
IK分词器(ikAnalyzer)简单使用
分词器简单使用:
1.首先在pom文件中添加如下坐标
<!-- 有可能一次导入本地仓库不成功,需要多尝试几次 -->
<dependency> <groupId>com.janeluo</groupId> <artifactId>ikanalyzer</artifactId> <version>2012_u6</version> </dependency>
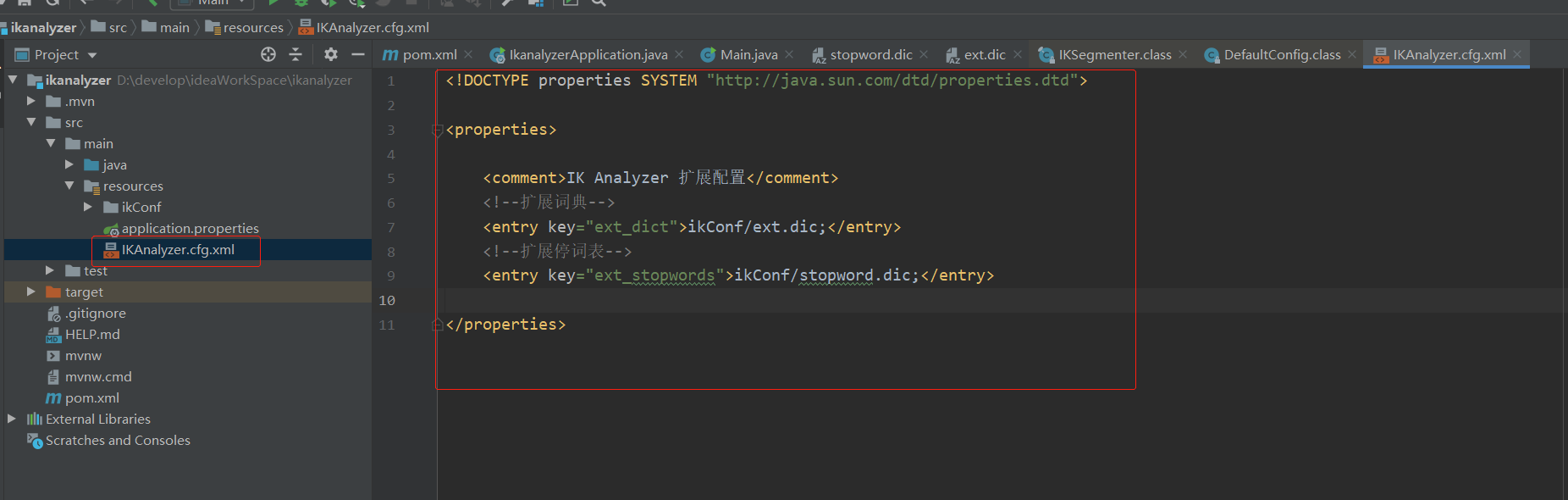
2.在资源文件夹下添加如下添加 IKAnalyzer.cfg.xml配置文件,并指定扩展词典配置的位置和扩展停词词典的位置。扩展文件的位置是在resource目录下建立ikConf目录,并添加两个扩展配置文件。
扩展词典:在我们汉语中本身有很多的常见词语,但是在一些专业领域方面有些专业的词语是不包含在常见词语中的,这时候我们可以通过这个配置文件进行配置。(数据湖,苯溴马隆)这些词想作为词组就直接添加在这个配置文件中。
扩展停词词典:停止词,是由英文单词:stopword翻译过来的,原来在英语里面会遇到很多a,the,or等使用频率很多的字或词,常为冠词、介词、副词或连词等。如果搜索引擎要将这些词都索引的话,那么几乎每个网站都会被索引,也就是说工作量巨大。可以毫不夸张的说句,只要是个英文网站都会用到a或者是the。那么这些英文的词跟我们中文有什么关系呢? 在中文网站里面其实也存在大量的stopword,我们称它为停止词。比如,我们前面这句话,“在”、“里面”、“也”、“的”、“它”、“为”这些词都是停止词。这些词因为使用频率过高,几乎每个网页上都存在,所以搜索引擎开发人员都将这一类词语全部忽略掉。如果我们的网站上存在大量这样的词语,那么相当于浪费了很多资源。原本可以添加一个关键词,排名就可以上升一名的,为什么不留着添加为关键词呢?停止词对SEO的意义不是越多越好,而是尽量的减少为宜。
主程序:放便我们去查看ik分词器帮我分词后的效果。
package com.zhp.ikanalyzer.test; import org.wltea.analyzer.core.IKSegmenter; import org.wltea.analyzer.core.Lexeme; import java.io.StringReader; import java.util.HashSet; import java.util.Set; public class Main { public static void main(String[] args) throws Exception { Set<String> segment = (Set<String>) segment("@车@险理赔@able,baby ll.bbbb,学a习"); for (String s : segment){ System.out.println(s); } } private static Set segment(String text) throws Exception{ Set<String> set = new HashSet<>(); StringReader re = new StringReader(text.trim()); IKSegmenter ik= new IKSegmenter(re,true); Lexeme lex; while((lex = ik.next())!=null){ set.add(lex.getLexemeText()); } return set; } }
构建IKSegmenter对象源码中可以看到加载配置文件是在classes路径下。因此我们在resources目录下创建IKAnalyzer.cfg.xml,maven功能编译之后会把resources目录下的文件放在classes目录下。
public IKSegmenter(Reader input, boolean useSmart) { this.input = input; this.cfg = DefaultConfig.getInstance(); this.cfg.setUseSmart(useSmart); this.init(); }
public class DefaultConfig implements Configuration { private static final String PATH_DIC_MAIN = "org/wltea/analyzer/dic/main2012.dic"; private static final String PATH_DIC_QUANTIFIER = "org/wltea/analyzer/dic/quantifier.dic"; private static final String FILE_NAME = "IKAnalyzer.cfg.xml"; private static final String EXT_DICT = "ext_dict"; private static final String EXT_STOP = "ext_stopwords"; private Properties props = new Properties(); private boolean useSmart; public static Configuration getInstance() { return new DefaultConfig(); } private DefaultConfig() { InputStream input = this.getClass().getClassLoader().getResourceAsStream("IKAnalyzer.cfg.xml"); if (input != null) { try { this.props.loadFromXML(input); } catch (InvalidPropertiesFormatException var3) { var3.printStackTrace(); } catch (IOException var4) { var4.printStackTrace(); } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号