
TS2Vec: 面向通用的时间序列表示《TS2Vec: Towards Universal Representation of Time Series》(时间序列、对比学习、多尺度特征(池化操作)、分层对比、上下文一致性(时间戳掩码+随机裁剪))
今天是2024年5月22日,10:24,今天看这篇经典的论文(如果你问我为什么最近频繁看论文,因为我的创新点无了,要找创新点+太菜了,菜就多看多学)。
论文:TS2Vec: Towards Universal Representation of Time Series
或者是:TS2Vec: Towards Universal Representation of Time Series
GitHub:https://github.com/zhihanyue/ts2vec(已跑,可.)
AAAI 2022的论文。
(不保证翻译能完美表达作者的内容,因为是机翻的,我人是看的原文,机翻方便写博客.)
摘要
本文介绍了 TS2Vec,这是一个用于学习任意语义层次的时间序列表示的通用框架。与现有方法不同的是,TS2Vec 在增强上下文视图上以分层方式执行对比学习,从而为每个时间戳提供稳健的上下文表示。此外,要获得时间序列中任意子序列的表示,我们可以对相应时间戳的表示进行简单的聚合。我们在时间序列分类任务中进行了大量实验,以评估时间序列表示的质量。结果表明,在 125 个 UCR 数据集和 29 个 UEA 数据集上,TS2Vec 比现有的无监督时间序列表示 SOTAs 有了显著提高。学习到的时间戳级表示在时间序列预测和异常检测任务中也取得了优异成绩。在所学表征基础上训练的线性回归结果优于之前的时间序列预测 SOTAs。此外,我们还提出了一种简单的方法,将学习到的表征用于无监督异常检测,从而在文献中确立了 SOTA 的结果。源代码可在 https://github.com/yuezhihan/ts2vec 公开获取。
1 引言
时间序列在金融市场、需求预测和气候建模等多个行业中发挥着重要作用。学习时间序列的通用表示是一个基本但具有挑战性的问题。许多研究(Tonekaboni、Eytan 和 Goldenberg,2021 年;Franceschi、Dieuleveut 和 Jaggi,2019 年;Wu 等人,2018 年)侧重于学习实例级表征,这种表征描述了输入时间序列的整个片段,并在聚类和分类等任务中取得了巨大成功。此外,最近的研究(Eldele 等人,2021 年;Franceschi、Dieuleveut 和 Jaggi,2019 年)采用了对比损失来学习时间序列的内在结构。然而,现有方法仍存在明显的局限性。
首先,实例级表征可能不适合需要细粒度表征的任务,例如时间序列预测和异常检测。在这类任务中,人们需要推断特定时间戳或子序列的目标,而整个时间序列的粗粒度表示不足以达到满意的性能。
其次,现有方法很少能区分不同粒度的多尺度上下文信息。例如,TNC(Tonekaboni、Eytan 和 Goldenberg,2021 年)可区分长度不变的片段。TLoss(Franceschi、Dieuleveut 和 Jaggi,2019 年)使用原始时间序列中的随机子序列作为正样本。然而,它们都没有在不同尺度上对时间序列进行特征描述,以捕捉尺度不变的信息,而这对时间序列任务的成功至关重要。直观地说,多尺度特征可以提供不同层次的语义,提高学习表征的泛化能力。
第三,大多数现有的无监督时间序列表示方法都受到 CV 和 NLP 领域经验的启发,这些方法具有很强的归纳偏差,如变换不变性和裁剪不变性。然而,这些假设并不总是适用于时间序列建模。例如,裁剪是一种常用的图像增强策略。然而,时间序列的分布和语义可能会随着时间的推移而发生变化,裁剪后的子序列很可能与原始时间序列的分布截然不同。
为了解决这些问题,本文提出了一种名为 TS2Vec 的通用对比学习框架,它能在所有语义层次上对时间序列进行表征学习。它在实例维度和时间维度上分层区分正样本和负样本;对于任意子序列,其整体表示可通过对相应时间戳的最大池化获得。这样,该模型就能以多种分辨率捕捉时间数据的上下文信息,并生成任何粒度的细粒度表示。此外,TS2Vec 的对比目标是基于增强上下文视图,即同一子序列在两个增强上下文中的表示应保持一致。这样,我们就能为每个子序列获得稳健的上下文表示,而不会引入未被重视的归纳偏差,如变换和裁剪不变性。
我们在多个任务中进行了广泛的实验,以证明我们方法的有效性。时间序列分类、预测和异常检测任务的结果验证了 TS2Vec 的学习表征是通用和有效的。
本文的主要贡献概述如下:
- 我们提出了 TS2Vec,这是一个统一的框架,可在不同语义层面学习任意子序列的上下文表示。据我们所知,这是第一项为时间序列领域的各种任务(包括但不限于时间序列分类、预测和异常检测)提供灵活通用表示方法的工作。
- 为了实现上述目标,我们在约束学习框架中采用了两种新颖的设计。首先,我们在实例和时间维度上使用分层对比方法来捕捉多尺度的上下文信息。其次,我们提出了用于正样本对选择的上下文一致性。与以往的技术不同,它更适用于具有不同分布和尺度的时间序列数据。广泛的分析表明了 TS2Vec 对有缺失值的时间序列的鲁棒性,分层对比和上下文一致性的有效性也通过消融研究得到了验证(也经过了时间的验证,分层和上下文一致性确实是有效果的)。
- 在分类、预测和异常检测等三个基准时间序列任务中,TS2Vec 的表现优于现有的 SOTAs。例如,与分类任务中无监督表示的最佳 SOTA 相比,我们的方法在 125 个 UCR 数据集上平均提高了 2.4% 的准确率,在 29 个 UEA 数据集上平均提高了 3.0%。
2 方法
2.1 问题定义
给定 N 个实例的一组时间序列 X = {x 1 , x 2 , --- , x N },目标是学习一个非线性嵌入函数 Temporal Contrast f θ,将每个 x i 映射到最能描述其自身的表示 r i 上。输入时间序列 x i 的维度为 T × F,其中 T 是序列长度,F 是特征维度。表示 r i = {r i,1 , r i,2 , --- , r i,T } 包含每个时间戳 t 的表示向量 r i,t∈ K,其中 K 是表示向量的维度。
2.2 模型架构
TS2Vec 的整体架构如图 1 所示。我们从输入时间序列 x i 中随机抽取两个重叠的子序列,并鼓励在共同的片段上保持上下文表征的一致性。原始输入被送入编码器,编码器通过时间对比损失和实例对比损失进行联合优化。在分层框架中,总损失在多个尺度上求和。
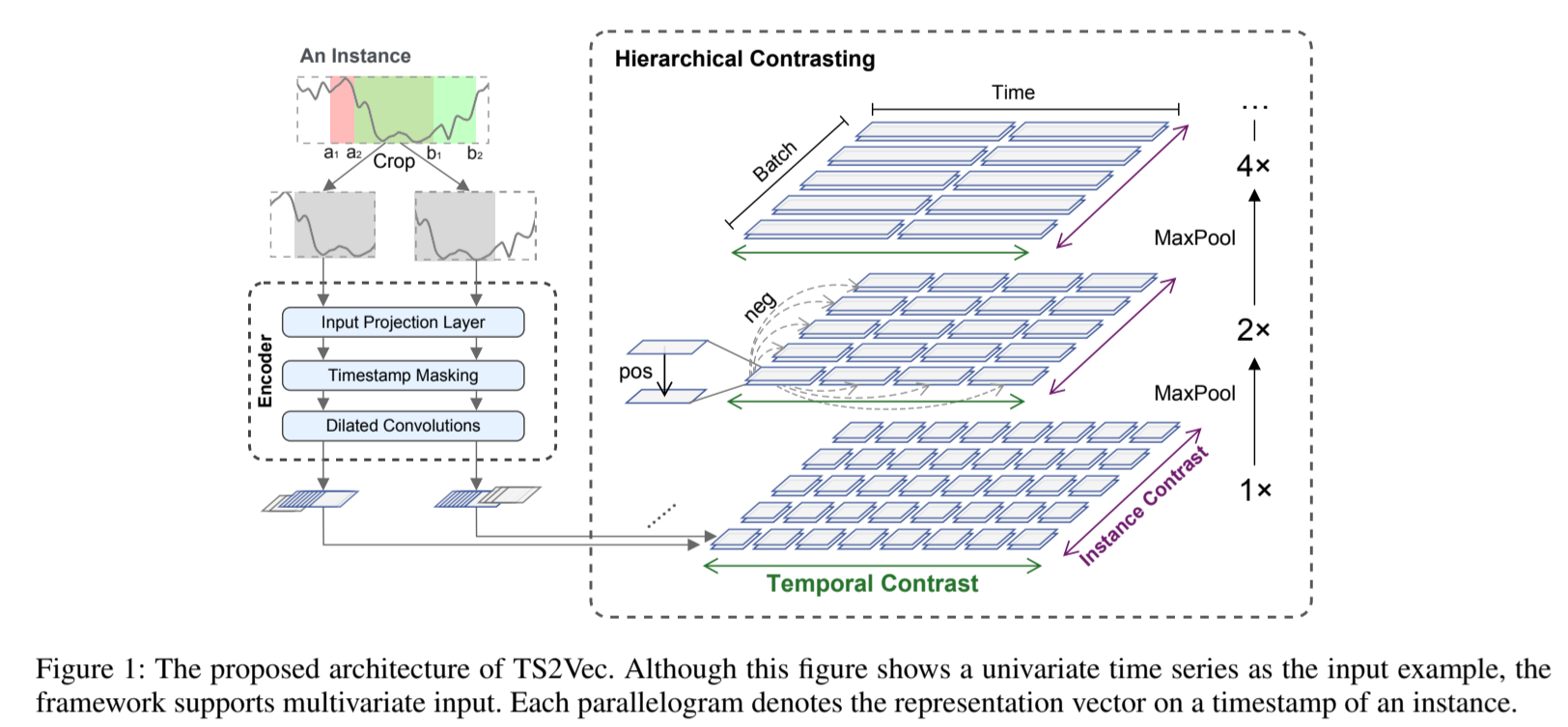
图 1:TS2Vec 的拟议架构。虽然该图显示的是单变量时间序列作为输入示例,但该框架支持多变量输入。每个平行四边形表示实例时间戳上的表示向量。
编码器 f θ 由三个部分组成,包括输入投影层、时间戳掩码模块和扩张 CNN 模块。对于每个输入 x i,输入投影层是一个全连接层,它将时间戳 t 的观测值 x i,t 映射到一个高维潜向量 z i,t 上。时间戳掩码模块会掩码随机选择的时间戳上的潜在向量,生成增强的上下文视图。请注意,我们掩码的是潜在向量而不是原始值,因为时间序列的值范围可能是无界的,而且不可能为原始数据找到特殊的标记。我们将在附录中进一步证明这种设计的可行性。
然后,我们将应用一个包含十个残差块的扩张 CNN 模块来提取每个时间戳的上下文表示。每个区块包含两个 1-D 卷积层,每个卷积层都有一个扩张参数(第 l 个区块为 2 l)。扩张卷积可为不同领域提供大的感受野(Bai、Kolter 和 Koltun,2018 年)。在实验部分,我们将展示它在各种任务和数据集上的有效性。
(12:07,吃午饭去了.)
(14:39,继续看,争取今天看完.)
2.3 上下文一致性
构建正样本对在对比学习中至关重要。以往的研究采用了多种选择策略(图 2),现总结如下:
- 子序列一致性(Franceschi、Dieuleveut 和 Jaggi,2019 年)鼓励时间序列的表示更接近其采样子序列。
- 时间一致性(Tonekaboni、Eytan 和 Goldenberg,2021 年)通过选择相邻的片段作为正样本来加强表示的局部平滑性。
- 变换一致性(Eldele 等人,2021 年)通过不同的变换(如缩放、排列等)来增强输入序列,从而鼓励模型学习变换不变的表征。
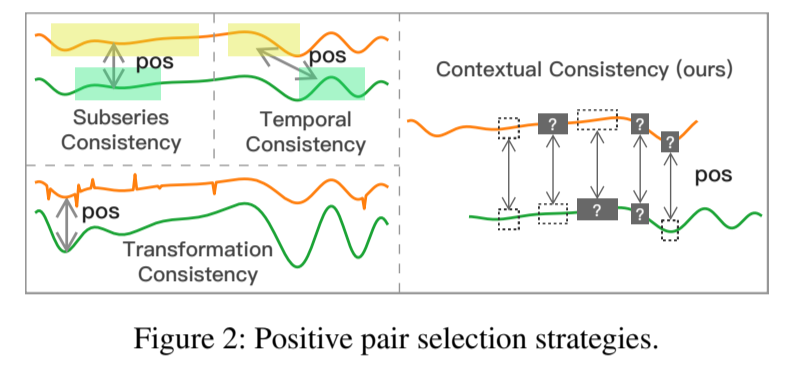
图 2:正样本对选择策略。
然而,上述策略基于数据分布的强假设,可能并不适合时间序列数据。例如,当存在水平移动时,子序列一致性很容易受到影响(图 3a),而当出现异常时,时间一致性可能会引入错误正样本对(图 3b)。在这两幅图中,绿色和黄色部分具有不同的模式,但以往的策略却将它们视为相似的模式。为了克服这一问题,我们提出了一种新策略--上下文一致性,它将两个增强上下文中同一时间戳的表征视为正对。上下文是通过对输入时间序列应用时间戳掩码和随机裁剪生成的。这样做有两个好处。首先,掩码和裁剪不会改变时间序列的幅度,这对时间序列非常重要。其次,它们还能迫使每个时间戳在不同的上下文中进行自我重构,从而提高所学表征的鲁棒性。

图 3:时间序列分布变化的两个典型案例,分别使用子序列一致性和时间一致性对学习到的表示随时间变化的热图进行可视化。
时间戳掩码 我们随机掩码实例的时间戳,以生成新的上下文视图。具体来说,在输入投影层之后,用二进制掩码 m ∈ {0, 1} T 对潜在向量 z i = {z i,t } 沿时间轴进行掩码,掩码元素从伯努利分布中独立采样,采样率为 p = 0.5。在编码器的每个前向传递中,掩码都是独立采样的。
随机裁剪 随机裁剪也用于生成新的上下文。对于任意时间序列输入 x i ∈ T×F,TS2Vec 随机采样两个重叠的时间片段 [a 1 , b 1 ]、[a 2 , b 2 ],使得 0 < a 1 ≤ a 2 ≤ b 1 ≤ b 2 ≤ T。重叠段 [a 2 , b 1 ] 上的上下文表示对于两次上下文回顾应该是一致的。我们将在附录中说明,随机裁剪有助于学习位置无关表征并避免表征崩溃。时间戳掩码和随机裁剪仅应用于训练阶段。
2.4 分层对比
在本节中,我们提出了分层对比损失,迫使编码器学习不同尺度的表征。算法 1 总结了计算步骤。基于时间戳级别的表征,我们沿时间轴对学习到的表征进行最大池化处理,并递归计算等式 3。尤其是在最高语义层的对比使模型能够学习实例层的表征。

与之前的研究相比,分层对比法能实现更全面的表征。例如,T-Loss(Franceschi、Dieuleveut 和 Jaggi,2019 年)仅在实例级别执行实例对比;TS-TCC(Eldele 等,2021 年)仅在时间戳级别应用实例对比;TNC(Tonekaboni、Eytan 和 Goldenberg,2021 年)在特定粒度级别鼓励时间局部平滑。这些研究并没有像 TS2Vec 那样封装不同粒度的表征。
为了捕捉时间序列的上下文表示,我们利用实例损失和时间对比损失共同对时间序列分布进行编码。损失函数适用于分层对比模型中的所有粒度级别。
时间对比损失(Temporal Contrastive Loss) 为了学习随时间变化的判别表征,TS2Vec 将输入时间序列的两个视图中同一时间戳的表征视为正表征,而同一时间序列中不同时间戳的表征视为负表征。假设 i 是输入时间序列样本的索引,t 是时间戳。那么 r i,t 和 r i,t 表示同一时间戳 t 的表示,但来自 x i 的两个增强。第 i 个时间序列在时间戳 t 的时间对比损失可表述为
![]()
其中,Ω 是两个子序列重叠范围内的时间戳集合,是指标函数。
实例对比损失 以 (i, t) 为索引的实例对比损失可表述为
![]()
其中 B 表示批次大小。我们使用同一批次中时间戳 t 处的其他时间序列作为负样本。
这两种损失是相辅相成的。例如,给定一组来自多个用户的用电数据,实例对比可以了解用户的特定特征,而时间对比则旨在挖掘随时间变化的动态趋势。总体损失定义为
![]()
3 实验
在本节中,我们将评估 TS2Vec 在时间序列分类、预测和异常检测方面的学习表示。详细的实验设置见附录。
3.1 时间序列分类
对于分类任务,类是在整个时间序列(实例)上标注的。因此,我们需要实例级表示,这可以通过对所有时间戳进行最大池化获得。然后,我们遵循与 T-Loss (Franceschi、Dieuleveut 和 Jaggi,2019 年)相同的协议,在实例级表示之上训练带有 RBF 内核的 SVM 分类器,以进行预测。
我们对时间序列分类进行了大量实验,以评估实例级表示法,并与其他无监督时间序列表示法的 SOTA 进行比较,包括 T-Loss、TS-TCC(Eldele 等人,2021 年)、TST(Zerveas 等人,2021 年)和 TNC(Tonekaboni、Eytan 和 Goldenberg,2021 年)。采用 UCR 档案(Dau 等人,2019 年)和 UEA 档案(Bagnall 等人,2018 年)进行评估。UCR 中有 128 个单变量数据集,UEA 中有 30 个多变量数据集。请注意,TS2Vec 可在所有 UCR 和 UEA 数据集上运行,TS2Vec 在所有数据集上的完整结果见附录。
表 1 总结了评估结果。与 UCR 和 UEA 数据集上的其他表示学习方法相比,TS2Vec 实现了大幅改进。其中,TS2Vec 在 125 个 UCR 数据集上平均提高了 2.4% 的分类准确率,在 29 个 UEA 数据集上平均提高了 3.0%。图 4 显示了在所有数据集(包括 125 个 UCR 和 29 个 UEA 数据集)上进行的 Nemenyi 测试的临界差异图(Demsarˇ 2006),其中没有用粗线连接的分类器在平均等级上有显著差异。这验证了 TS2Vec 在平均排名上明显优于其他方法。如第 2.3 和 2.4 节所述,T-Loss、TS-TCC 和 TNC 只在一定水平上进行对比学习,并施加了强烈的归纳偏差(如变换不变量)以选择正样本对。TS2Vec 在不同语义层次上进行分层对比学习,因此性能更好。
表 1 还显示了使用 NVIDIA GeForce RTX 3090 GPU 的表征学习方法的总训练时间。在这些方法中,TS2Vec 的训练时间最短。由于 TS2Vec 在一个批次中应用了不同粒度的对比损失,因此大大提高了表征学习的效率。

表 1:与其他时间序列表示方法相比的时间序列分类结果。为进行公平比较,TS2Vec、T-Loss、TS-TCC、TST 和 TNC 的表示维度均设置为 320,并采用 SVM 评估协议。
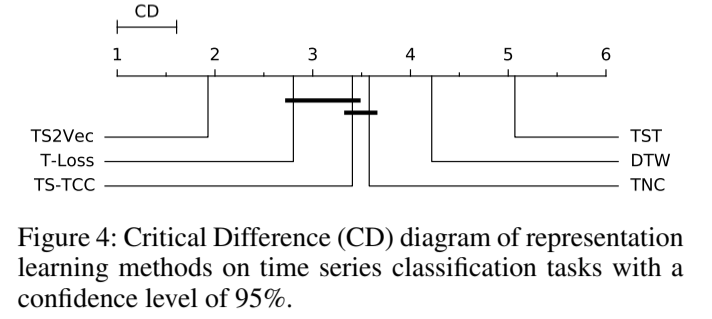
图 4:表征学习方法在置信度为 95% 的时间序列分类任务中的临界差(CD)图。
3.2 时间序列预测
给定最后 T l 个观测值 x t-T l +1 , ..., x t,时间序列预测任务旨在预测未来 H 个观测值 x t+1 , ..., x t+H 。我们使用最后一个时间戳的表示 r t 来预测未来的观测值。具体来说,我们训练一个带有 L 2 准则惩罚的线性回归模型,将 r t 作为输入直接预测未来值 xˆ。当 x 是单变量时间序列时,xˆ 的维度为 H;当 x 是具有 F 个特征的多变量时间序列时,xˆ 的维度应为 F H。
我们在四个公共数据集上比较了 TS2Vec 和现有 SOTAs 的性能,包括三个 ETT 数据集(Zhou 等,2021 年)和电力数据集(Dua 和 Graff,2017 年)。我们在单变量和多变量设置中分别应用了 Informer(Zhou 等,2021 年)、LogTrans(Li 等,2019 年)、LSTnet(Lai 等,2018 年)、TCN(Bai、Kolter 和 Koltun,2018 年),在单变量设置中应用了 N-BEATS(Oreshkin 等,2019 年),在多变量设置中应用了 StemGNN(Cao 等,2020 年)。按照之前的研究,我们使用 MSE 和 MAE 来评估预测性能。
单变量预测的 MSE 评估结果如表 2 所示,而完整的预测结果(单变量和多变量预测的 MSE 和 MAE)由于篇幅有限,将在附录中报告。总的来说,TS2Vec 在大多数情况下都建立了新的 SOTA,其中 TS2Vec 在单变量设置中实现了平均 MSE 下降 32.6%,在多变量设置中实现了平均 MSE 下降 28.2%。此外,每个数据集只需学习一次表征,并可直接应用于线性回归的各种水平(Hs),这证明了所学表征的通用性。图 5 展示了一个具有长期趋势和周期模式的典型预测切片,比较了单变量预测中表现最好的前 3 种方法(惊呼,这可视化出来的效果这么好吗???!!)。在这种情况下,Informer 展示了其捕捉长期趋势的能力,但未能捕捉周期性模式。TCN 成功捕捉了周期模式,但未能捕捉长期趋势。TS2Vec 则同时捕捉到了这两种特征,显示出比其他方法更好的预测结果。

表 2:关于 MSE 的单变量时间序列预测结果。
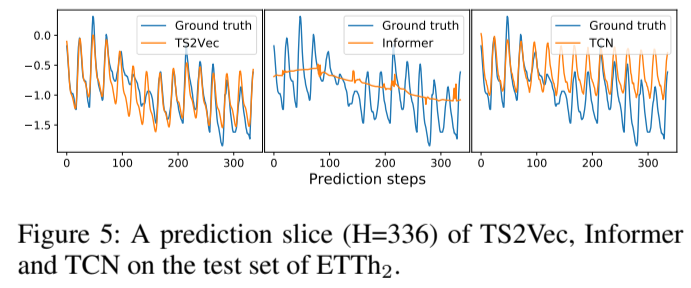
图 5:TS2Vec、Informer 和 TCN 对 ETTh 2 测试集的预测切片(H=336)。
表 3 列出了所提方法在 NVIDIA GeForce RTX 3090 GPU 上对 ETTm 1 的执行时间,并与 Informer(Zhou 等,2021 年)进行了比较。TS2Vec 的训练和推理时间分别为两个阶段。训练阶段包括两个阶段:(1)通过 TS2Vec 框架学习时间序列表示;(2)在学习到的表示之上为每个 H 训练线性回归器。同样,推理阶段也包括两个步骤: (1) 推断相应时间戳的表示,(2) 通过训练好的线性回归器进行预测。需要注意的是,TS2Vec 的表征模型只需针对不同的地平线(horizon settings)设置训练一次。无论是训练还是推理,与 Informer 相比,我们的方法都实现了更高的效率。

表 3:ETTm 1 数据集多变量预测任务的运行时间(秒)比较。
3.3 时间序列异常检测
我们遵循流式评估协议(Ren 等人,2019 年)。给定任意时间序列片段 x 1、x 2、...、x t,时间序列异常检测的任务是确定最后一个点 x t 是否是异常点。在学习到的表征中,异常点可能与正常点有明显的区别(图 7c)。此外,TS2Vec 鼓励在实例的相同时间戳上保持上下文一致性。考虑到这一点,我们建议将异常点得分定义为根据掩码输入和未掩码输入计算出的表征的差异。具体来说,在推理阶段,经过训练的 TS2Vec 会对一个输入进行两次转发:第一次,我们只掩码掉最后一个观测值 x t;第二次,不使用掩码。我们将这两次转发的最后一个时间戳的表示分别记为 r ut 和 r mt。L 1 距离用于测量异常得分:
![]() 为了避免漂移,根据之前的研究(Ren 等人,2019 年),我们取前 Z 点的局部平均值 α t = 1 Z t-1 i=t-Z α i 来调整异常得分,即 α adj t = α t -α t α t 。在推理中,当 α adj t > µ + βσ 时,时间戳 t 将被预测为异常点,其中 µ 和 σ 分别是历史得分的平均值和标准偏差,β 是一个超参数。
为了避免漂移,根据之前的研究(Ren 等人,2019 年),我们取前 Z 点的局部平均值 α t = 1 Z t-1 i=t-Z α i 来调整异常得分,即 α adj t = α t -α t α t 。在推理中,当 α adj t > µ + βσ 时,时间戳 t 将被预测为异常点,其中 µ 和 σ 分别是历史得分的平均值和标准偏差,β 是一个超参数。
我们将 TS2Vec 与其他单变量时间序列异常检测的无监督方法进行了比较,包括 FFT(Rasheed 等人,2009 年)、SPOT、DSPOT(Siffer 等人,2017 年)、Twitter-AD(Vallis、Hochenbaum 和 Kejariwal,2014 年)、Luminol(Brennan 和 Ritesh,2018 年)、DONUT(Xu 等人,2018 年)和 SR(Ren 等人,2019 年)。我们使用两个公共数据集来评估我们的模型。Yahoo (Nikolay Laptev,2015 年)是异常检测的基准数据集,包括 367 个带有标记异常点的每小时采样时间序列。它汇集了异常值和变化点等多种异常类型。KPI(Ren 等人,2019 年)是 AIOPS Challenge 发布的竞赛数据集。该数据集包括来自多家互联网公司的多条微小采样的真实 KPI 曲线。实验设置详见附录。
在正常设置中,每个时间序列样本按照时间顺序分成两半,前半部分用于无监督训练,后半部分用于评估。但是,在基线中,Luminol、Twitter-AD 和 FFT 不需要额外的训练数据就可以开始。因此,我们在冷启动设置下对这些方法进行了比较,在冷启动设置下,所有时间序列都用于测试。在这种情况下,TS2Vec 编码器在 UCR 档案中的 FordA 数据集上进行训练,并在 Yahoo 和 KPI 数据集上进行测试。我们将这一转换版本的模型称为 TS2Vec †。我们根据经验设置 β = 4,并按照(Ren 等人,2019 年)为两种设置设置 Z = 21。在正常设置中,我们协议的 µ 和 σ 是使用每个时间序列的训练分割来计算的,而在冷启动设置中,它们是使用最近点之前的所有历史数据点来计算的。
表 4 显示了不同方法在 F 1 分数、精确度和召回率方面的性能比较。在正常设置下,与基线方法的最佳结果相比,TS2Vec 在雅虎数据集上的 F 1 分数提高了 18.2%,在 KPI 数据集上提高了 5.5%。在冷启动设置中,与 SOTA 的最佳结果相比,F 1 分数在雅虎数据集上提高了 19.7%,在 KPI 数据集上提高了 1.0%。需要注意的是,我们的方法在这两种设置下获得了相似的分数,这表明 TS2Vec 可以从一个数据集转移到另一个数据集。

表 4:单变量时间序列异常检测结果。
4 分析
4. 1 消融研究
为验证 TS2Vec 中建议组件的有效性,表 5 显示了完整 TS2Vec 及其六个变体在 128 个 UCR 数据集上的对比情况,其中 (1) w/o Temporal Contrast 消除了时间对比损失,(2) w/o Instance Contrast 消除了实例对比损失、 (3) w/o Hierarchical Contrast 只在最底层进行对比学习;(4) w/o Random Cropping 使用两个视图的完整序列,而不是随机裁剪;(5) w/o Timestamp Masking 在训练中使用填充 1 的掩码;(6) w/o Input Projection Layer 删除输入投影层。结果表明,TS2Vec 的上述组成部分缺一不可。
表 5 还显示了不同正样本对选择策略之间的比较。我们将提议的上下文一致性(包括时间戳掩码和随机裁剪)替换为时间一致性(Tonekaboni、Eytan 和 Goldenberg,2021 年)和子序列一致性(Franceschi、Dieuleveut 和 Jaggi,2019 年)。时间一致性将一定距离内的时间戳作为正样本,而子序列一致性则随机将同一时间序列的两个子序列作为正样本。此外,针对输入时间序列的不同视图,我们尝试在方法中添加数据增强技术,包括抖动、缩放和排列(Eldele 等,2021 年)。在添加这些增强技术后,性能有所下降。如前所述,他们假定时间序列数据遵循一些不变的假设,而这些假设对于多样且不断变化的时间序列分布并不成立。(我感觉在某些场景下,这些假设是对的?或者说就是错的?emnnn...)
为了证明我们对骨干网的选择是正确的,我们用 LSTM 和 Transformer 替换了扩张的 CNN,参数大小相似。在这两种情况下,准确度得分都明显下降,这表明扩张型 CNN 是时间序列模型架构的有效选择。
(18:04去吃饭)
(19:21,继续看,还差一点看完了.)
4.2 对缺失数据的鲁棒性
缺失数据是现实世界中收集到的时间序列的常见现象。作为一种通用框架,TS2Vec 在馈送有大量缺失值的数据时能提供稳定的性能,其中所提出的分层对比和时间戳掩码策略发挥了重要作用。直观地说,时间戳掩码能让网络推断出不完整语境下的表征。分层对比带来了长程信息,有助于在周围信息不完整的情况下预测丢失的时间戳。
我们选择了最大的 4 个 UCR 数据集进行分析。我们随机掩码掉训练集和测试集中具有特定时间戳缺失率的观察结果。图 6 显示,在没有分层对比或时间戳屏蔽的情况下,分类准确率会随着缺失率的增加而迅速下降。我们还注意到,随着缺失率的增加,无层次对比度的分类准确率也急剧下降,这表明长范围信息对于处理大量缺失值的重要性。我们可以得出结论,TS2Vec 对缺失点的处理非常稳健。具体来说,即使有 50% 的缺失值,TS2Vec 在 UWaveGestureLibraryAll 上也能达到几乎相同的准确率,而在 StarLightCurves、HandOutlines 和 MixedShapesRegularTrain 上的准确率分别只下降了 2.1%、2.1% 和 1.2%。
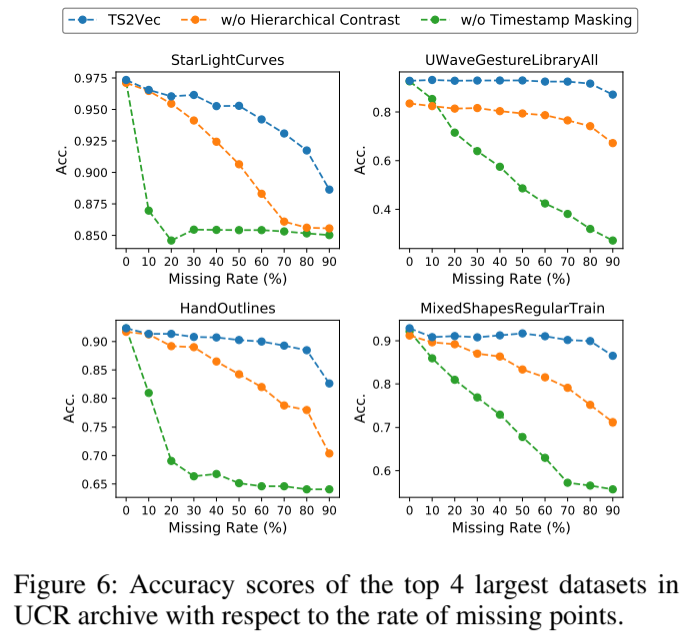
图 6:UCR 档案中最大的 4 个数据集在缺失点率方面的准确度得分。
4.3 可视化解释
本节将对 UCR 档案中的三个数据集(包括 ScreenType、Phoneme 和 RefrigerationDevices 数据集)的学习表征随时间变化的情况进行可视化(图 7)。我们从测试集中选择第一个样本,并选取方差最大的前 16 个表征维度进行可视化。图 7a 所对应的时间序列类似于二进制数字信号,TS2Vec 学习到的表示法可以清楚地区分高值和低值的时间戳。图 7b 显示的是波动性不断减小的音频信号。学习到的表示能够反映出各时间戳的变化趋势。在图 7c 中,时间序列具有周期性模式和一个突然的峰值。我们可以注意到,尖峰时间戳的学习表示与正常时间戳有明显区别,这表明 TS2Vec 能够捕捉时间序列分布的变化。

图 7:TS2Vec 的学习表示随时间变化的热图可视化。
5 结论
本文提出了一种通用的时间序列表示学习框架,即 TS2Vec,它应用分层对比来学习增强上下文视图中的尺度不变表示。在三个与时间序列相关的任务(包括时间序列分类、预测和异常检测)中对学习到的表征进行的评估证明了 TS2Vec 的通用性和有效性。我们还表明,当输入不完整数据时,TS2Vec 能提供稳定的性能,其中分层对比损失和时间戳掩码发挥了重要作用。此外,学习到的表征的可视化验证了 TS2Vec 捕捉时间序列动态的能力。消融研究证明了所提组件的有效性。TS2Vec 框架具有通用性,在我们未来的工作中有望应用于其他领域。
(19:43,看完了.)
(20:20了,给小导干了点杂活,现在总结一下这篇论文.)
没脑子了,总结一下:
1.多尺度特征(通过分层对比方法,池化操作)可以提供不同层次的语义,提高学习表征的泛化能力(对比通过时间对比损失+实例对比损失)。(分层对比)
2.同一子序列在两个增强上下文中的表示应保持一致(使用时间戳掩码和随机裁剪实现增强的上下文视图)。(上下文一致性)
(现在20:43,我的脑子一点也不转了,一团浆糊.)
(厌人情绪加重,很烦,抓紧看论文,跑实验,写论文,抓紧跑,多一天都不想待了.)
先这样吧,明后天脑子清醒了再回顾总结这篇论文,然后再和另外两篇论文串一下(虽然串完又会怀疑人生)。

