06 Spark SQL 及其DataFrame的基本操作
1.Spark SQL出现的 原因是什么?
sparkSQL的前身是shark。在hadoop发展过程当中,为了给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,hive应运而生,是当时惟一运行在hadoop上的SQL-on-Hadoop工具。
sparkSQL做为Spark生态的一员继续发展,而再也不受限于hive,只是兼容hive;SparkSQL产生的根本原因是为了完全脱离Hive限制(解耦)
优化: sparkSQL的表数据在内存中存储不是采用原生态的JVM对象存储方式,而是采用内存列存储;字节码生成技术(bytecode generation,即CG);scala代码优化。
2.用spark.read 创建DataFrame
3.观察从不同类型文件创建DataFrame有什么异同?
4.观察Spark的DataFrame与Python pandas的DataFrame有什么异同?

Spark SQL DataFrame的基本操作
spark.read.text()
file='file:///usr/local/spark/examples/src/main/resources/people.txt'
df=spark.read.text(file)

spark.read.json()
file='file:///usr/local/spark/examples/src/main/resources/people.json'
df1=spark.read.json(file)

打印数据
df.show()默认打印前20条数据,df.show(n)
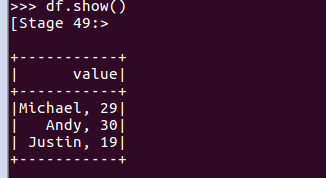

打印概要
df.printSchema()
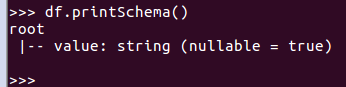
df1.printSchema()
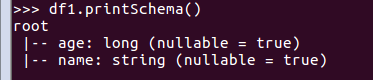
查询总行数
df.count()
df1.count()

df.head(3) #list类型,list中每个元素是Row类
df.head(3)
df1.head(3)

输出全部行
df.collect() #list类型,list中每个元素是Row类
df.collect()
df1.collect()

查询概况
df.describe().show()

df1.describe().show()

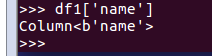
取列
df[‘name’]
df1['name']
df.name
df1.name

df.select()
df1.select(df1.name).show()

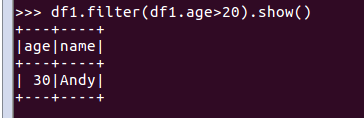
df.filter()
df1.filter(df1.age>20).show()
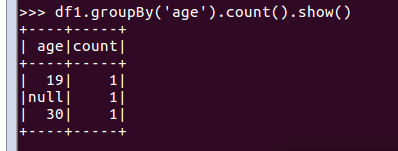
df.groupBy()
df1.groupBy('age').count().show()
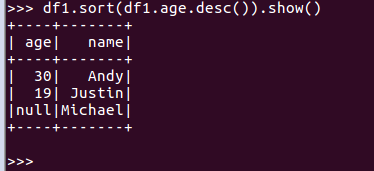
df.sort()
df1.sort(df1.age.desc()).show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号