DECL: 针对噪声时间序列的去噪感知对比学习《Denoising-Aware Contrastive Learning for Noisy Time Series》(时间序列、对比学习、去噪对比学习、去噪数据作为正样本,噪声增强(高斯噪声)数据作为负样本,正负样本映射方向相反)
今天是2024年9月12日,组会摸鱼,很久没看论文了,在摸鱼看代码,最近IJCAI 2024出来了,找了几篇论文看,首先这是第一篇。
论文:Denoising-Aware Contrastive Learning for Noisy Time Series
或者是:Denoising-Aware Contrastive Learning for Noisy Time Series
(两版本有修改,建议看IJCAI官网的版本,然后看arXiv版本里面的附录.)
GitHub:https://github.com/betterzhou/DECL
IJCAI 2024的论文。
摸鱼混子,抓紧看论文。
(声明:看的时候看的英文原文,但是写博客直接整段翻译器翻译的,会小修一下翻译的不合适的地方,大部分不修改,所以翻译的有问题就是翻译器的锅,哈哈哈哈哈哈哈哈哈哈.)
摘要
时间序列自监督学习(SSL)旨在利用无标签数据进行预训练,以缓解对标签的依赖。尽管近年来取得了巨大成功,但对时间序列中潜在噪声的讨论却很有限,因为噪声会严重影响现有 SSL 方法的性能。为了缓解噪声,事实上的策略是在模型训练前应用传统的去噪方法。然而,这种预处理方法可能无法完全消除 SSL 中的噪声影响,原因有二:(i) 时间序列中的噪声类型多种多样,很难自动确定合适的去噪方法;(ii) 将原始数据映射到潜在空间后,噪声可能会被放大(看看是否有论据,还是感性认知)。在本文中,我们提出了去噪感知对比学习(DECL),它使用对比学习目标来缓解表征中的噪声,并为每个样本自动选择合适的去噪方法。在各种数据集上进行的大量实验验证了我们方法的有效性。代码已开源。
(现在21:42,准备溜了,明天再看.)
(现在是14日的10点,准备看了,昨天摸了一天鱼.)
1 引言
时间序列学习在现实世界的各种应用中具有重要意义[Ismail Fawaz 等人,2019],例如心力衰竭诊断和工业故障检测。鉴于大量无标记时间序列数据的存在 [Meng 等人,2023b],从无标记时间序列数据中提取信息表征用于下游任务的时间序列自监督学习(SSL)备受关注 [Ma 等人,2023]。近年来提出了许多时间序列自监督学习方法[Zhang 等人,2023a],包括基于对比学习的方法[Tonekaboni 等人,2021]、基于生成的方法[Chowdhury 等人,2022]和基于对抗的方法[Luo 等人,2019]。
尽管在时间序列 SSL 方面取得了令人鼓舞的进展,但现有的研究往往假定给定的时间序列是干净的,而对时间序列中的潜在噪声讨论有限。不幸的是,许多时间序列(例如从传感器收集的生物信号)自然会受到噪声的影响,这些噪声会严重改变数据特征,损害 SSL 算法学习到的表征[Zhang 等人,2023b]。例如,如图 1(a)所示,心电图数据集 PTB-XL [Wagner 等人,2020] 中的一些样本表现出相当大的高频噪声。在该数据集上直接应用现有的时间序列 SSL 方法 CA-TCC [Eldele 等人,2023 年] 和 TS2vec [Yue 等人,2022 年] 进行分类任务,准确率很低,如图 1(c) 左侧所示。相比之下,如图 1(b)所示,采用适当的去噪方法(如 LOESS [Burguera,2018]),准确率会有显著提高,如图 1(c)中间所示。受此启发,我们研究了以下研究问题: 如何为 SSL 有效地去噪时间序列以学习更好的表征?
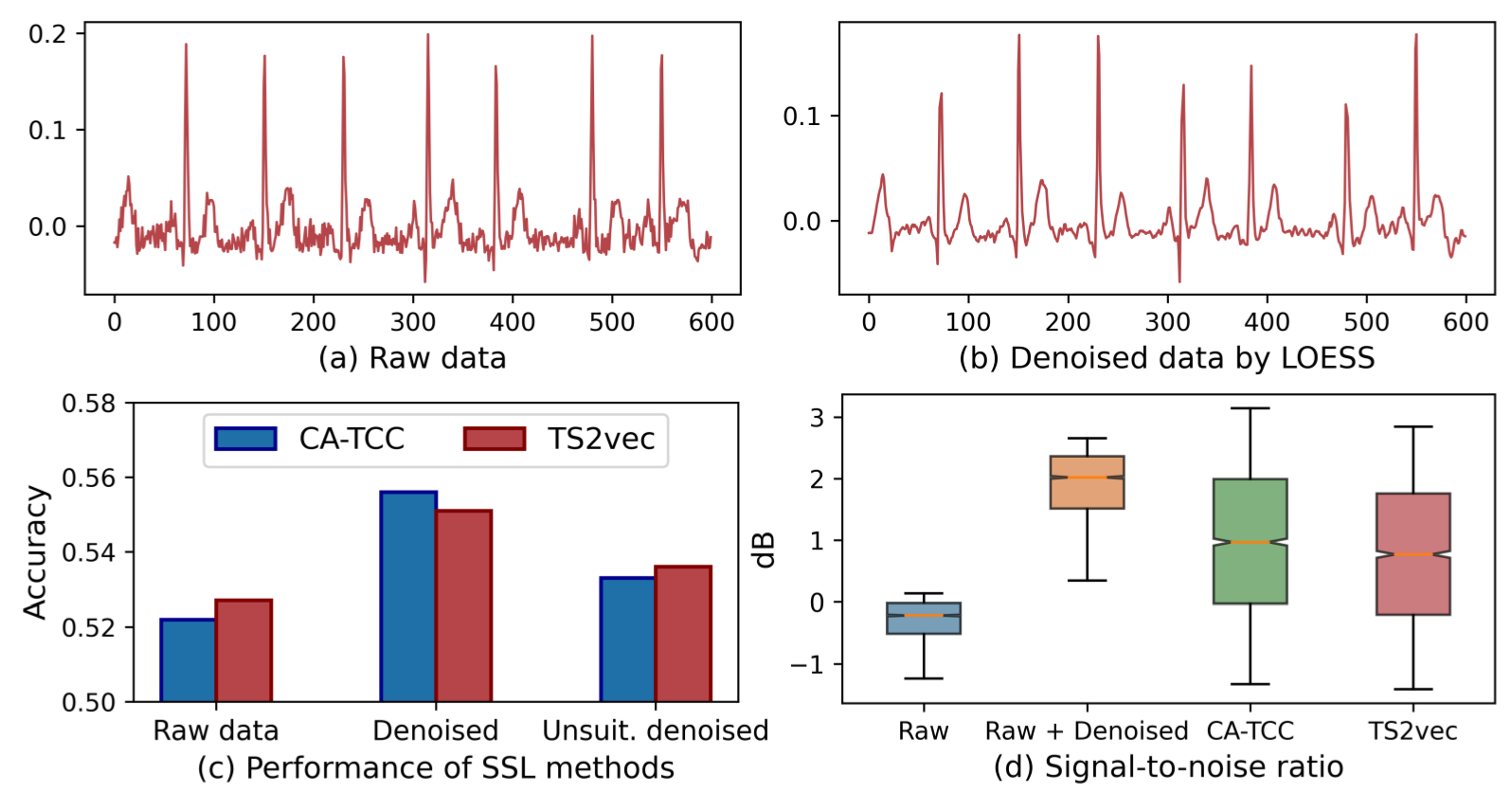
图 1:动机分析(更多详情见附录)。(a-c)表明,在 PTB-XL 数据集中,使用合适的去噪方法 LOESS 对噪声时间序列进行预处理后,SSL 方法获得了更高的性能,而使用中值滤波等不合适的方法进行处理时,性能提升并不明显。(d) 表明 SSL 方法倾向于放大表征中的噪声。
处理时间序列中噪声的实际策略是应用传统的去噪方法(如上文提到的 LOESS),然后进行模型学习[Lai 等人,2023]。然而,我们认为这种预处理方法不能完全消除时间序列中的噪声影响。首先,时间序列中的噪声类型多种多样,这给选择最合适的去噪方法带来了挑战[Zhang 等人,2021a]。许多真实世界的数据集,例如心电图数据,可能包含数千个样本,而每个样本涉及不同的噪声[He 等人,2015],如高频噪声、基线漂移和肌肉伪影(这是啥?)[Zhang 等人,2021b]。通常没有一种去噪方法能普遍处理所有类型的噪声[Robbins 等,2020;Zheng 等,2020],因此在实际应用中很难选择合适的去噪方法。例如,在图 1(c)的右侧,当我们使用不合适的去噪方法中值滤波器时,精度会下降。其次,将原始数据映射到潜在空间后,噪声可能会被放大。为了说明这一点,我们在图 1(d) 中比较了原始时间序列、去噪时间序列和在去噪时间序列上学习的表征的信噪比(SNR)[Chawla,2011]。结果显示:(i) 去噪数据的信噪比值得到了改善,这意味着原始数据中的噪声得到了缓解;(ii) 然而,如果进一步将去噪数据映射到表征空间中,信噪比值会下降,这表明表征学习过程可能会放大噪声。也就是说,尽管去噪方法可以缓解原始时间序列中的噪声,但噪声可能会在表征空间中 “卷土重来”,仍然会妨碍 SSL。(有意思,但是为什么会come back呢?)因此,如何缓解时间序列 SSL 中的噪声仍然是一个有待解决的难题。
在本文中,我们提出了去噪感知对比学习(DEnoising-aware Contrastive Learning,DECL),这是一个端到端的框架,可以利用任何传统的去噪方法来指导表征中的噪声缓解。具体来说,DECL 包括两个新颖的设计。首先,在自动回归编码器的基础上,我们提出了一种新颖的去噪器驱动的对比学习目标来缓解噪声。其主要思路是通过对原始时间序列应用现有的去噪器来构建正样本,同时通过在同一时间序列中引入噪声来生成负样本。随后,通过使用对比学习目标进行优化,我们引导表征向正样本靠拢,与负样本拉开距离,从而减少噪声。其次,我们引入了自动去噪器选择策略,学会为每个样本选择最合适的去噪器。我们的动机是,在自回归学习中,噪声数据通常会产生较大的重构误差,反之亦然。因此,我们可以用重构误差来代表去噪器对样本的适合程度。我们进一步将这种去噪器选择策略纳入到所提出的去噪器驱动的对比学习中,并对它们进行联合优化。我们将在下文中总结我们的贡献。
- 问题:观察到去除噪声能提高 SSL 的性能,受此启发,我们提出了对噪声时间序列进行自监督学习的问题。
- 算法: 我们提出了一种定制的去噪感知对比学习方法 1,它能为每个样本自动选择合适的去噪方法,从而在表征学习中指导缓解数据噪声。
- 实验结果: 广泛的实验证明了我们方法的有效性。我们还验证了 DECL 在不同程度的噪声下的鲁棒性,并且学习到的表征噪声更小。
(17:47,有事先溜.)
(16日的14:31,昨天中秋节假期第一天,寝室睡了一天,今天来实验室了.)
2 问题陈述
噪声时间序列的自监督学习。给定一组时间序列 D = {x 1 ,x 2 ,...,x N },包含 N 个实例和一定量的噪声 S,目标是以自监督的方式学习一个非线性映射函数 F,将每个时间序列 x i 映射到最能描述自身的表征 z i 上。具体来说,对于具有 T 个时间戳和 d 个特征维度的时间序列样本 x i = [x i,1 ,x i,2 ,...,x i,T ]∈ R T×d,涉及噪声 s i = [s i,1 ,s i,2 ,...,s i,T ]∈ R T×d,去噪数据为 v i = [(x i,1 -s i,1 ),(x i,2 -s i,2 ),...,(x i,T -s i,T )];映射函数 F 的目的是学习一个表征 z i = [z i,1 ,z i,2 ,......z i,C ]∈R C×r,其中 z i,t∈R r 是时间戳 t 的表征,有 r 个维度。
3 方法论
在本节中我们介绍所提出的去噪感知对比学习(DECL),如图 2 所示。它由三个部分组成: (i) 自回归学习,用于在潜在空间生成信息表征;(ii) 去噪器驱动的对比学习,利用去噪方法指导表征学习中的噪声缓解;(iii) 自动去噪器选择,为学习中的每个样本选择合适的去噪方法。
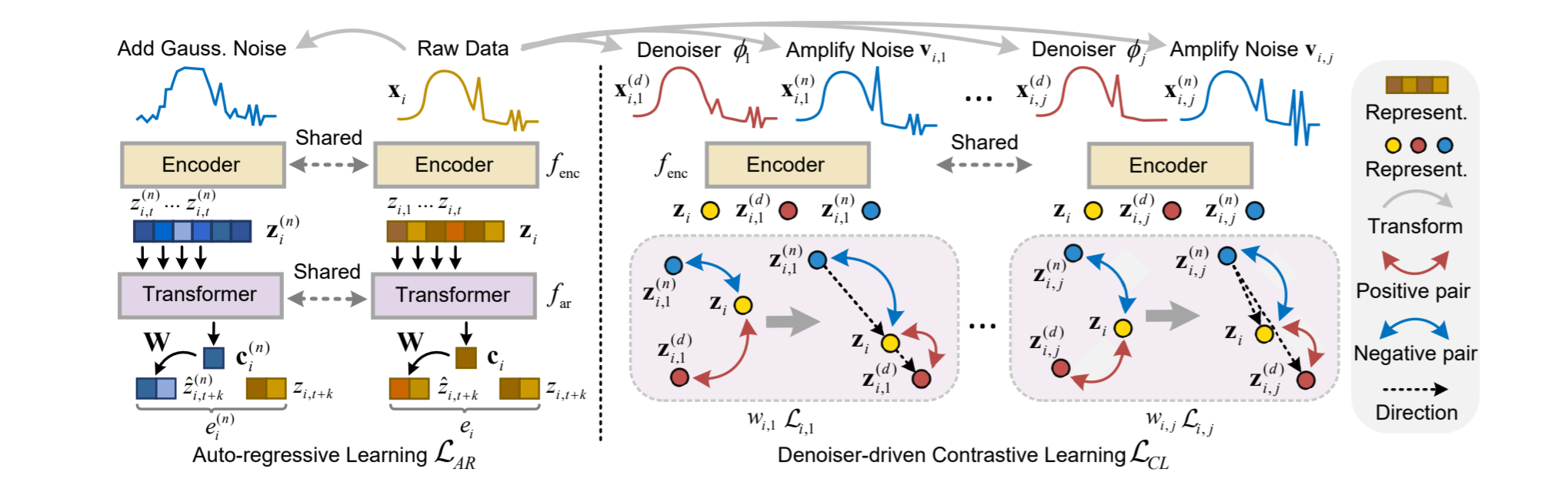
图 2:DECL 方法概述。它包括:(i) 自回归学习,将原始数据映射到潜在空间,并利用表征进行 SSL;(ii) 去噪器驱动的对比学习,利用去噪方法ϕ j建立正样本 z(d)i,j,放大相应的噪声以建立负样本 z(n)i,j,并在表征学习中缓解噪声;(iii) 自动去噪器选择,向数据注入高斯噪声以避免过拟合,并为对比学习确定合适的去噪方法。
3.1 自回归学习
其目的是通过编码器将原始数据映射到潜在空间,并利用获得的表征进行自监督学习。具体来说,它包括一个编码器 f enc(3 块卷积结构)和一个自回归(AR)模块 f ar。对于输入 x i,编码器将其映射为高维潜在表征 z i = f enc (x i),其中 z i ∈R C×r。然后,对于表征 z i,AR 模块将所有 z i,j≤t = {z i,1 ,z i,2 ,..., z i,t } 总结为上下文向量 c i =f ar (z i,j≤t ),c i ∈R h,其中 h 是 f ar 的隐藏维度。上下文向量 c i 用于预测从 z i,t+1 到 z i,t+k 的未来时间步(1 ≤ k < C),z i,t+k ∈ R r,其中 k 是预测的时间步数,r 是 f enc 的输出通道数。在这里,我们使用 Transformer [Vaswani 等人,2017] 作为 f ar,它由连续的多头注意力块组成,然后是一个 MLP 块。我们堆叠 L 层相同的层来生成预测。为了利用 c i 预测从 z i,t+1 到 z i,t+k 的时间步长,我们采用了一个参数为 W∈R h×r 的线性层,将 c i 映射回与 z i 相同的维度。最后,我们得到 zˆ i,t+1 直至 zˆ i,t+k 的预测时间步。因此,x i 的重构损失 e i 可以通过 z i,t+j 与 zˆ i,t+j 之间的均方误差来计算:
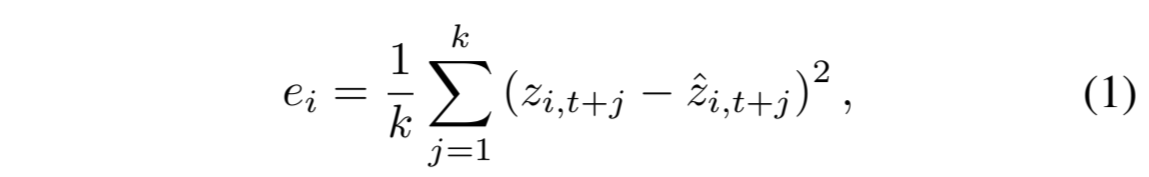
其中,z i,t+j 来自 z i,zˆ i,t+j 是预测值。最小化重构损失可以联合学习 f enc 和 f ar,从而生成信息丰富的表征。
3.2 去噪器驱动的对比学习
考虑到噪声可能会在潜在空间中被放大,我们建议通过去噪器驱动的对比学习直接消除表征中的噪声。我们的动机是,如果使用得当,传统的去噪方法已被证明能有效去除噪声[Zheng 等人,2020];直观地说,去噪数据的表征比原始数据的表征受到的噪声更少,可以作为正样本来指导学习。反之亦然,放大原始数据中的噪声也是可行的,噪声增强后的数据表征并不理想,可以作为负样本。因此,我们建议在对比学习中利用降噪数据和噪声增强数据,以获得更好的表征。
这包括两个步骤 (1) 为原始数据生成去噪和噪声增强的对应数据,并获得其表征;(2) 将原始数据的表征映射为接近去噪数据的表征(即正样本)和远离噪声增强的对应数据的表征(即负样本)。具体来说,我们首先对原始数据进行数据增强。给定原始数据 x i 的合适去噪方法ϕ j,我们就能生成去噪数据 x (d) i,j 。至于合成噪声增强数据,原理是在相应的噪声类型中添加更多的噪声。为此,我们将原始数据 x i 与经过去噪处理的数据 x (d) i,j 进行比较,以确定哪些是 “噪声”,然后将其放大。具体来说,我们首先用 x i 减去 x (d) i,j 来获得数据噪声 v i,j,它已被去噪方法ϕ j去除。然后,我们对 v i,j 的值进行缩放,进一步放大噪声,之后再将其加回 x i。这样,我们就得到了原始数据 x i 的噪声增强对应值 x (n) i,j。
数据增强后,我们通过 f enc 获得它们的表征,并执行去噪器驱动的对比学习。给定一个样本 x i 和一种去噪方法 ϕ j,我们首先建立一个三重表征 A(z i ,ϕ j ) 如下:
![]()
其中,z (n) i,j 和 z (d) i,j 是 x (n) i,j 和 x (d) i,j 的表征,在对比学习中分别作为负样本和正样本。然后,将表征 z i 作为锚点,我们将锚点拉向正样本,同时将其推离潜在空间中的负样本。此外,考虑到{z i,j ,z i ,z (d) i,j}的三元组是由噪声度从大到小的表征组成的噪声,潜在空间中从大噪声到微小噪声的方向可能表明去噪效果更好。因此,我们也强制要求每个三元组的正负样本到锚点的映射方向必须相反。总的来说,对于数据 x i 和去噪方法 ϕ j,对比学习损失 L i,j 如下所示:
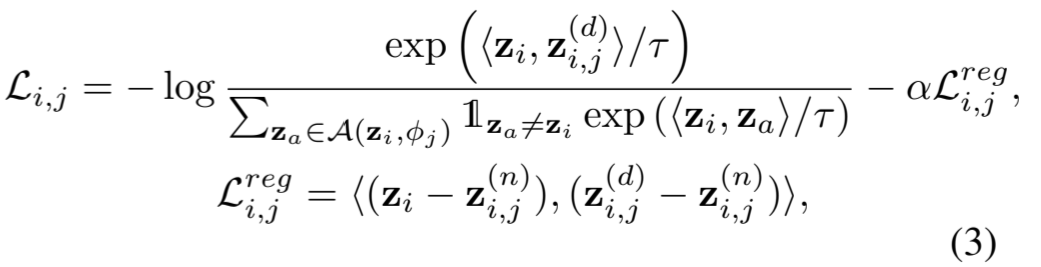
其中,⟨-, -⟩表示余弦相似度,1 z a ̸=z i∈ {0, 1} 是一个二进制指标,当 z a 表示 z i 时等于 0,τ 是一个时间参数,L reg i,j 是一个正则化项,用于将表征 z i 映射到无噪声方向。
3.3 自动去噪器选择
值得注意的是,上述对比学习需要为样本 x i 选择合适的去噪方法 ϕ j。然而,要满足这一要求并非易事。虽然许多传统的去噪方法已被证明能有效去除噪声,但当噪声类型不匹配时,它们可能无法很好地处理给定时间序列 x i 的噪声。为了解决这个问题,我们建议收集一组常用的去噪方法 M={ϕ 1 ,ϕ 2 ,...,ϕ m }(如附录表 2 所示)。(如附录表 2 所示),并从中自动选择合适的方法。
在此,我们建议利用 f ar 的重构误差来确定 M 中的合适方法。我们的灵感来自于噪声数据通常会导致相对较大的重构误差(噪声数据在潜在空间中放大误差的原因主要是由于非线性映射对噪声敏感、压缩过程中信号与噪声的混合、数据结构的破坏,以及模型可能过拟合噪声信息等因素。这些因素共同作用,导致在重构过程中噪声的影响被进一步放大,从而导致更大的重构误差)。因此,用合适的去噪方法处理的数据会产生较小的重构误差,而不合适的方法则会产生较大的误差。这样,M 中的合适方法就能自动为每个样本 x i 确定。不过,直接使用上述重构误差(公式(1))作为学习目标可能达不到目的。这是因为 AR 模块可能会过度拟合噪声数据,从而使原始数据的重构误差小于去噪数据。为了解决这个问题,我们提出了另一个正则化项,鼓励 f ar 从噪声时间序列中学习全局模式,避免过度拟合。其主要思路是用更多的噪声来增强数据,将其表征输入 f ar,并强制重构噪声较小的原始数据(通过噪声增强和正则化,结合Transformer的自注意力机制,使得模型能够捕捉时序数据的全局模式,避免过拟合到局部噪声。这种设计使得Transformer特别适合处理复杂的时序数据,并能在包含噪声的情况下学到全局模式。)。具体来说,我们在原始数据中加入高斯噪声进行数据增强,并将其映射到潜在空间,从而得到如下表示 z (n) i:
![]()
同样,我们将 z(n)i,j <=t 输入 f ar,得到 c(n) i 和预测结果 z^(n) i, t+j。从形式上看,自回归学习的总体学习目标是:
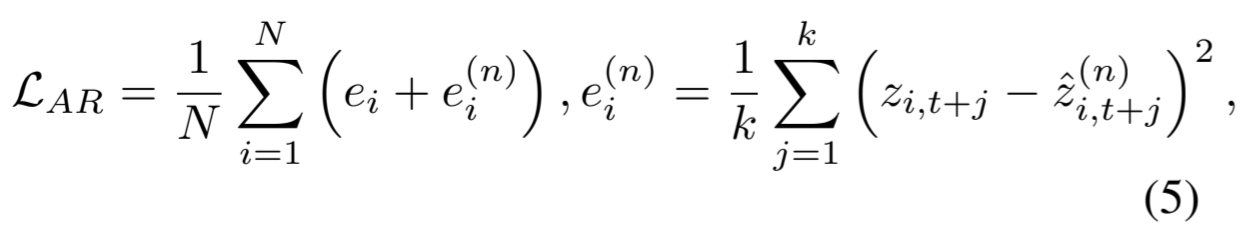 其中 N 是训练样本的数量。在优化过程中,L AR 鼓励从噪声时间序列中捕捉全局模式进行预测,从而避免对原始数据的过度拟合。因此,经过合适的去噪方法处理的样本最终会比原始数据拥有更小的重构误差,利用重构误差进行自动选择是可行的。
其中 N 是训练样本的数量。在优化过程中,L AR 鼓励从噪声时间序列中捕捉全局模式进行预测,从而避免对原始数据的过度拟合。因此,经过合适的去噪方法处理的样本最终会比原始数据拥有更小的重构误差,利用重构误差进行自动选择是可行的。
考虑到一个数据样本可能包含多种类型的噪声,需要不同的去噪方法,我们将 M 中所有合适的方法赋予较大权重,同时为不合适的方法设定较小的权重。具体来说,我们首先将去噪方法ϕ j处理过的样本 x (d) i,j 输入优化后的 f ar,并根据公式 (1) 得到重构误差 e i,j。然后,我们用 Softmax 函数计算ϕ j的权重值 w i,j 如下:
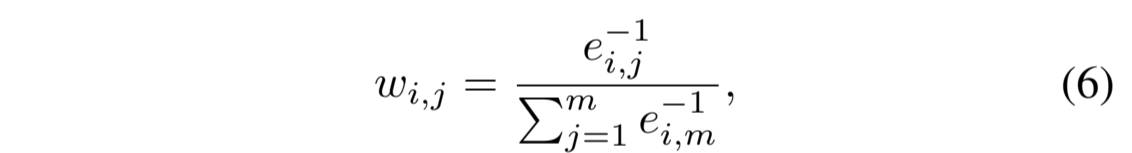 其中,m 是 M 中方法的数量。因此,对比学习目标 L CL 是 M 中去噪方法 L i, j 的加权组合,即:
其中,m 是 M 中方法的数量。因此,对比学习目标 L CL 是 M 中去噪方法 L i, j 的加权组合,即:
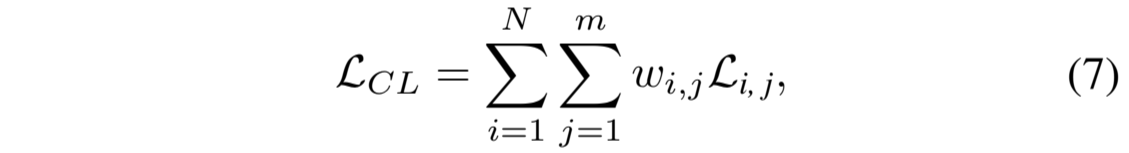
其中,N 是训练样本的数量,w i,j 是方法ϕ j的权重得分。通过最小化 L CL,我们的方法鼓励将原始数据的表征映射到无噪声的方向,从而缓解潜在空间的数据噪声。最后,我们将自回归学习和对比学习结合起来进行联合优化:
![]()
其中,γ 是平衡两个项的权重值。
(现在21:46,还差一页看完了,明天看,打算回寝室了,溜溜球,明天看完+做PPT.)
(17号,今天中秋节,假期快乐,哈哈哈哈哈哈哈哈哈哈,今天早上吃了一堆月饼,好撑,哈哈哈哈哈哈哈哈哈,现在15:28,继续看论文,收尾.)
4 实验
我们进行了实证评估,以回答以下研究问题: 问题 1:DECL 对无监督表征学习的效果如何?问题 2:该方法在微调后是否有效?问题 3: 每个组件的效果如何?问题 4: DECL 在不同程度的噪声下是否稳健?问题 5: 它对超参数有多敏感?问题 6:该方法的实际效果如何?
4.1 数据集
我们使用了五个噪声时间序列数据集。SleepEDF [Goldberger 等人,2000 年] 是一个脑电图数据集,其中每个样本都记录了人脑的活动。FaultDiagnosis [Lessmeier 等人,2016] 中的数据来自轴承机器在不同工作条件下的传感器读数。CPSC18 [Liu 等人,2018]、PTB-XL [Wagner 等人,2020] 和 Georgia [Alday 等人,2020] 是心电图数据集,其中每个样本都反映了心脏活动。数据统计如表 1 所示。详见附录 A.1。
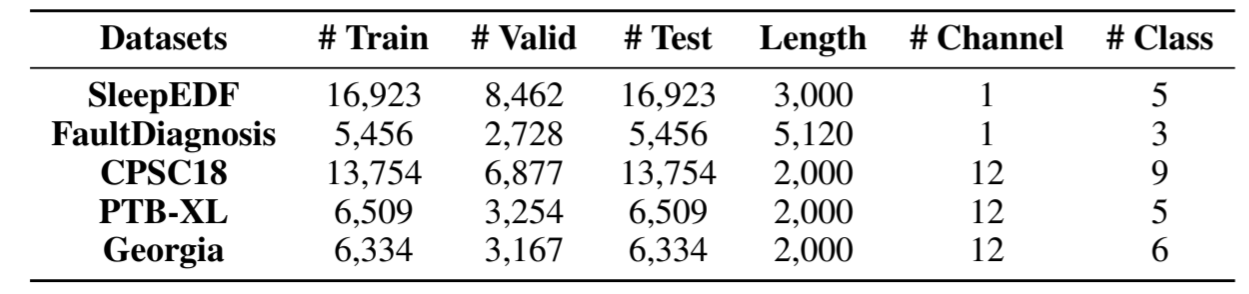
表 1:噪声时间序列数据集的统计数据。
4.2 实验设置
比较方法。我们将我们的方法与具有代表性的 SSL 方法进行比较,包括基于对比学习的方法,如 TF-C [Zhang 等人,2022]、TS2vec [Yue 等人,2022]、TS-CoT [Zhang 等人,2023b] 和 CA-TCC [Eldele 等人,2023],以及基于生成的方法,如 CRT [Zhang 等人,2023c] 和 SimMTM [Dong 等人,2023]。我们将在附录 A.2 中提供详细说明。
评估指标。我们沿用了之前的作品[Eldele 等人,2023][Yue 等人,2022],采用准确率和加权-F 1 分数进行分类性能评估。
实施细节。我们将数据分成 40%、20% 和 40%,分别用于训练集、验证集和测试集。我们将学习epochs设为 100,并将预训练和下游任务的batch大小设为 128,因为我们注意到训练损失不会进一步减少。在transformer中,我们设置 L 为 4,heads为 4,隐藏维度大小为 100。编码器和 AR 模块的详情可参见附录 C.2。至于超参数,我们将 k 设为时间戳总数的 30%,将 α 设为 0.5,并将所有数据集的γ 设为 0.1。我们使用 Adam 优化器对该方法进行了优化,将学习率设为 1e-4,权重衰减设为 5e-4。我们从相关论文中收集了针对不同类型时间序列的常用去噪方法,并应用报告中的超参数或默认参数进行去噪(详见附录表 2)。对于基线,我们选择在下游任务验证集上性能最佳的超参数。为了进行公平比较,我们对所有基线的原始数据进行了预处理:(i) 对数据集应用 M 中的每种去噪方法,并报告性能最好的方法(即 DN);(ii) 结合所有去噪方法进行除噪(即合并)。我们进行了 10 次实验,并报告了平均结果。
4.3 表征的线性评估(问题 1)
我们首先使用未标注数据预训练 SSL 方法进行表征学习,然后使用部分标注数据(即 10% 和 30%)评估所学表征的有效性。按照标准的线性评估方案[Eldele 等人,2023],我们固定自监督预训练模型的参数并将其视为编码器,然后在编码器之上训练线性分类器(单全连接层)。表 2 和附录表 1 显示了 10%和 30%训练标签的结果。我们发现,现有的 SSL 方法在噪声数据上的性能都不理想,而在采用合适的去噪方法进行降噪后,性能会得到提升。此外,直接结合所有去噪方法进行预处理会导致性能不理想。这是因为当噪声类型不匹配时,某些去噪方法可能会给数据带来额外的噪声。此外,与其他 SSL 方法相比,DECL 实现了更优越的性能。具体来说,在 CPSC18 数据集上,DECL 的性能比最佳基线提高了约 3%。这是因为我们的方法利用了合适的去噪方法来缓解噪声并引导表征学习。
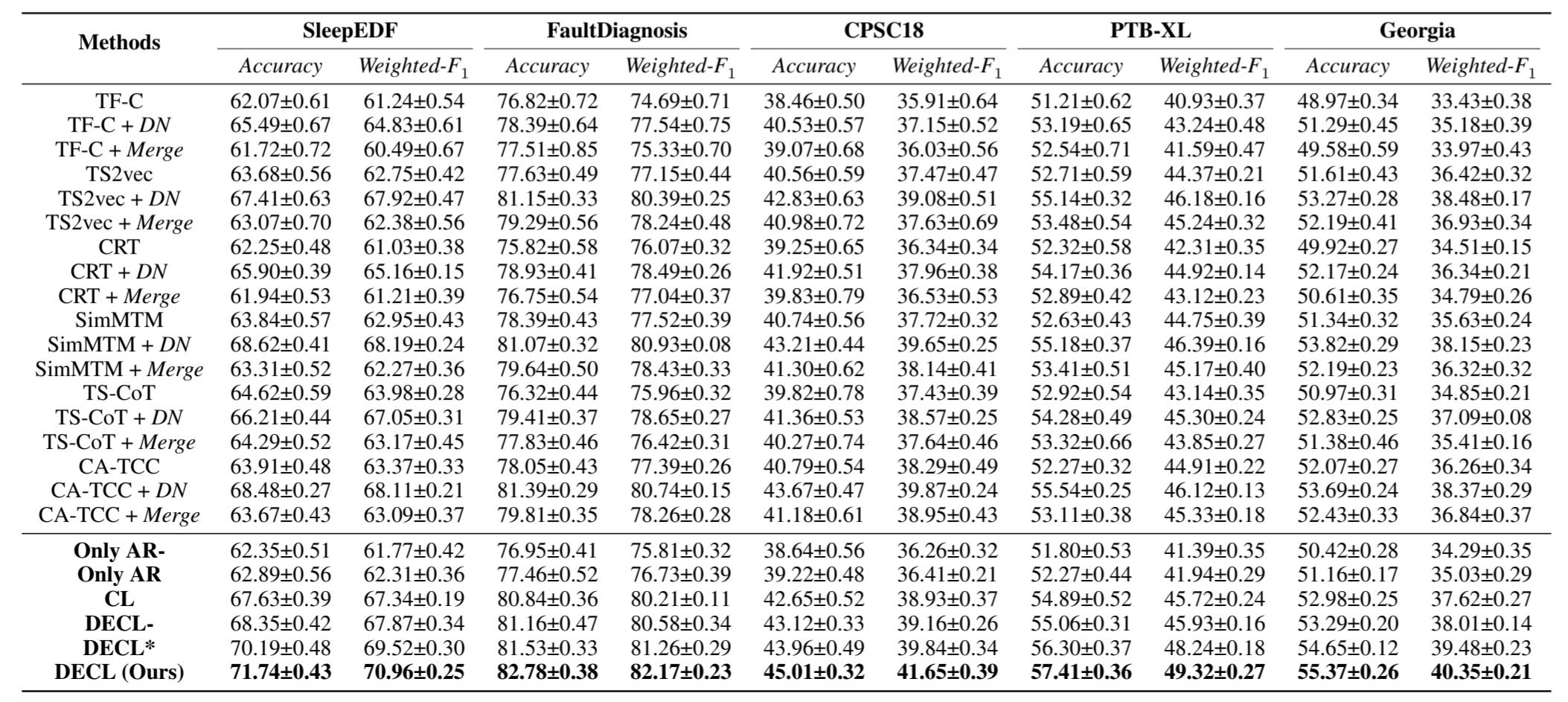
表 2: 数据集的整体性能(%)比较。DN 表示采用合适的去噪方法进行预处理。
4.4 微调性能评估(问题 2)
为了模拟现实世界中只能获得少量标签数据的场景,我们使用标签对预训练模型进行了微调,并研究了其有效性。有两种设置。
在源数据集上进行微调。按照之前的研究成果 [Lan 等人,2022],我们先用无标签数据对模型进行预训练,然后用同一数据集中不同数量的训练标签(即 1%、5%、10%、50%、75% 和 100%)对模型进行微调。图 3 显示了在三个数据集上与监督学习和强基线的性能比较。我们发现,在有限的标注数据(如 1%)下,监督学习的性能很差,而微调模型的性能要好得多。这验证了自监督预训练可以缓解标签稀缺问题。此外,在使用不同比例的训练标签进行微调时,DECL 的表现优于强基线。简而言之,这表明了我们的方法在微调模式下的有效性。
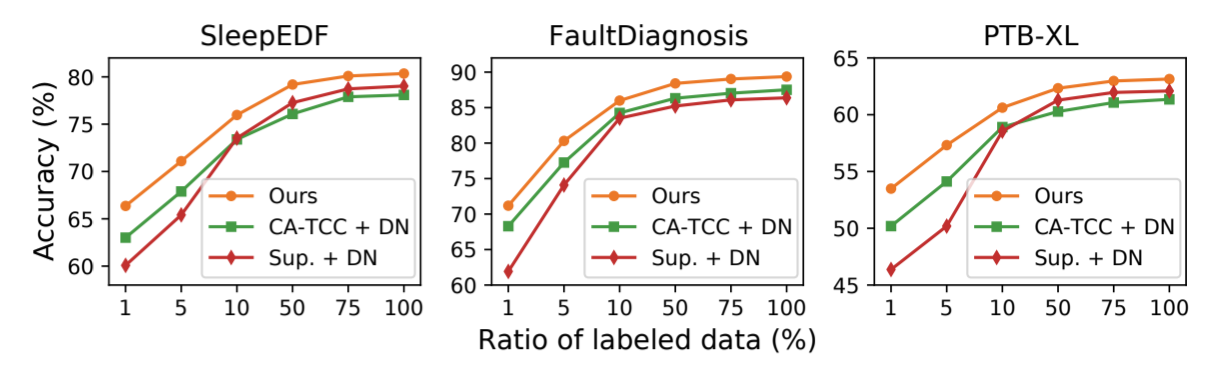
图 3:使用不同百分比的标记数据进行半监督表征学习的性能比较。
在新数据集上进行微调。为了评估学习到的表征的通用性,我们进一步在一个数据集上对模型进行预训练,并在另一个数据集上进行有监督的微调。具体来说,我们遵循一对一的评估方案(Zhang 等人,2022 年),使用部分标注数据(10%)进行微调。表 3 显示了心电图数据在六种跨数据集情况下的结果。同样,我们发现,与应用一种合适的去噪方法相比,将所有去噪方法结合起来会使基线的性能不尽如人意。此外,我们的微调模型始终优于强基准。此外,在综合数据集(如 CPSC18)上进行预训练通常能在新数据集上获得更好的性能,这与相关论文的研究结果一致[Yang 等,2023]。总之,这些结果验证了 DECL 能够缓解噪声对学习信息表征的影响,并在跨数据集场景下具有良好的泛化能力。
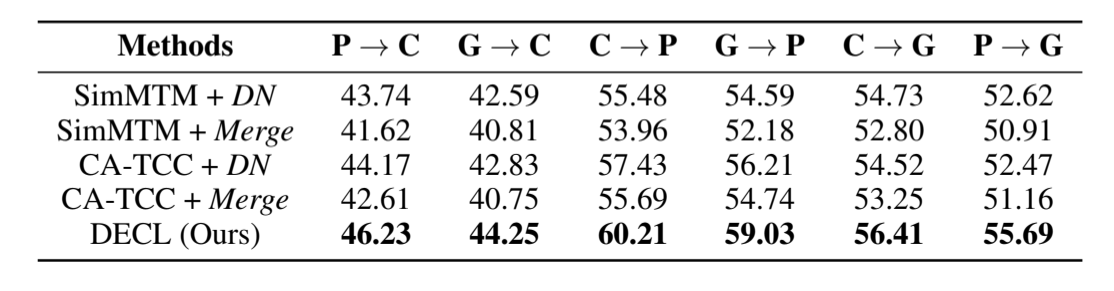
表 3:在 CPSC18 (C)、PTB-XL (P) 和格鲁吉亚 (G) 数据集上进行的可移植性评估的性能(准确率%)。
4.5 消融研究(问题 3)
我们还研究了 DECL 中各组成部分对其整体性能的影响。具体来说,我们推导出不同的方法变体进行比较:(1) DECL-,在自回归学习中去掉正则化项,其他不变;(2) DECL*,在对比学习中去掉方向约束;(3) CL,给去噪方法分配相等权重,其他不变;(4) Only AR,仅利用 L AR 作为学习目标;(5) Only AR-,利用 L AR,去掉正则化项。结果如表 2 所示。我们发现,(i) 仅仅利用 L AR 的效果并不理想。这是因为潜在空间中的噪声无法消除,阻碍了表征学习。(ii) 我们的方法优于 CL 和 DECL-,说明同等重视去噪方法会阻碍表征学习,而 L AR 中的正则化项有利于提高整体性能。(iii) 我们的方法取得了比 DECL* 更高的性能,说明对比学习中的方向约束有助于消除表征学习中的噪声。
4.6 对数据噪声的鲁棒性分析(问题 4)
我们进一步研究了 DECL 对不同程度数据噪声的鲁棒性。具体来说,我们在原始数据中引入高斯噪声(均值为零、标准偏差各不相同),然后进行线性评估以比较性能。三个数据集的结果如图 4 所示;更多结果见附录 B.2。我们有两个有趣的发现 (i) 随着噪声量的增加,各种方法的性能逐渐下降。这是因为所采用的去噪方法无法充分消除噪声,从而影响了表征学习。(ii) 我们的方法始终优于强基线。因为 DECL 会为每个样本选择合适的去噪方法,并通过对比学习进一步减少表征中的噪声。
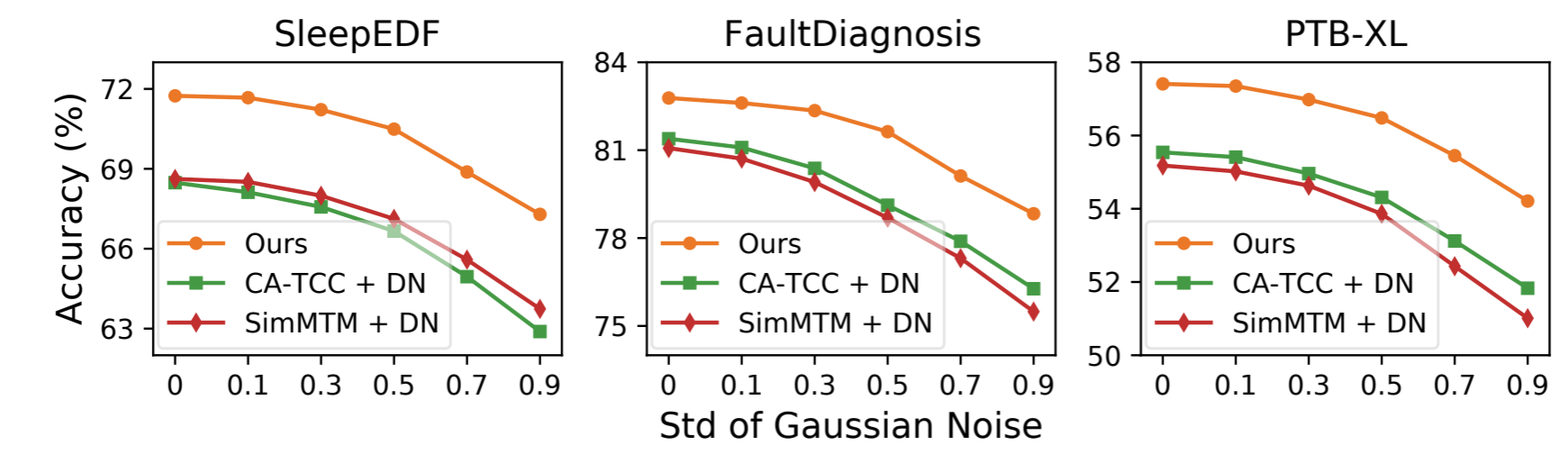
图 4:不同程度数据噪声下的无监督表征学习性能。
4.7 敏感性分析(问题 5)
我们进行敏感性分析,研究主要的超参数:式(5)中预测的未来时间步数 k、式(3)中的权重 α 和式(8)中的权重 γ。 具体来说,我们采用与线性评估实验相同的设置,在图 5 中展示了 PTB-XL 数据集的结果,并在附录 B.3 中展示了更多结果。我们首先分析 k 的影响,其中 x 轴表示 k/C 的百分比,C 是总的时间步数。结果表明,随着百分比值的增加,性能先上升后下降。因此,我们建议在实践中将其设置为 0.1-0.4 的范围。关于超参数 α 和 γ,当提高其值时,性能会先升后降。出现这种情况的原因是,过小或过大的参数值都无法实现学习目标之间的平衡。有鉴于此,我们建议将 α 的值设置为 0.1-5,将 γ 的值设置为 0.1-1。

图 5:超参数分析结果。
4.8 可视化结果(问题 6)
正则化项的效果。在此,我们将研究 L AR 中提出的正则化项(见公式 (5))能否缓解过拟合问题,并使重构误差成为选择合适去噪方法的指标。具体来说,我们通过在 PTB-XL 数据集上重构误差分布的可视化,比较了使用 L AR(即带正则化)学习的模型和不带正则化的模型。详见附录 B.4。图 6 中的结果显示:(i) 在没有正则化项的情况下,原始数据和去噪数据的重构误差分布变得相似,因此很难使用重构误差作为指标。(ii) 加入正则化项后,重构误差的分布更加明显。简而言之,这验证了所提出的正则化项确实可以缓解过拟合,有利于确定合适的去噪方法。
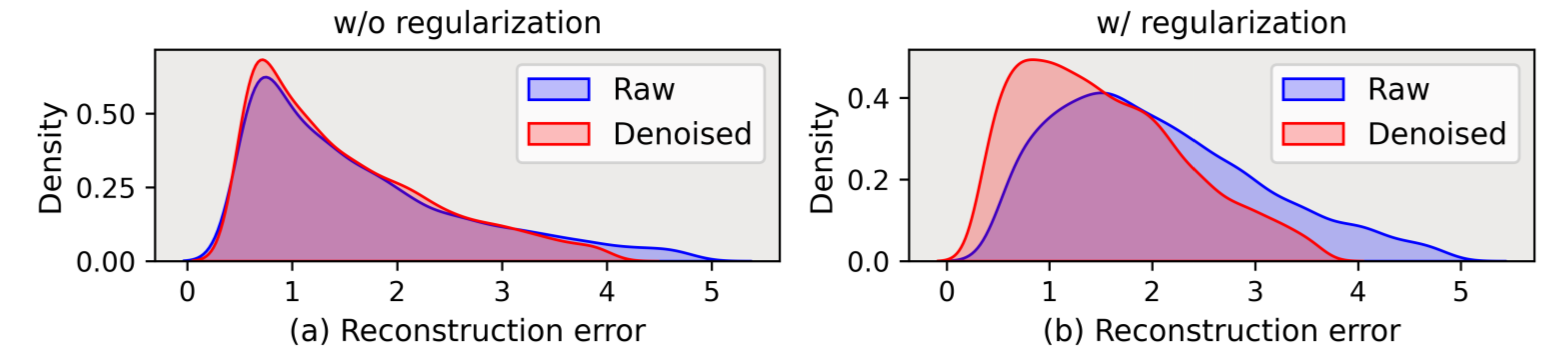
图 6:原始数据与去噪数据的重构误差分布对比。添加正则化后,分布差距更加明显。
对选定去噪方法的分析。我们还验证了 DECL 能否为合适的去噪方法分配更多权重。具体来说,我们通过 PTBXL 数据集的案例研究,(i) 直观展示了 M 中去噪方法在高频噪声样本中的权重值,(ii) 展示了原始数据和去噪后的对应数据,以检验去噪效果。如图 7(a)所示,AR 模块为一组可能可行的去噪方法分配了不同的权重。例如,据报道可去除心电图高频噪声的 LOESS 方法(Burguera,2018 年)获得了较大的权重值;而不适合这类噪声的 PCA 方法(Alickovic 和 Subasi,2015 年)则拥有较小的权重值。我们在图 7(b)中进一步展示了用 LOESS 对数据进行去噪处理的结果,这表明噪声得到了很好的缓解。然而,如图 7(c)所示,用 PCA 方法去噪的数据仍然存在严重的噪声。更多结果见附录 B.5。上述分析证明,我们的方法可以自动选择合适的噪声时间序列去噪方法。
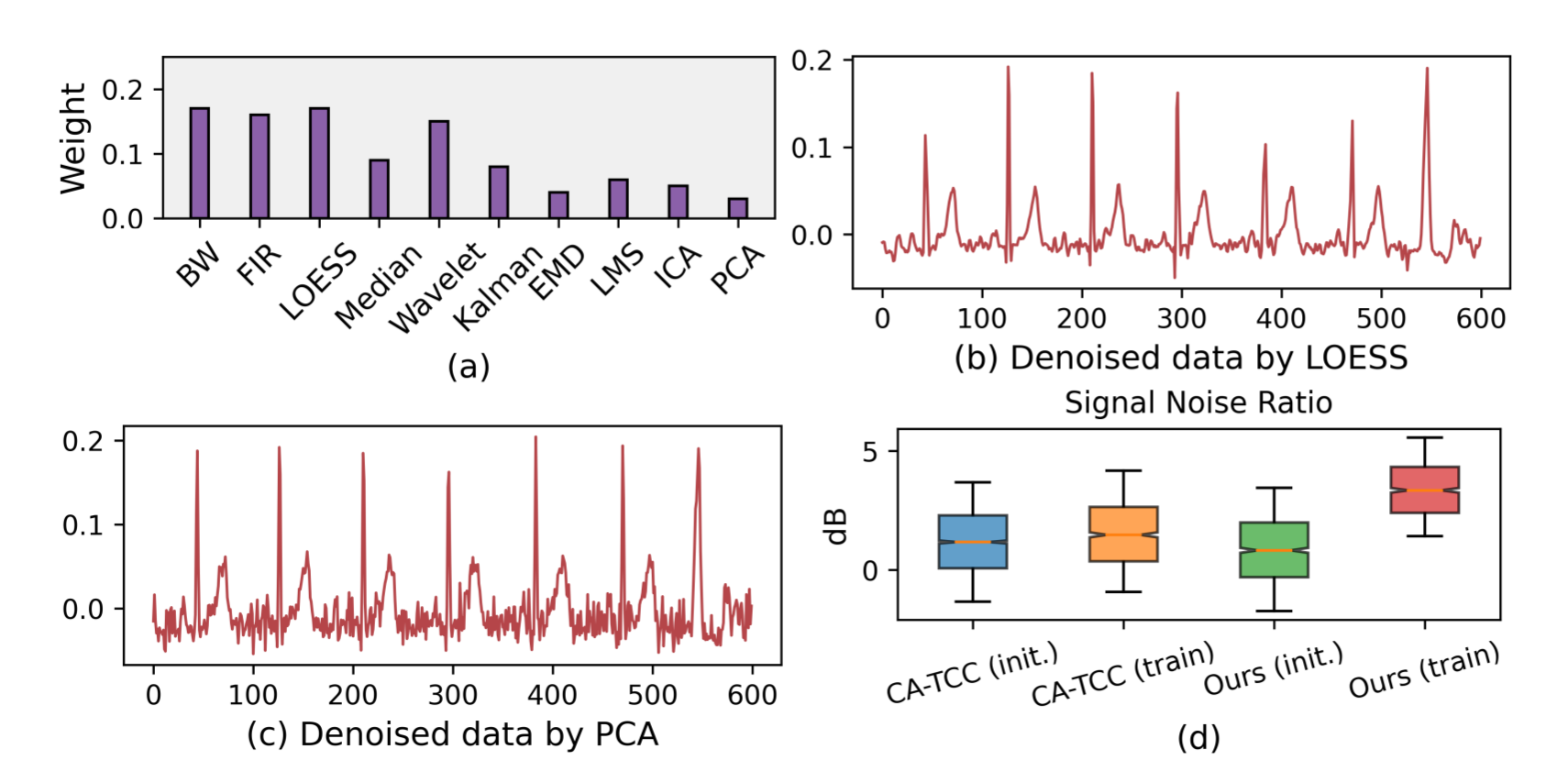
图 7:(a-c) 去噪方法的学习权重及其效果。(d) 信噪比对代表性的影响比较。
对学习表征的分析。此外,我们还分析了 DECL 对表征的影响。与试验研究类似,我们在原始数据中引入一些高斯噪声,然后比较随机初始化表征法和优化后学习表征法的信噪比值。PTB-XL 数据集的结果如图 7(d)所示。我们观察到,强基准 CA-TCC 的信噪比值在训练后几乎保持稳定,而我们的方法的信噪比值得到了显著提升。详细说明见附录 B.6。这些分析验证了 DECL 确实可以缓解表征学习中的噪声。
5 相关工作
5.1 时间序列自监督学习
为了缓解监督学习对大量标注训练数据的依赖,越来越多的研究关注以自监督方式学习时间序列的表征。时间序列 SSL 方法大致分为三类[Zhang 等人,2023a]:(1) 基于对比的方法[Meng 等人,2023b][Ma 等人,2023][Meng 等人,2023a],其特点是构建正样本和负样本进行对比学习;(2) 基于生成的方法[Zerveas et al、 2021][Li等人,2022],其特点是最小化原始数据与生成的对应数据之间的重构误差,用于模型学习;(3)基于对抗的方法[Seyfi等人,2022],通常利用生成器和判别器进行对抗学习。其中,基于对比的方法是最主要的方法。对比学习的关键步骤包括建立相似(正向)和不相似(负向)的数据样本对,并将正向样本对的表征映射到附近,同时将负向样本对的表征映射到更远的地方。基于对比的方法可进一步分为基于采样的方法[Yeche`等人,2021][Tonekaboni等人,2021]、基于增强的方法[Yue等人,2022][Yang和Hong,2022]和基于预测的方法[Oord等人,2018][Deldari等人,2021]。最近一种名为 TS-CoT 的方法[Zhang 等人,2023b]假定来自不同视图的互补信息可用于缓解数据噪声。与之不同的是,我们的方法利用传统去噪方法的力量来指导表征学习。更多详情见附录 D.1。
5.2 时间序列去噪
现有的时间序列去噪方法可分为两类:传统方法和基于学习的方法。传统方法包括经验模式分解法 [Huang 等人,1998 年]、小波滤波法 [Chaovalit 等人,2011 年]、基于稀疏分解的贝叶斯滤波法 [Barber 等人,2011 年],以及用于降噪的混合方法(如基于小波的 ICA [Castellanos 和 Makarov,2006 年])。传统方法的优势在于,如果适当采用与噪声类型相匹配的方法,会产生很好的去噪效果。然而,选择合适的去噪方法需要事先了解相关知识或反复试验。为了避免人工操作,近年来提出了许多基于学习的方法,可以缓解噪声的影响。根据网络结构,这些方法包括小波神经网络、基于 RNN 的方法 [Zhang 等人,2023d][Yoon 等人,2022] 和自动编码器 [Zheng 等人,2022]。与前人不同的是,我们的工作利用传统的去噪方法来指导学习中的降噪,这结合了两类方法的优点。
6 结论
在这项工作中,我们研究了缓解时间序列 SSL 数据噪声影响的问题。因此,我们提出了一种端到端的方法,称为 “去噪感知对比学习”(DECL),用于消除表征学习中的噪声。它能为每个样本自动选择合适的去噪方法来指导学习,并执行定制的对比学习,以获得无噪声表征。广泛的实证结果验证了我们方法的有效性。此外,我们还进行了全面的分析,以验证我们的主张,如重构误差的分布可视化和所选方法的去噪效果可视化。未来的工作可以探索:(i) 如何自动确定去噪方法的合适超参数;(ii) 研究该方法在更多下游任务(如预测和异常检测)中的有效性[Lai 等人,2021]。
(现在17:32,看完了.)
总结:对比学习正负样本到锚点的映射方向,还要再看一下。
反思:一篇论文看了五天,你怎么回事,你好好反省一下好不好,为什么效率这么低,你在干啥呢老铁???!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号