记一次 hadoop does not have enough number of replicas问题处理
背景 凌晨hadoop任务大量出现 does not have enough number of replicas
集群版本 cdh5.13.3 hadoop2.6.0
首先百度 大部分人建议 dfs.client.block.write.locateFollowingBlock.retries = 10 大部分人给出的意见是因为cpu不足,具体都是copy别人的,因为我们的namenodecpu才用3%,所以我猜测他们的意思是客户端cpu跑完了(我们的客户端cpu用的还真的高)。 网上文章的意思是客户端cpu不足导致客户端上报到namenode有延时,超过了namenode的等待时间时间,所以报错。 因为我们是生产环境,所以等待晚上重启看效果。
第二天凌晨被电话吵醒,发现还是有很多同样的报错
这次不再盲目相信网上了,直接看日志(实际上花了差不多四天 包括向售后提case)
第一步 namenode 日志
2021-09-28 15:31:18,008 INFO org.apache.hadoop.hdfs.StateChange: BLOCK* allocateBlock: /user/hive/warehouse/stg.db/stg_erp_sal_bgy_order_head/part_date=20210928__ffbd3cf3_670b_4897_a885_5e8b1382f8dc/stg_erp_sal_bgy_order_head_data__5e6d17b5_98e0_471c_b58e_8a878bbfbf99. BP-1938937130-10.8.22.2-1516416995387 blk_2136776575_1063083777
以上详解
BLOCK* allocateBlock: 表示在申请block
BP-1938937130-10.8.22.2-1516416995387 这个是namenode的唯一标识 写在VERSION里面
/data/dfs/nn/current/VERSION
blk_2136776575_1063083777这个表示这个块的名称
UNDER_CONSTRUCTION:数据块处于构建阶段状态下。它最近被分配,用于write或appendUNDER_CONSTRUCTION状态下,文件刚刚被create,或者正在被append,此时的数据块正在被持续的写入,其大小和时间戳都是可以更改的,但是这种状态的下的数据块对于读是可见的,具体能读多少则是由客户端询问DataNode得知的,该block的所有副本replica接收到的数据大小都会大于等于这个可读的数据大小,这样,才能保证所有的副本replica均可用
从上面可以看出数据的写入顺序
10.8.22.17 ----->10.8.56.9----> 10.8.22.46
第二步 找到日志里面的第一台机器10.8.22.17 可以看到日志
2021-09-28 15:31:18,013 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving BP-1938937130-10.8.22.2-1516416995387:blk_2136776575_1063083777 src: /10.8.22.17:48703dest: /10.8.22.17:1004
2021-09-28 15:31:19,285 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /10.8.22.17:48703, dest: /10.8.22.17:1004, bytes: 62851, op: HDFS_WRITE, cliID:DFSClient_NONMAPREDUCE_-424249781_105, offset: 0, srvID: 2efdedb9-c953-46f7-b70b-7dfc402e138d, blockid: BP-1938937130-10.8.22.2-1516416995387:blk_2136776575_1063083777, duration: 377335230
2021-09-28 15:31:19,285 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder: BP-1938937130-10.8.22.2-1516416995387:blk_2136776575_1063083777, type=HAS_DOWNSTREAM_IN_PIPELINE terminating
以上详解
src: /10.8.22.17:48703, dest: /10.8.22.17:1004
表示客户端是22.17 目标端也是22.17(namenode 选定的)
type=HAS_DOWNSTREAM_IN_PIPELINE terminating
这里表示这个块数据写入完成 继续写入下一台机器(数据写入是串行的A-->B--->C)
10.8.56.9 日志相同 不详细写
第三步 看10.8.22.46的日志
2021-09-28 15:31:18,467 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving BP-1938937130-10.8.22.2-1516416995387:blk_2136776575_1063083777 src: /10.8.56.9:57488 dest: /10.8.22.46:1004
2021-09-28 15:31:18,798 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /10.8.56.9:57488, dest: /10.8.22.46:1004, bytes: 62851, op: HDFS_WRITE, cliID: DFSClient_NONMAPREDUCE_-424249781_105, offset: 0, srvID: eefc5ad9-3e92-4640-99a9-7c4c5a4a27de, blockid: BP-1938937130-10.8.22.2-1516416995387:blk_2136776575_1063083777, duration: 14511253
2021-09-28 15:31:18,798 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder: BP-1938937130-10.8.22.2-1516416995387:blk_2136776575_1063083777, type=LAST_IN_PIPELINE, downstreams=0:[] terminating
这里没什么不同 只有type=LAST_IN_PIPELINE 表示这是最后一个块儿了,他完成就可以向NAMENODE汇报写入完成了
第四步 继续看10.8.22.46的日志
2021-09-28 15:31:52,723 INFO org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetAsyncDiskService: Scheduling blk_2136776575_1063083777 file /data2/dfs/dn/current/BP-1938937130-10.8.22.2-1516416995387/current/finalized/subdir92/subdir159/blk_2136776575 for deletion
2021-09-28 15:31:52,740 INFO org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetAsyncDiskService: Deleted BP-1938937130-10.8.22.2-1516416995387 blk_2136775295_1063082497 file /data1/dfs/dn/current/BP-1938937130-10.8.22.2-1516416995387/current/finalized/subdir92/subdir154/blk_2136775295
2021-09-28 15:31:52,740 INFO org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetAsyncDiskService: Deleted BP-1938937130-10.8.22.2-1516416995387 blk_2136776575_1063083777 file /data2/dfs/dn/current/BP-1938937130-10.8.22.2-1516416995387/current/finalized/subdir92/subdir159/blk_2136776575
发现在31:52 有日志输出删除这个block,为什么会有这个操作呢?我们看namenode日志
第五步拨开面纱
2021-09-28 15:31:19,287 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: BLOCK* checkFileProgress: blk_2136776575_1063083777{blockUCState=COMMITTED, primaryNodeIndex=-1, replicas=[ReplicaUnderConstruction[[DISK]DS-2fb03e6c-cf60-4b12-8fcd-7cc92510c8ca:NORMAL:10.8.22.17:1004|RBW], ReplicaUnderConstruction[[DISK]DS-06c4c8c3-68ad-4089-b263-28364e71316b:NORMAL:10.8.56.9:1004|RBW], ReplicaUnderConstruction[[DISK]DS-363d48bc-7453-40e6-9977-25cec11aa18b:NORMAL:10.8.22.46:1004|RBW]]} has not reached minimal replication1
。。。。。。。。。
2021-09-28 15:31:31,695 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: BLOCK* checkFileProgress: blk_2136776575_1063083777{blockUCState=COMMITTED, primaryNodeIndex=-1, replicas=[ReplicaUnderConstruction[[DISK]DS-2fb03e6c-cf60-4b12-8fcd-7cc92510c8ca:NORMAL:10.8.22.17:1004|RBW], ReplicaUnderConstruction[[DISK]DS-06c4c8c3-68ad-4089-b263-28364e71316b:NORMAL:10.8.56.9:1004|RBW], ReplicaUnderConstruction[[DISK]DS-363d48bc-7453-40e6-9977-25cec11aa18b:NORMAL:10.8.22.46:1004|RBW]]} has not reached minimal replication1
。。。这里省略了四条日志,内容和上面一样 时间不一样
这里打印了六条日志 表示 15:31:19 ---> 15:31:31 这12S内 数据还没有写入完成 也就是namenode没有收到datanode的完整报告
但是我们看最后写入的datanode(10.8.22.46)的日志
dest: /10.8.22.46:1004, bytes: 62851, op: HDFS_WRITE, cliID: DFSClient_NONMAPREDUCE_-424249781_105, offset: 0, srvID: eefc5ad9-3e92-4640-99a9-7c4c5a4a27de, blockid: BP-1938937130-10.8.22.2-1516416995387:blk_2136776575_1063083777, duration: 14511253
2021-09-28 15:31:18,798 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder: BP-1938937130-10.8.22.2-1516416995387:blk_2136776575_1063083777, type=LAST_IN_PIPELINE, downstreams=0:[] terminating
我们发现15:31:18就已经完成写入了 ,说明了这段时间内dn和nn通信有问题,
具体是nn还是dn的问题呢? 我们可以继续看nn的日志
第六步 问题初现
2021-09-28 15:31:31,843 INFO BlockStateChange: BLOCK* InvalidateBlocks: add blk_2136776575_1063083777 to 10.8.22.46:1004
因为已经超过了6次(可配置)没收到dn的汇报,上面提示 要求dn删除数据blk_2136776575_1063083777
2021-09-28 15:31:31,843 INFO BlockStateChange: BLOCK* InvalidateBlocks: add blk_2136776575_1063083777 to 10.8.22.46:1004
这里提示正式要求10.8.22.46删除数据块有这么多
继续看日志
2021-09-28 15:31:43,862 INFO BlockStateChange: BLOCK* InvalidateBlocks: add blk_2136776575_1063083777 to 10.8.56.9:1004
要求 10.8.56.9同样删除快
继续 要求 22.17删除快
2021-09-28 15:33:20,593 INFO BlockStateChange: BLOCK* InvalidateBlocks: add blk_2136776575_1063083777 to 10.8.22.17:1004
第七步
分析: 从这一大块删除的块挑选了几个块儿 在nn中查询,发现都是这段时间写入的块儿。。。无一例外都失败了,里面以22.17最多。
但是无法确认就是这台的dn问题
大概率还是namenode问题导致这一时间段(2s内)的通信出问题,同理我们用的解决办法也是减小nn的压力,最后效果不错。
另外我们的版本是2.6.0 据说全是bug的版本 还有很多可能影响nn
可以参考一下博客
其实问题到这儿能大概判断出问题,但是知道我看到下面的博客才更加确认
https://blog.csdn.net/lipeng_bigdata/article/details/51145368
修改的配置
优化
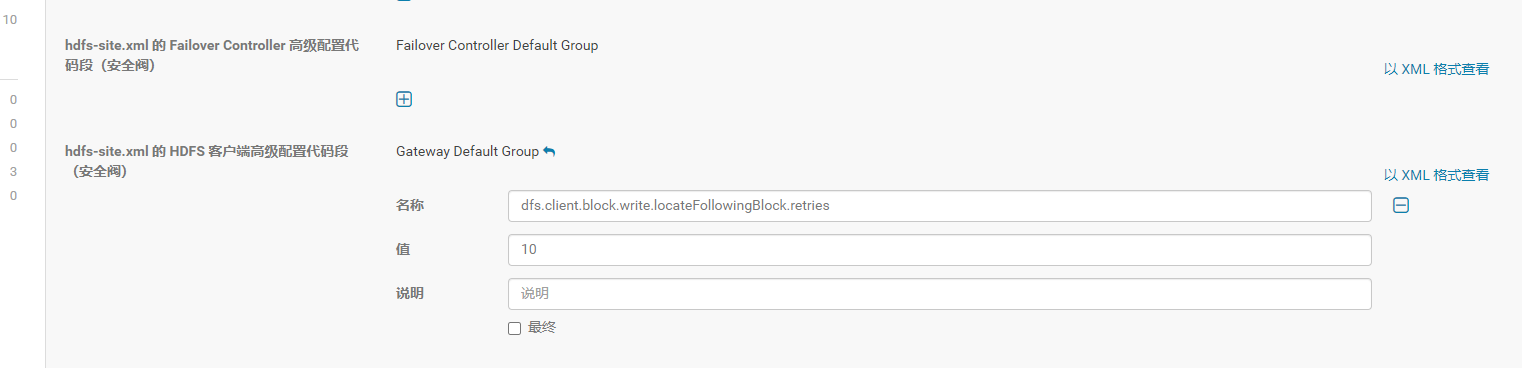
1 dfs.client.block.write.locateFollowingBlock.retries = 10
这个参数是说client等待的次数由6次变为10次。
Cloudera Manager -> HDFS -> Configuration -> Enter hdfs-site.xml in search bar, add dfs.client.block.write.locateFollowingBlock.retries = 10 in "HDFS Client Advanced Configuration Snippet (Safety Valve) for hdfs-site.xml"
注意这个参数是加在client的hdfs-site.xml里。
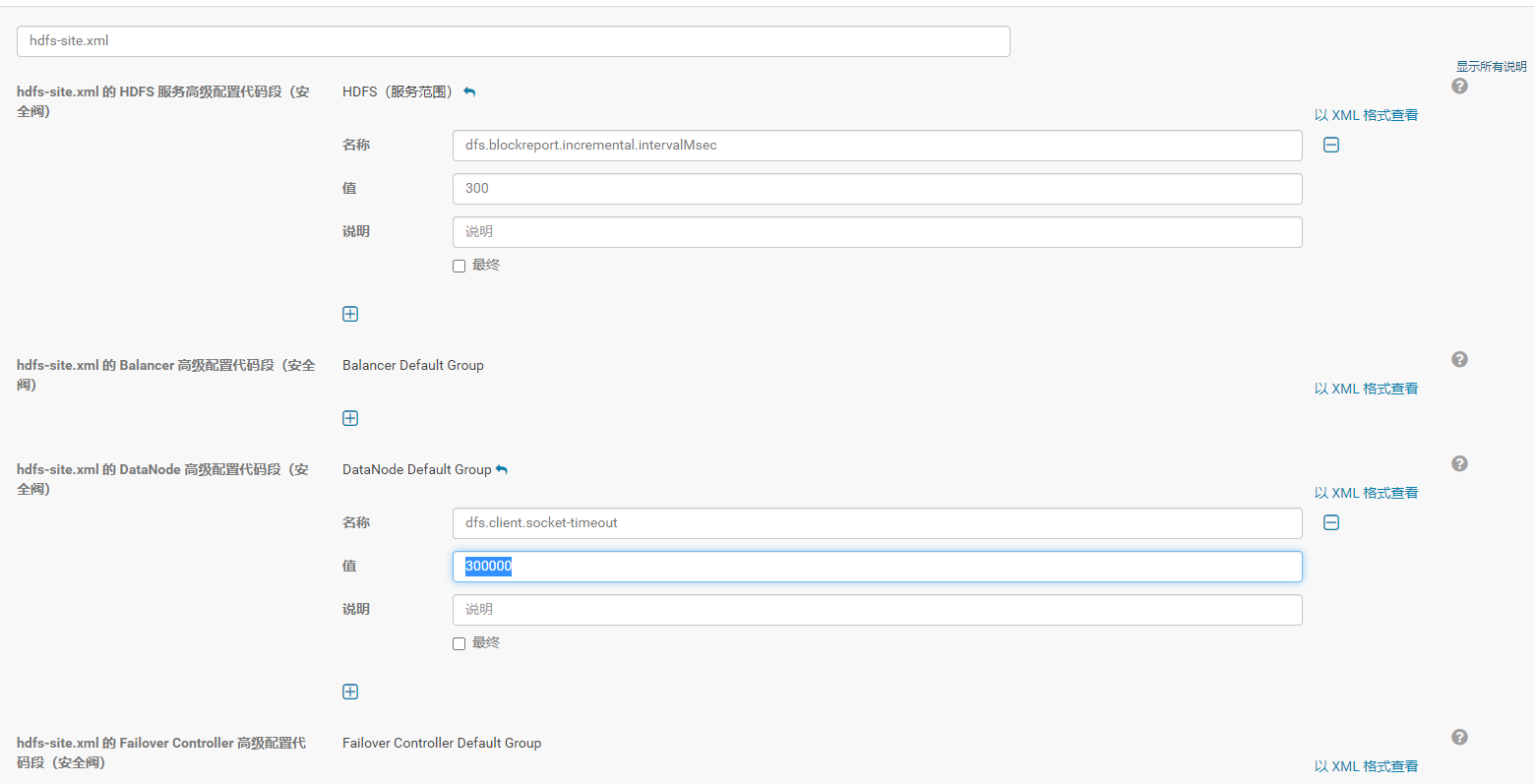
2 dfs.blockreport.incremental.intervalMsec = 300 ##这个最重要
这个参数是说datanode不立即回送block report给namenode,而是等300毫秒,然后一次性回送300毫秒内所有block的变化,这样可以极大减轻namenode的压力。
3 Cloudera Manager -> HDFS -> Configuration -> Enter hdfs-site.xml in search bar, add dfs.blockreport.incremental.intervalMsec = 300 in "HDFS Service Advanced Configuration Snippet (Safety Valve) for hdfs-site.xml"
注意这次加在service level的hdfs-site.xml里。
dfs.client.socket-timeout=300000
是否为数据盘的问题
之前我一段怀疑可能是某个磁盘有问题(22.17概率最高) 但是我统计了下数据
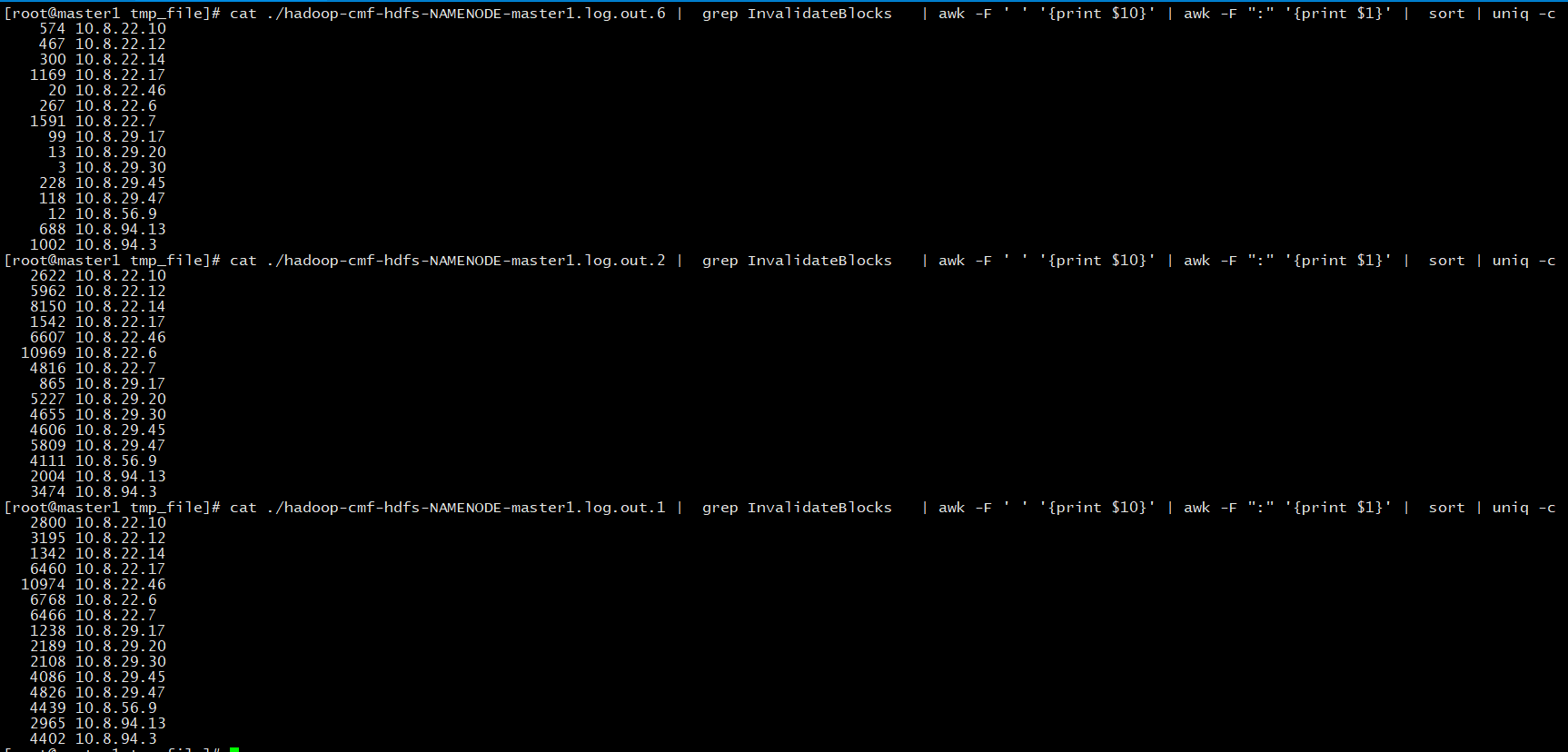
发现和磁盘没大关系!!
之所以我每次排查问题的块儿都会落在22.17 是因为开发同事的程序在这台机器上,hadoop利用最优方案 数据会首先写入到这台机器上!
修改后的效果
**cat ./hadoop-cmf-hdfs-NAMENODE-master1.log.out | grep InvalidateBlocks | wc -l**
1261
[root@master1 tmp_file]# !3016
cat ./hadoop-cmf-hdfs-NAMENODE-master1.log.out.1 | grep InvalidateBlocks | wc -l
64258
少了60倍InvalidateBlocks 不能清零的原因大概率还是因为bug 提官方case了 看能不能有回复,毕竟5.13已经停止维护了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号