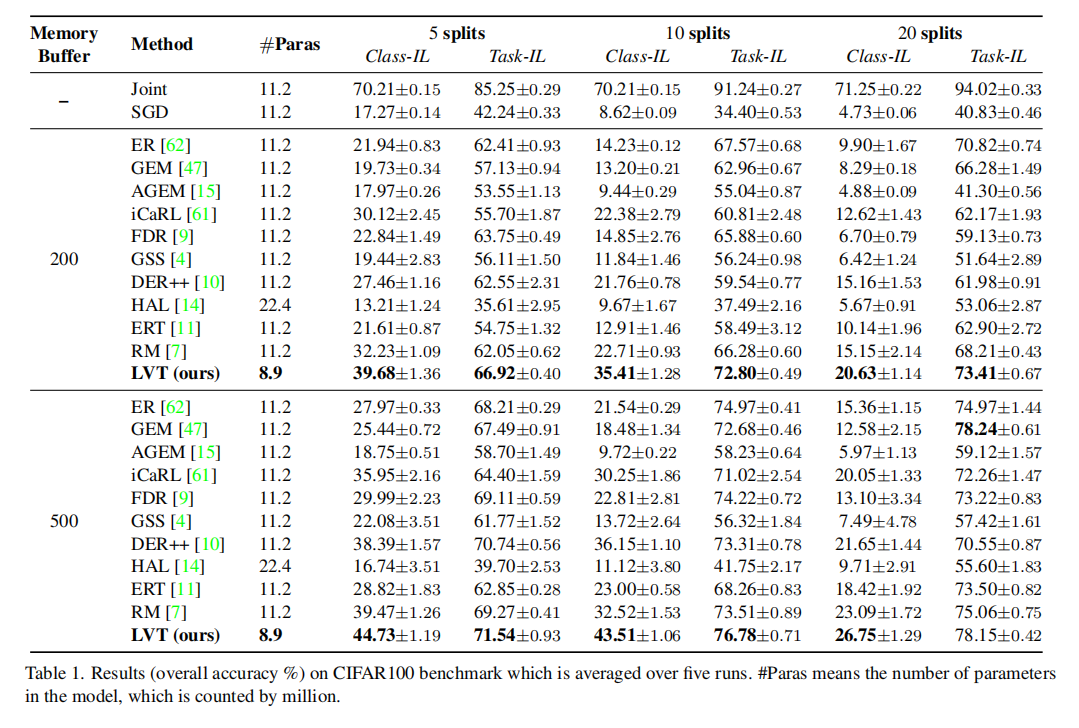
Evaluation on CIFAR100: 我们遵循协议,该协议在几个分割中训练所有100个类,包括5、10、20个增量任务。表1总结了具有200和500内存大小的CIFAR100的总体精度。结果表明,LVT在不同增量分割方面的性能明显优于其他方法,例如LVT在200内存容量的10分割中将连续学习的准确率提高12%以上。特别是在内存较小的情况下,LVT的优势更为明显,说明LVT性能更现实和更具挑战性的数据稀缺情况下会更好。值得注意的是,尽管LVT比其他方法(11.2M∼22.4M)使用更少的参数(8.9M),但它仍然可以达到最先进的性能。其中一个原因是,LVT继承了Transform的优点,并设计了用于建模任务流的架构,因此在不堆叠大量参数的情况下,在持续学习中工作得很好。
Evaluation on ImageNet datasets.:表2总结了TinyImageNet和ImageNet100个数据集的实验结果。结果表明,在TinyImageNet和ImageNet100数据集上,LVT在类-IL和任务-IL方面始终超过了其他方法。具体来说,我们的方法在ImageNet100基准测试上的类il精度方面优于现有的方法,准确率约为5.9%。对于TinyImageNet基准,Task-IL准确率从52.08%提高到57.39%(+5.31%)。此外,与其他基于cnn的方法相比,LVT所采用的参数更少。

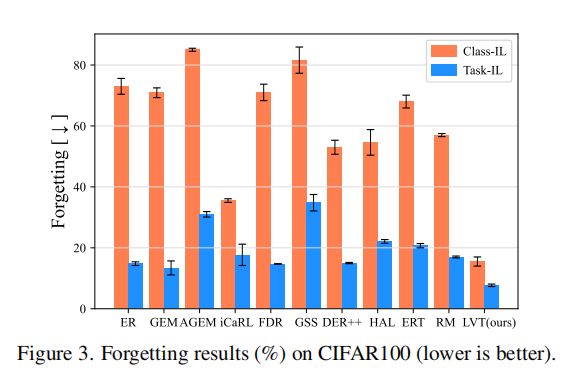
Forgetting:为了比较预防遗忘能力,我们评估了在后续任务中衡量性能下降的平均遗忘。图3显示,在内存大小为500的Class-IL和Task-IL设置中,LVT比所有其他方法遭受的遗忘都要少。这是因为LVT构建了一个任务间注意架构,并利用了注入和积累策略,从而提高了Vision Transformer网络的稳定性。
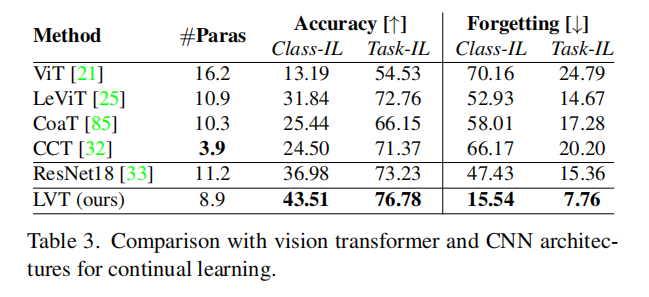
Comparison to Transformer and CNN Architectures:我们将LVT和SOTA Vision Transformers(ViT,LeViT ,CvT,和CCT)和CNN基准ResNet18 在ced持续学习排练策略下进行了比较。表3和图1的结果表明,ViT不胜任持续学习的任务,因为它是“数据饥饿”,只适合i.i.d.大型数据集。LeViT、CvT和CCT包含CNN结构来获得归纳偏差,这提高了通用性但在不断的学习中仍然遭受着灾难性的遗忘。直接使用Vision Transformers进行持续学习甚至不如ResNet的性能好。只有LVT利用具有更少参数的Transformer的优势来获得更好的持续学习性能,这得益于任务间注意机制和双分类器结构.
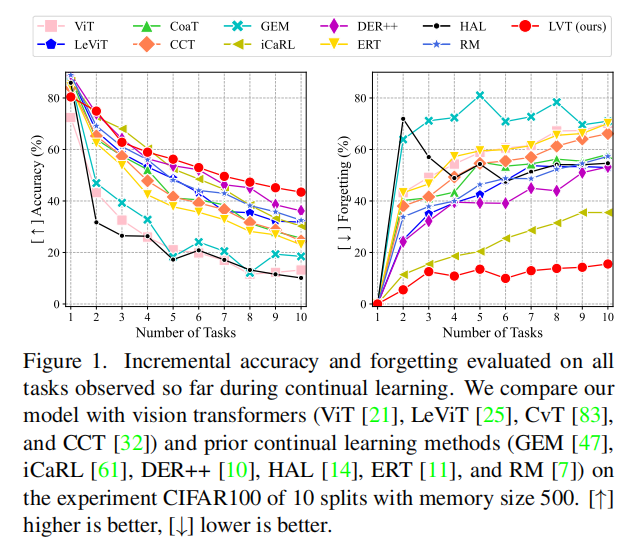
Incremental Performance: 我们演示了Class-IL设置下的平均增量性能,这是对完成每个任务后迄今为止观察到的所有任务进行评估的结果。如图1和图4所示,大多数方法的性能会随着新任务的到来而迅速下降,而我们的方法在准确性和遗忘方面的每一步都始终优于最先进的方法。
4.3. Ablation Study and Analysis
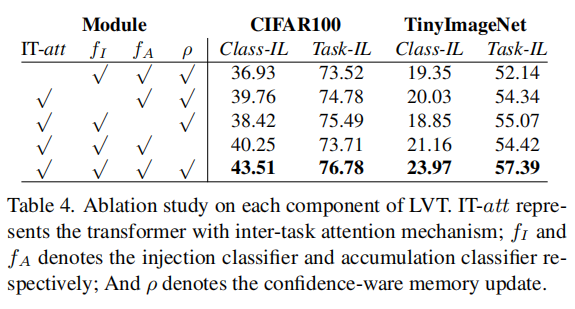
Effect of Each Component: 表4显示了LVT各组件对具有500个内存的CIFAR100和TinyImageNet的影响。我们可以看到,通过使用具有任务间注意的Transformer块,CIFAR100的平均精度从36.93%显著提高到43.51%。双分类器结构在class-il类设置中获得了5.09%的增益。利用TinyImageNet上的置信度软件内存更新策略,进一步提高了模型的性能,提高了2.97%
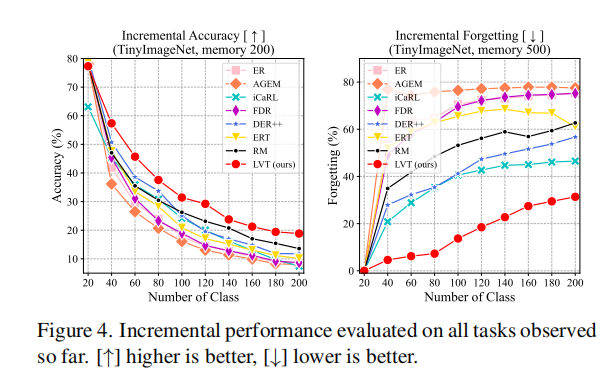
Sensitive Analysis on Memory Size: 我们评估了该方法在各种内存能力上的有效性。图5a显示,在CIFAR100上,LVT在不同内存容量下的性能始终优于其他方法。我们还注意到,小内存对LVT的改进变得更加显著,这说明我们的方法可以更好地适应具有有限时的真实情况。
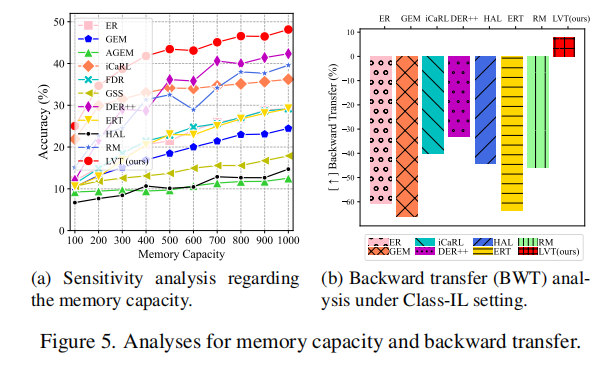
Backward Transfer (BWT) Analysis :BWT是学习任务对之前任务表现的影响,由BWT的定义,其中a(T,t)是模型完成学习任务TT时对任务Tt的测试准确性。我们分析了CIFAR100对1000内存分割的不同方法的BWT。如图5b所示,其他方法在Class-IL设置中存在较大的负BWT,这意味着严重的遗忘。相比之下,我们的方法甚至达到了正的BWT,这意味着学习新任务可能有助于之前任务的表现。这一结果进一步证明了该方法的优越性。
5. Conclusion
据我们所知,本文是文献中第一个设计一个持续学习的vision Transformers。所提出的Lifelong Vision Transformer(LVT)包含一种任务间注意机制和一种双分类器结构,可以巩固先前的知识,减轻对先前任务的遗忘。此外,我们开发了一种置信度感知的内存更新策略,以加深对之前任务的印象。大量的实验结果表明,我们的方法显著优于目前的最先进的方法与更少的参数。消融分析验证了建议组件的有效性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号