第四次实践作业
一.使用Docker-compose实现Tomcat+Nginx负载均衡
要求:
- 理解nginx反向代理原理;
- nginx代理tomcat集群,代理2个以上tomcat;
- 了解nginx的负载均衡策略,并至少实现nginx的2种负载均衡策略;
参考资料:
1.理解nginx反向代理原理
关于代理
说到代理,首先我们要明确一个概念,所谓代理就是一个代表、一个渠道;此时就设计到两个角色,一个是被代理角色,一个是目标角色,被代理角色通过这个代理访问目标角色完成一些任务的过程称为代理操作过程;如同生活中的专卖店~客人到adidas专卖店买了一双鞋,这个专卖店就是代理,被代理角色就是adidas厂家,目标角色就是用户。
正向代理
先看看正向代理,正向代理也是大家最常接触的到的代理模式,我们会从两个方面来说关于正向代理的处理模式,分别从软件方面和生活方面来解释一下什么叫正向代理。
在如今的网络环境下,我们如果由于技术需要要去访问国外的某些网站,此时你会发现位于国外的某网站我们通过浏览器是没有办法访问的,此时大家可能都会用一个操作FQ进行访问,FQ的方式主要是找到一个可以访问国外网站的代理服务器,我们将请求发送给代理服务器,代理服务器去访问国外的网站,然后将访问到的数据传递给我们!
上述这样的代理模式称为正向代理,正向代理最大的特点是客户端非常明确要访问的服务器地址;服务器只清楚请求来自哪个代理服务器,而不清楚来自哪个具体的客户端;正向代理模式屏蔽或者隐藏了真实客户端信息。
反向代理
明白了什么是正向代理,我们继续看关于反向代理的处理方式,举例如我大天朝的某宝网站,每天同时连接到网站的访问人数已经爆表,单个服务器远远不能满足人民日益增长的购买欲望了,此时就出现了一个大家耳熟能详的名词:分布式部署;也就是通过部署多台服务器来解决访问人数限制的问题;某宝网站中大部分功能也是直接使用nginx进行反向代理实现的,并且通过封装nginx和其他的组件之后起了个高大上的名字:Tengine。那么反向代理具体是通过什么样的方式实现的分布式的集群操作呢,我们先看一个示意图:
通过上述的图解大家就可以看清楚了,多个客户端给服务器发送的请求,nginx服务器接收到之后,按照一定的规则分发给了后端的业务处理服务器进行处理了。此时~请求的来源也就是客户端是明确的,但是请求具体由哪台服务器处理的并不明确了,nginx扮演的就是一个反向代理角色
反向代理,主要用于服务器集群分布式部署的情况下,反向代理隐藏了服务器的信息!
2.nginx代理tomcat集群,代理2个以上tomcat
项目结构
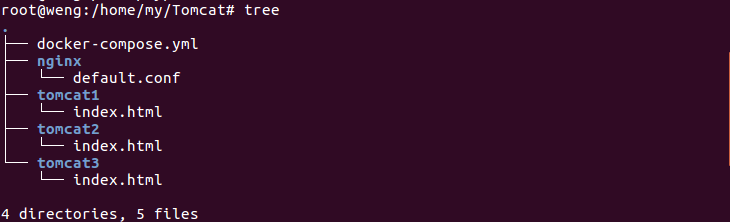
注:index.html用于显示登录到服务器上时页面显示的内容,用于区分不同的Tomcat
docker-compose.yml
version: "3"
services:
nginx:
image: nginx
container_name: ex4ngx
ports:
- "80:80"
volumes:
- ./nginx/default.conf:/etc/nginx/conf.d/default.conf # 挂载配置文件
depends_on:
- tomcat01
- tomcat02
- tomcat03
tomcat01:
image: tomcat
container_name: ex4tc1
volumes:
- ./tomcat1:/usr/local/tomcat/webapps/ROOT # 挂载web目录
tomcat02:
image: tomcat
container_name: ex4tc2
volumes:
- ./tomcat2:/usr/local/tomcat/webapps/ROOT
tomcat03:
image: tomcat
container_name: ex4tc3
volumes:
- ./tomcat3:/usr/local/tomcat/webapps/ROOT
nginx配置文件
upstream tomcats {
server ex4tc1:8080; # 主机名:端口号
server ex4tc2:8080; # tomcat默认端口号8080
server ex4tc3:8080; # 默认使用轮询策略
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://tomcats; # 请求转向tomcats
}
}
运行docker-compose up并登录到localhost查看配置是否正确
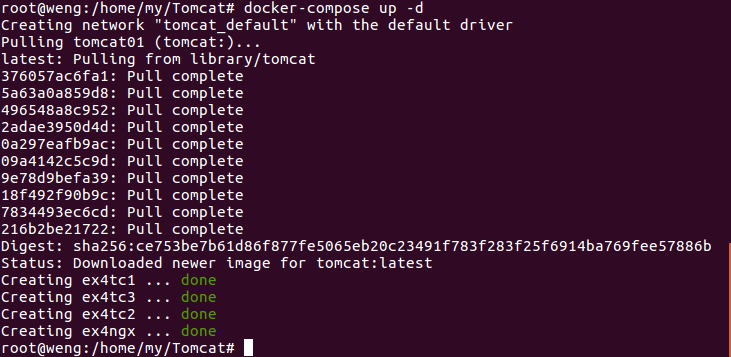
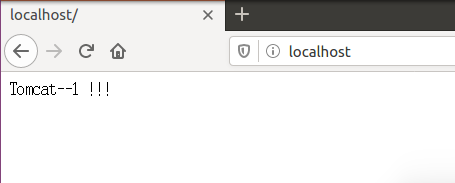
注:显示的内容为Tomcat1里面index.html的内容,说明配置没有问题 ,可以开始接下来的测试了。
3.了解nginx的负载均衡策略,并至少实现nginx的2种负载均衡策略
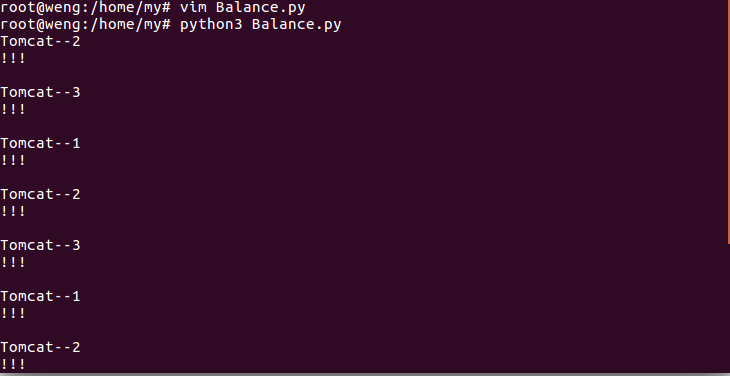
轮询策略
编写一个简单的python脚本用于测试负载均衡的轮询策略。
Balance.py
import requests
url="http://localhost"
for i in range(0,10):
reponse=requests.get(url)
print(reponse.text)
运行脚本并查看结果
权重策略
修改defaul.conf文件然后重启nginx
upstream tomcats {
server ex4tc1:8080 weight=5; # 主机名:端口号
server ex4tc2:8080 weight=3; # tomcat默认端口号8080
server ex4tc3:8080 weight=2; # 默认使用轮询策略
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://tomcats; # 请求转向tomcats
}
}

Balance1.py
import requests
url="http://localhost"
context={}
for i in range(0,100):
response=requests.get(url)
if response.text in context:
context[response.text]+=1
else:
context[response.text]=1
print(context)

注:可以看到在100次请求返回的结果中,Tomcat--1:Tomcat--2:Tomcat--3 = 5:3:2,与我们在nginx配置文件中的权重的比值是基本一致的(5:3:2)。
二.使用Docker-compose部署javaweb运行环境
要求:
- 分别构建tomcat、数据库等镜像服务;
- 成功部署Javaweb程序,包含简单的数据库操作;
- 为上述环境添加nginx反向代理服务,实现负载均衡。
参考资料:
注:该部分是用的老师给的那个项目,拿来跑一下看。
1.项目结构
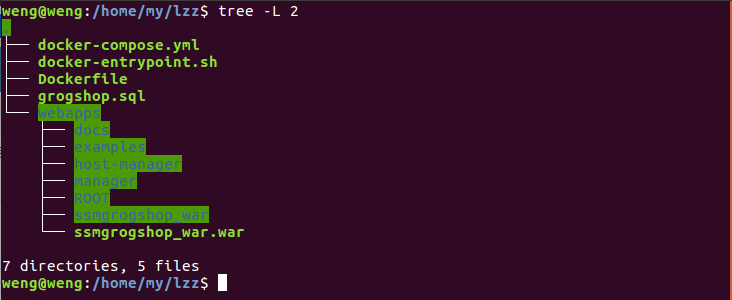
2.项目运行过程
将下载的压缩解压后,复制到虚拟机中。
进入项目对应的目录中
修改下面这个文件
将这个改为自己的IP地址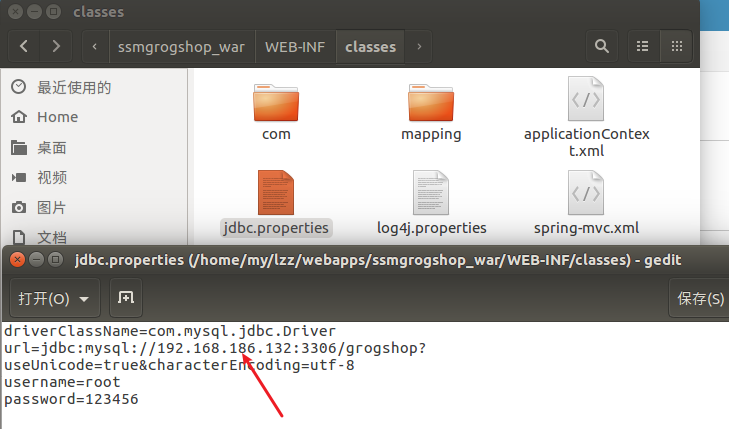
查看自己的IP地址

修改好IP地址,回到lzz目录,启动
启动好后到浏览器输入以下路径进行访问,密码:123。(注意:地址中的IP地址要用你自己的)
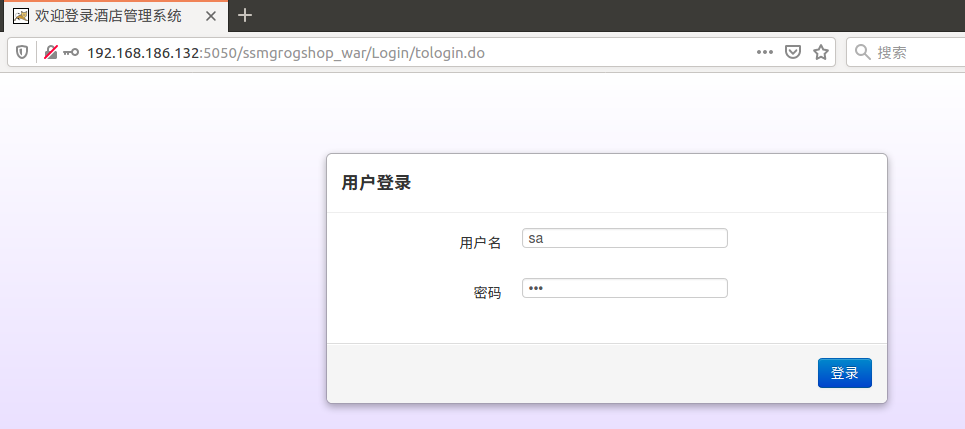
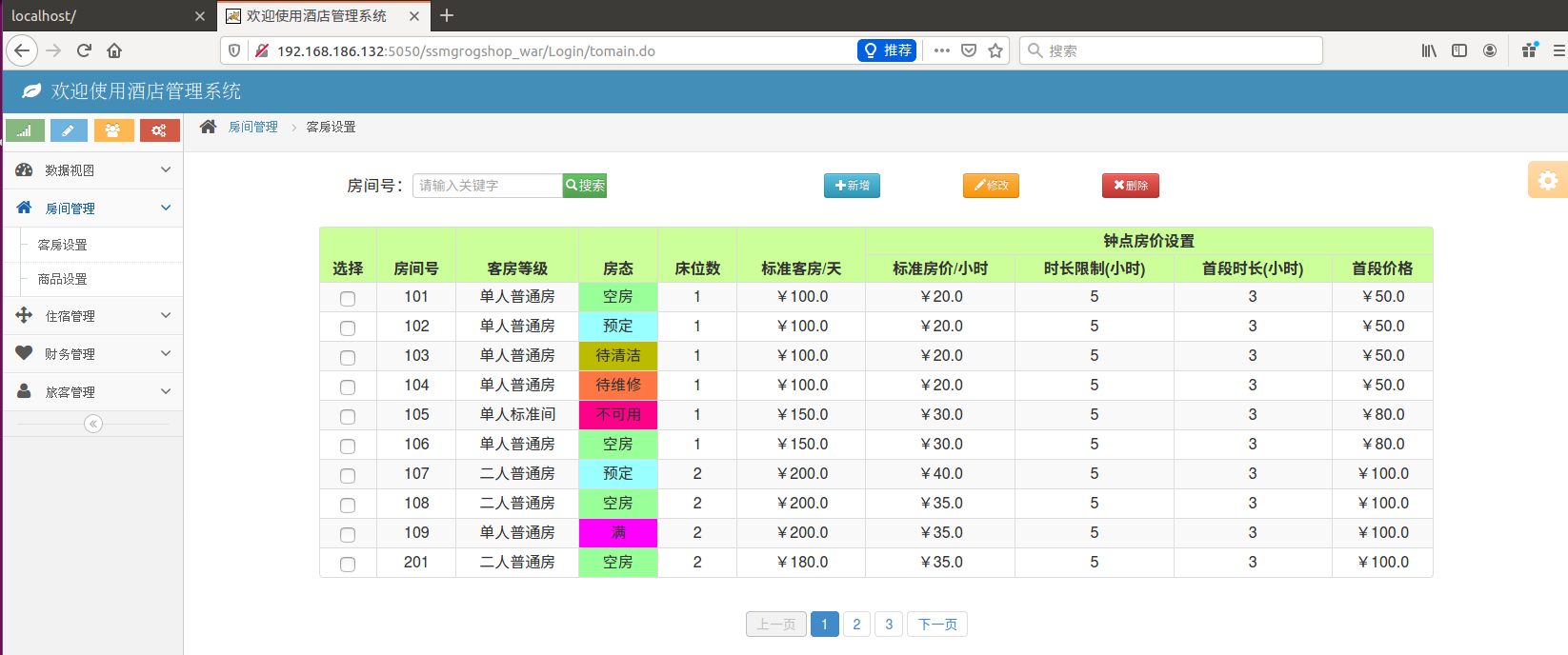
可以正常访问。

三.使用Docker搭建大数据集群环境
要求:
- 完成hadoop分布式集群环境配置,至少包含三个节点(一个master,两个slave);
- 成功运行hadoop 自带的测试实例。
参考资料:
1.在Docker安装Ubuntu系统
拉取Ubuntu镜像
查看

在个人文件下创建一个目录,用于向Docker内部的Ubuntu系统传输文件

在Docker上运行Ubuntu系统
2.Ubuntu系统初始化
更新系统软件源
apt-get update

安装vim
apt-get install vim

安装sshd
安装sshd:
apt-get install ssh

开启sshd服务器:
/etc/init.d/ssh start

设置每次登录Ubuntu系统时,都能自动启动sshd服务
vim ~/.bashrc
在该文件中最后一行添加如下内容:
/etc/init.d/ssh start

配置sshd
配置ssh无密码连接本地sshd服务:
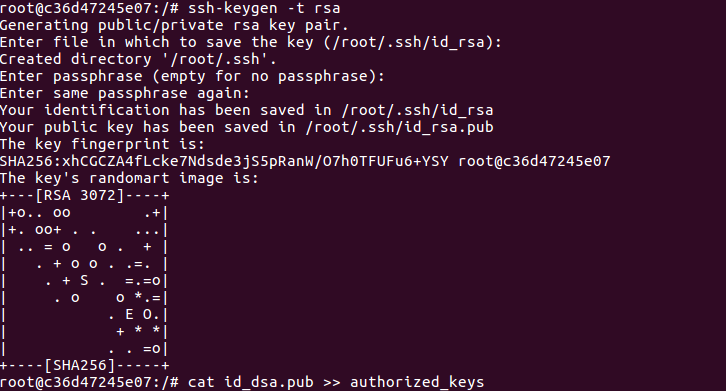
ssh-keygen -t rsa #一直按回车键即可
cat id_dsa.pub >> authorized_keys
安装JDK
因为Hadoop有用到Java,因此还需要安装JDK
apt-get install default-jdk

安装成功后,打开 ~/.bashrc 文件配置环境变量,在最后输入以下内容
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
export PATH=$PATH:$JAVA_HOME/bin
执行如下命令使 ~/.bashrc 生效
source ~/.bashrc

保存镜像文件
登录docker后,先查看当前Ubuntu镜像ID
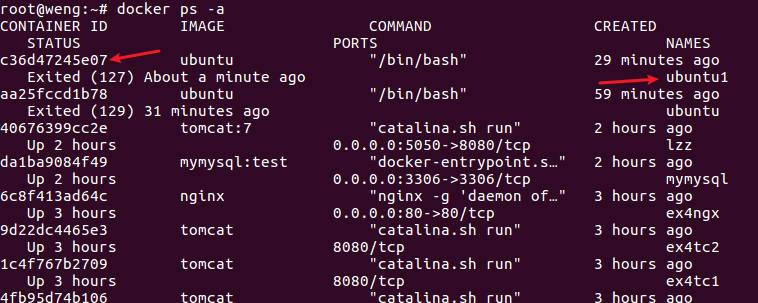
然后保存当前镜像为ubuntu/jdkinstalled,表示jdk安装成功的ubuntu版本
docker commit c36d47245e07 ubuntu/jdkinstalled

查看保存是否成功
docker images
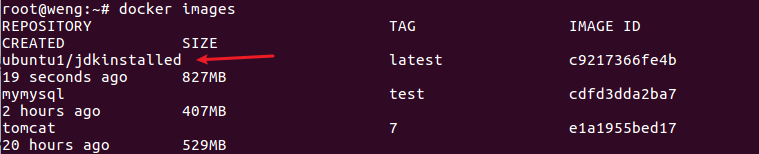
可见保存成功了
3.安装Hadoop
开启上一步保存的那份镜像ubuntu1/jdkinstalled
docker run -it -v /home/hadoop/build:/root/build --name ubuntu-jdkinstalled ubuntu1/jdkinstalled
将预先下载好的压缩包放到创建的目录(容器宿主机共享目录)下以便后续安装
cd /root/build
tar -zxvf hadoop-3.1.3.tar.gz -C /usr/local
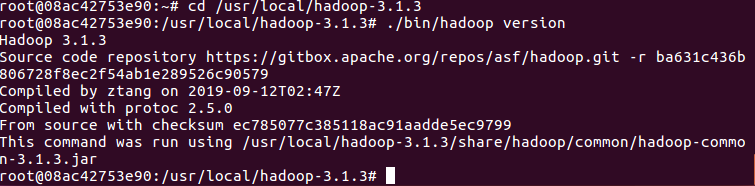
cd /usr/local/hadoop-3.1.3
./bin/hadoop version # 验证安装
4.配置Hadoop集群
文件配置
hadoop-env.sh
cd /usr/local/hadoop-3.1.3/etc/hadoop #进入配置文件存放目录
vim hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/ # 在任意位置添加

core-site.xml
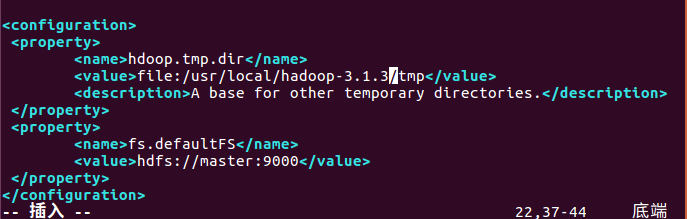
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-3.1.3/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-3.1.3/tmp/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/usr/local/hadoop-3.1.3/tmp/dfs/data</value>
</property>
</configuration>

mapred-site.xml
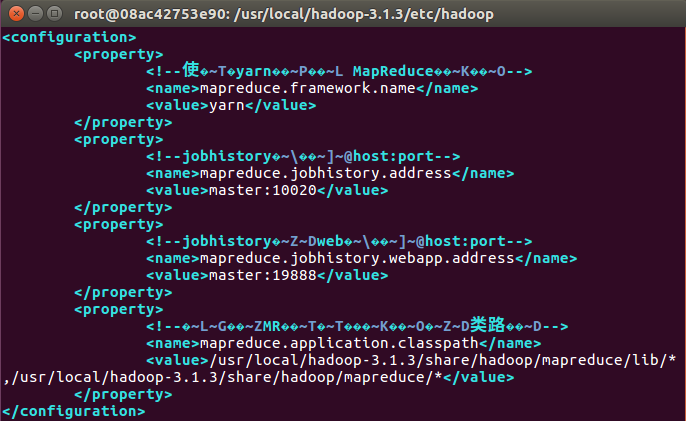
<configuration>
<property>
<!--使用yarn运行MapReduce程序-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<!--jobhistory地址host:port-->
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<!--jobhistory的web地址host:port-->
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<!--指定MR应用程序的类路径-->
<name>mapreduce.application.classpath</name>
<value>/usr/local/hadoop-3.1.3/share/hadoop/mapreduce/lib/*,/usr/local/hadoop-3.1.3/share/hadoop/mapreduce/*</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.5</value>
</property>
</configuration>

修改脚本
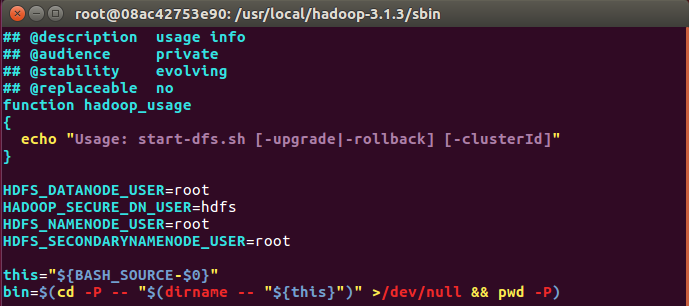
对于start-dfs.sh和stop-dfs.sh文件,添加下列参数
cd /usr/local/hadoop-3.1.3/sbin
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
start-dfs.sh
stop-dfs.sh
对于start-yarn.sh和stop-yarn.sh,添加下列参数
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
start-yarn.sh
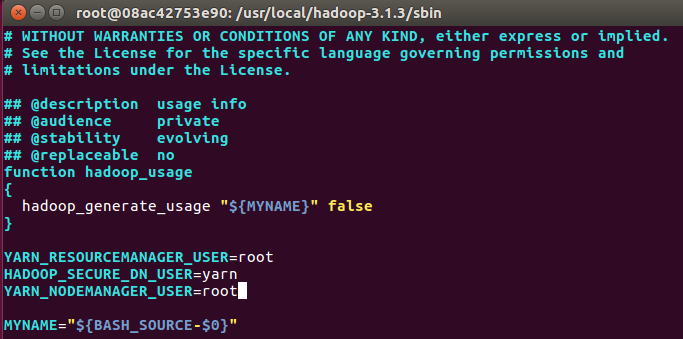
stop-yarn.sh
在容器中运行三个集群
保存镜像
docker commit 08ac42753e90 ubuntu2/hadoopinstalled

在三个终端上开启三个容器运行ubuntu2/hadoopinstalled镜像
# 第一个终端
docker run -it -h master --name master ubuntu2/hadoopinstalled
# 第二个终端
docker run -it -h slave01 --name slave01 ubuntu2/hadoopinstalled
# 第三个终端
docker run -it -h slave02 --name slave02 ubuntu2/hadoopinstalled
master

slave01

slave02

配置master,slave01和slave02的地址信息,这样他们才能找到彼此。分别打开/etc/hosts可以查看本机的ip和主机名信息,最后得到三个ip和主机地址信息如下
172.17.0.3 master
172.17.0.4 slave1
172.17.0.5 slave2
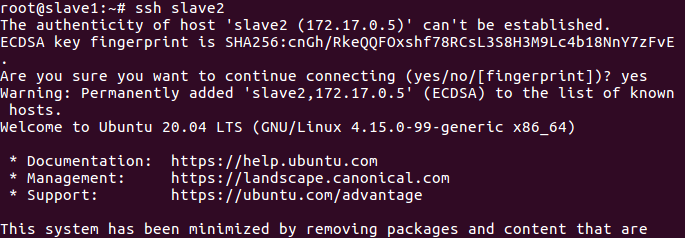
在master结点测试ssh;连接到slave结点
ssh slave1
ssh slave2
exit 退出


打开master上的slaves文件,输入两个slave的主机名
vim /usr/local/hadoop-3.1.3/etc/hadoop/workers
slave1
slave2
启动Hadoop集群
cd /usr/local/hadoop-3.1.3
bin/hdfs namenode -format #首次启动Hadoop需要格式化
sbin/start-all.sh #启动所有服务

使用jps查看三个终端



5.运行Hadoop实例程序grep
创建目录
建立HDFS文件夹
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/root #注意input文件夹是在root目录下
bin/hdfs dfs -mkdir /user/root/input


拷贝文件
然后将/usr/local/hadoop/etc/hadoop/目录下的所有文件拷贝到hdfs上的目录
查看是否拷贝到对应目录

执行实例
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep /user/hadoop/input output 'dfs[a-z.]+'
在hdfs上的output目录下查看到运行结果
./bin/hdfs dfs -cat output/*

停止所有服务
sbin/stop-all.sh

四.问题反馈
实验中零零碎碎遇到很多问题,问题比较琐碎,一一记录下来太麻烦了,说一下印象比较深的几个问题。首先是由于之前做过大数据的实验,虚拟机上已经安装过Hadoop了,所以在docker上跑Hadoop时有时候会忘记进入容器去操作Hadoop,结果也都一样,但是后面的实验就受到了影响,所以只能返工再做,这个地方没有仔细看浪费一些时间。
还有就是在设置ssh免密登录时,在第一个镜像上设置失败了,就没去管便继续做了下去,后面做主从节点测试时,登录到从节点时,需要手动确认。但是一开始我看它需要手动确认还以为报错了,便又重新去配了ssh,然后再提交镜像,设置节点什么的又搞了一遍,浪费了不少时间。
五.实验总结
这次实验明显比较难,量也比较大。前前后后花了两天,第一天做的时候遇到了一些问题,搞了半天都没解决,果断不做了。第二天继续做,心态比较好,思路清晰了,一个一个问题慢慢解决,做着做着就做完了。时间估计用了十几个小时,反正就是做的很累。
但是收获还是很大的,由于在大数据做过Hadoop的搭建,做这部分的时候就比较熟悉了,少了茫然。所以一方面熟悉了docker的操作,一方面又重温了大数据所学的知识。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号