Continual Learning with Transformers for Image Classification---阅读笔记
Continual Learning with Transformers for Image Classification---阅读笔记
摘要:
阻止灾难性遗忘是一件很困难的事,一个最近的研究趋势是动态扩展参数可以有效的减少灾难性遗忘。但是这需要复杂的微调来平衡增长的的参数,且任务中的信息也很少共享。本文在计算机视觉领域验证了一个最近的解决方案ADA(Adaptive Distillation of Adapters)。该方案是使用pre-trained和Adapters在文本分类任务上发展起来的。该方法在不需要重新训练模型或者不会再增加参数的情况下会维持一个好的性能。
1、 介绍
目前有很多阻碍灾难性遗忘的方法,目前主要分为三类:
(1)replay-based methods : 当数据量很大时会导致内存开销很大
(2)regularization-based methods : 经常很难微调
(3)parameter isolation methods : 参数众多
受到在NLP领域Transformers的重大改进的启发,最近一些开创性的工作开始应用于CV方向。例如:Vision Transformer(ViT)表明了一个纯粹的Transformer直接应用到图像的分类上,并且性能很好。我们利用Vision Transformer来提高CL框架在实际应用程序中的易用性。
最近的一些工作将Transformer架构应用于图像数据集上的CL,但它们也需要排练内存或从头开始训练一个新的Transformer模型(不能与预训练的Transformer模型一起工作)。现有的方法似乎不适合许多实际CL应用的要求。我们发现Memory efficient continual learning for
neural text classification 的工作是一个很有前途的方法,因为它不需要重新训练模型,也不存储旧的任务数据,随着任务数量的增长,保持有限的内存和资源消耗(例如常数数量的参数),并且可以使用预训练的Transformer模型。但是这个方法是否可以应用于图像领域是一个未知的问题。
我们在CIFAR100和MiniImageNet上测试了自适应适配器蒸馏(ADA)的效率。我们的主要贡献是:
1)在连续图像分类任务中首次使用Adapters 方法与Vision Transformer一起使用
2)验证Adapters 与Vision Transformer一起工作,并表明Adapters 的自适应提取(ADA)可以实现与占用内存的方法(如AdapterFusion)相当的预测性能,
3)通过使用Transformer架构使用CL方法(如弹性权重巩固(EWC)和经验重播放(ER)添加基准。
2、 问题设置
每个任务代表一个不同的分类问题,learner为每个任务创建一个新的分类头。
learner的目标是学习一系列的参数使得
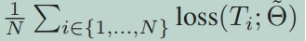
最小化。
3、 ADA 算法
ADA分为两步执行:第一步是使用新任务Ti的训练数据集Di(称为新模型)训练适配器模型和新分类器;第二步是巩固旧模型、前一轮获得的模型和新模型。
Adapters
适配器在所有任务中共享大量参数Θ,并引入少量特定于任务的参数Φi。目前关于适配器的工作侧重于为每个任务分别培训适配器。对于N个任务中的每一个,模型都使用预先训练的模型Θ的参数进行初始化。参数Θ是固定的,只有参数Φi是经过训练的。这使得训练所有N个任务的适配器成为可能,并将相应的知识存储在模型的指定部分。每个任务的目标是:
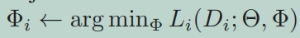
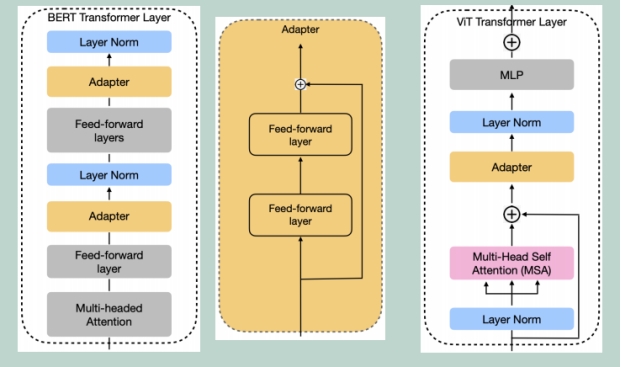
在这项工作中,我们为Vision Transformer定义和使用Adapters ,虽然这提供了良好的预测性能,但在CL设置中,新任务被顺序添加,并存储了一组大型适配器Φ1;:::;ΦN实际上是不可行的。与AdapterBERT一样,我们在ViT和DeiT的每个Transformer层中插入一个2层全连接网络(参见上图)。DeiT是建立在ViT架构之上的,因此以同样的方式添加适配器。
Distillation of Adapters
对于每一个新的任务Ti,Adapters 参数Φi被添加到模型中,而预训练的模型参数Θ保持冻结。针对当前任务,只训练特定于任务的模型参数Φi和头部模型参数hi。这两个模型的蒸馏有以下目的:
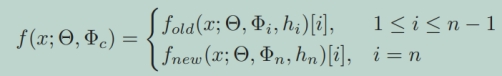
合并模型的输出近似于旧模型和新模型的模型输出的组合。在合并模型Φc的联合训练中,旧模型和新模型的输出作为监督信号。为此,他们使用提出的双重蒸馏损失来训练一个新的适配器,该适配器与预先训练的模型一起使用,以对旧的和新学习的任务进行分类。蒸馏过程如下:
fold和fnew保持不变,对每个训练样本运行前馈传递,并收集两个模型的logits值。
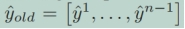
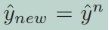
然后将合并模型生成的logits与现有两个专家模型基于L2-loss生成的logits组合之间的差值最小化:
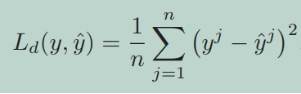
巩固的训练目标:
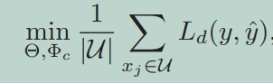
Transferability Estimation
ADA保留了一个适配器池,要提取的适配器的选择基于可移植性。这种选择背后的直觉是,高度相似的任务之间的相互干扰会减少,因此会显著减少遗忘。
两种常用的可转移性估计方法:
(1)Log Expected Empirical Prediction (LEEP)
(2)TransRate
LEEP是一种度量(或分数),它可以告诉我们,在没有对目标数据集进行训练的情况下,迁移学习算法如何有效地将源模型Θs中学习到的知识转移到目标任务.
TransRate通过预训练模型提取的目标示例的特征与单次通过目标数据的标签之间的相互信息来衡量可移植性。
Algorithm
对于每一个新的任务,算法训练一个新的适配器和头部模型。如果适配器池还没有达到最大大小(由K控制),则将其添加到池中。如果池达到最大大小,算法将被迫选择池中已经存在的适配器之一,并将其与新训练的适配器一起提取。为了选择要提取的适配器,它会利用可转移性得分。一旦识别出池中可转移性得分最高的适配器(称为fold j *),它就会将该适配器和新训练的适配器合并为一个新的适配器,并替换池中现有的旧适配器。为了能够进行有效的预测,该算法还保留了一个映射(在映射m中),即池中的哪个适配器必须与每个特定于任务的头结合使用。

4、 Experiments
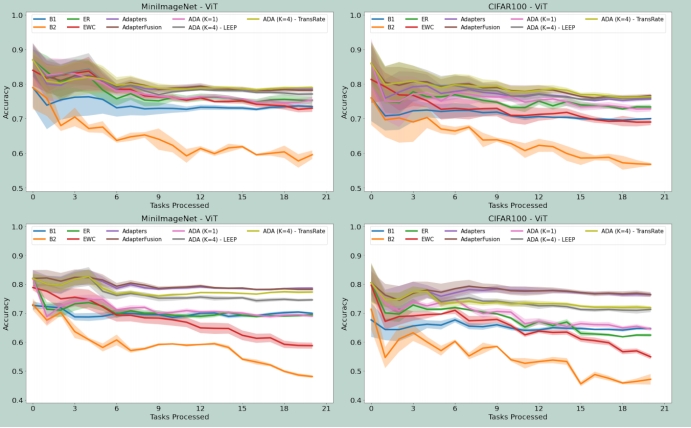
图2显示了ADA和基线方法的比较。可以清楚地看到,冻结所有预训练的模型参数,只微调头部模型(B1)导致与其他方法相比性能较差。B2只在前2-3个任务中表现良好,因为我们一直在训练完整的模型,所以它很快就会忘记之前学习的任务。当K=1时,ADA表明单独蒸馏并不能防止遗忘。K=4的适配器的ADA-LEEP和ADA-TransRate结果表明,适配器的选择性合并显著提高了性能。对于二元分类,其性能与AdapterFusion相当,但模型参数数量显著减少。对于多类来说,在完成一定数量的任务后,他们的表现会略有下降。
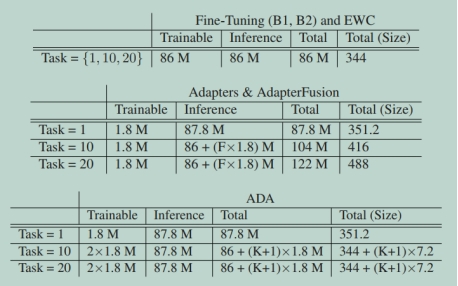
表1表明了我们实验中用于基线和ADA的参数数量。我们没有将头大小添加到表中,因为它非常小:每个二进制头有768个参数,20个任务有15K参数(6 KB),每个多类头有3840个参数,20个任务有75K参数(30KB)。所有的方法都是一样的。这些结果清楚地表明,ADA在内存使用方面的效率要高得多。它可以实现与Adapters和AdapterFusion类似的预测性能,同时需要的模型参数要少得多。ADA只存储5个适配器(K=4个适配器)。
5、总结
在这项工作中,我们展示了在连续CV问题中适配器与Transformer的结合使用。特别是,利用ad-hoc算法,如ADA,可以在常量参数增加的情况下,在预测性能方面给出强大的结果。众所周知,Vision Transformer倾向于过度拟合训练数据集,从而导致在小数据体系中的预测性能较差,然而刚刚表明,这一说法得到了很差的支持,解释了多头自关注的性质,并表明ViT即使在较小的数据集上也不会过拟合。这项工作对未来的视觉变压器CV研究是鼓舞人心的,该领域的任何发展都将对Transformer CL研究产生积极影响。
我们的研究结果中有一些方面是我们希望在未来进一步研究的。例如,在这项工作中,我们在NLP领域采用了相同的适配器结构杠杆,虽然这给出了良好的结果,但有可能这是一个次优选择。同样,我们用固定数量的适配器测试了ada,但很容易观察到适配器的数量可以由算法本身控制,例如利用基于LEEP或TransRate分数阈值的启发式。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人