selenium入门学习
在写爬虫的学习过程中,经常会有一些动态加载,有些是可以动过接口直接获取到,但是实在没办法,所以学习下selenium。
首先百度一下:
Selenium [1] 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
首先下载:
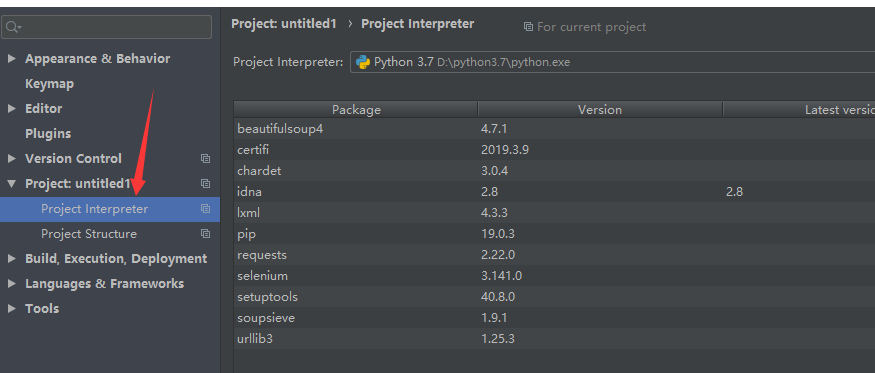
二: 下载chromedriver
找到本地chrome版本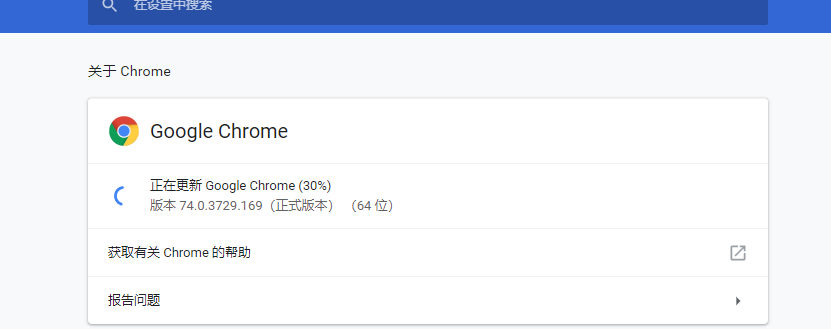
去队员的driver网站 http://npm.taobao.org/mirrors/chromedriver/ 下载(注意这里的win32兼容64位的)

接下来执行一小段代码

报错:
TypeError: 'module' object is not callable
解决办法
chrome-->Chrome 再次执行还是报错

解决办法,吧二进制包放到python家目录下面

或者
driver=webdriver.Chrome ('D:\python3.7\chromedriver') 写绝对路径
环境安装好了之后,一下是个基本应用:
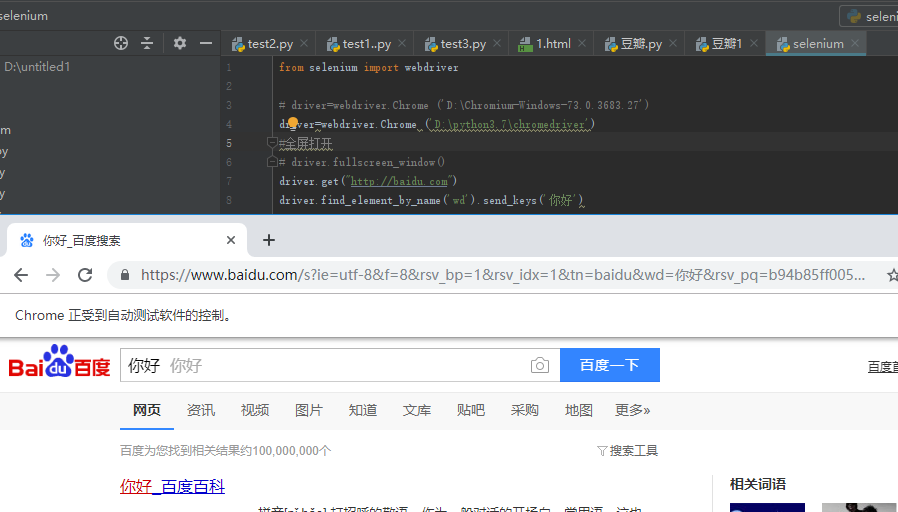
driver.quit()退出浏览器
elements=driver.find_elements_by_link_text("a") for elment in elements: if "新闻" in elment.test: elment.clink()
elements=driver.find_elements_by_link_text("贴吧").click() driver.back() driver.find_element_by_partial_link_text("贴").click()driver.find_element_by_name('wd').send_keys('你好 \n') driver.quit()
from selenium import webdriver # driver=webdriver.Chrome ('D:\Chromium-Windows-73.0.3683.27') driver=webdriver.Chrome ('D:\python3.7\chromedriver') #全屏打开 # driver.fullscreen_window() driver.get("http://baidu.com") #获取页面头部 baiduTitle = driver.title print(baiduTitle) #获取 带钱的url currentUrl = driver.current_url print(currentUrl) # 页面刷新 driver.refresh() #打开另一个url driver.get("https://google.com") #后退 driver.back() #获取页面源代码 pageSource=driver.page_source

 浙公网安备 33010602011771号
浙公网安备 33010602011771号