Map接口的实现类
HashMap
LinkedHashMap
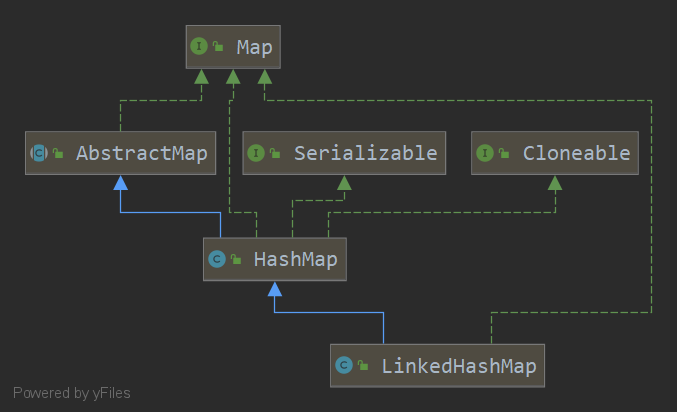
LinkedHashMap是HashMap的子类,实际上它连HashMap的putVal等方法都没有重写,因为HashMap就调用了预留给子类的函数,在HashMap中是空实现,在LinkedHashMap中重写,用作建立双向链表
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
这是LinkedHashMap中的一个类,结合上方信息可看出,LinkedHashMap并没有修改HashMap的数据结构,只是在HashMap的基础上添加了两个元素
newNode方法是putVal中调用的,生成节点的方法,在linkedHashMap也被重写了
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
可以看到,一旦有新元素,那么它就会被放在链表的结尾,那么,如果有修改元素的情况出现呢
在putVal中有这样一段
其中afterNodeAccess在HashMap是空实现,在LinkedHashMap中被重写
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
实际上,afterNodeAccess这个方法的就是,将被修改的类置于链表末尾
void afterNodeAccess(HashMap.Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
Hashtable
Hashtable确实老了,从jdk1.0开始,Hashtable就已经出现了.它甚至都没有按照驼峰命名法来命名
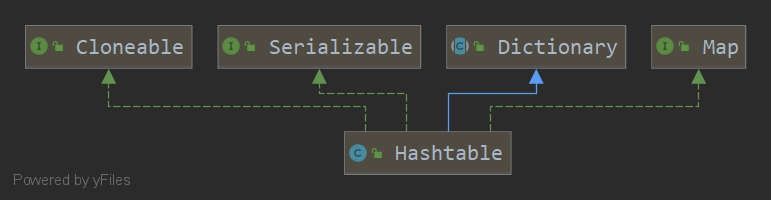
一般说来,大家都知道Hashtable和HashMap的区别就在于,Hashtable线程安全,而HashMap线程不安全,但是差距肯定不止于此
由于Iterate和Map出现得比较晚,所以Hashtable没有使用这两个东西,看他独特的继承树,就知道它是版本弃子.
如果jdk开发人员没有放弃这个类,完全可以完全重写它.
即使Hashtable线程安全,但是在使用多线程时,还是建议使用Map的同步代理类,说明Hashtable可以完全被遗弃了.
在功能方面,Hashtable不允许空值
if (value == null) {
throw new NullPointerException();
}
这是Hashtable的put中第一句
在这里有杜绝了key为null的可能
int hash = key.hashCode();
那么HashMap是怎么处理的呢?
首先HashMap没有特别判断value为空的情况
而hashMap的key的hash值是这么计算的:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
我看了一下,Hashtable既没有扰乱hash值的操作,也没有红黑树,也没有位运算优化...
还有一些方法功能上的差别,不细说了
TreeMap
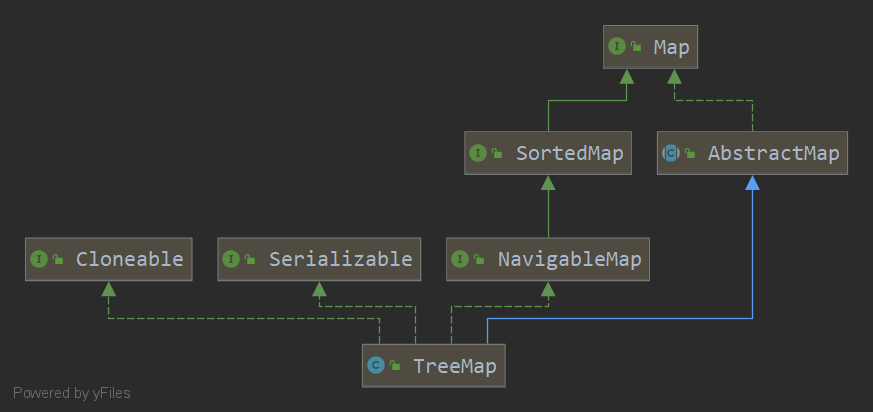
要使用这个类,不需要重写hashcode方法与equals方法,但是Key一定要实现Compareble接口或者在创建TreeMap时,传入一个Compartor的实现类
TreeMap会优先使用Comparator
TreeMap内部直接是一个红黑树,所以,内部的Key是有序的,要想查找Key的最大最小值都比较容易
但是,如何进行遍历呢?
当然想都不用想,用递归实现树的前序遍历可以做到,但是,用户调用Iterate的next方法的时候,树里面的值可不是全部直接出来了
显然这里不能使用递归
首先要知道,在调用Iterate的构造器时,指针就已经指向了数中的最小值
//这个方法用于确定t的下一个元素
static <K,V> TreeMap.Entry<K,V> successor(Entry<K,V> t) {
if (t == null)
return null;
右侧不为空,往右侧走一步,接着找到右子树的最小值
else if (t.right != null) {
Entry<K,V> p = t.right;
while (p.left != null)
p = p.left;
return p;
} else {
//parent这个属性就是去掉递归的核心
Entry<K,V> p = t.parent;
Entry<K,V> ch = t;
while (p != null && ch == p.right) {
ch = p;
p = p.parent;
}
return p;
}
}
当然相关方法和HashMap也有区别,能写出红黑树的话就差不多能看懂了
ConcurrentHashMap
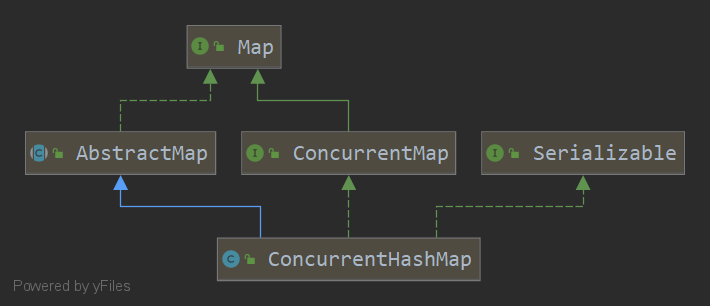
这个类是线程同步的,不支持null
实际上它的做法就是在table数组上每一个散列位置上加锁,而不是像Hashtable那样吧整张表给锁了
显而易见,如果要用到多线程,一定要深入了解这个类
但是目前我对sun.misc.Unsafe的了解还不够,而这个类中用到了它,所以无法对源码进行跟深入的分析
以后再回头单开一个博客介绍一下这个类吧,同学们一定要搞清楚这个类呀
如有侵权,联系删除
2290713181@qq.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号