
后缀数组
对于后缀有关的东西,本人一无所知。
如果你点击进来这博客,那请你谨慎阅读。
本菜鸡在开开心心刷沈大佬给我拉的铜牌题专题的时候,突然遇到了一到后缀自动机的题,不过,我完全不会。上网搜索资料的时候,我看到了后缀数组,后缀自动机,后缀树这几个东西,我也不知道他们是干什么的,也不知道他们的难度如何,于是就找了一个看起来最简单的来学一下。
此博客会基于挑战,谈一些自己现在的理解。由于是本菜鸡的初步理解,再次重申,请谨慎阅读!!
所谓后缀数组,就是先拿到某个数组的所有后缀,给他们加上一个标号id,再将他们排个序,最后得到id的序列就是后缀数组。
请大家看一下我的暴力代码:
#include<iostream>
#include<algorithm>
#include<string>
using namespace std;
string s;
const int maxn = 10086;
struct node
{
string ss;
int id;
}sa[maxn];
bool cmp(node x,node y)
{
return x.ss<y.ss;
}
int main()
{
ios::sync_with_stdio(false);
cin>>s;
int l=s.length();
for(int i=l-1;i>=0;i--){
sa[i].ss=sa[i+1].ss;
sa[i].ss.insert(sa[i].ss.begin(),s[i]);//得到后缀
sa[i].id=i;//打上标号
}
sort(sa,sa+l,cmp);//根据后缀排序
//最后,id顺序就是后缀数组的内容
for(int i=0;i<l;i++){
cout<<sa[i].id<<" ";
}
cout<<endl;
return 0;
}
这样的暴力时间复杂度取决于string的插入操作,其他的地方就只有一个sort有n2log(n)的复杂度(字符串比对的复杂度是O(n) ),本菜鸡并不知道string的复杂度是多少,不过据我分析,应该是n2的。
就此而言,整个算法的时间复杂度就应该是n2log(n)的。
所以,挑战上给我们介绍了一种nlog2n的算法。
整个算法的过程挑战已经说得非常清楚了,在P378.所以我会再次讲解一下他的代码。
一下代码是一个一个字直接打出来,但愿我没有抄错,不过测了一点数据,和暴力的输出是一样的。
所有的解释都在注释里面,如果有解释不清楚的,可以留言一下.
#include<iostream> #include<algorithm> #include<string> using namespace std; const int maxn = 100086; int n,k; int Rank[maxn+1];//记录下长度为k的子串的相对大小 int tmp[maxn+1]; int sa[maxn];//后缀数组 string S; void view() { for(int i=0;i<=S.length();i++){ printf("%d ",sa[i]); } printf("\n"); } //长度为k时,对sa进行比较 //如果Rank[i]!=Rank[j],那说明在前半段,s[i..]就比s[j..]大. //如果相等,就比较后半段. bool compare_sa(int i,int j) { if(Rank[i]!=Rank[j]){return Rank[i]<Rank[j];} //如果以i开始,长度为k的字符串的长度,已经超出了字符串尾,那么就赋值为-1 //这是因为,在前面所有数据相同的情况下,字符串短的字典序小. int ri = i+k<=n?Rank[i+k]:-1; int rj = j+k<=n?Rank[j+k]:-1; return ri<rj; } int construct_sa() { n=S.length(); //初始的RANK为字符的ASCII码 for(int i=0;i<=n;i++){ sa[i]=i; Rank[i]=i<n?S[i]:-1; } for(k=1;k<=n;k*=2){ sort(sa,sa+n+1,compare_sa); tmp[sa[0]]=0; //全新版本的RANK,tmp用来计算新的rank //将字典序最小的后缀rank计为0 //sa之中表示的后缀都是有序的,所以将下一个后缀与前一个后缀比较,如果大于前一个后缀,rank就比前一个加一. //否则就和前一个相等. for(int i=1;i<=n;i++){ tmp[sa[i]]=tmp[sa[i-1]]+(compare_sa(sa[i-1],sa[i])?1:0); } for(int i=0;i<=n;i++){ Rank[i]=tmp[i]; } } } int main(){ construct_sa(); view(); return 0; } /* abracadabra */
这样的话,我们才刚刚完成了后缀数组的构建,但是目前还是非常迷茫,这个东西究竟有什么用?
然后我们接下来看下这个基于后缀数组的字符串匹配.
先告知各位,compare的用法.
s.compare(sa[c],t.length(),t)
这句话就是说,将s串中,从sa[c]开始的,长度为t.length()的子串,与t做比较.
话不多说,先上裸题休闲一下.
http://csustacm.com:4803/problem/1026
这题可用KMP,Hash等一系列算法过,不过我这里使用后缀数组.
int contain(string s,string t)//求子串个数 { int a=0,b=s.length(),c; int l=b; while(b-a>1){ c=(a+b)/2; if(s.compare(sa[c],t.length(),t)<0)a=c; else b=c; } int ans = 0; for(int i=b;i>=0;i--){ if(s.compare(sa[i],t.length(),t)==0){ans++;} else break; } for(int i=b+1;i<=l;i++){ if(s.compare(sa[i],t.length(),t)==0){ans++;} else break; } return ans; // return s.compare(sa[b],t.length(),t)==0; }
这里就是有关匹配的代码,在二分结束之后,b的位置就是可能是子串的位置,由于后缀数组是有序的,所以只要在前后找一下,就可以知道有多少个子串了.
挑战上的代码只是判断了子串存不存在.
不过,在这一题上面,后缀数组确实没什么优势.
KMP:
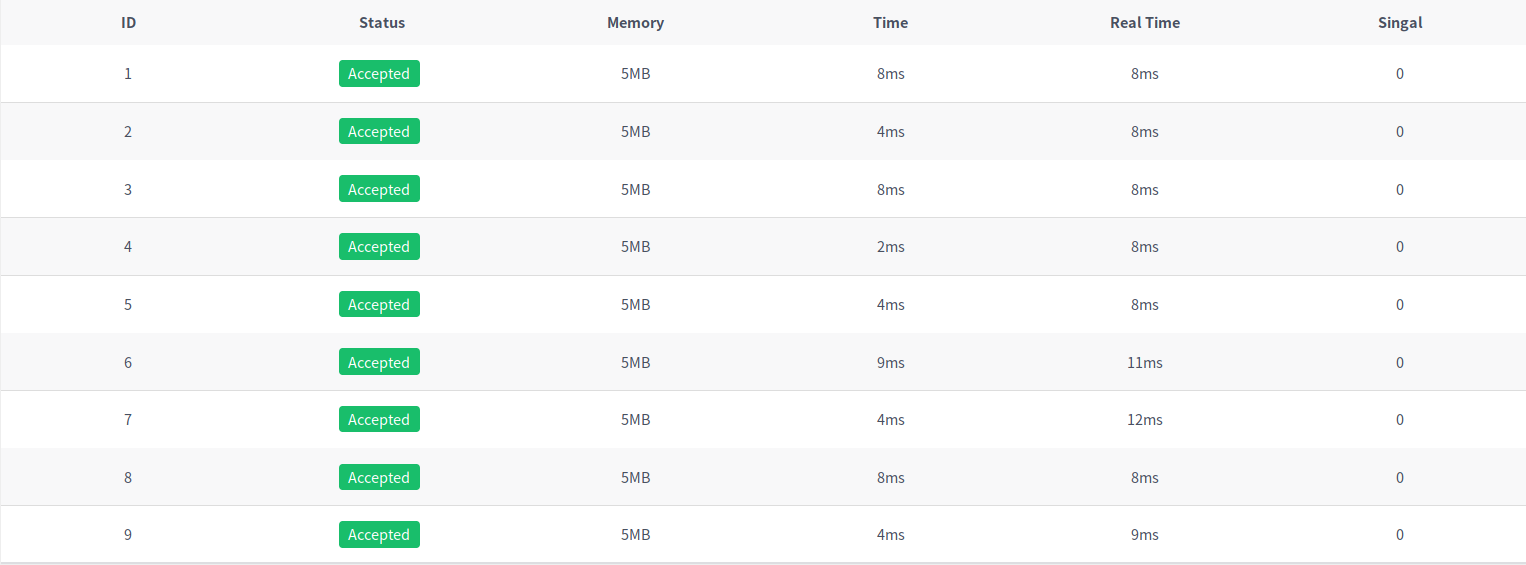
后缀数组:

当然问题可能出在:
1.string的天生劣势.
2.本人的写法过于暴力.
本人稍后会去观察一下别人的博客,然后看看能不能优化一下.
如有侵权,联系删除
2290713181@qq.com

