用python写了一个检索题目信息(WP题目)与关键知识点的小工具
引言:一个工具之所以被开发出来,肯定是先有的需求,然后才去想办法开发。
这个程序能干什么?
这个程序可以帮你检索信息,你可以把你的WP的题目存上来,然后再针对这个题目存一些你这个WP里的相关知识点。当你做了一道新的题目,需要去重温一下之前某个WP上的知识点,这时候你就可以用这个工具来进行检索了。比如你输入以前存的某一个关键点,这个程序就可以去检索到,这个知识点相关的所有题目,你也可以继续去输入知识点,来精准的查找到你的某个WP,当检索到之后,这个程序还可以帮你把这个WP顺便给运行了。
程序效果如图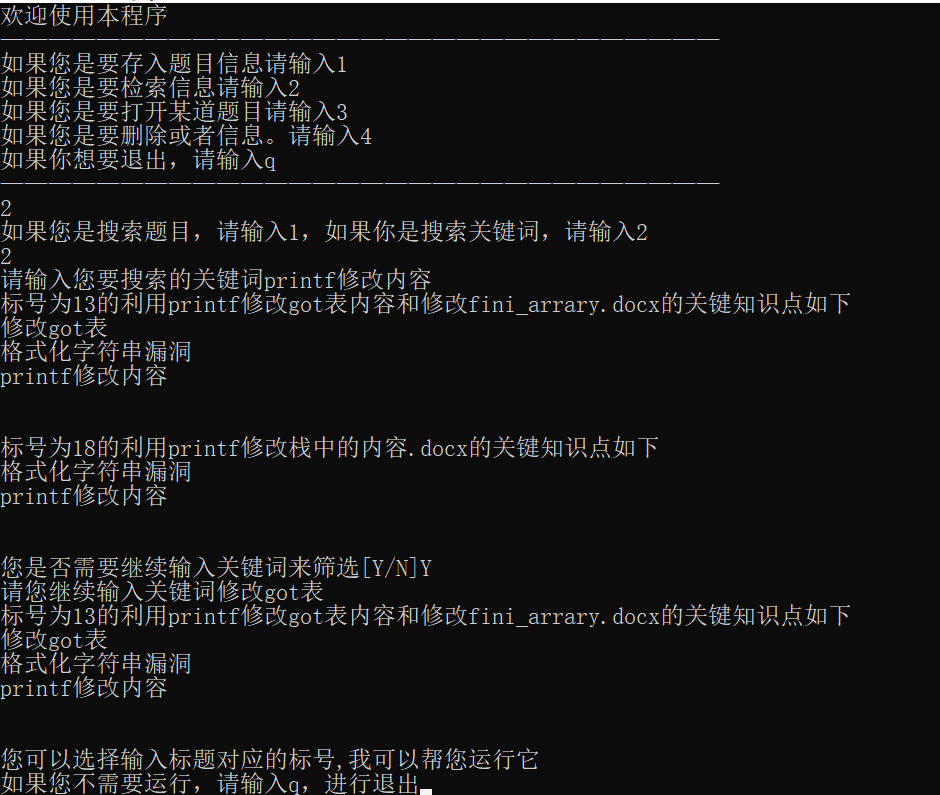
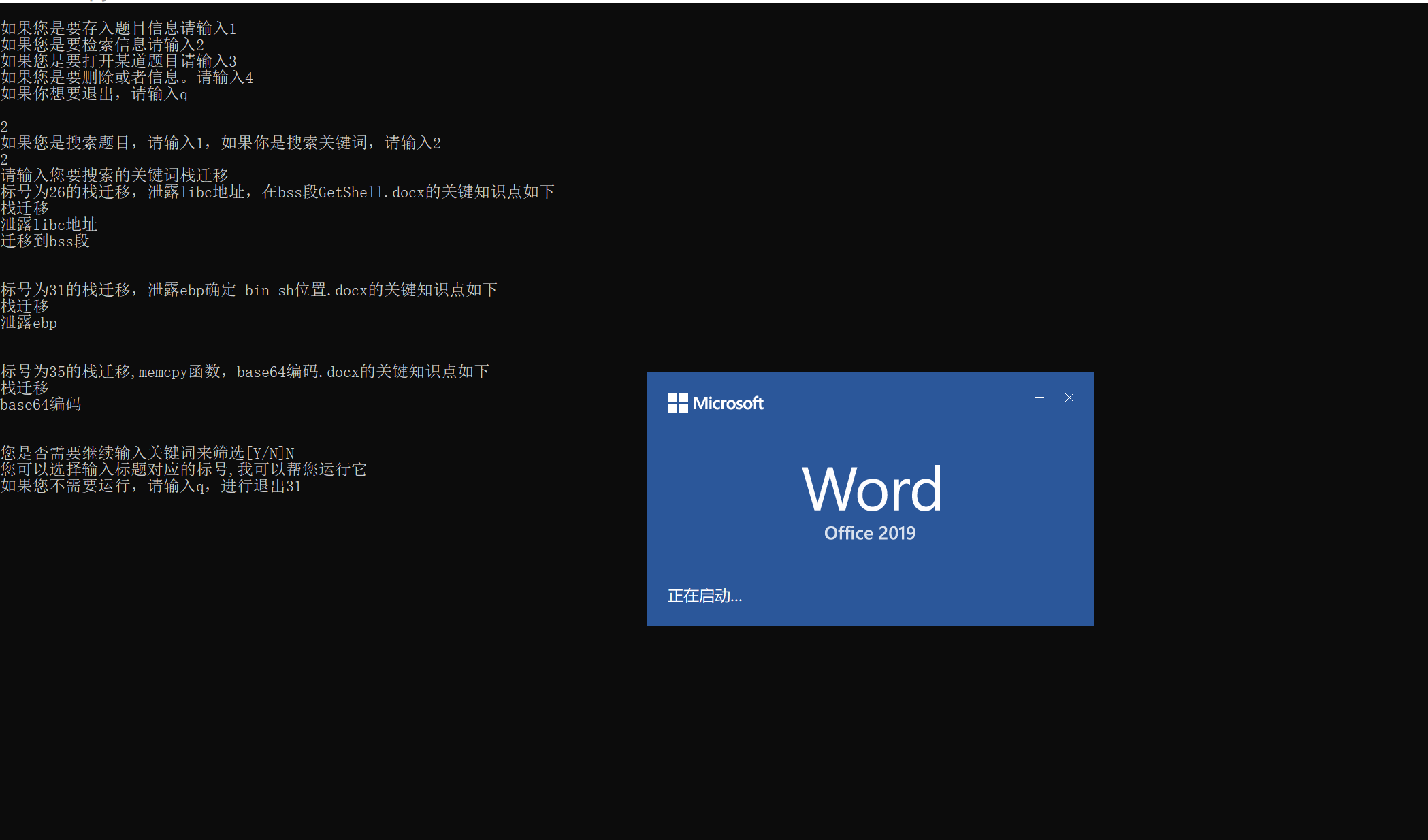
怎么使用这个程序?
①如果你要是用我的源码的话(源码在最后),那就要自己用python去运行,然后把这个文件 和你写的所有WP放在一个目录下面即可(不然程序是打不开WP的),然后先要存入每道题目和对应的关键词(这个还是要自己手动输入的)(这只是个检索的小工具),至于怎么存,运行一下程序应该就知道了。然后存的时候还会生成一个database.txt文件,你输入的数据就存储到这个文件里了,可千万不要不小心去删了(并且这个文件也要和search.py.py放在一个目录里面)
和你写的所有WP放在一个目录下面即可(不然程序是打不开WP的),然后先要存入每道题目和对应的关键词(这个还是要自己手动输入的)(这只是个检索的小工具),至于怎么存,运行一下程序应该就知道了。然后存的时候还会生成一个database.txt文件,你输入的数据就存储到这个文件里了,可千万不要不小心去删了(并且这个文件也要和search.py.py放在一个目录里面)
②如果你使用的是我转换好的exe文件(文件在最后),那么是需要把WP放进dist里面的search文件夹里面

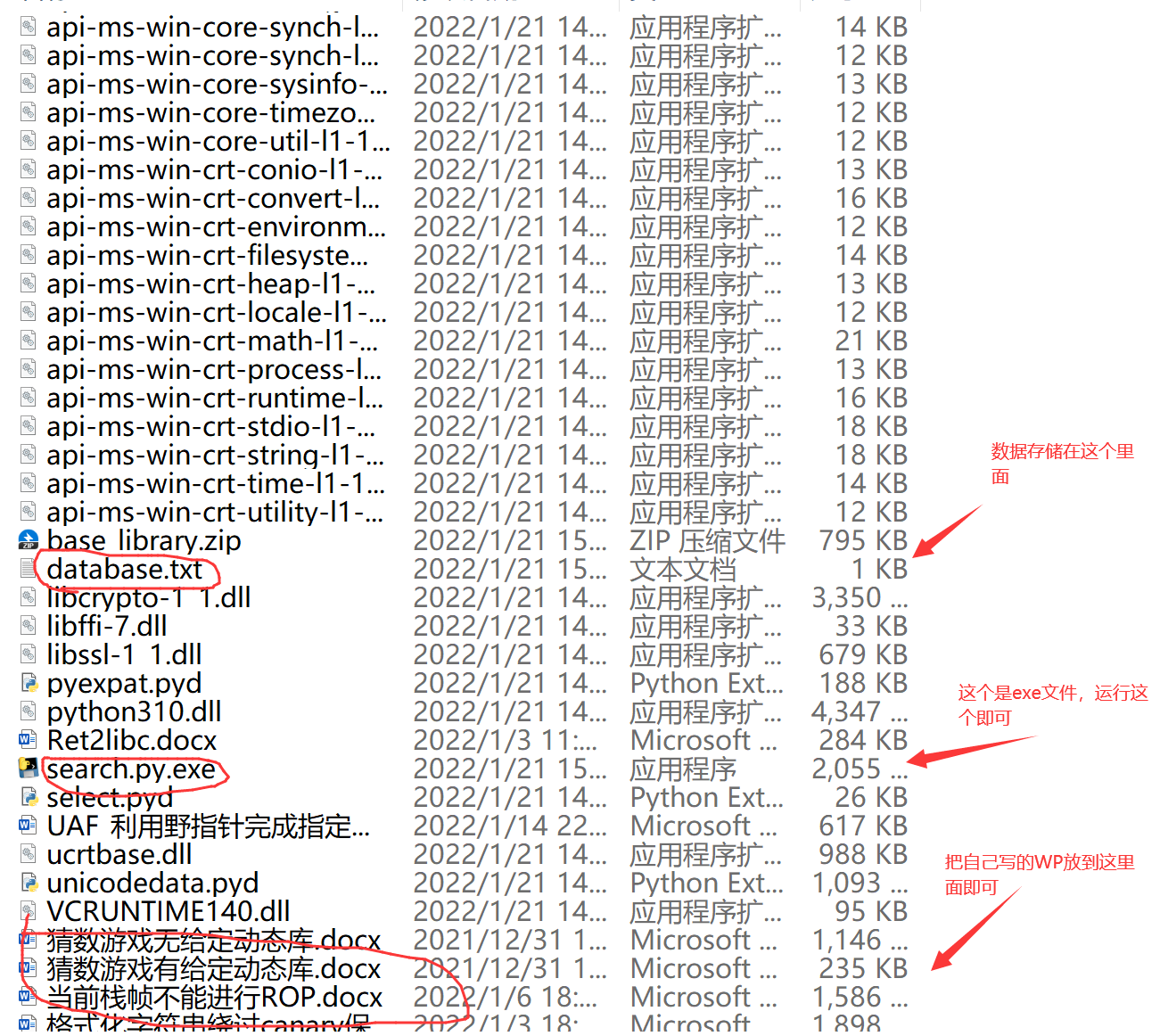
然后运行这个search.py.exe即可(不过里面的信息依然是要自己手动填写)
使用的注意事项:
1、由于本人目前实力有限,无法增加删除功能,需要手动删除,要想查看详情,请选择程序菜单中的4(这个程序菜单是进入程序里面之后选择4)
2、菜单功能中的1(进入程序之后选择的1),一旦进入,就必须要输入内容,不然会多出来一条分界线,这样对于之后的检索有可能出现问题,如果你这么做了,那么请看第四条。
3、如果是正常使用,还出现了检索问题,请去database.txt文件中,看一下存储的格式是否正确
4、database.txt正确格式为一条分界线(分界线就是10个_),然后题目,然后是关键词,每个内容都是独占一行,如果不是这个格式,请去database.txt里面手动改一下(只要是正常使用,就应该不会出现格式问题,至少我现在还没遇见过)。
5、并且database.txt文件内容的最后结尾是没有分界线的
6、所有的信息都会被存储在database.txt文件中,该文件绝对不可以被删除
7、本程序一定要与WP的文件放在一个目录中,不然是没办法运行WP的。
为什么要写这个程序?
本人刚刚开始学pwn,在刷题的时候,每次写过一道题,基本都会自己去写一下这道题的WP,起初刚写完的时候,还对里面的知识点记忆犹新,可是过了几天之后,知识点基本就忘的差不多了(如果点进去看的话,肯定扫一眼,就又想起来知识点了)但如果不点进去的话,基本光看题目,就不知道这个WP写的是什么,后来我去把每道题目的知识点,命名成WP的名字。WP少的时候还行,可是WP越来越多,即使每个题目上都写着知识点,再找的时候,也比较麻烦。于是乎,就有了想写个工具,来帮我检索信息的想法。
因为前一段时间花了将近一个星期的时间去学习python,因此这里就想着去用python去来开发这个程序。
声明:
本人是初学python(就学了不到一个星期...),并且能力有限,因此如果程序使用中出现了bug,欢迎大家与我联系,我会尽力修复。并且这个程序我还有四个想法,鉴于目前能力有限,无法写出来。它们分别是
①增加一个删除指定信息的功能
②增加一个修改指定信息功能(如果①实现的话,那么②应该指日可待了)
③增加一个图形化界面,这个应该是比较难的,但如果可以的话,谁想面对一个黑漆漆的程序窗口呢
④增加一个模糊搜索功能,针对关键词而已,如果我们记得不太清楚了,五个字的栈迁移原理,我们输入成了栈迁移就无法被检索出来,这个模糊功能我是想让它实现输入一部分的字,也可以检索出来我们要找的关键字
如果大家有思路,并且想与我共同完成这个程序剩下功能的开发,那么我是十分欢迎您与我联系的。
源代码
代码写的很烂...请见谅。
# -*- codeing = utf-8 -*-
# @Time : 2022/1/20 15:49
# @Author : ZIKH
# @File : search.py
# @Software : PyCharm
import os
import sys
def create_contents(): # 该函数用于存入题目以及关键词
fd = open('database.txt', 'a') # 加换行是因为每一行只存储一个信息
fd.write('__________\n')
title = input('请输入题目\n')
fd.write(title + '\n')
key_word = '1' #初始化这个变量
while True:
key_word = input('每次请输入一个关键词然后按下回车,输入q则代表存储完毕\n')
if key_word == 'q':
fd.close()
break
fd.write(key_word + '\n')
fd.close()
def search_add_keyword(list, add_word): # 经过第一次筛选之后,再添加关键词,则进入本函数
# list为第一轮筛选关键词之后符合题目的列表
# add_word为添加的关键词
for title in list.copy(): # 遍历每一个存在列表中的元素
fd = open('database.txt', 'r')
flag = 0 # flag为1表示在这个题目中找到了新加关键词,为0代表没找到
ret = 0 # ret为1用来结束第二个循环
while True: # 一直读,直到遇见当前的content,再进行判断
content = fd.readline()
if not content:
break
if title == content:
while True:
content = fd.readline()
if content == '__________\n': # 这个循环本就是搜寻当下题目的关键字,如果在到达下个题目之前,没找到,那就退出
ret = 1
break
if not content: # 但如果题目正好是最后一个那么下面就没有分界线
break # 因此需要加上这句
if add_word + '\n' == content:
flag = 1
break
if flag == 1:
break
if flag == 0:
list.remove(title) # 当题目中没有要检索的新增关键词,那就删除列表中的元素
if ret == 1:
break
fd.close()
return list
def title_search(target): # 这个函数用于检索题目
fd = open('database.txt', 'r')
biaohao = 0 # 标号是给每个题目添加一个序号,便于下面函数运行该题目
flag = 0
while True:
content = fd.readline()
biaohao = biaohao + 1 # 只要每读一行的内容,就让标号+1
if not content:
break
if content == '__________\n': # 此时content的下一个就是题目
content = fd.readline() # 此时的content为题目
biaohao = biaohao + 1
if content == target + '\n': # 此时检索到了要找寻的题目
flag = 1 # 这个值用于判断是否,检索到数据库里的题目
print('标号为' + str(biaohao) + '的' + target + '的关键知识点如下')
while True: # 开始打印这个题目对应的知识点
content = fd.readline()
biaohao = biaohao + 1
if not content:
break
if content == '__________\n':
break
print(content, end='')
print('\n') # 此处在关键词的结尾加一个换行,为了整洁
else:
pass
else: # 只要没有遇到__________,那就说明下一个不是标题,那就跳过
continue
if flag == 0:
print('没有检索到您输入的题目,请您检查下是否输入了文件类型的后缀')
print('程序将退出')
fd.close()
sys.exit(1)
fd.close()
def print_title_word(titles): # 打印当前列表中存储的题目
for title in titles:
title_search(title.strip()) # 进入title_search判断的时候会加上一个回车,因此这里要删掉本身的回车
def keyword_search(word): # 检索关键词,把出现过的关键词对应的标题存入列表中
fd = open('database.txt', 'r')
titles = [] # 这个列表是用来储存具有要检索关键词的题目(这样的题目不唯一)
flag = 0 # 所以要用列表来存储题目
flag_panduan = 0 # 这个标志点用来检测程序是否检索到关键词
while True:
if flag != 1: # 防止在这里读了两次,在下面的循环中已经读到__________了
content = fd.readline()
if not content: # 如果读完了整个文件,那么就进行退出
break
flag = 0 # 让标志点重新归零,不然以后都进不来这个的if
if content == '__________\n': # 当发现__________之后,把下面的题目存储在head中
content = fd.readline()
head = content # 只要接下来出现的word是被检索的,那就把这个head放进title列表
continue # 然后continue一次,目的为了是从关键词开始读
if content == word + '\n':
titles.append(head)
flag_panduan = 1
while True: # head只要在列表里存储一次即可,该循环用于跳出这个题目下所有关键词
content = fd.readline()
if not content:
break
if content == '__________\n':
flag = 1 # 设置标志点,不然刚进入大循环的时候,就会再读一次
break
if flag_panduan == 0:
print('未检测到关键词,请检查后输入')
return
print_title_word(titles) # 第一轮检索完毕,打印列表中的题目,以及题目所属的关键词
while len(titles) > 1:
panduan = input('您是否需要继续输入关键词来筛选[Y/N]')
if panduan == 'Y':
add_word = input('请您继续输入关键词')
titles = search_add_keyword(titles, add_word)
print_title_word(titles)
if panduan == 'N':
print('您可以选择输入标题对应的标号,我可以帮您运行它')
number = input('如果您不需要运行,请输入q,进行退出')
if number == 'q':
sys.exit(0)
else:
run(number) # 运行对应的标号,在run函数里面,会对标号进行遍历
print('您可以选择输入标题对应的标号,我可以帮您运行它')
number = input('如果您不需要运行,请输入q,进行退出')
if number == 'q':
sys.exit(0)
else:
number = int(number) # 如果这里不是q的话,就把输入的内容当做标号来处理
run(number) # 去运行标号对应的题目文件
def search(): # 检索信息时的交互函数
panduan = input('如果您是搜索题目,请输入1,如果你是搜索关键词,请输入2\n')
if panduan == '1':
target = input('请输入您要搜索的标题,我将为您展示它的关键词')
title_search(target)
if panduan == '2':
word = input('请输入您要搜索的关键词') # word为要检索的关键词
keyword_search(word)
if panduan != '1' and panduan != '2':
print('请输入有效数字,程序将退出')
sys.exit(0)
def run(biaohao): # 先检索到标号对应的题目,然后去运行该题目
fd = open('database.txt', 'r')
biaohao = int(biaohao)
try:
for i in range(biaohao):
content = fd.readline()
except :
print('非法标号,请输入正确的标号')
print('程序将退出')
sys.exit(1)
try:
os.system(content)
except :
print('非法标号,请输入正确的标号')
print('程序将退出')
sys.exit(1)
print('程序已经帮您运行')
print('感谢您的使用')
sys.exit(0)
def main(): # 主函数,用来交互
print('欢迎使用本程序')
while True:
print('——————————————————————————————')
print('如果您是要存入题目信息请输入1')
print('如果您是要检索信息请输入2')
print('如果您是要打开某道题目请输入3')
print('如果您是要删除或者信息。请输入4')
print('如果你想要退出,请输入q')
print('——————————————————————————————')
number = input()
if number == '1':
create_contents()
elif number == '2':
search()
elif number == '3':
program = input('您要运行的程序标号为')
run(program)
elif number == '4':
delete_content()
elif number == 'q':
print('感谢使用')
sys.exit(0)
else:
print('请输入有效数字,程序将结束')
sys.exit(0)
def delete_content():
print('鉴于本人目前实力有限,这部分的功能,暂且没办法用代码来实现')
print('如果您需要删除题目,以及题目下的关键词,请去database.txt文件中手动删除')
print('从题目上面的分界线(包括这个分界线)删除到题目下一个分界线(不包括这个分界线)即可')
print('如果您要修改或删除某个题目的关键词,那么在database.txt文件中找到对应题目,删除或修改关键词即可')
print('\n')
main()
代码中有很多的不足,如果您能与我联系并给予指正,我将感激不尽。
exe文件
生成的exe文件我上传到百度网盘了 网址https://pan.baidu.com/s/1djrHBytgDdtzNvu5O4iOXw?pwd=8nme 提取码8nme
使用的方法,上文也已经说明
程序的设计思路
下面是写程序之前的预想思路和实际实现功能的思路,我做了一个对比,这个对比其实更多的还是给我自己看的,看下预想和实际的区别。
程序名称:WP的检索关键词小程序
程序功能:①去存入一个题目名称,和一些关键词
②进行检索(输入题目名称或者关键词,都可以检索出来对应的所有信息)(也可以输入多个关键词,来准确找出题目(同一个关键词可能对应多个题目))
③去运行这个检索到的wp
针对功能①
初期大体思路:
创建一个储存信息的数据库(用字典,键来存储题目名称,值用列表,来储存关键词)(这个数据库要存储到一个新的文件里)
实际大体思路:
把信息直接写到文件里面,不用字典,第一行写入题目,剩下的行依次写入关键词(一行一个)(用一条分界线(我用了十个_来表示)来划分题目)
针对功能②
初期大体思路
先对键进行遍历,每次检查一个键的时候,再对这个值(也就是列表)进行遍历,如果输入的内容与列表中的关键词相同,那么去把这个键存到一个新建的列表中,最后输出列表
中的内容。
如果要检索多个关键词,那就先对第一个关键词执行上一段的操作,然后把符合条件的题目都先放到列表中,然后再对第二个关键词执行操作(此时去遍历新建列表中的键的值)
然后不符合条件的删掉即可,如果还有关键词,就依旧同上操作。
实际大体思路:
如果搜索题目的话,那就去遍历文件的每一行,如果没有碰见分界线的话(分界线下面就是题目),那就继续直接跳到下一轮循环,去读入下一行内容。如果碰到分界线的话
那就去读入下一行的内容,去与要搜索的题目,进行对比,如果一样的话,那就去打印他们下面的每一行内容(这些内容都是关键词),直到读到下一个分界线,就停止
如果是搜索关键词的话,也是遍历文件的每一行,只不过用一个head变量来存储当前检索关键词的题目,如果找到了关键词,那就把这个题目存到一个列表里面
然后找完了所有具有关键词的题目,然后用for遍历整个列表,每从列表里拿出一个元素,就把这个元素当做参数去放到搜索题目的那个函数里面,去一次打印每个题目里的关键词
新增功能:检索完一次关键词之后,可能依然有很多的题目,这时候可以继续去检索关键词,以来筛选出,我们最想要的题目。具体实现是让文件从头开始跑一次
然后遇到列表中的题目,就去检索一下其中的关键词,如果发现了要找的关键词,则去检索列表的下一个题目,如果遍历完整个文件没有发现当前题目中具有新输入的关键词
那就将它从列表中 删除。依次来达到筛选的目的
针对功能③
初期思路:
得到题目之后,把题目当做路径,然后用函数直接运行题目的WP即可(要将本程序和题目的WP放在一起)
实际思路:
先创建一个标号的变量。从最开始,程序只要往下读一行,就会让标号+1,这样题目就有了属于自己的标号
然后让用户输入标号,输入完毕之后,直接进行循环(从头开始),每次循环就往下读一行,循环标号的次数,然后得到标号对应的题目,因为文件名就是题目,因此
用os.system()直接调用这个题目即可
强化功能(未完成):如果关键词是 shellcode的构造及利用 那么我希望在检索的时候只输入一个shellcode,也能让找到shellcode的构造及利用这个关键词对应的题目
针对这个功能,暂时还没有什么思路
写程序的时候,有一些新发现:
list = [1,2,3,4,5,6,7,8,9,10]
for i in list:
list.remove(i)
print(list)
你认为这个最后的结果会是什么
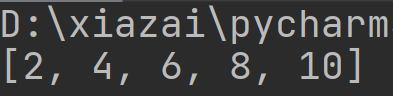
没错,结果并不是[],这是为什么呢?
因为当第一次循环的时候是要把下标为0的元素删掉,因此删掉了1,然后第二次循环的时候.本应该是删除下标为1的元素了。可此时的列表已经是2,3,4,5,6,7,8,9,10,因此在删掉下标为1的元素的时候(这里说删掉其实有点不合适,更准确的应该说是在第二次遍历的时候,是取出的下标为1的元素覆给了i),因此第二次循环的i其实是3,并非是2。之后的情况也是如此。这个点在我写程序的时候,困扰我了很久,最后看了这篇文章才理解Python中使用for循环遍历操作时容易踩的坑 - 小博测试成长之路 - 博客园 (cnblogs.com)
解决办法就是把这个list先给复制一份(从这个复制的这个list取出i,这样列表就不会因为删掉了元素,而导致列表是变化的) 如下
list = [1,2,3,4,5,6,7,8,9,10]
for i in list.copy():
list.remove(i)
print(list)
此时得到了我们想要的结果
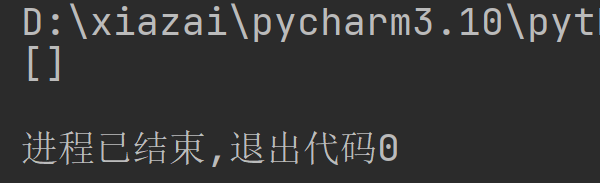
心得:
第一次用python写了一个这么长的程序(至少以目前我的水平而言,我感觉两百多行还是比较长的),上一回写两百多行还是用c写了个小程序,也是自己第一次真正的写了一个小工具(尽管这个小工具可能存在bug,尽管它没图形化界面,尽管它的功能并不多,但毕竟是一个工具,而非没有意义的程序。
说实话写的时候,还是遇到了不少的问题,最开始是有了思路,然后思考用代码怎么实现,后来是开始写,写的时候,并不算太困难,我感觉我的这个工具逻辑并不复杂。最痛苦的时候,其实就是写完之后,程序一堆bug,最开始的时候还可以通过调试找出来问题,但是如同我上面写的那个发现一样,这个就调试不出来,只知道是哪出了问题,但是根本想不通为什么会这样,不过好在身处互联网时代,干什么都能搜,并且幸运的被我搜到了问题,以此得以解决。最后开始完善交互,并且还在有的地方画蛇添足,结果又增加了点bug,不过最后还是一一给排查掉了。
收获也是显而易见的,最直接的莫过于得到了一个检索题目信息的工具,这样以后想看以前的知识点了,只要输入一下知识点,就可以找到对应的wp。其次就是编程能力得到了不小的提升,这个程序里面的每个部分功能都是用函数来实现的,处理每个函数的时候,也确实锻炼自己的编程能力。再者就是提升了自己思考程序设计的能力,一个程序首先要根据自己所掌握的知识想出来一个绝佳的思路,才能去编写它,说实话我最开始,只是想用字典去写,但是后来发现,感觉用文件一行一行,来存储信息也不错。写了这一个工具确实是受益匪浅。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号