利用python3 爬虫 定制版妹子图mzitu爬取
在刚开始学爬虫的时候,用来练手的基础爬虫就是爬取各种妹子图片,前几天同时说了这个,便准备随便写一个。。。最后发现真是三天不练。。什么都记不住了!!所以花了政治一天重新写了一个爬虫程序,并且支持按照时间(自己选择)来爬取图片!
程序里面用到的库有requests bs4 re
爬虫地址入口:http://www.mzitu.com/all
在程序设计上,我想要用户手动输入爬取的时间!比如 2018 06
好了思路理顺了,就开始程序设计吧!首先我们登陆首页 查看观察页面!(利用谷歌的F12)

我们发现了有两个重要的点!第一 这里面需要cookie 第二 host 为 www.mzitu.com !这里很容易里面,cookie就是我们登陆首页(www.mzitu.com)生成的!
第一步:登陆首页获取cookie!!!
我们在首页用同样的方法查看12 看里面的request headers!!!然后我们模仿这个headers发送请求,然后用requests方法来获取cookie并且记录下来以供以后使用!
def __init__(self): url="http://www.mzitu.com/" headers={ 'Accept': 'text / html, application / xhtml + xml, application / xml;q = 0.9, image / webp, image / apng, * / *;q = 0.8', 'Accept - Encoding': 'gzip, deflate', 'Accept - Language': 'zh - CN, zh;q = 0.9', 'Cache - Control': 'max - age = 0', 'Host': 'www.mzitu.com', 'Upgrade - Insecure - Requests': '1', 'User - Agent': 'Mozilla / 5.0(Windows NT 10.0;WOW64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 66.0.3359.117 Safari / 537.36' } html = requests.get(url, headers=headers) cookies=str(html.cookies.get_dict()) # print(cookies)
第二步:获取用户输入的年月的所有图片的url
这一步是整个程序的重点!我们在http://www.mzitu.com/all 这个页面发现了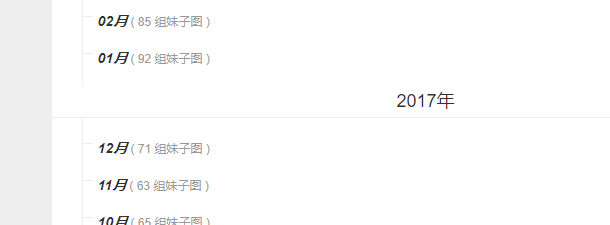 这里面的图片是按照时间来分类的,所以我们想要按照时间来分类的话就先分析源码里面的逻辑:
这里面的图片是按照时间来分类的,所以我们想要按照时间来分类的话就先分析源码里面的逻辑:
我们发现年份是在div标签属性为main-content之下!!!而月份图片在p标签 下面的em标签下面
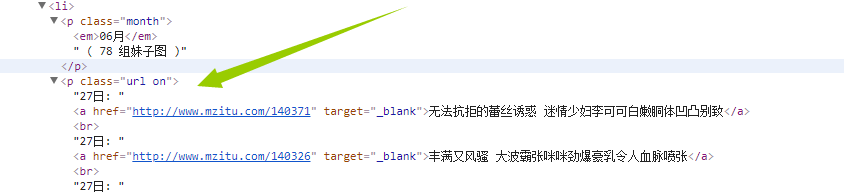
而我们需要的url是在p标签属性为url on下面!!!!
这里我想了很久,最终选择了父子,兄弟标签的方法来解决!!
url="http://www.mzitu.com/all/" headers={ 'Accept': 'text / html, application / xhtml + xml, application / xml;q = 0.9, image / webp, image / apng, * / *;q = 0.8', 'Accept - Encoding': 'gzip, deflate', 'Accept - Language': 'zh - CN, zh;q = 0.9', 'Cache - Control': 'max - age = 0', 'Cookie':cookies , 'Host': 'www.mzitu.com', 'Upgrade - Insecure - Requests': '1', 'User - Agent': 'Mozilla / 5.0(Windows NT 10.0;WOW64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 66.0.3359.117 Safari / 537.36' } html = requests.get(url, headers=headers) years=input("请输入您想要爬去的年份: ") month=input("请输入您想要爬去的月份: ") month1=str(month)+"月" soup = BeautifulSoup(html.text,'lxml') all=soup.find('div',text=re.compile(years)) all1=all.next_sibling test=all1.find('em',text=re.compile(month1)) ##获取包含月份的父节点 parent=test.parent #获取每个月的数据,也就是上一个标签的兄弟标签 allpic=parent.next_sibling #获取每个图片的url allurllist=[] for url1 in allpic.find_all('a', href=True): if url1.get_text(strip=True): print(type(url1['href'])) allurllist.append(str(url1['href'])) #这里就获取了全部的url,列表形式,以逗号分隔 # self.getallpic(strall4) self.getallpic(allurllist,cookies)
上面这一段代码详解!
这里面需要特别注意
for url1 in allpic.find_all('a', href=True): if url1.get_text(strip=True): print(type(url1['href'])) allurllist.append(str(url1['href']))
目的是为了获取所有的url href=True的意思是寻找所有满足有herf的a标签
然后判断if
url1.get_text(strip=True): 如果这个标签里面的内容不为空【strip=True的意思是过滤掉文本内容的前后空白】, 那么通过url1['href']来获取href具体属性内容!!
当然也可以通过正则表达式来处理
month1=str(month)+"月" 这段代码是用户输入06 需要转换为06月 因为源码里面是06月
soup = BeautifulSoup(html.text,'lxml')
all=soup.find('div',text=re.compile(years)) 这两端代码利用bs来找到了输入的年份所在的那个标签!!!注意这里的返回值是一个bs类,也就是我们还可以继续对这个类使用bs里面的任何方法!!!
all1=all.next_sibling
test=all1.find('em',text=re.compile(month1))这两段代码实现了通过年份标签来找到月份标签(这里千万别走偏了!!寻找这个标签的目的其实是为了寻找我们需要的url)
parent=test.parent
allpic=parent.next_sibling 这两段代码就实现了找到需要的url!!通过找月份标签的兄弟标签!
第三步:保存图片
我们拿一个图片的url举例:http://www.mzitu.com/139042/7
我们发现进入到图片系列之后!!!发现图片不止一张!!

我们当然不能只爬取一页!那么怎么获取这个图片一共多少页呢?

看这里!!我们还是老办法!通过找到下页面这个标签的上一个标签的内容就行了!代码如下
html = requests.session().get(i,headers=headers) soup = BeautifulSoup(html.text, 'lxml') all = soup.find('span', text=re.compile("下一页")) #找到下一页的父标签 parent = all.parent #获取上一级标签,也就是含有最大页面的标签 allpic = parent.previous_sibling maxyema=allpic.find('span').get_text()
这里的i是一个循环 也就是我们上一步获取的url!
拿到最大页码之后 我们需要对这个url的每一页遍历
for p in range(1,int(maxyema)+1): url=str(i)+"/"+str(p) self.downloadpict(p,url,headers)
然后我们定义数据存储函数
def downloadpict(self,yema,url,headers): #加载每一个页面 html = requests.session().get(url, headers=headers) soup = BeautifulSoup(html.text, 'lxml') picture = soup.find('div', class_="main-image") picture = str(picture) # 获取每张图片的url pattern = re.compile(r'src="(.*?)"/.*', re.S) picturl = pattern.findall(picture) #匹配名称为后面的命令打基础 namepattern = re.compile(r'alt="(.*?)" src.*',re.S) name1=str(namepattern.findall(picture)).replace('"','').replace("[","").replace("]","")[0:5] # picture=requests.get(str(picturl[0]),headers=headers) headers = { 'Accept': 'text / html, application / xhtml + xml, application / xml;q = 0.9, image / webp, image / apng, * / *;q = 0.8', 'Accept - Encoding': 'gzip, deflate', 'Accept - Language': 'zh - CN, zh;q = 0.9', 'Cache - Control': 'max - age = 0', 'Connection': 'keep - alive', 'Host': 'i.meizitu.net ', # 'Referer': 'http://www.mzitu.com/139042/7', 'Referer': 'http://www.mzitu.com/', 'Upgrade - Insecure - Requests': '1', 'User - Agent': 'Mozilla / 5.0(Windows NT 10.0; WOW64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 66.0.3359.117 Safari / 537.36' } picture = requests.get(picturl[0], headers=headers) print("正在爬取"+name1+str(yema)+".jpg") # print(picture) with open('picture'+name1+str(yema)+'.jpg', 'wb') as file: file.write(picture.content) file.close() print("正在爬取" + name1 + str(yema) + ".jpg"+"成功") # 已经获取了最大页面接下来开始爬取数据
我们大致的思路是 A 函数 获取cookieA B函数通过用户输入的时间利用正则已经BS来寻找到基础URL C函数根据基础URL来获取每个URL的最大页面 D函数获取每个图片并且存储
A-->调用B-->调用C-->调用D
这里面需要主要的是在存储阶段,也就是下载图片的时候需要观察页面!重新生成cookie!!!不能用前面的cookie
最后我们直接把全部代码放上来:
import requests from bs4 import BeautifulSoup import re import os class getmeizitu(): def __init__(self): url="http://www.mzitu.com/" headers={ 'Accept': 'text / html, application / xhtml + xml, application / xml;q = 0.9, image / webp, image / apng, * / *;q = 0.8', 'Accept - Encoding': 'gzip, deflate', 'Accept - Language': 'zh - CN, zh;q = 0.9', 'Cache - Control': 'max - age = 0', 'Host': 'www.mzitu.com', 'Upgrade - Insecure - Requests': '1', 'User - Agent': 'Mozilla / 5.0(Windows NT 10.0;WOW64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 66.0.3359.117 Safari / 537.36' } html = requests.get(url, headers=headers) cookies=str(html.cookies.get_dict()) # print(cookies) self.getall(cookies) def getall(self,cookies): url="http://www.mzitu.com/all/" headers={ 'Accept': 'text / html, application / xhtml + xml, application / xml;q = 0.9, image / webp, image / apng, * / *;q = 0.8', 'Accept - Encoding': 'gzip, deflate', 'Accept - Language': 'zh - CN, zh;q = 0.9', 'Cache - Control': 'max - age = 0', 'Cookie':cookies , 'Host': 'www.mzitu.com', 'Upgrade - Insecure - Requests': '1', 'User - Agent': 'Mozilla / 5.0(Windows NT 10.0;WOW64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 66.0.3359.117 Safari / 537.36' } html = requests.get(url, headers=headers) # print(html.text) years=input("请输入您想要爬去的年份: ") month=input("请输入您想要爬去的月份: ") month1=str(month)+"月" soup = BeautifulSoup(html.text,'lxml') # print(soup.name) all=soup.find('div',text=re.compile(years)) all1=all.next_sibling # print(all1) test=all1.find('em',text=re.compile(month1)) ##获取包含月份的父节点 parent=test.parent #获取每个月的数据,也就是上一个标签的兄弟标签 allpic=parent.next_sibling #获取每个图片的url # print(type(allpic)) # for i in (allpic): allurllist=[] for url1 in allpic.find_all('a', href=True): if url1.get_text(strip=True): print(type(url1['href'])) allurllist.append(str(url1['href'])) #这里就获取了全部的url,列表形式,以逗号分隔 # self.getallpic(strall4) self.getallpic(allurllist,cookies) def getallpic(self,url,cookies): for i in url: headers = { 'Accept': 'text / html, application / xhtml + xml, application / xml;q = 0.9, image / webp, image / apng, * / *;q = 0.8', 'Accept - Encoding': 'gzip, deflate', 'Accept - Language': 'zh - CN, zh;q = 0.9', 'Cache - Control': 'max - age = 0', 'Connection': 'keep - alive', 'Cookie': cookies, 'Host': 'www.mzitu.com', # 'If - Modified - Since': 'Tue, 26 Jun 2018 05: 26:18 GMT', 'Upgrade - Insecure - Requests': '1', 'User - Agent': 'Mozilla / 5.0(Windows NT 10.0; WOW64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 66.0.3359.117 Safari / 537.36' } html = requests.session().get(i,headers=headers) soup = BeautifulSoup(html.text, 'lxml') all = soup.find('span', text=re.compile("下一页")) #找到下一页的父标签 parent = all.parent #获取上一级标签,也就是含有最大页面的标签 allpic = parent.previous_sibling maxyema=allpic.find('span').get_text() #获取了最大页面之后循环获取每一页 for p in range(1,int(maxyema)+1): url=str(i)+"/"+str(p) self.downloadpict(p,url,headers) def downloadpict(self,yema,url,headers): #加载每一个页面 html = requests.session().get(url, headers=headers) soup = BeautifulSoup(html.text, 'lxml') picture = soup.find('div', class_="main-image") picture = str(picture) # 获取每张图片的url pattern = re.compile(r'src="(.*?)"/.*', re.S) picturl = pattern.findall(picture) #匹配名称为后面的命令打基础 namepattern = re.compile(r'alt="(.*?)" src.*',re.S) name1=str(namepattern.findall(picture)).replace('"','').replace("[","").replace("]","")[0:5] # picture=requests.get(str(picturl[0]),headers=headers) headers = { 'Accept': 'text / html, application / xhtml + xml, application / xml;q = 0.9, image / webp, image / apng, * / *;q = 0.8', 'Accept - Encoding': 'gzip, deflate', 'Accept - Language': 'zh - CN, zh;q = 0.9', 'Cache - Control': 'max - age = 0', 'Connection': 'keep - alive', 'Host': 'i.meizitu.net ', # 'Referer': 'http://www.mzitu.com/139042/7', 'Referer': 'http://www.mzitu.com/', 'Upgrade - Insecure - Requests': '1', 'User - Agent': 'Mozilla / 5.0(Windows NT 10.0; WOW64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 66.0.3359.117 Safari / 537.36' } print("正在爬取崔潜喜欢的"+name1+str(yema)+".jpg") try: pwd=os.getcwd() picture = requests.get(picturl[0], headers=headers) # print(picture) isExists = os.path.exists(name1) # 判断结果 if not isExists: # 如果不存在则创建目录 # 创建目录操作函数 os.makedirs(name1) os.chdir(name1) with open(""+'picture'+name1+str(yema)+'.jpg', 'wb') as file: file.write(picture.content) file.close() os.chdir(pwd) except Exception as e: print("有异常,异常如下\n %s:" %e) else: print("爬取崔潜喜欢的" + name1 + str(yema) + ".jpg"+"成功") # 已经获取了最大页面接下来开始爬取数据 cuiqian=getmeizitu()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号