DBPM: 增强时间序列对比学习:一种动态坏对挖掘方法《Towards Enhancing Time Series Contrastive Learning: A Dynamic Bad Pair Mining Approach》(时间序列表征学习、对比学习、噪声正对、错误正对,损失重新加权(基于概率密度的加权))
今天是2024年10月12日,思路枯竭,还是论文看的太少了,继续看论文.
论文:Towards Enhancing Time Series Contrastive Learning: A Dynamic Bad Pair Mining Approach
或者是:Towards Enhancing Time Series Contrastive Learning: A Dynamic Bad Pair Mining Approach
GitHub:https://github.com/lanxiang1017/DynamicBadPairMining_ICLR24
ICLR 2024的论文。
摘要
(现在是10月14日,10:27.)
并非所有正对都有利于时间序列对比学习。在本文中,我们研究了两种会损害通过对比学习获得的时间序列表示质量的坏正对:噪声正对和错误正对。我们观察到,当出现噪声正对时,模型倾向于简单地学习噪声模式(噪声对齐)。同时,当出现错误正对时,模型会浪费大量精力来对齐不具代表性的模式(错误对齐)。为了解决这个问题,我们提出了一种动态坏对挖掘(DBPM)算法,它能在时间序列对比学习中可靠地识别和抑制坏的正对。具体来说,DBPM 利用记忆模块在训练过程中动态跟踪每个正对的训练行为。这样,我们就能根据历史训练行为,在每个时间点识别出潜在的坏正对。识别出的坏对随后会通过转换模块降低权重,从而减轻它们对表征学习过程的负面影响。DBPM 是一种简单的算法,设计成轻量级插件,无需可学习参数,可提高现有先进方法的性能。通过在四个大规模真实时间序列数据集上进行的广泛实验,我们证明了 DBPM 在减轻坏正对的负面影响方面的功效。
1 引言
自监督对比学习在从未标明的时间序列数据中学习有意义的表征,从而提高下游任务(如时间序列分类)的性能方面显示出显著的功效(Oord等人,2018年;Tonekaboni等人,2021年;Eldele等人,2021年;Yèche等人,2021年;Lan等人,2022年;Yue等人,2022年;Yang & Hong,2022年;Zhang等人,2022年b;Ozyurt等人,2023年)。时间序列对比学习的关键概念是捕捉视图(通常由随机数据增强生成)之间共享的有意义的基本信息,从而使学习到的表征在时间序列之间具有区分性。为了实现这一目标,现有的对比方法都遵循一个假设,即来自同一实例(即正对)的增强视图共享有意义的语义信息(Chen 等人,2020;He 等人,2020a;Chen & He,2021a;Wen & Li,2021)。
但是,如果违反了这一假设会发生什么呢?最近的一些研究(Morgado 等人,2021;Chuang 等人,2022)调查了错误视图问题在图像对比学习中的影响。研究发现,当从同一幅图像中生成的两个视图实际上并不共享有意义的信息时(例如,从同一幅图像中剪切出的一对毫不相干的猫狗),对比学习模型的有效性确实会受到影响。换句话说,并非所有的正对图像都有利于对比学习。我们将这一思路延伸到时间序列,研究时间序列对比学习是否也会遇到类似的挑战,并探索什么样的正对会对学习过程不利。具体来说,当把常用的对比学习方法应用到时间序列应用中时,我们观察到两种极端的正对情况,它们违反了假设,从而削弱了学习到的时间序列表示的质量:
噪声正对: 如图 1 (a)所示,这是睡眠-EDF 数据集(Goldberger 等人,2000 年)(脑电信号)中的一个实际例子。当原始信号显示出大量噪声时,就会出现这些正负对,这可能是由于现实世界中数据收集不当造成的。这就会产生噪声对比视图,视图之间的共享信息主要是噪声。在给定的例子中,低电压脑电图受到其他电信号的干扰,如眼球运动产生的眼球电图(EOG),这使得一些指示早期癫痫的微妙脑电图尖峰被噪声淹没。因此,出现了噪声对齐,在这种情况下,模型只是学习噪声模式,而不是真实信号。
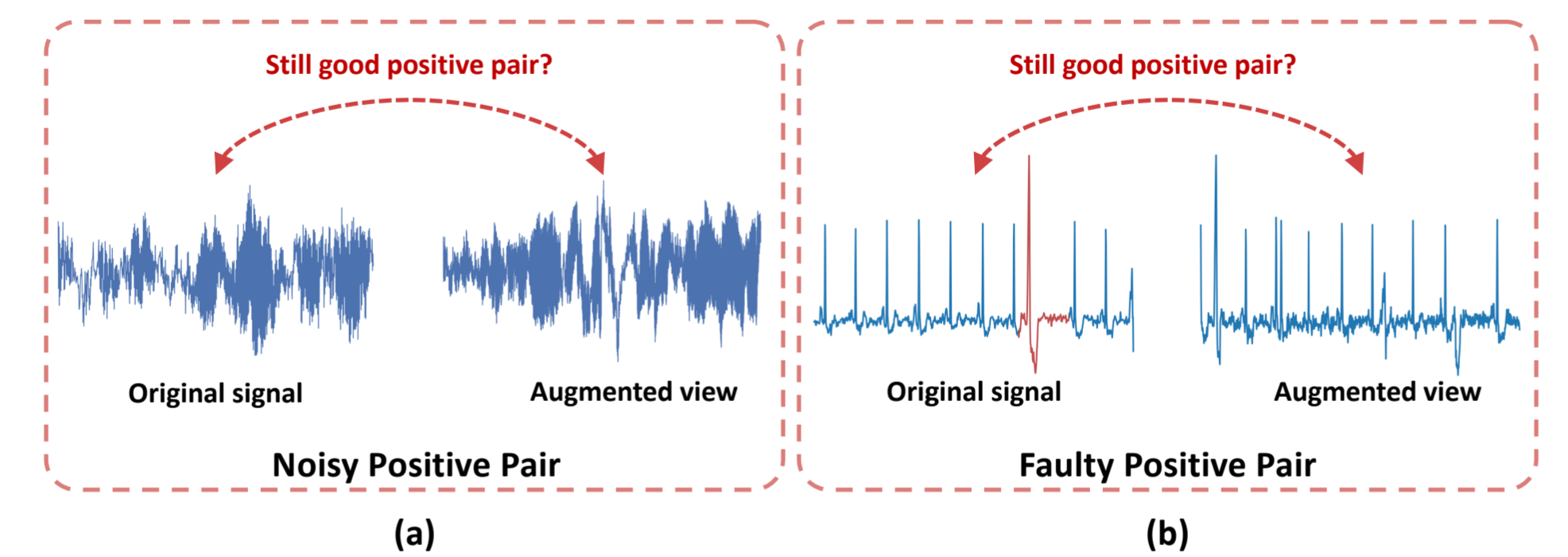
图 1:动机: 在真实世界的时间序列对比学习中发现的两类坏正对: 噪声正对: 原始信号和增强视图中存在过多噪声,导致对比模型主要从噪声中学习模式(即噪声对齐)。错误正对: 由于在增强过程中破坏了重要的时间模式(即原始信号中突出显示的红色部分),增强后的视图不再具有与原始信号相同的语义,从而导致对比模型学习对齐非代表性模式(即错误对齐)。
错误正对: 如图 1 (b)所示,这是一个来自 PTB-XL 数据集(Wagner 等人,2020 年)(心电图信号)的真实例子。由于时间序列的敏感性,数据增强可能会无意中损害原始信号中包含的复杂时间模式,从而产生错误的视图。在本例中,用于诊断心电图异常的室性早搏(红色部分)所显示的独特时间模式在增强后被破坏。因此,增强后的视图不再具有与原始心电图相同的语义,从而导致错误的对齐,即模型学会对齐视图之间共享的非代表性模式。
为了清楚起见,我们将这两种极端情况称为时间序列对比学习中的坏正对问题。一个直观的解决方案是在对比训练过程中抑制坏的正对,然而,在现实世界的数据集中直接识别坏的正对具有挑战性,原因有两个。首先,对于噪声正对,通常无法根据真实世界数据集的信号来测量噪声水平。其次,对于错误正对,如果没有地面实况,我们将无法识别增强视图的语义是否发生了改变。
因此,在这项工作中,我们首先使用模拟数据研究了对比学习模型在存在坏正对的情况下的训练行为。如图 3 所示,我们发现噪声正对在整个训练过程中的损失相对较小。相比之下,错误正对往往会在训练过程中造成较大的损失。
受这些观察结果的启发,我们设计了一种动态坏对挖掘(DBPM)算法。所提出的 DBPM 算法用一个简单的概念来解决坏正对问题:识别和抑制。具体来说,DBPM 的目标是在对比训练中挖掘可靠的坏正对并降低权重。为此,DBPM 首先利用一个记忆模块来跟踪每个对在训练过程中的训练行为。通过记忆模块,我们可以根据潜在坏正对的历史训练行为,在每个时间点动态识别它们,从而使识别更加可靠。此外,我们还设计了一个转换模块,用于估算坏正对的抑制权重。通过这种设计,DBPM 可以在学习过程中可靠地减少坏正对的负面影响,从而提高学习到的表征的质量。
总的来说,这项工作的贡献可以概括为三个方面。首先,据我们所知,这是第一项研究时间序列对比学习中存在的坏正对问题的研究。我们的研究有助于加深对这一尚未被深入探讨的重要问题的理解。其次,我们提出了 DBPM,这是一种简单而有效的算法,设计为轻量级插件,可在对比学习过程中动态处理潜在的坏正对,从而提高学习到的时间序列表示的质量。第三,在四个真实世界的大规模时间序列数据集上进行的广泛实验证明了 DBPM 在提高现有先进方法性能方面的功效。
2 相关工作
2.1 自监督对比学习
对比学习旨在最大化同一实例中不同但相关视图(即正对)之间的一致性,因为它们被假定共享有意义的基本语义(Chen 等,2020;He 等,2020a;Zbontar 等,2021;Grill 等,2020)。通过最小化 InfoNCE 损失(Oord 等人,2018 年),对比模型迫使正对在表征空间中对齐。因此,对比学习的成功很大程度上依赖于视图设计(是的,依赖于代理任务),而在不合适的视图上进行训练会不利于模型性能的提高(Wang & Qi,2022a;Tian 等人,2020;Wen & Li,2021)。
之前有一些视觉领域的研究探讨了潜在的错误正对问题。RINCE(Chuang 等人,2022 年)通过设计一个对称的 InfoNCE 损失函数来缓解这一问题,该函数对错误视图具有鲁棒性。加权 xID(Morgado 等人,2021 年)则在视听对应学习中对可疑的视听对进行了降权。我们的 DBPM 在以下方面不同于基于图像的解决方案。首先,DBPM 是为时间序列对比学习而设计的,在时间序列对比学习中,不仅会出现错误正对,还会存在噪声正对。处理两种不同类型的坏正对是时间序列数据特有的挑战,也是时间序列数据与图像数据的区别所在。直接从图像数据中调整方法,可能无法有效解决时间序列背景下这些正负对带来的挑战。我们的 DBPM 是根据时间序列数据中这些对的独特特征设计的,因此能够同时处理这两种类型的坏对。此外,DBPM 还能根据坏正对的历史训练行为,以动态的方式识别坏正对,从而更可靠地识别潜在的坏正对。
2.2 时间序列对比学习
最近的一些研究表明,对比学习是时间序列表征学习的一种突出的自监督方法。例如,TSTCC(Eldele et al. BTSF(Yang & Hong,2022 年)提出了一种双线性时谱融合模块,利用时谱密切程度来提高表征的表现力。CoST(Woo 等人,2022 年)应用对比学习来学习用于长序列时间序列预测的分离季节趋势表征。TS2Vec(Yue 等人,2022 年)在增强的上下文视图上利用了分层对比,从而使学习到的每个时间戳的上下文表示具有鲁棒性。TF-C(Zhang 等人,2022b)利用时间频率一致性作为预训练机制,促进数据集之间的知识转移。
2.3 带标签错误的学习
基于对比视图可以相互提供监督信息(Wang et al., 2022),我们将坏正对问题与监督学习中的标签错误问题联系起来。Swayamdipta 等人(2020)、Shen & Sanghavi(2019)的研究表明,与正常数据相比,存在标签错误的数据表现出不同的训练行为。受这些观察结果的启发,我们在时间序列对比学习的背景下,利用模拟数据分析了坏正对的训练行为(如训练过程中的单个对损失及其方差),并进一步设计了 DBPM,以根据观察结果动态处理坏正对。
3 方法
在本节中,我们首先从理论上分析了当前时间序列对比学习在存在坏正对的情况下存在的弊端。然后,我们使用专门制作的模拟数据集来验证我们的假设并研究坏正对的训练行为。接下来,我们将介绍 DBPM 算法,该算法旨在减轻真实世界数据集中潜在坏正对的不利影响。拟议的 DBPM 算法概览见图 2。
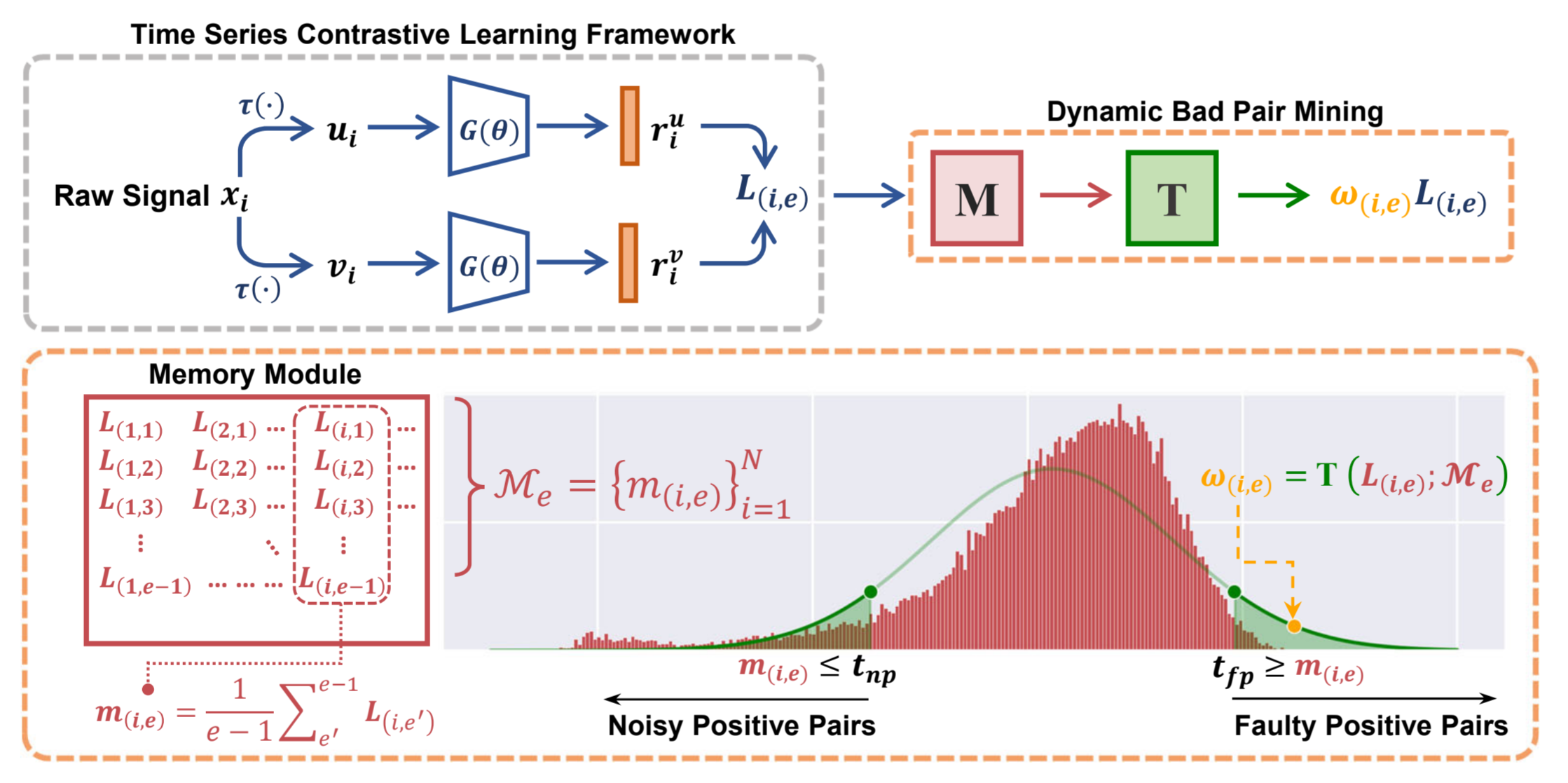
图 2:利用 DBPM 进行时间序列对比学习的图解。M 记录了每个正对在训练过程中的训练行为(即 m (i,e) ),并生成一个全局统计量 M e,用于在每个epoch识别潜在的坏正对。DBPM 简单而有效,可以轻松集成到现有框架中以提高其性能(如上橙色框所示)。
3.1 问题定义
我们将原始时间序列表示为 x ∈ R C×K,其中 C 是通道数,K 是时间序列的长度。给定一组时间序列 X,时间序列对比学习的目标是学习一个编码器 G(θ),将每个 x 从输入空间投射到其表示 r∈R H,其中 H 是表示向量的维度。
我们使用公认的线性评估协议(Chen 等人,2020;Eldele 等人,2021;Yue 等人,2022)来评估学习到的时间序列表示的质量。具体来说,给定训练数据集 X train = {X train ,Y train } 和测试数据集 X test = {X test ,Y test },首先在训练数据 {X train } 上训练编码器 G(θ)。然后固定 G(θ) 参数,仅用于生成训练表示 R train = {G(X train |θ)} 。然后,使用 {R train ,Y train } 训练线性分类器 F (θ lc )。最后,在测试数据集上使用预定义的指标来评估表示的质量,即 Metric(F(G(X test |θ)|θ lc ),Y test )。
3.2 分析:时间序列对比学习(这部分再多看看,晚上看的,脑子都是晕的)
在此,我们从理论上分析了噪声正对和错误正对会如何影响表征学习过程。为简单起见,我们使用一个简单的基于 InfoNCE 的时间序列对比学习框架(如图 2 中灰色框所示)进行分析。
前言。考虑一个训练时间序列 x i ∈R C×K 在一个有 N 个实例的训练集 X train 中,时间序列对比学习框架首先应用随机数据增强函数 τ (-) 从原始数据中生成两个不同的视图 (u i ,v i )=τ(x i ) (即正对)。然后,时间序列编码器 (r ui ,r vi )=(G(u i |θ),G(v i |θ))将这两个视图投射到表示空间。时间序列编码器的学习目的是通过最小化对比损失(即 InfoNCE)来最大化正对(u i ,v i )之间的一致性:
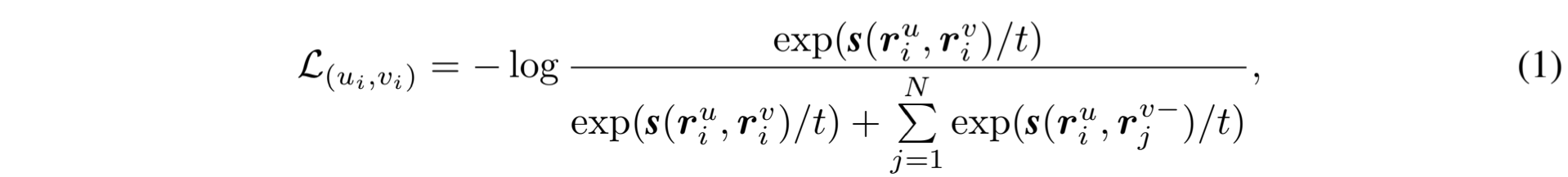 其中,s(r u ,r v )=(r u⊤ r v )/∥r u ∥∥r v ∥ 是计算 ℓ 2 归一化表示 r u 和 r v 之间点积的得分函数。(r ui , r v-j) 表示来自不同时间序列的表示(即负对)。t 是温度参数。
其中,s(r u ,r v )=(r u⊤ r v )/∥r u ∥∥r v ∥ 是计算 ℓ 2 归一化表示 r u 和 r v 之间点积的得分函数。(r ui , r v-j) 表示来自不同时间序列的表示(即负对)。t 是温度参数。
噪声对齐。让我们考虑一下噪声正对问题。根据 Wen & Li (2021),每个输入数据都可以 x i = z i +ξ i 的形式表示,其中 z i ∼ D z 表示真实信号,包含我们希望编码器 G(θ) 学习的期望特征,而 ξ i ∼ D ξ 是杂散密集噪声。我们假设,当 ξ i ≫ z i 时,噪声正对问题很可能发生在 x i 上,因为噪声原始信号在数据增强后会产生噪声视图。形式上,我们将 (u i ,v i ) 定义为当ξ ui ≫ z ui 和ξ vi ≫ z vi 时的噪声正对。此外,我们知道,最小化对比损失等同于最大化两个视图表征之间的互信息(Tian 等人,2020 年)(最小化对比损失(如InfoNCE)相当于最大化两个视图(如正样本对)之间的下界互信息。最小化对比损失等价于最大化两个视图之间的互信息,因为对比损失通过最大化正样本对的相似性以及最小化负样本的相似性,提供了正样本对之间互信息的下界。)。因此,当存在噪声正对时,arg max θ (I(G(u i |θ); G(v i |θ)))近似为 arg max θ (I(G(ξ ui |θ); G(ξ vi |θ)))。这就导致了噪声对齐,即模型主要从噪声中学习模式。
错误对齐。现在,我们考虑错误正对问题。鉴于时间序列的敏感性,随机数据扩增(如排列、裁剪(Um 等人,2017 年))有可能改变或损害原始时间序列中包含的语义信息,从而产生错误视图。形式上,当 τ (x i )∼D unknown 时,我们将 (u i ,v i ) 定义为故障正对,其中 D unknown ̸=D z。取 L (u i ,v i ) 相对于 r ui 的偏导数(全部推导过程见附录 A.4),得到

公式 2 揭示了增强视图 u i 的表示取决于增强视图 v i 的表示,反之亦然。这就是对比学习中正对的对齐方式:两个增强视图 u i 和 v i 相互提供监督信号。例如,当 v i 是一个错误的视图时(即 z ui ∼D z ,z vi ∼D unknown ),r vi 就会向 G(θ) 提供一个错误的监督信号来学习 r ui 。在这种情况下,arg max θ (I(r ui ;r vi )) 近似于 arg max θ (I(G(zui |θ); G(z vi |θ)),其中 G(θ) 提取了 u i 和 v i 之间共享的错误或无关信息,从而导致错误的对齐。这一分析也可应用于 u i 是错误视图,或 u i 和 v i 都是错误视图的情况。此外,我们假设来自错误正对的表征往往表现出较低的相似性(即 s(r ui ,r vi ) ↓),因为它们的时间模式是不同的。这意味着编码器会将更大的梯度放在错误正对上,从而加剧了错误的对齐。(为什么错误正对的表征往往表现出较低的相似性?时间模式不同吗?)
3.3 经验证据
我们建立了一个模拟数据集来验证我们的假设,并观察坏正对的训练行为。特别是,我们关注坏正对在不同训练epochs中的训练损失均值和方差。我们在模拟数据集中预先定义了三种类型的正对:正常正对、噪声正对和错误正对。为了模拟噪声正对,我们假设信号的噪声水平取决于其信噪比(SNR)。通过调整信噪比,我们可以生成不同噪声水平的时间序列,从干净(即信噪比大于 1)到极度噪声(即信噪比小于 1)。为了模拟错误正对,我们随机选取一部分数据,改变其时间特征,产生错误的视图。详细的坏正对模拟过程见附录 A.5。
我们的主要观察结果如图 3 所示。我们发现,在整个训练过程中,噪声正对表现出相对较小的损失和方差(绿色群组)。在附录 A.6 中,我们进一步证明了从噪声正对学习到的表征属于潜空间中的一个小区域,这意味着模型会坍缩为一个琐碎的解。这些证据证实了我们关于噪声对齐的假设。它揭示出,与监督学习不同,小的对比损失并不总是意味着模型学习到了有用的模式,而可能只是从噪声中提取了信息。相比之下,错误正对在训练过程中往往伴随着较大的对比损失和较小的方差(橙色群),这意味着错误正对很难对齐。这支持了我们关于错误对齐的假设,即模型花费大量精力试图对齐不相关的模式。

图 3:观察结果: 在训练过程中,噪声正对(绿色簇)表现出相对较小的对比损失,而错误正对(橙色簇)往往有较大的对比损失。
3.4 动态坏对挖掘
基于理论分析和经验观察,我们提出了一种动态坏正对挖掘(DBPM)算法,以减轻坏正对带来的负面影响。DBPM 背后的理念很简单:动态识别并抑制坏正对,以减少其对表征学习过程的影响。
识别。为了识别真实世界数据集中可能存在的坏正对,我们首先使用了一个记忆模块 M 来跟踪每个训练epoch中的个体训练行为。具体来说,M∈R N×E 是一个查找表,其中 N 是训练样本数,E 是最大训练epoch数。对于第 i 个正对(u i ,v i ),M(i,e)在第 e 个训练epoch用其对比损失 L(i,e)更新,对比损失 L(i,e)由公式 1 计算得出。然后,我们取第 e 个训练epoch(e > 1)之前 (u i ,v i ) 的平均训练损失来总结第 i 对正对的历史训练行为:
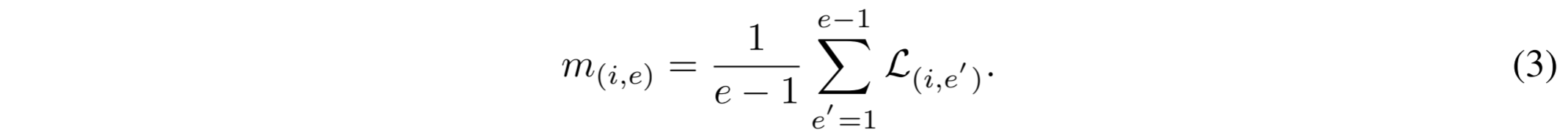
因此,在第 e 个训练epoch,M 将生成一个全局统计量 M e ={m (i,e) } iN=1 描述所有正对的历史训练行为。获得 M e 后,我们将使用其平均值和标准偏差作为第 e 个训练epoch的全局统计量描述符:

为了识别潜在的坏正对,我们必须确定一个将其与正常正对区分开来的阈值。我们将噪声正对和错误正对的阈值定义为:
![]()
在第 e 个训练epoch时,我们会识别出平均历史对比损失 m (i,e) 小于 t np 的噪声正对,而平均历史对比损失 m (i,e) 大于 t fp 的正对则会被识别为错误正对。请注意,β np 和 β fp 是决定阈值的超参数(还是有人工干预,超参数)。在实践中,作为一种简单的启发式方法,我们将 β np 和 β fp 设置在 [1, 3] 的范围内,发现效果一般都很好。关于 β np 和 β fp 影响的进一步分析,请参见附录 A.8。这样,我们就能在每个训练epoch根据历史训练行为动态识别潜在的坏正对,进而使识别更加可靠。例如,在整个训练过程中对比损失都很高的一对正对,比仅在几个训练epochs偶尔出现对比损失很高的一对正对更有可能是错误正对。
权重估计。接下来,我们设计一个转换模块 T 来估计每个训练epoch中坏正对的抑制权重。我们将转换模块 T 的权重估算表述为:
![]()
其中,1 i 是一个指标,如果第 i 对是坏正对,则设为 1,否则设为 0。T 将第 i 对正对在第 e 个时间点的训练损失映射为权重 w (i,e) ∈ (0, 1)。受经验证据中平均训练损失分布的启发,我们将 T 设为高斯概率密度函数。因此,当第 i 个正对在第 e 个epoch被识别为坏正对时,其对应的权重 w (i,e) 由以下方式估算:
![]()
通过使用该函数,我们假设每个epoch的全局统计量 M e 遵循均值为 µ e、方差为 σ 2 e 的正态分布。因此,坏正对的权重是 N ∼ (µ e ,σ 2e ) 的概率密度,它与正对损失近似成正比。这可以确保坏正对得到平稳的权重降低,从而抑制其影响(正样本相似度越低,损失就越大,且根据正态分布,低相似性样本的概率密度会越低,从而其权重也会减小。这种机制可以平滑地减少坏正对对模型的影响,帮助模型更加稳定地训练。)(但是我有疑问:如果全都是平滑的样本,那么模型区分样本细微差别的能力就会变弱,样本越相似,权重越高,干脆两个样本一模一样算了,这就是一个权衡的问题吧。)(但是个人理解,对比学习效果好不好具体取决于负样本的丰富程度,所以作者这样做,好像也没问题。)。此外,转换模块还提供了权重估计函数选择的灵活性。关于 DBPM 与其他权重估计函数的性能比较,请参见附录 A.7。
3.5 训练
在 DBPM 中,对比模型是通过重新加权损失来优化的。形式上,在初始热身epochs后,第 i 个正对在第 e 个训练历时的重新加权损失为:
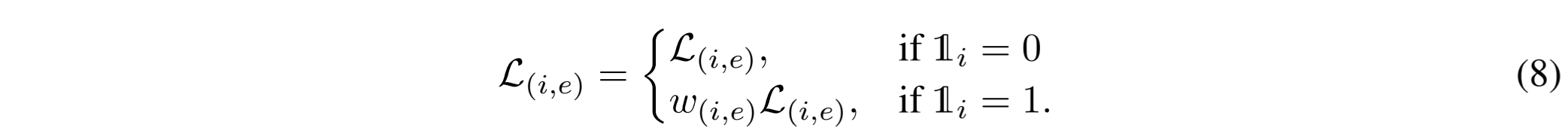
关于使用 DBPM 的对比学习程序算法,请参见附录 A.1。
4 实验
4.1 数据集、任务和基线
(现在是21:51,还差实验部分没看完,明天继续.)
(15日和16日也在看论文,研究里面的具体细节和一些疑问,所以没看实验部分,今天17日,研究的差不多了,继续看实验部分,现在14:40,今天把这篇论文结束。)
我们的模型在四个真实世界基准时间序列数据集上进行了评估: PTB-XL(Wagner 等人,2020 年)是迄今为止最大的免费临床 12 导联心电图波形数据集。基于心电图标注方法,有三个多标签分类任务: 诊断任务(44 个类别)、形式任务(19 个类别)和节奏任务(12 个类别)。HAR(Anguita 等人,2013 年):针对 6 种不同活动的多类分类。睡眠-EDF(Goldberger 等人,2000 年):5 个睡眠阶段的多类分类。癫痫(Andrzejak 等人,2001 年):识别癫痫发作的二元分类。与 Strodthoff 等人(2020 年)一样,我们使用 AUROC 作为 PTB-XL 的测试指标;与 Eldele 等人(2021 年)一样,我们使用 Accuracy 和 AUPRC 作为 HAR、Sleep-EDF 和癫痫的测试指标。每个数据集的详细说明见附录 A.2。我们研究了将 DBPM 集成到六种最先进的对比学习框架(包括三种通用方法)中所带来的性能提升: SimCLR[ICML20](Chen 等人,2020 年)、MoCo[CVPR20](He 等人,2020 年b)和 SimSiam[ICCV21](Chen & He,2021 年b);以及三种为时间序列量身定制的方法: TSTCC[IJCAI21]、TF-C[NeurIPS22]和 BTSF[ICML22]。我们还将 DBPM 与 RINCE[CVPR22]进行了比较,RINCE 是一种稳健的 InfoNCE 损失,用于处理图像对比学习中的视图错误问题。请注意,RINCE 并不适用于 SimSiam,因为它没有负对。对于每个实验,我们使用五种不同的种子运行五次,并报告测试指标的平均值和标准偏差。实施细节见附录 A.3。
4.2 线性评估
表 1 和表 2 表明,在不同任务和数据集下,与最先进的原始方法及其带有 RINCE 的变体相比,集成 DBPM 始终能带来更优的测试 AUROC 和更低的性能波动。例如,通过集成 DBPM,BTSF 在诊断分类任务中的性能从 69.48 显著提高到 73.32,而 TF-C 在节律分类任务中的性能从 80.46 提高到 82.10。我们进一步研究了 PTB-XL 数据集的每类 AUROC。图 4 显示了将 DBPM 集成到 SimCLR 中后改进最大的前 15 个类别。很明显,DBPM 不仅大大提高了这些类别的 AUROC,还使训练比原始 SimCLR 更稳定。集成 DBPM 后,大多数类别在不同运行中的性能差异都有所减少。结果表明,坏对问题在某些时间序列中更容易出现,而 DBPM 可以有效缓解其不利影响。此外,最小的运行时间和内存开销表明 DBPM 是一个轻量级插件,只给模型增加了可忽略不计的复杂性。复杂性分析见附录 A.1。
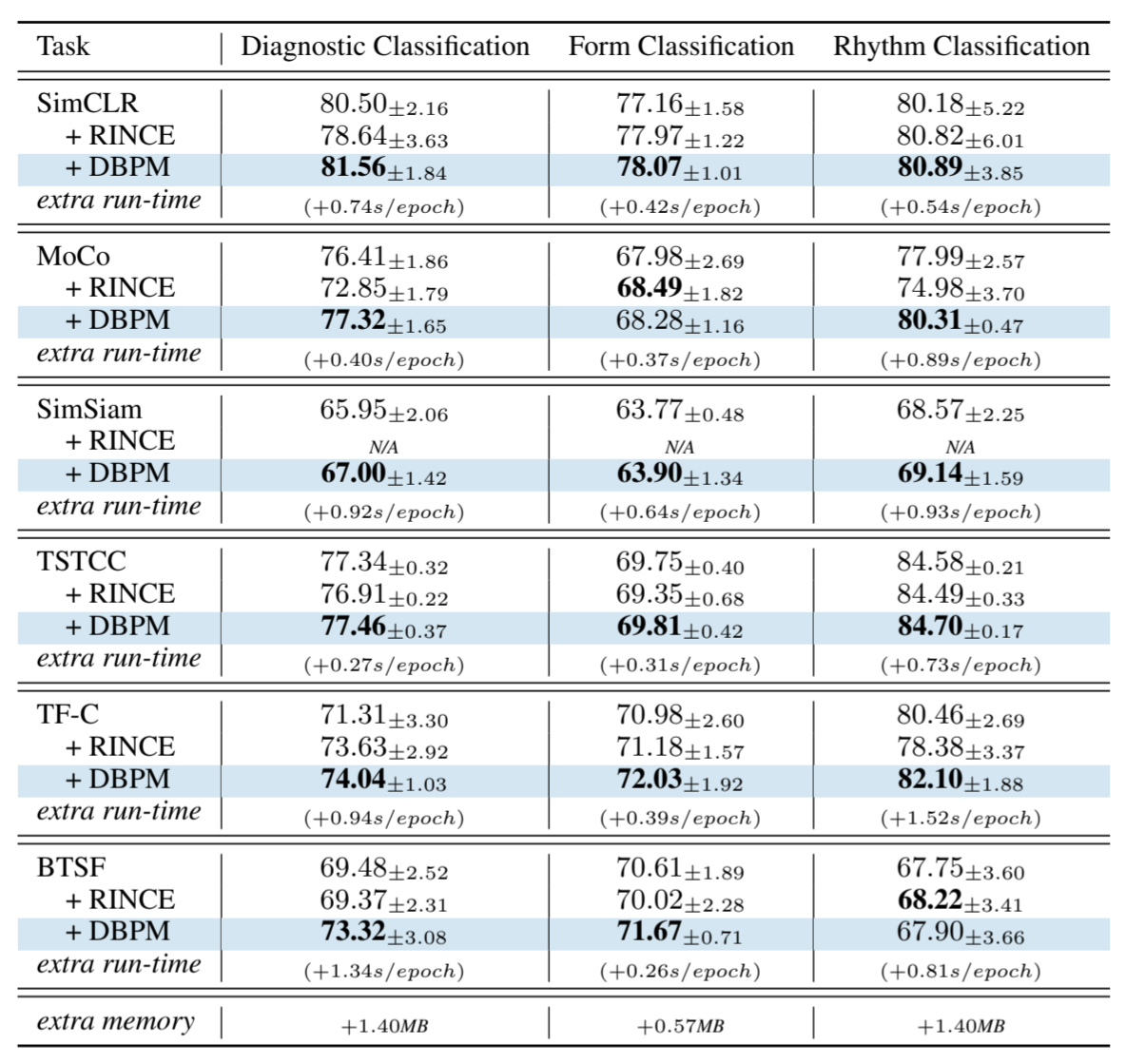
表 1:在 PTB-XL 数据集上对三种不同任务进行线性评估的测试 AUROC(%)。
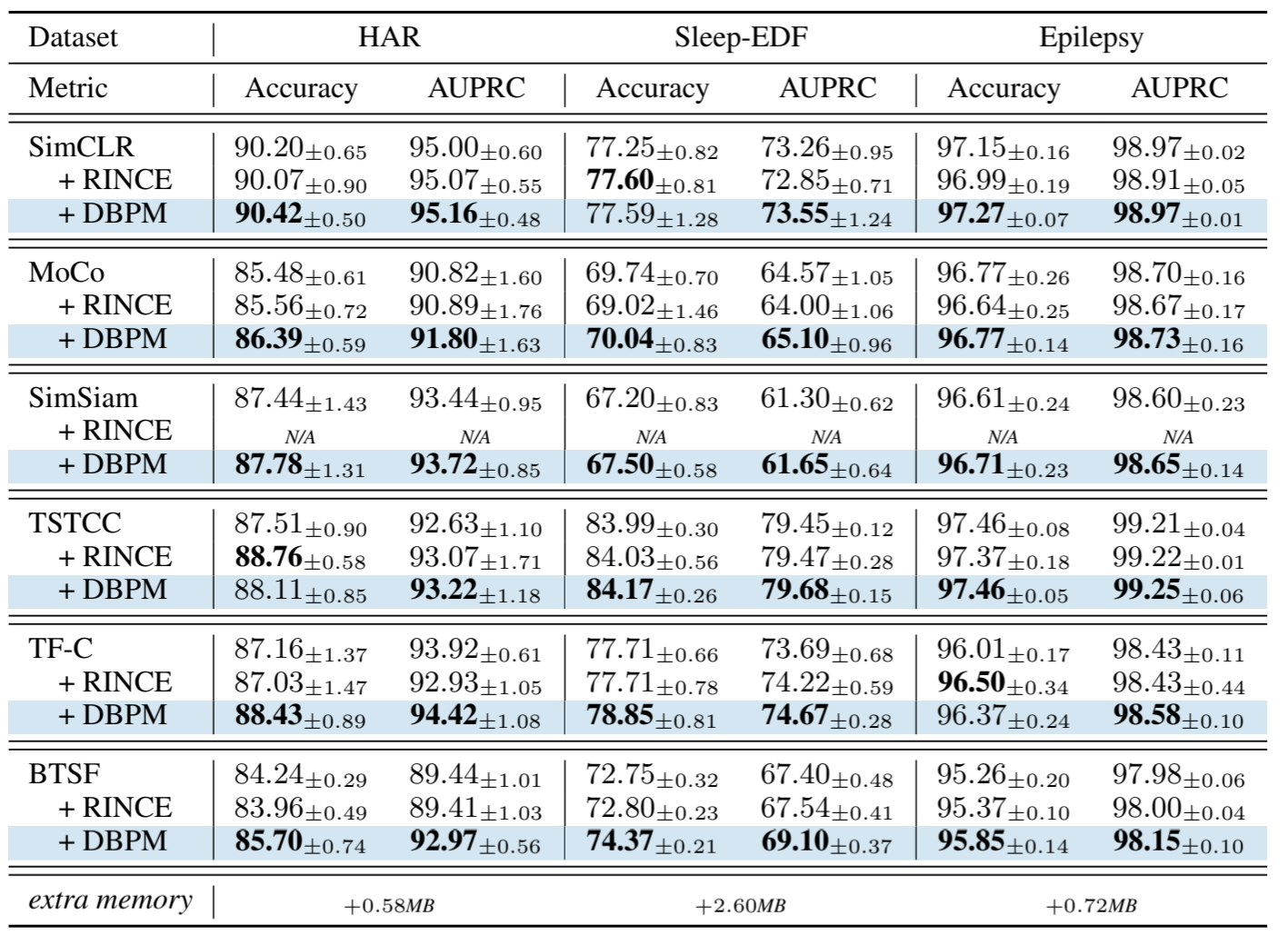
表 2:对三个真实世界时间序列数据集进行线性评估的测试精度(%)和 AUPRC(%)。
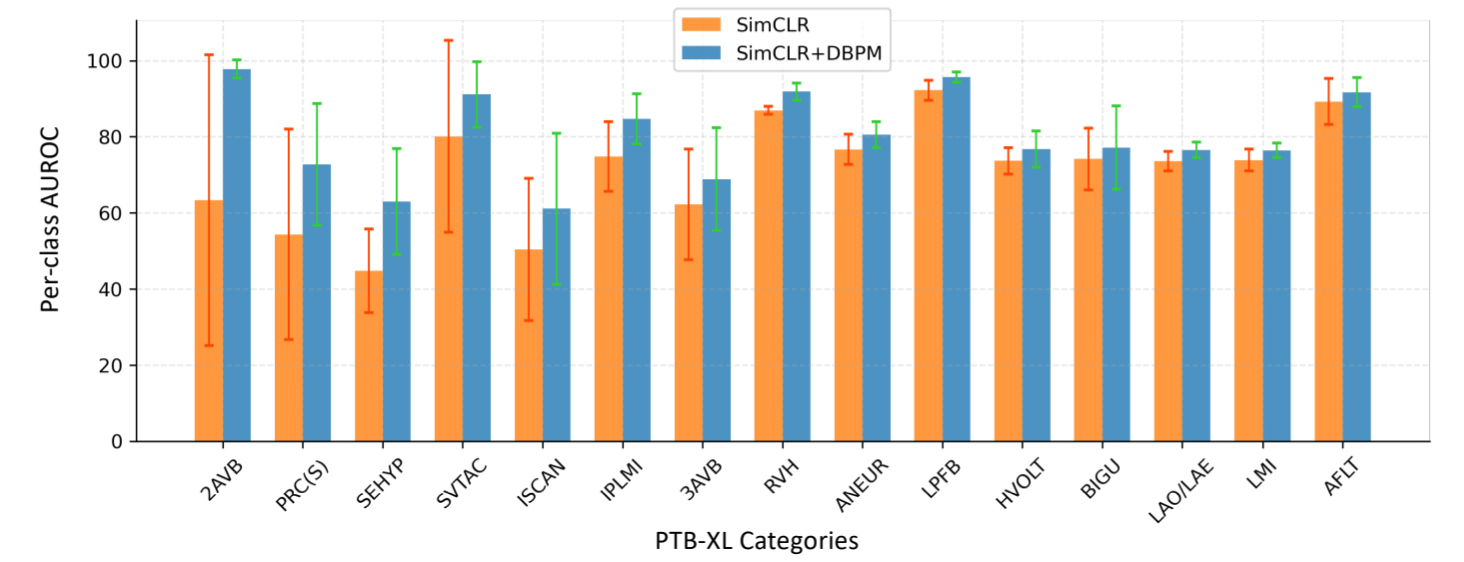
图 4:PTB-XL 数据集上的每类 AUROC (%)。集成 DBPM 不仅能显著提高性能,还能使不同运行中的模型性能更加一致。
在比较 DBPM 和 RINCE 时,我们发现 DBPM 更加可靠,在大多数实验中始终优于 RINCE,比基线有更大的性能提升。这主要是因为:首先,RINCE 只解决了有问题的正对问题,而在时间序列对比学习中,有噪声的正对也会削弱模型的性能;其次,RINCE 在每次训练迭代时都会简单地惩罚所有损失较大的正对,这可能会导致惩罚过度。例如,在保持其原始特征的同时,通过更强的增强生成的一些配对确实有利于对比学习(Tian 等,2020;王琪,2022b),尽管它们在某些训练迭代中可能会有相对较大的损失。对这类配对进行惩罚可能会导致次优表现。相比之下,DBPM 会考虑到这两种类型的坏对,并根据历史训练行为动态识别它们。因此,DBPM 在减轻坏对的负面影响方面更加可靠,从而在所有数据集上都能保持良好的性能。有关 M 和 T 的消融分析,请参见附录 A.8。
4.3 对坏正对的稳健性
我们进行了对照实验,以评估坏正对的影响以及 DBPM 对此类正对数量增加的鲁棒性。除了使用已经包含未知数量坏正对的 Sleep-EDF,我们还使用了一个干净的模拟数据集,以便更好地观察。对照实验设计见附录 A.5。图 5 显示,随着坏正对的增加,两个数据集的性能都会下降,这表明坏正对对时间序列对比学习产生了负面影响。我们的 DBPM 在两个数据集中都表现出了更强的抗坏正对能力,始终以不小的优势超过基线。结果表明,DBPM 有效地减轻了坏正对的负面影响,从而增强了所学表征的稳健性。
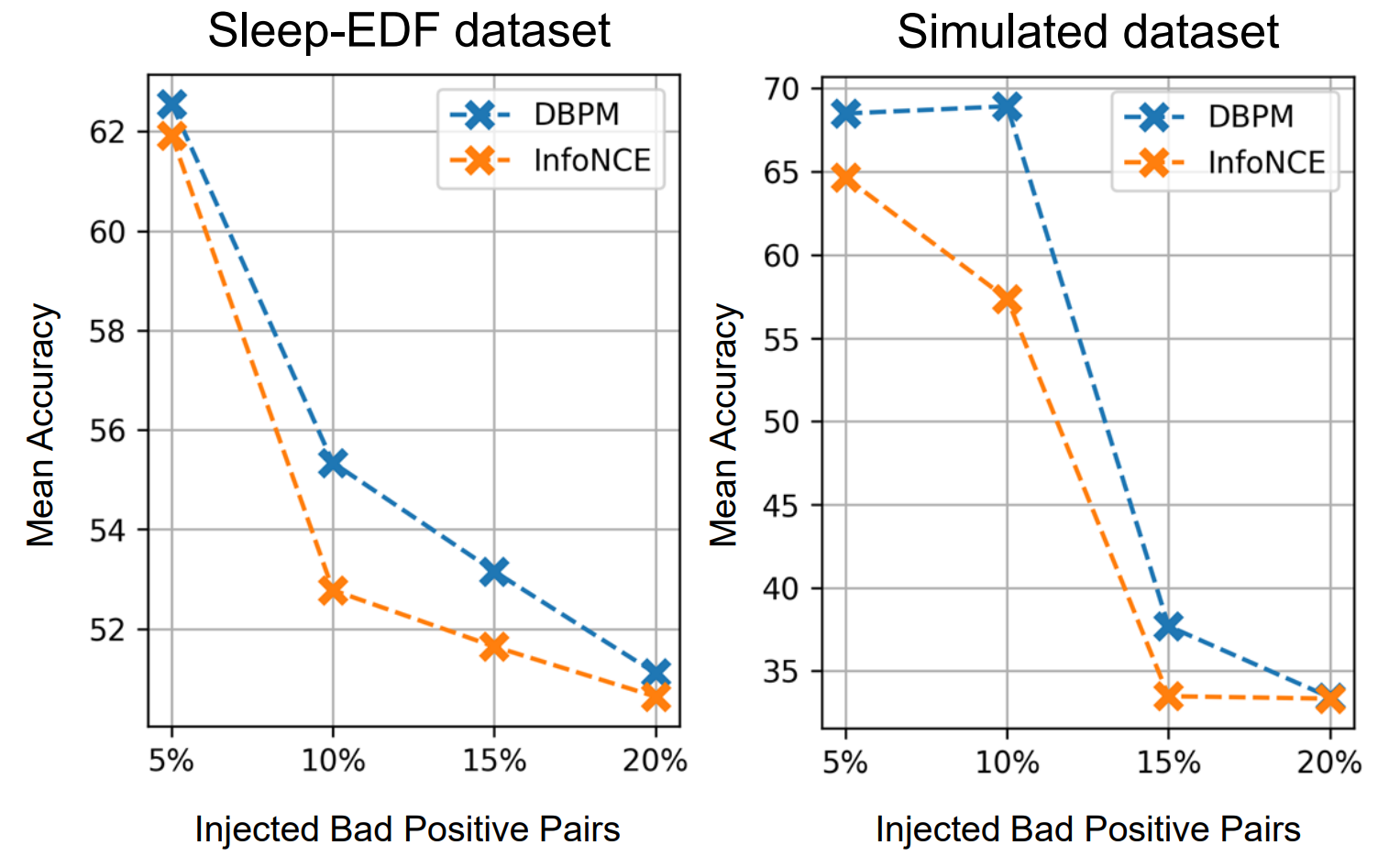
图 5:对坏正对的鲁棒性。
(这里我有话要说,哈哈哈哈,如图所示:)

(当然,也可能是我瞎说的,得论证.)
5 结论
本文研究了时间序列对比学习中的坏正对问题。我们从理论和实证角度分析了噪声正对和坏正对如何损害对比学习得到的时间序列表示的质量。我们进一步提出了一种动态坏对挖掘算法(DBPM)来解决这一问题,并在四个实际数据集中验证了其有效性。此外,我们还通过实证证明,DBPM 可以轻松集成到最先进的方法中,并持续提升其性能。展望未来,改进 DBPM 的方向有两个。首先是借助决策方法(如强化学习)开发自动阈值选择策略。此外,我们还计划将 DBPM 应用于更多时间序列应用,如预测和异常检测。我们相信,我们的方法为开发更好的时间序列对比学习提供了一个新的方向。
(现在21:15,再看看附录,结束.)
(18日,附录部分记录.)
附录部分:
A.5 坏正对模拟
使用正弦波、方波和锯齿波作为基本事件模式,每个时间序列只分配一种基本的时间模式。(真实的现实数据,往往是多种时间模式的组合,单一的时间模式,应该是针对简单场景下的.)
(毕竟是模拟实验).
对照实验。在图 5 中评估 DBPM 对坏正对鲁棒性的对照实验中,我们通过随机抽样一部分正对并手动将其转换为坏正对来控制坏正对的数量。具体来说,我们通过向信号中添加强高斯噪声来创建噪声正对,使噪声压倒真实信号。坏正对是通过对信号进行过度增强(如强随机缩放)生成的,这会损害信号的时间模式。我们增加坏正对的数量,看看性能如何变化。(这很难评,因为适当的噪声对对比学习是有益的,具体的就是作者如何评估这个 使噪声压倒真实信号 了.)
(今天21日,今天22日,我又来回顾这篇论文了.)
(看完了.)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号