4-1 线程安全性-原子性-atomic-1



我们发现在不做任何同步的情况下,我们计算的累加结果是错误的。
com.mmall.concurrency.example.count.CountExample2
C:\Users\ZHONGZHENHUA\imooc\concurrency\src\main\java\com\mmall\concurrency\example\count\CountExample2.java
package com.mmall.concurrency.example.count; import com.mmall.concurrency.annoations.ThreadSafe; import lombok.extern.slf4j.Slf4j; import java.util.concurrent.CountDownLatch; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.Semaphore; import java.util.concurrent.atomic.AtomicInteger; @Slf4j @ThreadSafe public class CountExample2 { // 请求总数 public static int clientTotal = 5000;//1000个请求 // 同时并发执行的线程数 public static int threadTotal = 200;//允许并发的线程数是50 public static AtomicInteger count = new AtomicInteger(0); public static void main(String[] args) throws Exception { ExecutorService executorService = Executors.newCachedThreadPool(); final Semaphore semaphore = new Semaphore(threadTotal); final CountDownLatch countDownLatch = new CountDownLatch(clientTotal); for (int i = 0; i < clientTotal; i++) { executorService.execute(()-> { try { semaphore.acquire(); add(); semaphore.release(); } catch (Exception e) { log.error("exception",e); } countDownLatch.countDown(); }); } countDownLatch.await(); executorService.shutdown(); //log.info("count:{}",count); log.info("count:{}",count.get()); } private static void add() { //count++; count.incrementAndGet(); // count.getAndIncrement(); } }
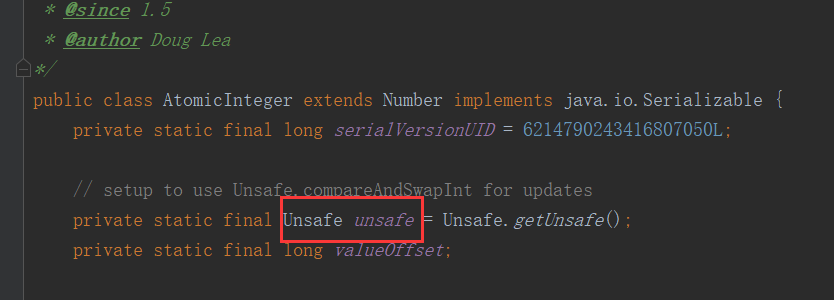
把计数的值从int换成了AtomicInteger,看一下AtomicInteger的incrementAndGet方法的源码实现。AtomicInteger的源码实现使用了一个unsafe的类,unsafe提供了一个方法叫做getAndAddInt,getAndAddInt这个方法不是特别关键的,核心关键是getAndAddInt它的实现。
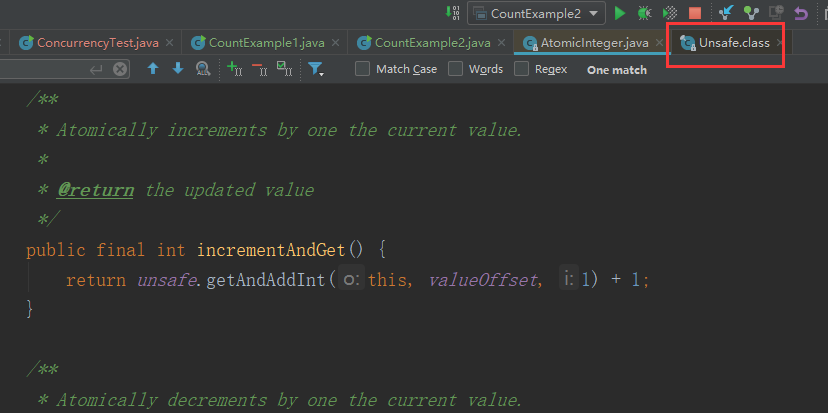
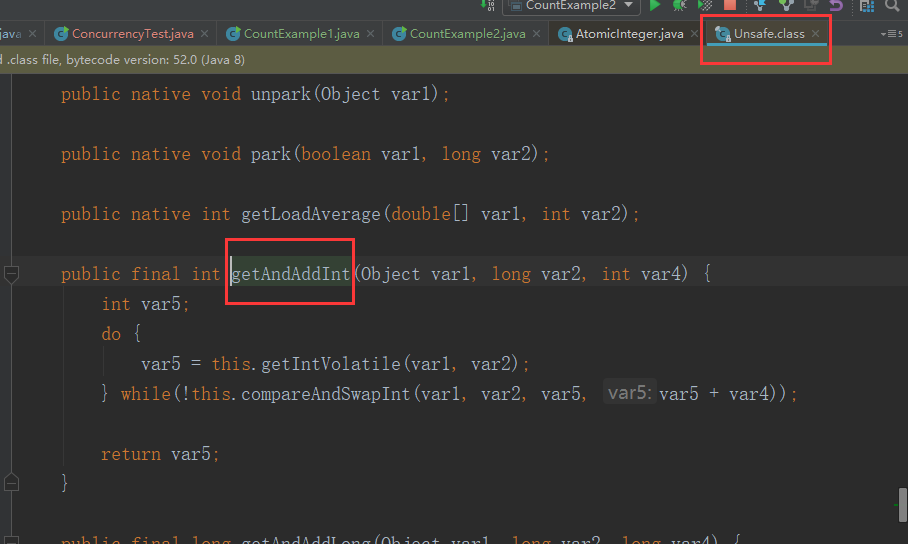
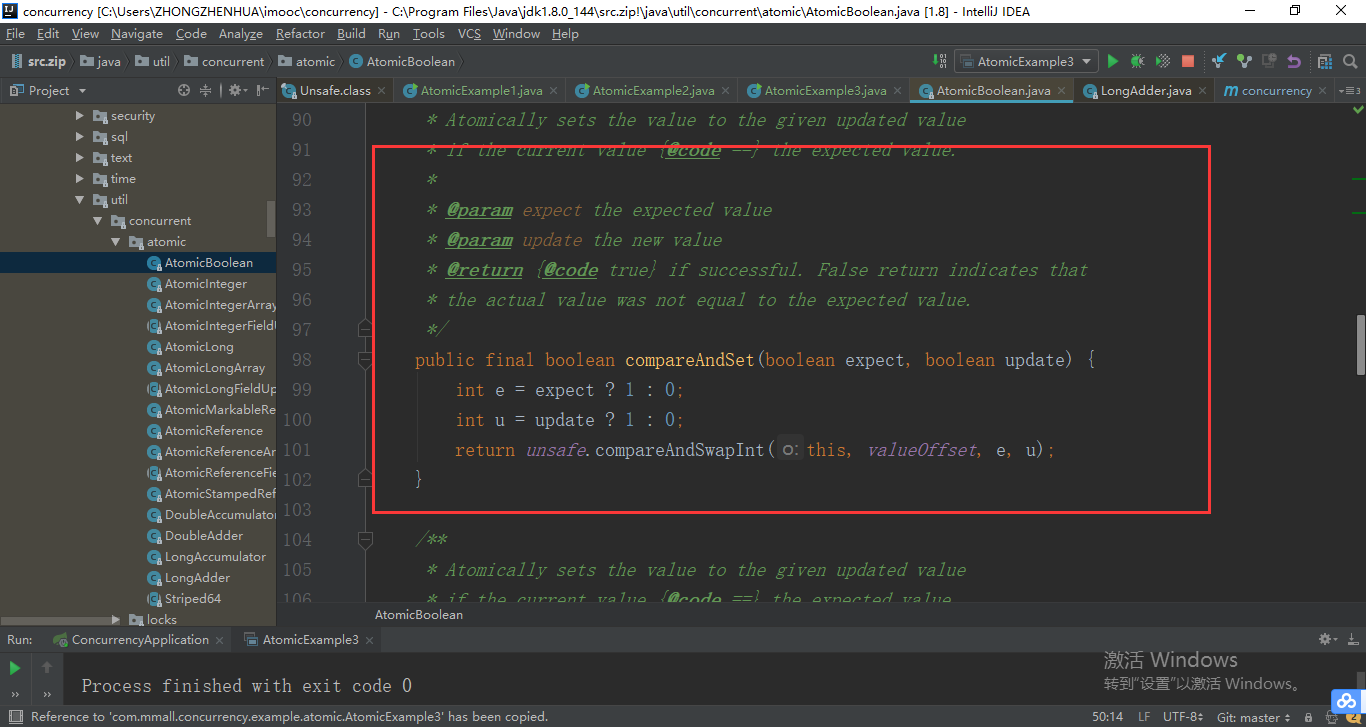
compareAndSwapInt这个方法需要大家特别注意。compareAndSwapInt它其实是用native标识的方法。native这个代表是Java底层的方法,不是我们通过Java去实现的。Object var1是传过来的count这个对象,第二个值long var2是我们当前的值,比如我想执行的是2+1=3这个操作,当前这个第二个参数var2它等于2,第三个值var4等于1,如果当前的值var2跟底层的这个值var5相同的话,那么把它var5更新成后面的这个值va5+var4。当我们一个方法进来的时候,long var2它这个值是2,这个时候我们第一次取出来的变量var5的值应该也等于2,但是当我们在执行进行更新层增删的时候呢,可能会被别的线程更改,因此它这里要判断如果我当前这个值var2跟我期望的值var5是相同的话,就是这里面取出来的值var2也等于2的时候,那么我才允许它更新成3,否则重新取出来当前这个变量var5,然后这里面的变量var2相当于是重新从我当前的这个count对象里面取一次也会变成3,相当于继续判断,如果当前的值var2=3,与我底层的值var5相同也等于3的话,那么我就把它变成3+1=4的这个值。通过这样不停地循环来判断,最后保证的是,期望的是一个值,与底层的值完全相同的时候,才执行对应的+1的这个值,把底层的值给覆盖掉。

compareAndSwapInt这个方法的核心就是CAS的核心。刚才我们介绍的是整型值的处理,对于其他的类型比如long、double、对象的值它们都可以通过对应的方法来进行处理,核心都是通过compareAndSwap的方式来进行操作。
关于CAS的实践我们就先讲到这里,大家一定要记住这里面它的实现的原理,是拿当前这个对象里的值var2和底层的值var5来进行对比,如果当前的值跟底层的值它们一样的时候,才执行对应的操作,这就是它的核心的原理。如果不一样的话那就不停地取最新的值,直到它们相同的时候才进行这个操作。如果大家不明白为什么这个count对象里面的值会和正常存储数据的底层的值不一样的话,大家可以看一下工作内存和主内存的关系,count里面存的值其实就属于工作内存,底层其实就是主内存,它们的值不一定完全一样的,所以我们做一些同步的操作才能保证它们在某个时刻是一样的。
com.mmall.concurrency.example.atomic.AtomicExample1
C:\Users\ZHONGZHENHUA\imooc\concurrency\src\main\java\com\mmall\concurrency\example\atomic\AtomicExample1.java
package com.mmall.concurrency.example.atomic; import com.mmall.concurrency.annoations.ThreadSafe; import lombok.extern.slf4j.Slf4j; import java.util.concurrent.CountDownLatch; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.Semaphore; import java.util.concurrent.atomic.AtomicInteger; @Slf4j @ThreadSafe public class AtomicExample1 { // 请求总数 public static int clientTotal = 5000;//1000个请求 // 同时并发执行的线程数 public static int threadTotal = 200;//允许并发的线程数是50 public static AtomicInteger count = new AtomicInteger(0); public static void main(String[] args) throws Exception { ExecutorService executorService = Executors.newCachedThreadPool(); final Semaphore semaphore = new Semaphore(threadTotal); final CountDownLatch countDownLatch = new CountDownLatch(clientTotal); for (int i = 0; i < clientTotal; i++) { executorService.execute(()-> { try { semaphore.acquire(); add(); semaphore.release(); } catch (Exception e) { log.error("exception",e); } countDownLatch.countDown(); }); } countDownLatch.await(); executorService.shutdown(); //log.info("count:{}",count);
log.info("count:{}",count.get()); } private static void add() {
//count++; count.incrementAndGet(); // count.getAndIncrement(); } }



com.mmall.concurrency.example.atomic.AtomicExample2
C:\Users\ZHONGZHENHUA\imooc\concurrency\src\main\java\com\mmall\concurrency\example\atomic\AtomicExample2.java
package com.mmall.concurrency.example.atomic; import com.mmall.concurrency.annoations.ThreadSafe; import lombok.extern.slf4j.Slf4j; import java.util.concurrent.CountDownLatch; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.Semaphore; import java.util.concurrent.atomic.AtomicInteger; import java.util.concurrent.atomic.AtomicLong; @Slf4j @ThreadSafe public class AtomicExample2 { // 请求总数 public static int clientTotal = 5000;//1000个请求 // 同时并发执行的线程数 public static int threadTotal = 200;//允许并发的线程数是50 public static AtomicLong count = new AtomicLong(0); public static void main(String[] args) throws Exception { ExecutorService executorService = Executors.newCachedThreadPool(); final Semaphore semaphore = new Semaphore(threadTotal); final CountDownLatch countDownLatch = new CountDownLatch(clientTotal); for (int i = 0; i < clientTotal; i++) { executorService.execute(()-> { try { semaphore.acquire(); add(); semaphore.release(); } catch (Exception e) { log.error("exception",e); } countDownLatch.countDown(); }); } countDownLatch.await(); executorService.shutdown(); //log.info("count:{}",count); log.info("count:{}",count.get()); } private static void add() { //count++; count.incrementAndGet(); // count.getAndIncrement(); } }
JDK8里面单独新增了一个类LongAdder跟AtomicLong特别像,


 因此我们这个线程安全了是没问题了。为什么有了AtomicLong之后还要新增一个LongAdder这个类?很显然如果增加一个类肯定是有它的优点的。这里LongAdder它的实现我们就不多说了,我们具体说一下LongAdder和AtomicLong它俩对应的优点和缺点。之前我们在讲AtomicInteger的实现机制的时候我们看过CAS的底层实现,它们是在一个死循环内不断地尝试修改目标值直到修改成功。如果竞争不激烈的时候呢,它修改成功的概率很高,否则的话修改失败的概率就会很高,在大量修改失败的时候呢,这些原子操作就会进行多次的循环尝试,因此呢性能会受到一些影响。这里呢有一个知识点,对于普通类型的long和double变量,JVM允许将64位的读操作或者写操作拆成两个32位的操作,那么LongAdder这个类它的实现是基于什么思想呢?它的核心是将热点索引分离,比如说它可以将AtomicLong的内部核心数据value分离成一个数组,每个线程访问时通过哈希系统算法映射到其中一个数字进行计数,而最终的计数结果则为这个数组的求和累加,其中热点数据value它会被分离成多个单元的cell,每个cell独自维护内部的值,当前对象的实际值由所有的cell累计合成,这样的话热点就进行了有效的分离并提高了并行度,这样一来呢LongAdder它相当于是在AtomicLong的基础上将单点的更新压力分散到各个节点上,在第一并发的时候呢通过对base的直接更新,可以很好的保障和Atomic的性能基本一致,而在高并发的时候呢则通过分散提高了性能,这就是我们所说的LongAdder,但是LongAdder也有自己的缺陷,它的缺点是在统计的时候如果有并发更新,可能会导致统计的数据有些误差。实际使用中,在处理高并发计数的时候,我们可以优先使用LongAdder,而不是继续使用AtomicLong,当然了在线程竞争很低的情况下进行计数,使用Atomic还是更简单、更直接一些,并且效率也会稍微高一点点。其他的情况下,比如序列号生成啦,这种情况下需要准确的数值,全局唯一的AtomicLong才是正确的选择,这个时候就不适合使用LongAdder了。
因此我们这个线程安全了是没问题了。为什么有了AtomicLong之后还要新增一个LongAdder这个类?很显然如果增加一个类肯定是有它的优点的。这里LongAdder它的实现我们就不多说了,我们具体说一下LongAdder和AtomicLong它俩对应的优点和缺点。之前我们在讲AtomicInteger的实现机制的时候我们看过CAS的底层实现,它们是在一个死循环内不断地尝试修改目标值直到修改成功。如果竞争不激烈的时候呢,它修改成功的概率很高,否则的话修改失败的概率就会很高,在大量修改失败的时候呢,这些原子操作就会进行多次的循环尝试,因此呢性能会受到一些影响。这里呢有一个知识点,对于普通类型的long和double变量,JVM允许将64位的读操作或者写操作拆成两个32位的操作,那么LongAdder这个类它的实现是基于什么思想呢?它的核心是将热点索引分离,比如说它可以将AtomicLong的内部核心数据value分离成一个数组,每个线程访问时通过哈希系统算法映射到其中一个数字进行计数,而最终的计数结果则为这个数组的求和累加,其中热点数据value它会被分离成多个单元的cell,每个cell独自维护内部的值,当前对象的实际值由所有的cell累计合成,这样的话热点就进行了有效的分离并提高了并行度,这样一来呢LongAdder它相当于是在AtomicLong的基础上将单点的更新压力分散到各个节点上,在第一并发的时候呢通过对base的直接更新,可以很好的保障和Atomic的性能基本一致,而在高并发的时候呢则通过分散提高了性能,这就是我们所说的LongAdder,但是LongAdder也有自己的缺陷,它的缺点是在统计的时候如果有并发更新,可能会导致统计的数据有些误差。实际使用中,在处理高并发计数的时候,我们可以优先使用LongAdder,而不是继续使用AtomicLong,当然了在线程竞争很低的情况下进行计数,使用Atomic还是更简单、更直接一些,并且效率也会稍微高一点点。其他的情况下,比如序列号生成啦,这种情况下需要准确的数值,全局唯一的AtomicLong才是正确的选择,这个时候就不适合使用LongAdder了。
com.mmall.concurrency.example.atomic.AtomicExample3
C:\Users\ZHONGZHENHUA\imooc\concurrency\src\main\java\com\mmall\concurrency\example\atomic\AtomicExample3.java
package com.mmall.concurrency.example.atomic; import com.mmall.concurrency.annoations.ThreadSafe; import lombok.extern.slf4j.Slf4j; import java.util.concurrent.CountDownLatch; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.Semaphore; import java.util.concurrent.atomic.AtomicLong; import java.util.concurrent.atomic.LongAdder; @Slf4j @ThreadSafe public class AtomicExample3 { // 请求总数 public static int clientTotal = 5000;//1000个请求 // 同时并发执行的线程数 public static int threadTotal = 200;//允许并发的线程数是50 public static LongAdder count = new LongAdder(); public static void main(String[] args) throws Exception { ExecutorService executorService = Executors.newCachedThreadPool(); final Semaphore semaphore = new Semaphore(threadTotal); final CountDownLatch countDownLatch = new CountDownLatch(clientTotal); for (int i = 0; i < clientTotal; i++) { executorService.execute(()-> { try { semaphore.acquire(); add(); semaphore.release(); } catch (Exception e) { log.error("exception",e); } countDownLatch.countDown(); }); } countDownLatch.await(); executorService.shutdown(); log.info("count:{}",count); //log.info("count:{}",count.get()); } private static void add() { //count++; count.increment(); //count.incrementAndGet(); // count.getAndIncrement(); } }
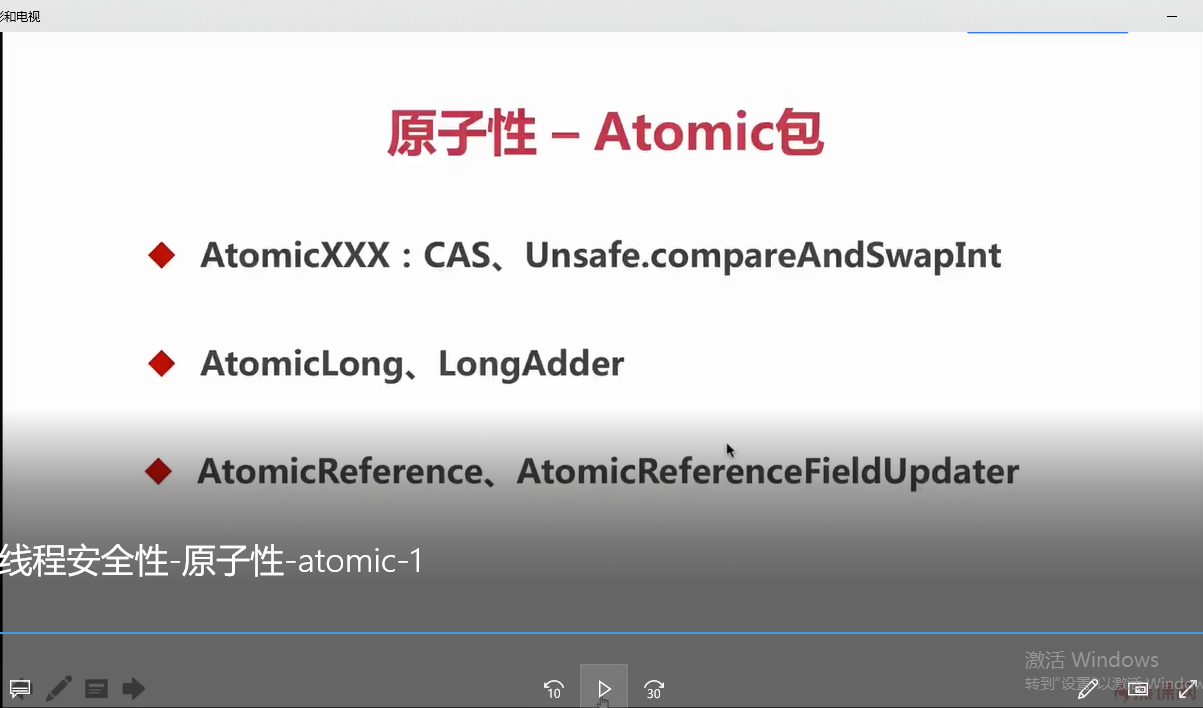
AtomicLong我们就暂时先介绍到这里,现在呢我们来看一下Atomic包。


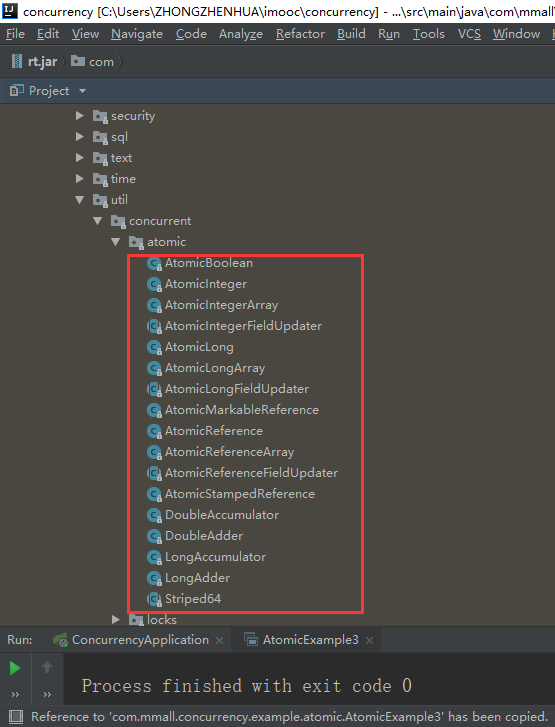 这是JDK里面默认提供好的包,这个包里面我们可以看到我们平时用的一些基本类型,什么布尔类型啦整型啦Long型都有对应的原子相关的类,这里除了compareAndSwapInt这个函数还有一个函数compareAndSet需要大家注意一下,这个方法/函数更多的用在于AtomicBoolean这个类里面。为什么这么说呢?实际中我们经常会遇到比如我希望某件事情只执行一次,在执行这件事情之前呢它的标记可能为false,一旦执行之后我就要把它变成true。这个时候呢如果我们使用AtomicBoolean这个类里面的compareAndSet方法,分别传入false、true的时候呢,就可以保证对应我们要控制的那一段代码只执行一次,甚至可以理解为当前只有一个线程可以执行这段代码。如果我们在执行完之后再把这个变量标识为false之后,当然它可以继续执行。这样它达到的效果就是,同样的代码、同一时间只有一个线程可以执行。
这是JDK里面默认提供好的包,这个包里面我们可以看到我们平时用的一些基本类型,什么布尔类型啦整型啦Long型都有对应的原子相关的类,这里除了compareAndSwapInt这个函数还有一个函数compareAndSet需要大家注意一下,这个方法/函数更多的用在于AtomicBoolean这个类里面。为什么这么说呢?实际中我们经常会遇到比如我希望某件事情只执行一次,在执行这件事情之前呢它的标记可能为false,一旦执行之后我就要把它变成true。这个时候呢如果我们使用AtomicBoolean这个类里面的compareAndSet方法,分别传入false、true的时候呢,就可以保证对应我们要控制的那一段代码只执行一次,甚至可以理解为当前只有一个线程可以执行这段代码。如果我们在执行完之后再把这个变量标识为false之后,当然它可以继续执行。这样它达到的效果就是,同样的代码、同一时间只有一个线程可以执行。