


- 邮件
- 发邮件
from email.mime.text import MIMEText from smtplib import SMTP from email.header import Header from email.utils import formataddr if __name__ == '__main__': # 构建邮件 msg = MIMEText('就是一个测试', 'plain', 'utf-8') # 发件人 msg['From'] = formataddr((Header('学习','utf-8').encode(), '12345678910@qq.com')) # 收件人 msg['To'] = formataddr((Header('朋友','utf-8').encode(), '12345678@163.com')) # 邮件主题 msg['Subject'] = Header('圣诞快乐', 'utf-8') # 发邮件 smtp = SMTP() smtp.connect('smtp.qq.com', 25) # 打开调试 smtp.set_debuglevel(1) # 登录邮箱 smtp.login('12345678910@qq.com', '授权密码') # 发送 smtp.sendmail('12345678910@qq.com', ['123456@163.com'], msg.as_string()) # 断开 smtp.quit()
- 发邮件添加附件
from email.mime.text import MIMEText from email.mime.multipart import MIMEMultipart from email.utils import formataddr from email.header import Header from smtplib import SMTP from email.mime.base import MIMEBase from email.encoders import encode_base64 if __name__ == '__main__': msg = MIMEMultipart() text = MIMEText('你好!\n不好意思有打扰您!涨工资的事您考虑的怎么样了....', 'plain', 'utf-8') msg.attach(text) msg['From'] = formataddr((Header('某人', 'utf-8').encode(), '12345678910@qq.com')) msg['To'] = formataddr((Header('领导', 'utf-8').encode(), '123456@163.com')) msg['Subject'] = Header('您在考虑一下', 'utf-8') # 添加附件图片 with open('cool.gif', 'rb') as f: mime = MIMEBase('image', 'gif') mime.add_header('Content-Disposition', 'attachment', filename='cool.gif') # 加载图片 mime.set_payload(f.read()) # 指定编码格式 encode_base64(mime) msg.attach(mime) # 发邮件 smtp = SMTP('smtp.qq.com', 25) # 打开调试 smtp.set_debuglevel(1) # 登录邮箱 smtp.login('12345678919@qq.com', '授权密码') # 发送 smtp.sendmail('12345678910@qq.com', ['123456@163.com'], msg.as_string()) # 断开 smtp.quit()
- 收邮件
from poplib import POP3 if __name__ == '__main__': pop = POP3('pop.163.com', 110) pop.set_debuglevel(1) # 连接成功欢迎字符串 print(pop.getwelcome().decode()) # 登录 pop.user('123456@163.com') pop.pass_('python123456') # 邮件状态(总件数,总大小) print(pop.stat()) # 获取每一封邮件索引和大小 response, res, oct = pop.list() print(res) # 获取最后一封邮件 response, context, oct = pop.retr(25) print(context) res = b'\r\n'.join(context) print(res.decode('utf-8'))
- nurl
网页读取
import urllib.request import re # 打开并读取url url = urllib.request.urlopen('https://movie.douban.com/') print(url) # 读取数据 data = url.read().decode() # print(data) res = re.findall(r'<img src="(.*?)" alt="神探狗笨吉"', data) print(res)
- re
正则:筛选出来目标
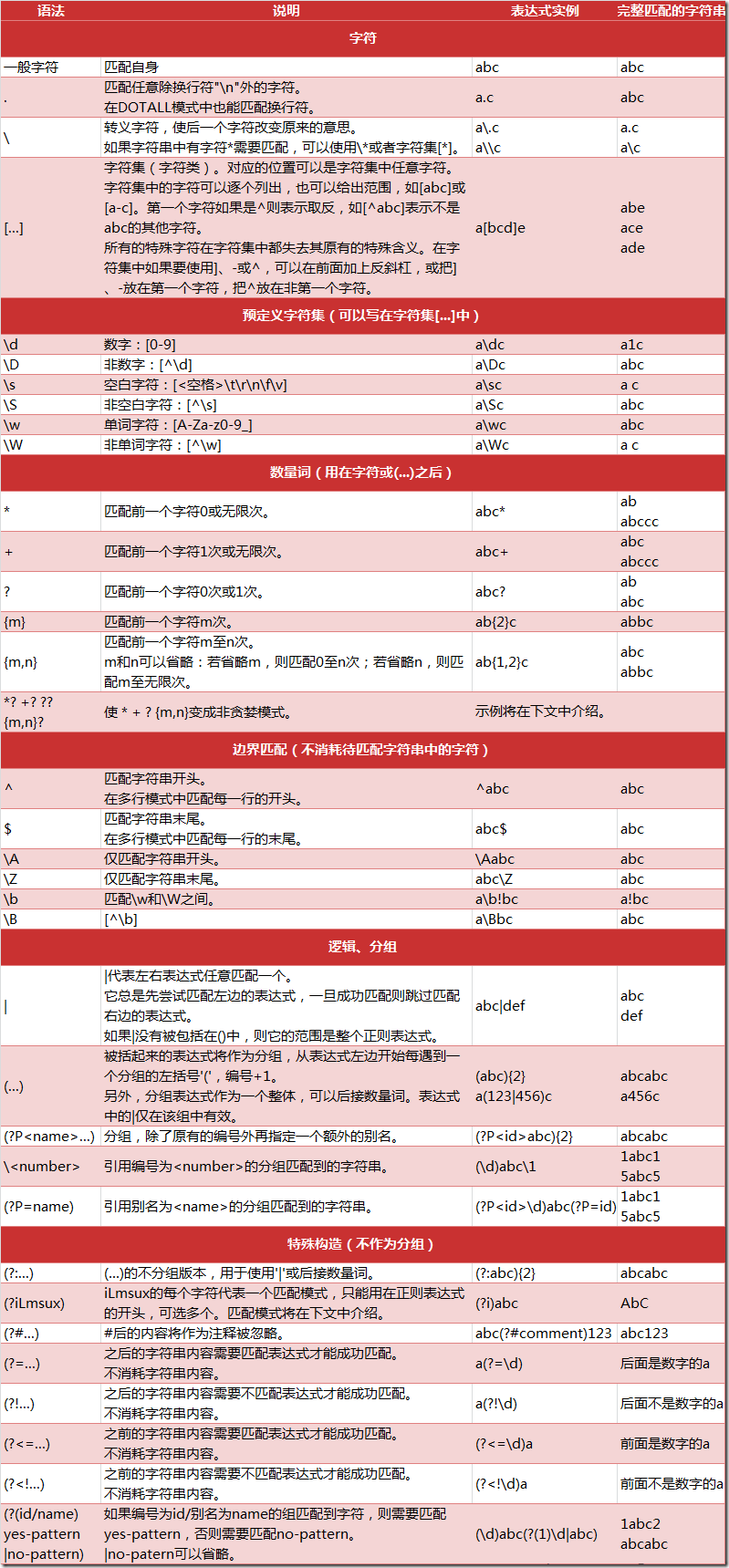
import re s = 'a href"=https://Book.douban\.com" booktarget="_blank"\\ \ndata-moreurl-dict=">读书</a>' # 编译规则 cmp = re.compile(r'.{3,8}?') # 得到与规则匹配的结果对象 res = cmp.match(s) print(res.group(), res.start(), res.end(), res.span()) # 从头 res = re.match(r'[a-z]*', s) print(res) # 匹配整个字符串 re.S 使得.包括'\n', re.M多行模式 res = re.findall(r'^[a-z](.+)>$', s, re.S) print(res) res = re.finditer(r'[a-z]{2}', s) print(res) res = re.findall(r'Book|book', s) print(res) p = re.compile(r'\W+') res = p.split('This is a test, short and sweet, of split().') print(res)
