CycleNet: 通过周期模式建模加强时间序列预测《CycleNet: Enhancing Time Series Forecasting through Modeling Periodic Patterns》(时间序列、建模周期模式) +《SparseTSF: Modeling Long-term Time Series Forecasting with 1k Parameters》
这篇是11月20日就看到了,当时大体看了一下,然后12月2日花了一天时间看完了(摸鱼版本),然后今天12月9日,才想写一下博客记录一下。
不打算全文都直接翻译器翻译了,没意思+浪费时间,反正大家都有翻译器,我就不翻译了。
简单记录一下个人认为需要记录的地方。
论文:CycleNet: Enhancing Time Series Forecasting through Modeling Periodic Patterns
或者是:CycleNet: Enhancing Time Series Forecasting through Modeling Periodic Patterns
GitHub:https://github.com/ACAT-SCUT/CycleNet
NeurIPS 2024 Spotlight的论文。
推荐一篇知乎文章: [NeurIPS 2024 Spotlight] CycleNet: 利用可学习循环周期直接建模时序数据周期性
这篇论文是SparseTSF: Modeling Long-term Time Series Forecasting with 1k Parameters这篇论文的改进版本。
论文:SparseTSF: Modeling Long-term Time Series Forecasting with 1k Parameters
GitHub:https://github.com/lss-1138/SparseTSF
ICML 2024 Oral的论文。
原始的这个SparseTSF没有看原文,但是大体了解了一下。
那么就先简单说一下SparseTSF这篇论文:
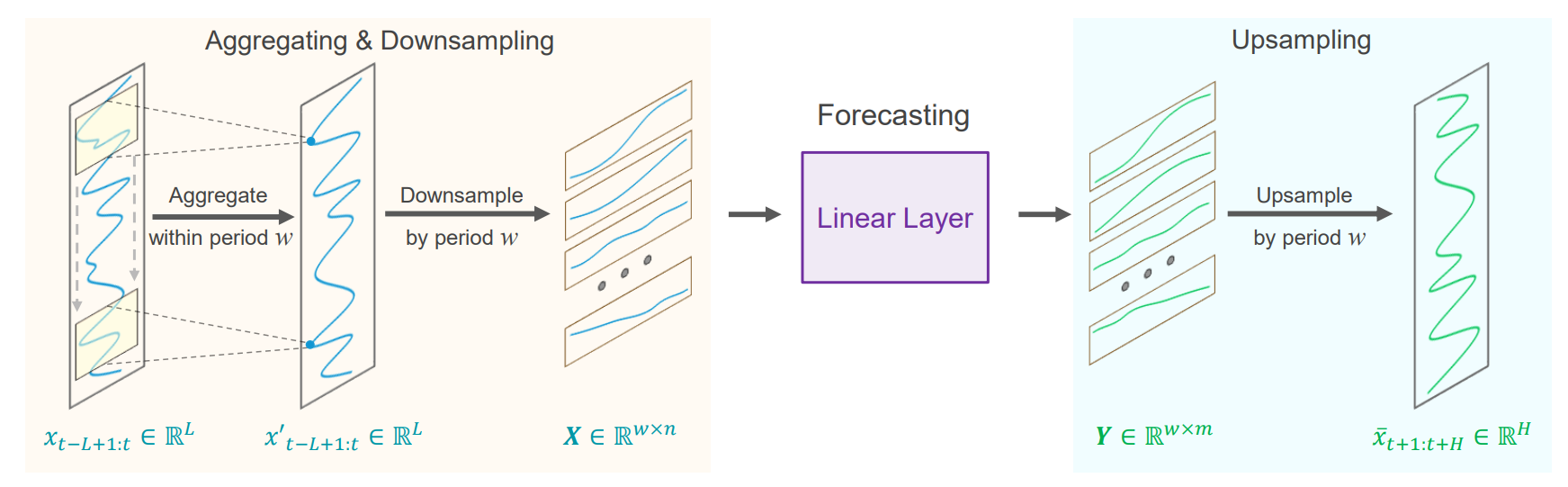
图1:SparseTSF架构。
一句话总结:
提出了一种通过提取周期性特征并利用简单的MLP模型进行时序预测的方法,通过人工提取周期性并进行周期性分块,减少了复杂模型的需求,模型在有限的参数下实现较好的长期预测效果。
准确的长时序预测的基础在于时序数据固有的周期性和趋势性。如果把模式明显的数据进行重新采样,原始序列的周期性和趋势性可以被分解和转化。也就是周期性模式被转化为子序列间的关系,而趋势性模式被重新解释为子序列内特征。这篇论文就采用了一种跨周期稀疏预测技术,对时间序列数据的周期性和趋势性进行解耦。通过对原始序列按照周期w进行降采样,聚焦于跨周期的趋势预测,提取周期特征的同时将模型的复杂度和参数量降低。
具体操作:
1.将原始时间序列按固定周期w进行下采样,生成w个等长子序列(子序列长度为(长度L/周期w)),然后在这些子序列上进行预测,最后再把预测结果组合回完整的预测序列。
2.跨周期预测,子序列使用共享参数的单层线性模型进行预测。
3.把预测子序列重新上采样组合为完整的预测序列。
在预测之前,对原始序列进行滑动聚合,每个聚合的数据点都包含了周围周期内其他点的信息,并且因为是聚合操作,加权平均可以缓解极值点的影响。
按照周期性进行降采样后的数据,数据的周期性就会被分解和转换为子序列内部之间的关联关系,周期性已经被显示的分离提取了,也就不需要进一步的建模周期性了,模型只需要建模子序列内的跨周期趋势。
问题:
1.对于长周期数据,降采样后会导致参数连接过于稀疏,导致信息利用不充分。
2.对于多周期的数据,表现也不好,因为模型只能下采样并分解一个主要周期。
3.适用于周期性明显的数据,如果是周期性不明显的数据,就不太行。
思考(个人的一些理解):
1)进步的角度:
1.这种按照周期性处理数据的操作,是一种知识嵌入,不是传统的特征工程。知识嵌入是在模型中引入已有的领域知识或先验知识,以提升模型性能。
2.说明在建模周期性明显的数据的时候,可能并不需要复杂的模型,设计轻量化模型是可行的操作。借助周期性分块的结构来捕捉时序数据的内在规律,从而提升预测准确性。
2)倒退的角度:
过度依赖人工干预,缺乏足够的自动学习能力。人工提取特征可能限制了模型的灵活性和泛化能力。
3)综合考虑:
如果数据周期性明显,并且目标是快速解决问题,那么这种人工提取特征并进行分块的方法是一种有效且高效的操作,简化了问题,避免了过度复杂性。
如果数据复杂,那么过度依赖手动提取特征的操作,可能会限制模型的表现,因为深度学习模型可以自动学习到周期性及其他隐藏的模式,从而更具泛化能力。
接下来就是CycleNet这篇论文:
前面的SparseTSF是通过降采样间接使用周期性,CycleNet通过可学习的参数来直接建模周期性。
作者抛出的观点是:构建复杂的模型的目的也是为了更好地提取周期特征,那我为什么不直接对这些周期性进行建模呢?毕竟数据中潜在的稳定周期性,是进行长期预测的实际基础。
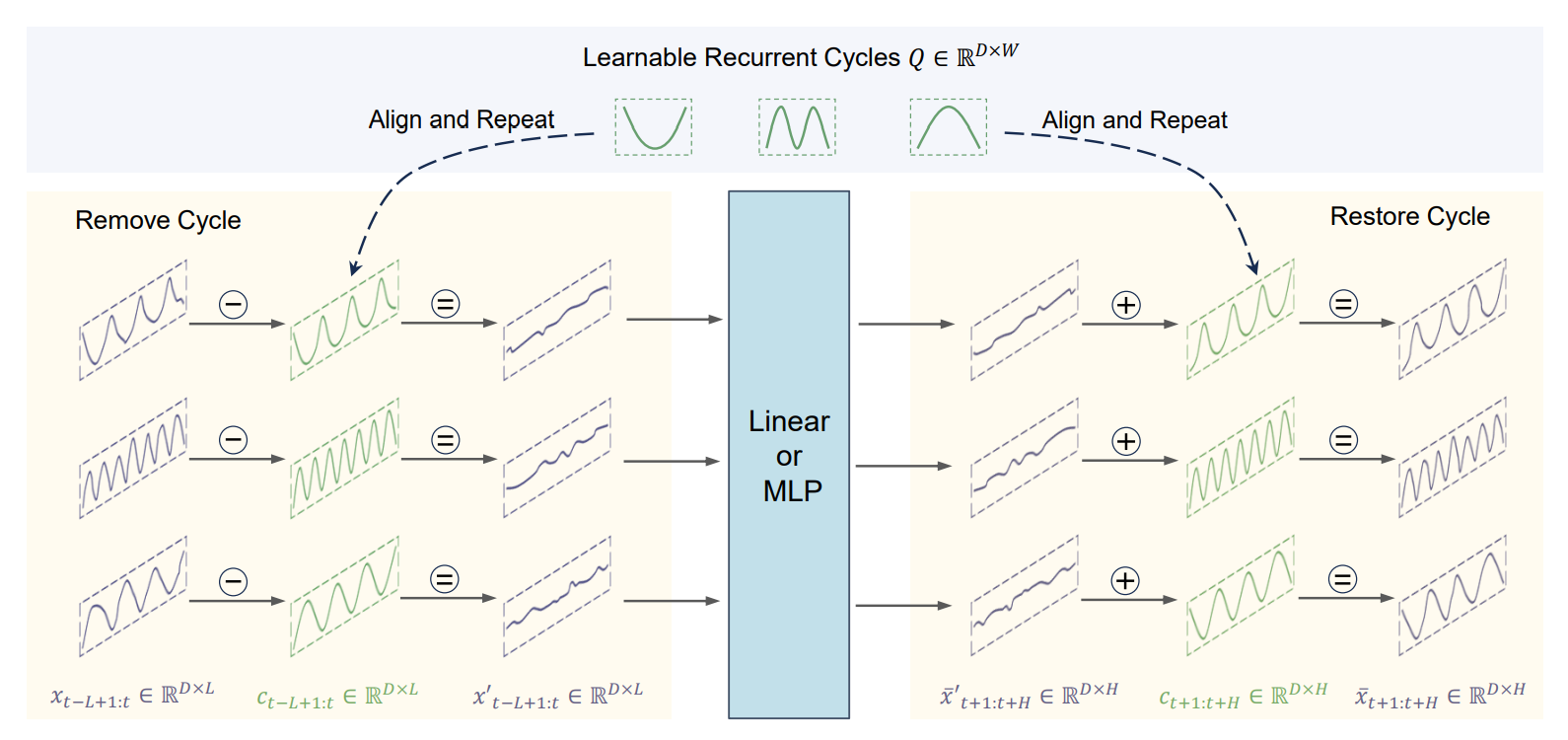
图2:CycleNet架构。
一句话总结:
提出了残差周期预测技术,首先通过可学习循环周期显式建模时间序列数据中的固有周期模式,然后对已建模周期的残差分量进行预测。把残差周期预测技术和单层的Linear或双层的MLP结合,就得到了CycleNet。
具体操作:
1.使用独立通道的全局可学习循环周期Q进行周期性建模。
2.预测建模周期性之后的残差分量,做法就是原始输入-周期分量=残差分量,然后这个残差分量放入到backbone模型中(MLP或Linear)进行残差分量的预测。
3.把预测的残差分量和周期分量再加到一起,得到最终的结果。
其中对于第1个操作,怎么进行周期性建模呢?
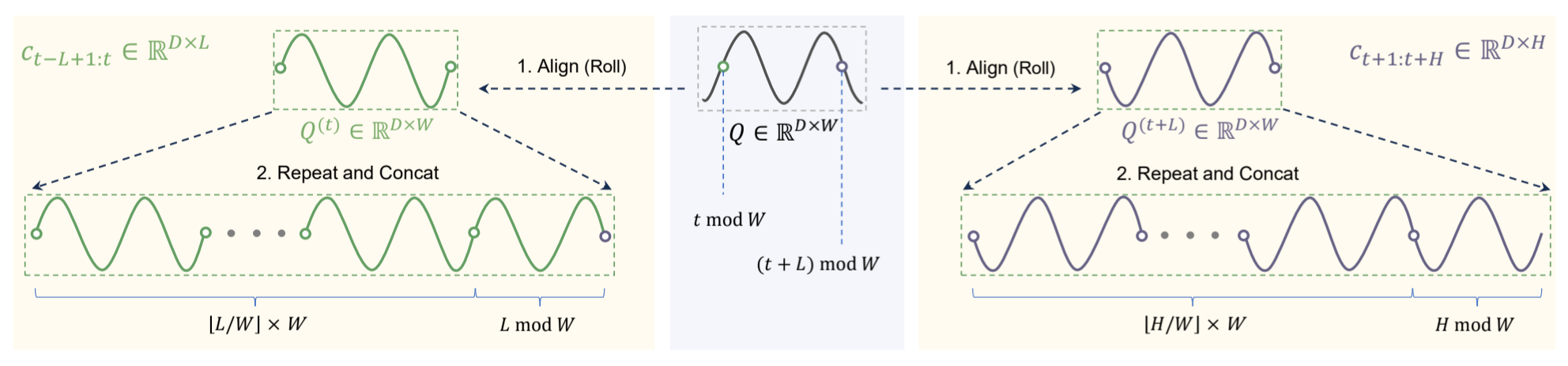
图3:循环周期Q的对齐和重复。
首先是循环长度W,这个W是超参数,但是需要数据集的先验特征,应设置为数据集中的最大稳定周期(还是需要人工经验的)。
通过时间t mod W,得到当前序列样本X在Q中的相对位置索引(看作是相对位置索引,这里其实是有道理的,因为位置索引确实可以提升模型效果,但是具体的这个是怎么做的,还需要看一下具体的实现),然后Q左移(t mod W)个位置得到循环分量C(这个循环分量就是Q(t)),然后复制C,复制下取整(L/W)次,L是这个序列样本X的长度(历史的L步预测未来的H步),然后把这些C进行连接(concat)。
这里的可学习循环周期Q的初始化为零,初始是一条直线,在训练的过程中这些长度为W的循环Q与主干的预测模型一起经过训练,训练得到学习到的表示(也就是学习到数据内在的周期模式),揭示序列中的内部循环模式。可学习循环周期在通道内是全局共享的。
接下来是残差预测,如何实现?
因为循环分量C是从Q的循环复制中导出的子序列,并不能直接获得历史子序列的C和未来子序列的C,所以就需要对循环周期Q进行适当的对齐和重复,以此来获得等效的子序列。(就是上面写的这个周期性建模里的内容)
那么就能得到历史的循环分量Q(t)和Q(t+L),然后原始输入移除这个循环分量就可以得到剩下的残差分量了,然后把这个残差分量送到backbone里进行预测就可以了。
最后再把预测的残差分量和循环分量加起来,就得到最终的预测值了。
这篇论文里,作者使用的backbone是单层Linear和双层MLP,使用通道独立策略,也就是每个通道都使用具有参数共享的相同骨干进行建模。
(现在22:05,还有一点实例规范化的内容没写,明天再写一下就可以了,今天先这样.)
(现在是2024年12月11日16:10,继续,写完剩下的一点.)
实例规范化策略:
作者还引入了实例规范化策略的内容,用来提升模型的鲁棒性,操作就是:从模型输入和输出步骤之外的模型内部表示中删除了不同的统计属性,具体参考,参考论文《Reversible Instance Normalization for Accurate Time-Series Forecasting against Distribution Shift》ICLR 2022 Poster的论文(还没看)。目的是为了解决分布漂移的问题。
实验部分:
采用的大多是模式稳定的数据集,具体的可以看论文里写的。结果中,除了交通数据集(Traffic)外,其他数据集的效果都很好(说明模型在建模复杂的模式的情况下还是有问题的哦)。
作者对交通数据集为什么效果不好进行了分析,作者认为交通数据集具有时空特征(spatiotemporal characteristics)和时滞特征(temporal lag characteristics),即某个检测点的交通流量会显著影响相邻检测点的未来值。在这种情况下,有必要建立充分的信道间关系模型,iTransformer模型可以实现,而作者提出的CycleNet模型对每个信道的时间依赖性进行独立建模,因此在这种情况下处于劣势。但是在交通数据集上,作者提出的模型比其他基线还是效果好的,这证明了提出的模型的竞争力。作者在附录部分进行了相关的补充(我没看)。
此外,作者还验证了提出的Residual Cycle Forecasting (RCF) 技术是否能提高现有模型的预测精度,因为提出的这个RCF本质上是一种即插即用的技术。除了效果好的之外,作者发现PatchTST和iTransformer与RCF结合使用的时候MAE会降低,但MSE会增加。作者分析背后的原因是:交通数据集中存在极值点,可能会影响RCF的效果,而RCF从根本上依赖于学习数据集中的历史平均周期。然后附录部分也给出了具体分析(还没看)。
消融实验与分析部分:
作者还分析了提出的方法与Seasonal-Trend Decomposion(STD)技术的比较,作者认为提出的RCF技术是一种更有效的STD技术。与从有限的回溯窗口分解周期性(季节性)成分的现有方法不同,作者提出的RCF技术是从训练集中学习全局周期性成分。作者认为基于移动平均(a basic moving average MOV)和可学习分解(Learnable Decomposition LD)方法是通过在回溯窗口内进行滑动聚合来实现趋势估计的,这种方法存在问题。
1.移动平均线的滑动窗口需要大于季节性成分的最大周期,否则分解可能不完整(尤其是当周期长度超过回溯序列长度时,分解可能无法进行)。
2.需要在序列样本的边缘进行零填充,以获得大小相等的移动平均序列,从而导致序列边缘失真(边缘填充,导致边缘失真,这个我看其他模型的代码的时候,边缘确实是填充处理的)。对于稀疏技术,作为一种轻量级分解方法,它更依赖于较长的回溯窗口和实例归一化策略来确保足够的性能。
此外,这些在回溯窗口内将趋势和季节解耦的方法本质上等同于无约束或弱约束线性回归,这意味着在完全训练收敛后,与这些方法相结合的基于线性的模型理论上等同于纯线性模型。相比之下,RCF技术所获得的周期成分是从训练数据集中全局估计出来的,能够超越有限长度回溯窗口的限制,因此其功能超出了标准线性回归的范围。
为什么等同于无约束或弱约束的线性回归?
GPT给出的解释为(直接截图吧):

补充:
1)因为从数学形式上,Y(t)是一个关于t和正弦、余弦基函数的线性组合,这就是线性回归模型的基本形式。
趋势和季节性分解的模型可以通过最小化均方误差(MSE)来拟合参数,这与线性回归的目标是一致的。具体而言:
1.无约束线性回归:如果分解过程没有对a,b,ci,di添加约束,那么优化这些参数的过程与无约束的线性回归完全等价。
2.弱约束线性回归:如果分解过程中对参数施加了一些弱约束(如正则化项),则这个过程等价于加权的线性回归或正则化线性回归。
无论是无约束还是弱约束,最终模型本质上都是基于线性假设的回归模型。
2)为什么“解耦”之后仍然是线性模型?
虽然这些方法在“形式”上解耦了趋势和季节性,但从本质上看,它们只是对时间序列数据进行了一种线性分解:
趋势解耦:趋势被建模为时间的线性函数或低阶多项式函数,与线性回归完全等价。
季节性解耦:季节性被建模为一组正弦函数和余弦基函数的线性组合,这也是一种线性变换。
因此,在完成训练并完全收敛后,这些基于线性分解的方法,理论上等价于一个纯线性的模型。模型无法捕捉到数据中的复杂非线性关系或高阶交互特征。
3)线性模型的局限性:
线性模型虽然简单易懂,但是存在局限性:
1.缺乏非线性能力,无法捕捉数据中复杂的非线性模式。
2.假设过于严格:假设趋势和季节性成分的变化都是线性的或固有周期的,而真实世界中的时序数据往往更复杂。
3.对突发事件或动态变化不敏感:比如经济波动或天气异常,线性模型难以建模。
因此,论文认为这些解耦趋势和季节性的传统方法,虽然在形式上进行了分解,但是本质上没有超越线性回归的框架。
而CycleNet提出的建模方法,通过引入非线性学习机制来克服线性模型的局限性。利用深度神经网络捕捉复杂的周期性变化,而不是简单依赖正弦和余弦基函数。虽然仍然进行趋势和季节性的分解,但对每一部分使用非线性模型进行学习,从而突破线性假设的限制。
以上,作者说的这些线性回归的比对的基线模型是:LD from Leddam [55](《Revitalizing multivariate time series forecasting: Learnable decomposition with inter-series dependencies and intra-series variations modeling》), MOV from DLinear [56](《Are transformers effective for time series forecasting?》), and Sparse technique from SparseTSF [32](《Sparsetsf: Modeling long-term time series forecasting with 1k parameters》)。
(emnnnnn,行吧,这也有道理.)
CycleNet模型的局限性:
1.周期长度不稳定:CycleNet可能不适合周期长度随时间变化的数据集,eg:心电图(ecg)数据集,因为CycleNet只能学习固定长度的周期。
2.不同通道的周期长度不同:当数据集中的不同通道表现出不同长度的周期时,CycleNet会遇到挑战,因为默认以相同的周期长度W对所有通道进行建模。考虑到CycleNet与通道无关的建模策略,一种潜在的解决方案是根据周期长度长度对数据集进行拆分预处理(这不就是这个作者在SparseTSF的操作吗,哈哈哈),或将每个通道作为单独的数据集进行独立建模。(说实话,我不是很赞同这些做法,就违背了简洁的初衷,不如直接换模型.)
3.异常值的影响:如果数据集包含大量异常值,模型性能会有影响。因为模型的基本工作原理是学习数据集中的历史平均周期。如果存在明显异常值(极值点),模型学习到的周期中某一点的平均值就会被夸大,导致对周期成分和残差成分的估计不准确,进而影响预测过程。
4.长周期建模:模型的RCF技术对中程稳定周期(每日周期或每周周期)建模非常有效。然而,考虑更长的依赖关系(年周期)对RCF技术来说是有挑战的。虽然理论上模型的W可以设置为年周期的长度来模拟年周期,但是数据集不支持,需要几十年的数据,所以未来还是需要解决长周期建模问题。
未来工作:
这里作者说设计结合CycleNet的更合理的多元建模方法会更有前景和价值,因为论文所提方法并未明确考虑多个变量之间的关系(所以交通数据集上效果不好),然后就是iTransformer和一些模型表明,对信道间关系建模可以提高交通场景中的性能。然而作者把CycleNet直接加到iTransformer中并不能带来显著改善(MSE指标上效果不好)。
(大概就这些,现在21:44,到时候再简单看一下代码,这篇论文就结告辞.)
该说不说,这篇论文确实分析的很到位,既写了自己的优点,也写了自己的缺点,并且都给出了令人信服的理由和说法。虽然整体的思路是简单的,但是可以让人反思。
截图一下作者在知乎评论里的一条回答:

这也和MB师兄告诉我的是相同的道理,既然能解决一个问题,那就是合理的,不可能一下子就做到很完美,一步一步来,逐步解决,总比什么都没有要好。
摸鱼结束,回寝室躺了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号