CONTINUAL LEARNING IN VISION TRANSFORMER--阅读笔记
CONTINUAL LEARNING IN VISION TRANSFORMER---阅读笔记
摘要:
持续学习的目标是从新数据中持续学习新任务,同时保留过去学习的任务的知识。最近,利用最初在计算机视觉自然语言处理中提出的Vsion Transformer,在图像识别任务中显示出比卷积神经网络(CNN)更高的精度。然而,很少有方法已经实现了持续学习的vision Transformer。在本文中,我们比较和改进了可以应用于CNN和Vision Transformer的持续学习方法。在我们的实验中,我们比较了几种连续学习方法及其组合,以显示其准确性和参数数量的差异。
一、介绍
在深度学习模型中,当多个任务按顺序给定时,先前学习到的任务会被新的任务覆盖并被遗忘。这被称为灾难性的遗忘。持续的学习通过从新的数据中不断地学习新的任务来处理灾难性的遗忘,同时保留先前学习过的任务的知识。
最近,Vision Transformer,利用了最初在计算机视觉的自然语言处理中提出的transformer架构,在图像识别任务中显示出了比CNN更高的精度。然而,传统的连续学习方法通常被认为是应用于CNN的卷积层,因此,可以应用于Vision Transformer 的所有组合层的方法是有限的。此外,没有任何方法被证明是有效的CNN和Vision Transformer。
因此,本文的目的是研究可以同时应用于CNN和Vision Transformer的方法,并可以在少量附加参数下抑制灾难性遗忘。通过比较每种方法的精度和额外参数的数量,我们检验了这些方法是否不仅对CNN有效,而且对Vision Transformer也有效。此外,我们的目标是提出一种结合传统方法,具有更高性能的方法。
二、相关工作
持续学习旨在平衡两种权衡:改变的刚性和适应的可塑性,以便学习新的数据,但过去的数据不会被忘记。Singh等人[6]提出了基于识别的知识保留(RKR),这是一种在持续学习中修改每个任务的网络权重和中间激活的方法。权值修改是通过将由一个称为整流生成器(RG)的生成器生成的参数添加到卷积层的权值中来完成的。中间激活通过将卷积层的输出乘以一个称为缩放因子生成器(SFG)的生成器生成的参数来修改。Piggyback[7]是一种高精度学习的方法,通过应用学习到的权重掩模来转换输出来学习大量任务的权重。RKR和Piggyback可应用于全连接层,也可应用于Vision Transformer。
Transformer首先被引入在自然语言处理的机器翻译中,现在是一种常用的方法。ViT 提出将像素块作为标记应用于计算机视觉。Swin Transformer是一种通过分层计算使用转换窗口来解决Transformer从语言到视觉的适应问题的方法。具体来说,他们处理了视觉实体规模的巨大变化,以及图像中的像素比文本中的单词的高分辨率。本文利用ViT和Swin Transformer验证了连续学习方法在 Vision Transformer 中的性能。
最近,人们提出了几种针对Vision Transformer的连续学习方法。DyTox 是一种方法,其中初始层由所有任务共享,并且特定于任务的标记用于生成特定于任务的嵌入。提示学习持续学习(L2P)[10]是一种受提示学习[11]启发的方法,这是自然语言处理领域的一种新的连续学习方法。这些方法不适用于CNN,因为它们是专门的Vision Transformer。此外,这些方法都是类增量学习的方法,这与本文提出的任务增量学习方法的目的不同。
三、方法
在本文中,我们提出了一个适用于CNN和Vision Transformer的持续学习方法的比较研究,即RKR [6]和Piggyback[7]。此外,我们提出了一种新的方法,Mask-RKR,它是这两种方法的结合。通过将Piggyback[7]应用于基础RKR [6],Mask-RKR保留了RKR的特性,同时由于任务数量的增加而减少了额外参数的数量。
3.1 通过RKR来适应任务
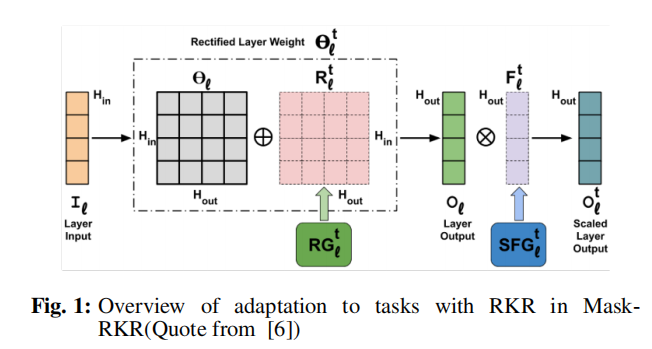
在Mask-RKR中,RKR应用于除最终输出层外的视觉变压器的所有全连接层。对于每一层,权重被RG修改,中间激活被SFG修改。RG对权值的修正如式(1)所示:
SFG网络生成F,用于对featuremap进行相乘矫正 如式(3)所示:
3.2 通过Piggyback来减少参数
Piggyback方法是一种通过将学习到的权重掩模应用到基础模型的权值来转换输出的方法。Mask-RKR不直接应用于权重,而是RKR的参数。具体地说,它被应用于RKR的两个低秩近似参数LM和RM以及SFG的F。
掩模学习是通过保持一组实值权值,将它们通过确定性阈值函数获得二进制掩模,并将其应用于现有权值来实现的。通过利用反向传播对重值权值进行更新,学习了一个适合于该任务的二进制掩码。通过为每个任务学习不同的二进制掩码,并将它们逐元素应用于RG和SFG参数,相同的基本网络可以以最少的附加参数重用于多个任务。
Mask-RKR RG中掩模学习过程如图2a所示。
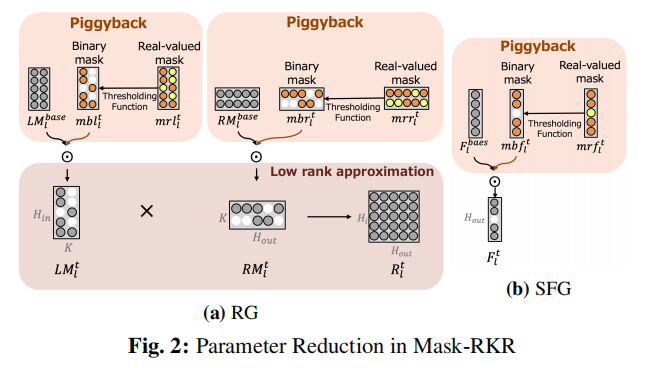
每个实值掩模通过式(4)中给出的硬二值阈值函数:
利用阈值过程生成的二进制掩模,将任务t中式(2)表示的权值的修改替换为式(5)。这里,⊙表示每个元素的点积或掩码:
接下来,MaskRKR的SFG中的掩模学习过程如图2b所示。
四、实验
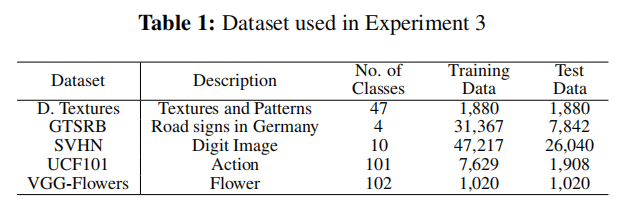
在实验1和消融实验中,我们使用了CIFAR-100,这是一个包含100类动物、植物、设备和车辆的数据集。为了在持续学习环境下进行实验,CIFAR-100被分为10个任务,每个任务有10个类。图像大小为32×32。我们使用了50000张图像作为训练数据和10000张图像作为测试数据。在实验2中,我们使用了ImageNet-1k,这是一个包含1000个类的大型数据集。为了在持续学习的环境中运行实验,我们将ImageNet-1k分为10个任务,每个任务有100个类。图像大小为224×224。我们使用了1,232,167张图像作为训练数据,而49,000张图像作为测试数据。在实验3中,我们使用了来自视觉十项全能(VD)基准测试[12]的5个不同领域的数据集。VD基准测试是一个评估同时解决10个不同视觉域的能力的基准测试。所使用的数据集如表1所示。
五、结论
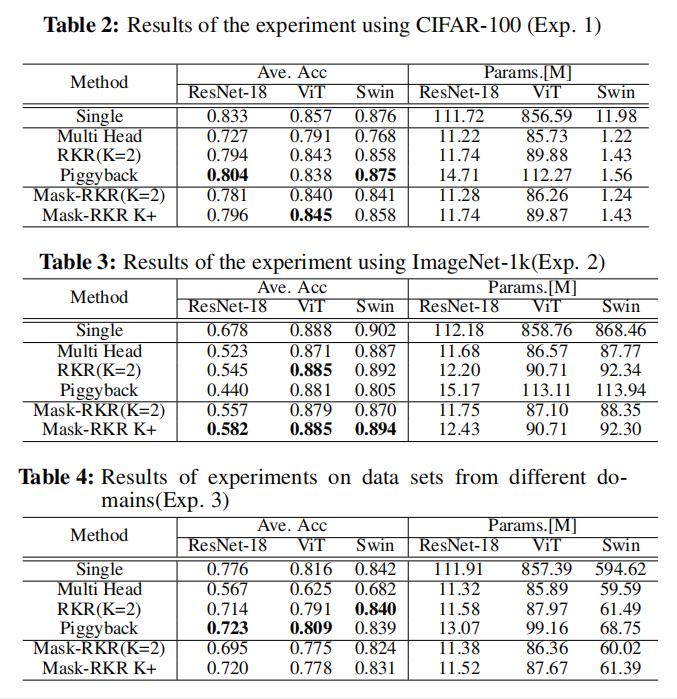
在本文中,我们比较了可以同时适用于CNN和Vision Transformer的持续学习方法。我们还提出了Mask-RKR,它结合了RKR [6]和Piggyback。从实验中,我们发现Mask-RKR在减少参数数量的同时,可以获得比原RKR和Piggyback更高的精度。然而,在不同领域的连续学习设置中,Piggyback显示出最高的准确性,当参数的数量不受限制时更有效。在未来,我们希望改进Mask-RKR,使其足够灵活,可以使用来自不同领域的数据集来处理连续学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号