glibc中的源码该怎么读
写在前面:
在PWN的学习过程中,阅读glibc的源代码是一项必备的技能。一方面而言有些问题需要深入到源码中寻找答案,另一方面阅读源码来探究glibc中函数的实现是再合适不过的方法(有很多师傅做了优秀的总结,可不论怎么阅读他人的总结还是不如自己去实际的探究一下),最后一方面,在不断探究和学习源码的过程中其实也在不断的进步并打下基础,如此看来阅读glibc中的源码百利而无一害。但我对于第一次尝试阅读源码的印象颇深,无从下手,不知所措。于是乎我写下了这篇文章,来向当初和我一样入门的师傅们提供一些经验和建议。
由于本人水平有限,提供的思路和建议未必是最好的,但应该是当下在我的认知中对我而言是最合适的了。如果有错误或更方便的做法,师傅们也可以提出来。
1、准备环境&工具&源码
我们需要先把环境和工具准备好,这个其实很好搞。
我们需要去搞一下gdb源码调试的这个功能,尤其是在初学的时候,源码基本每行都看不懂(至少当时我是这样hhh),那就必须要配合着gdb动态调试看源码了,这样我们可以去看一些变量的值,以及程序的走向又或者函数的调用关系等等。对于最初的萌新来说,这样就舒服很多了。
如何搭建gdb源码调试的环境可以看我的这篇文章 here
其次就是工具,工具的话建议选择vscode,这个具体咋搞就百度吧。
最后源码在这里下载
https://launchpad.net/ubuntu/+source/glibc/
里面有很多个版本的glibc,如果没有特殊需要的话最好下载2.23-0ubuntu3这个版本。
最后打开vscode,将刚才下载的glibc的文件打开(说实话正常的话下面两张图片没必要放,因为现在在我看来这些步骤应该是理所当然,但我初学的时候其实连这个都不知道,也算是给曾经的自己看一下吧)
glibc中的文件有很多,选择我们需要分析的那个函数所在的文件夹即可。比如我要分析fopen函数,那就打开这个libio这个文件(想知道函数在哪个文件夹的话,百度一下即可)
2、vscode的一些快捷键
要说分析源码,不得不提的就是一些快捷键。使用快捷键和不使用快捷键的效率简直天差地别。
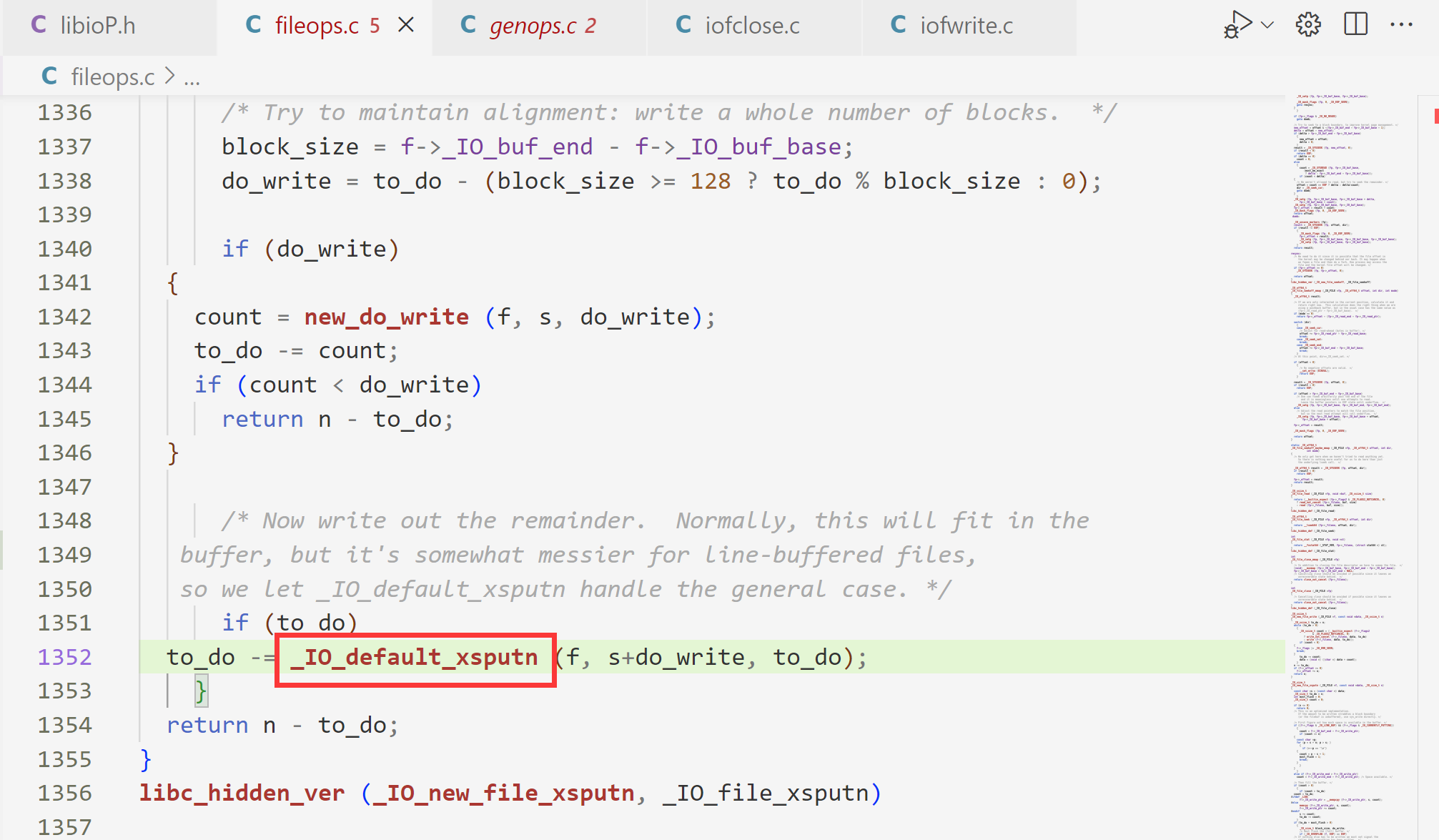
假设我现在在分析代码的1352行,这里出现了_IO_default_xsputn函数,如果我们要查看该函数定义的地方的话,ctrl+左键点击该函数,即可跳转到定义的地方。(如下图)
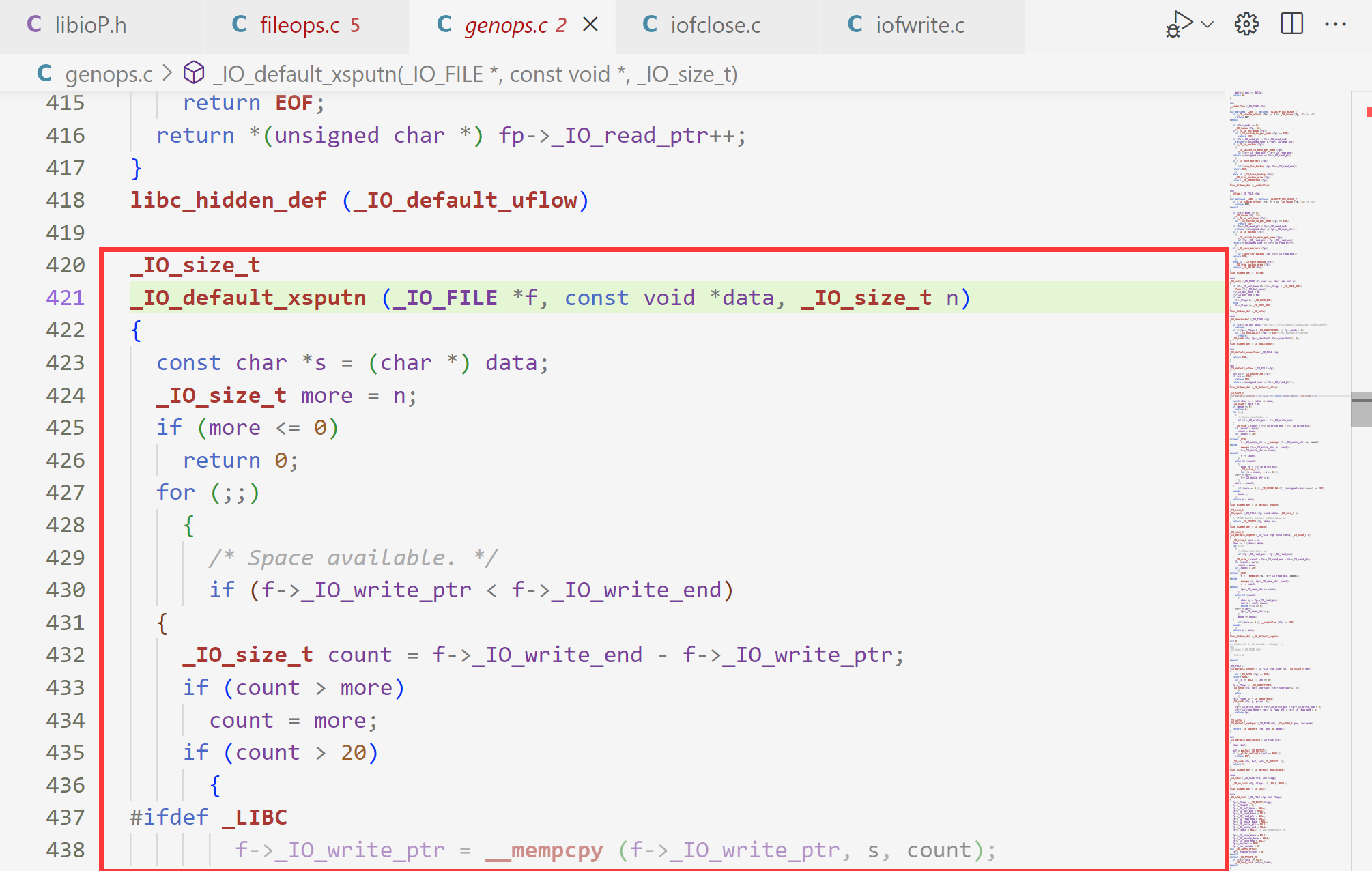
下图是我们已经跳转到函数定义的地方了,但是有一个很难受的事情就是,如果我们想回去刚才的代码继续分析还要手动再找回去么? 我们可以使用快捷键Alt加<-键(这个<-键就是键盘里那个上下左右键的左)返回到刚刚的代码,同理Alt加->键可以再回到函数定义的地方。
ctrl+f是在当前文件搜索指定的内容
ctrl+z就是撤回刚刚的一步操作
3、宏&如何溯源解决问题
在glibc源码分析中,宏定义十分常见(如果不知道什么是宏可以百度一下)
有可能你眼前这个陌生的东西就是个宏。(初学的时候,我看源码一脸懵,心想咋这么多东西我都没见过,我学的假的c语言么?)
以下面432这行代码为例:
发现上来就是一个_IO_size_t干懵萌新,因为之前没见过啊。

我们ctrl+左键溯源一下这个_IO_size_t(如下图),发现是个宏定义,不过size_t还是没见过呀,那就继续溯源

发现最终是typedef给unsigned __int64新定义了一个名字叫做size_t(不清楚typedef的请自行百度)

这下子unsigned int64我们认识了,这不就是无符号整形变量么,ok问题解决,最初的那行代码其实就是unsigned int64 count 定义了count这个变量,仅此而已。
下面放一个我初学时的问题,下面这个结构体Elf32_Sym为什么是16字节?(我在这里并不是想表达这个结构体是多大,我是想强调我们在面对不会的问题的时候,解决的思路应该如何)
typedef struct
{
Elf32_Word st_name; /* Symbol name (string tbl index) */
Elf32_Addr st_value; /* Symbol value */
Elf32_Word st_size; /* Symbol size */
unsigned char st_info; /* Symbol type and binding */
unsigned char st_other; /* Symbol visibility */
Elf32_Section st_shndx; /* Section index */
} Elf32_Sym;
这似乎是在定义变量? 可是没听过Elf32_Word是个变量类型啊。
鼠标右键一下(我当时用的是VisualStudio ,发现是有个转到定义的,就说明这个Elf32_Word也是个被定义的东西
到定义那里看一下发现了typedef这个东西和uint32_t,奈何c的基础不牢,google一下。

发现了这个东西其实就是类似于提供了一个自定义类型的功能,举个例子,typedef unsigned int ai;
那么此时的ai就相当于unsigned int这个东西了,因此比如我们想定义一个unsigned int类型的变量b,就可以写成这样了,ai b;此时的效果是和unsigned int b;效果是一样的
那么这个uint32_t又是什么呢?继续google。
发现了这个uint32_t的这个_t的意思是这些数据类型(指的是uint32_t,而并非Elf32_Word)是通过typedef来定义的,而不是新的数据类型。也就是说,他们其实是我们已知的类型的别名。
然后下面这些就是这些数据类型被定义的地方
# ifndef __int8_t_defined
# define __int8_t_defined
typedef signed char int8_t;
typedef short int int16_t;
typedef int int32_t;
# if __WORDSIZE == 64
typedef long int int64_t;
# else
__extension__
typedef long long int int64_t;
# endif
# endif
typedef unsigned char uint8_t;
typedef unsigned short int uint16_t;
# ifndef __uint32_t_defined
typedef unsigned int uint32_t;
# define __uint32_t_defined
# endif
# if __WORDSIZE == 64
typedef unsigned long int uint64_t;
# else
__extension__
typedef unsigned long long int uint64_t;
# endif
如此再回到这行代码 Elf32_Word st_name,其实它就等同于unsigned int st_name,此时应该就能够看懂了。
最后回到最开始的那个问题,为什么这个结构是16字节?
typedef struct
{
Elf32_Word st_name; /* Symbol name (string tbl index) */
Elf32_Addr st_value; /* Symbol value */
Elf32_Word st_size; /* Symbol size */
unsigned char st_info; /* Symbol type and binding */
unsigned char st_other; /* Symbol visibility */
Elf32_Section st_shndx; /* Section index */
} Elf32_Sym;
因为分别查看了定义类型发现Elf32_Word和Elf32_Addr都是unsigned int类型,这个类型是4个字节,而unsigned char是1个字节,而查看了Elf32_Section发现它是被uint16_t定义的,而uint16_t则是unsigned short int类型,为2个字节。因此整个结构体为16字节。
上面两个示例都提供了解决问题的基本思考方式,希望对师傅们有帮助
4、分析一个函数源码首先应该做的是什么?
我这里提供一个初学者最开始分析源码的一个思路。
以我最初分析fopen函数源码为例,首先肯定是要把vscode打开,确保自己手里有一份源码(而非只看某篇文章出现的源码),然后先用gdb去调试,这次调试看什么?对于初学者而言,第一次应该是啥都看不懂,那也要硬着头皮把整个函数的汇编指令都si给执行一遍(就最起码对整个函数调用的函数数量,哪些出现频率高的函数起码有个印象),然后第二次在把整个函数的汇编指令都si给执行一遍,这次去观察并记录期间调用的函数关系(最好是拿图画下来),看不懂函数关系也没事,但至少要去画一遍或者写一遍。(就如下图这样)
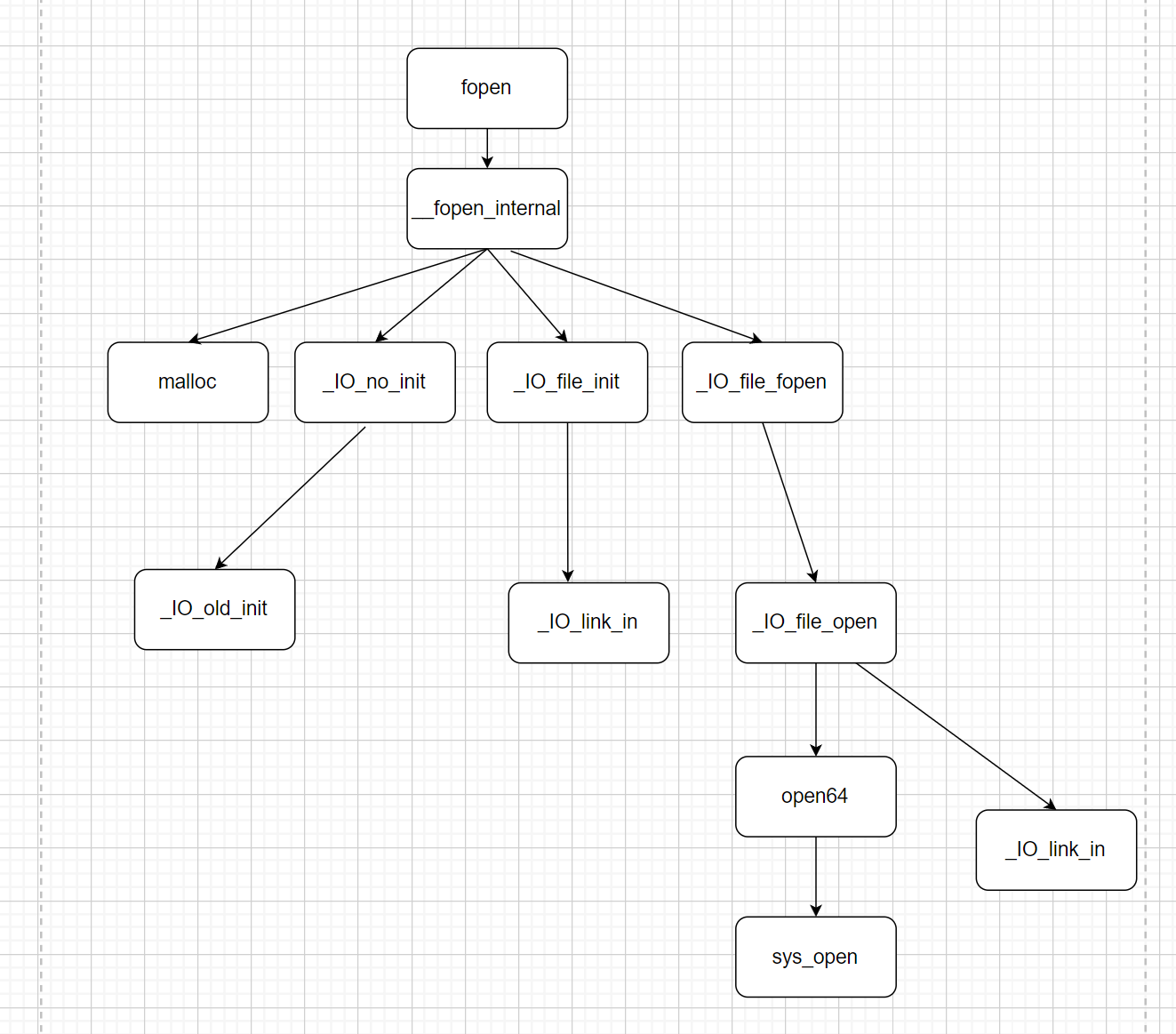
现在我们已经通过自己的调试有了一份“地图”,然后开始对着vscode源码开始从头分析。因为刚开始肯定有很多地方都不懂,那我们所谓的分析就会变的异常困难,我们可以先试着预测函数的走向以及执行后可能的结果。
举个最简单的例子:
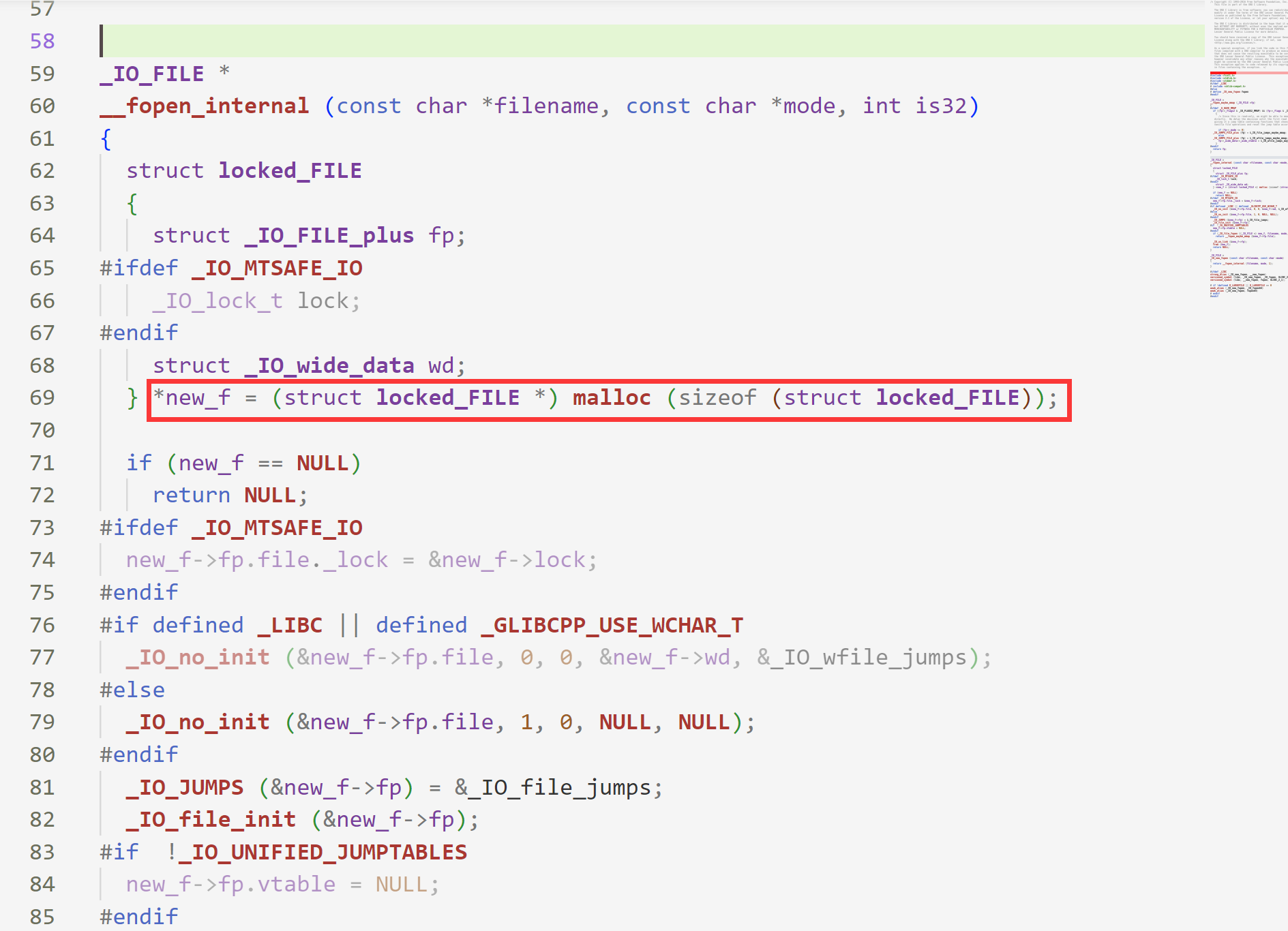
下面的代码就是fopen函数的最开始部分,发现在69行执行了malloc函数,那我们就可以猜测推断__fopen_internal函数就会调用malloc函数,而malloc申请的内存大小应该是locked_FILE结构体的大小,而返回的地址则给了new_f。(如下图)
因为是初学时的源码分析,我们并不能保证百分百是这样的,那我们就用动态调试来看看是不是这样的,发现动态调试到这里,确实执行到了这里。
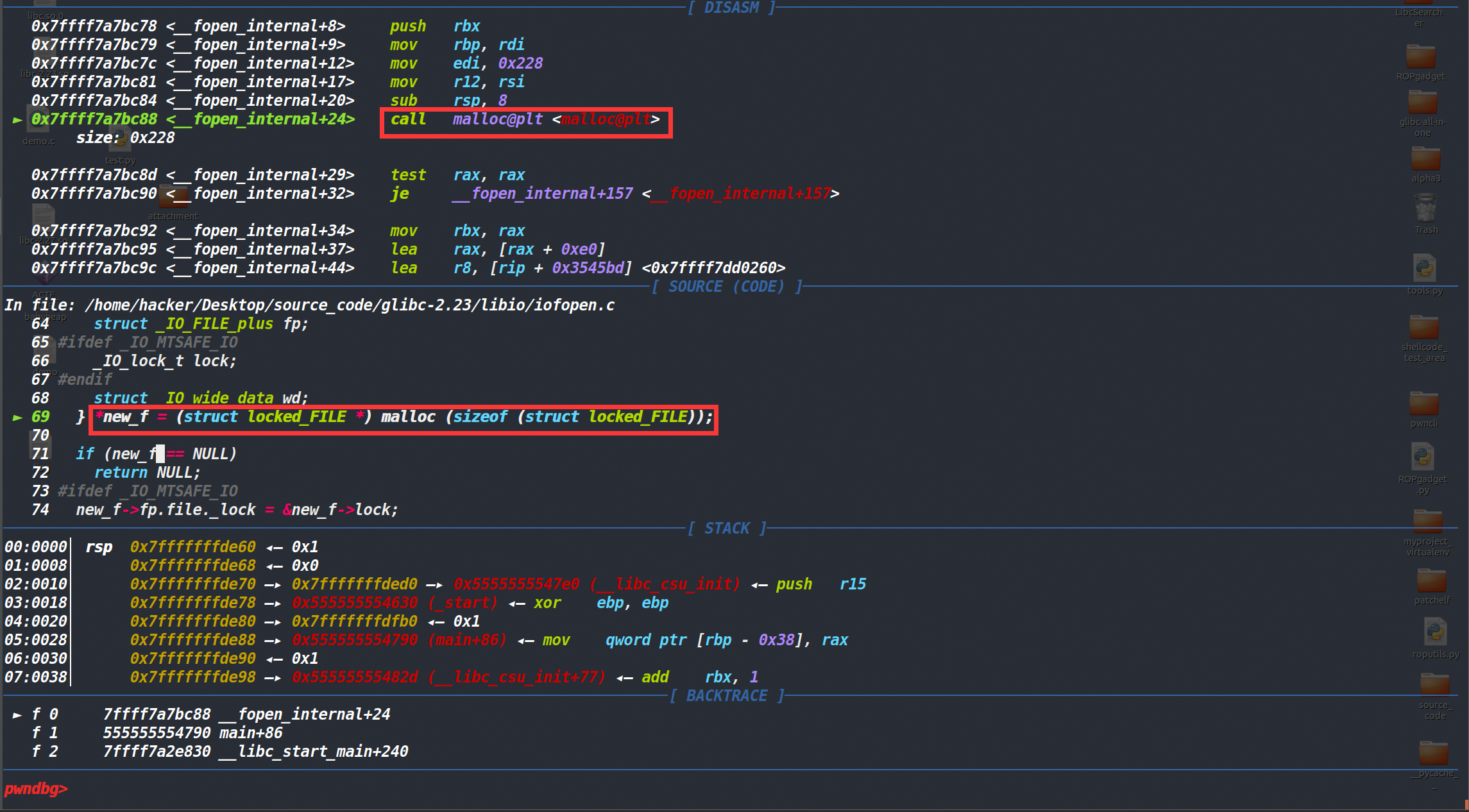
我们执行这行代码后再看下locked_FILE结构体的大小(如下),因此判断申请的堆块大小最终为0x231(0x220+0x10+0x1)

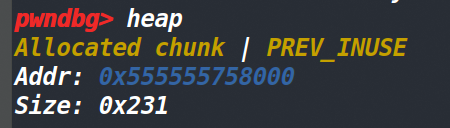
而new_f的值应该是malloc返回的堆块的用户区地址。(如下)
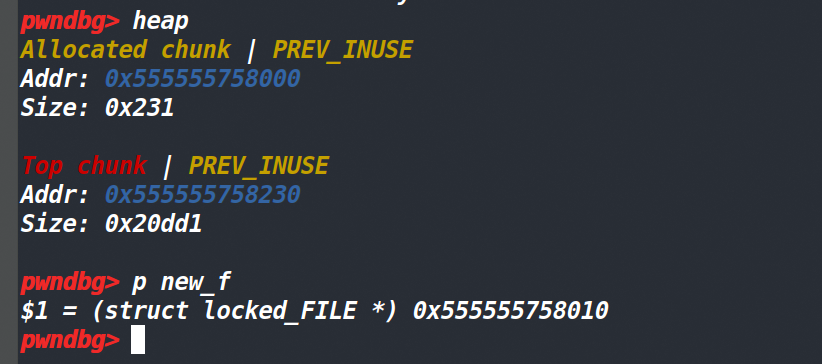
至此我们就完成了一次最简单的验证。
而之后的流程也大致如此,先看源码分析,如果源码看懂了那就配合动态调试看看是否是自己分析的那样,如果源码没看懂,就直接动态调试看看函数是怎么执行的。对于初学者而言刚开始可能会比较困难,可以去网上找一些师傅已经做过的源码分析来作为参考,这样遇到实在分析不懂的地方,就看看其他师傅是怎么分析的。
5、善于用搜索引擎
现在许多常见的问题其实很多都可以在师傅们的文章中找到答案,如果遇到自己不会的问题,可以尝试在百度或者google上搜索(如果有条件的话,最好还是用google)。
6、总结函数的调用流程
为了确保自己是真的熟悉了函数整个的调用流程,建议调试过之后,自己在不看源码的情况下,将函数的调用流程总结一遍。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号