深度学习/NLP中的Attention注意力机制
首先是整体认知,Attention的位置:

传送门1:Attention 机制
传送门2:Attention用于NLP的一些小结
一句话概括:Attention就是从关注全局到关注重点。
借鉴了人类视觉的选择性注意力机制,核心目标也是从众多信息中选择出更关键的信息。
Attention的思路就是:带权求和。
Attention机制本身并不依赖于特定的框架。
具体的介绍看这篇文章,写的很详细,传送门3:深度学习中的注意力机制
在关于使用Encoder-Decoder框架中,进行机器翻译的Attention机制,这篇文章有句话:
“目标句子生成的每个单词对应输入句子单词的概率分布可以理解为输入句子单词和这个目标生成单词的对齐概率,这在机器翻译语境下是非常直观的:传统的统计机器翻译一般在做的过程中会专门有一个短语对齐的步骤,而注意力模型其实起的是相同的作用。
就是生成的概率分布就是作为实际应用中由输入得到结果的概率分布。
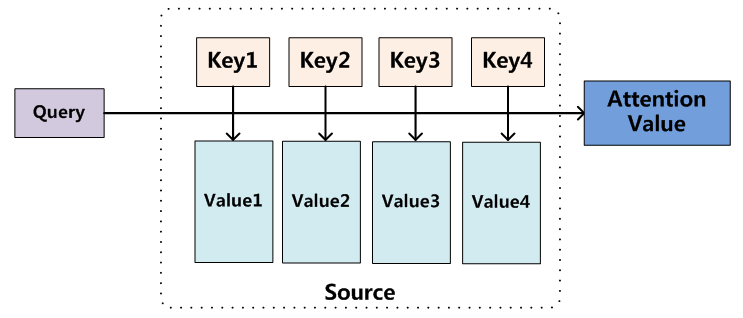
参考上面链接的文章,Attention机制就是:
将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。
个人理解:Attention就是从关注全局到关注重点。体现在权重系数的分配上,分配的值越大,说明关注度越高,也就是越重要。
链接文章的作者说,Attention机制算是一种寻址操作,个人理解感觉有点像遍历一个存了<key,value>的数组,通过条件查询key值,然后对对应的value值进行加权求和,最后得到结果。

Attention注意力机制
用图片很详细的介绍了机器翻译中,Attention的机制,主要介绍了以下内容:
-
seq2seq + attention
-
seq2seq with bidirectional encoder + attention
-
seq2seq with 2-stacked encoder + attention
-
GNMT — seq2seq with 8-stacked encoder (+bidirection+residual connections) + attention
传送门5:入门 | 什么是自注意力机制?
传动门6:Attention机制简单总结
传送门7:自然语言处理中的Attention机制总结 这篇写的很有逻辑

 浙公网安备 33010602011771号
浙公网安备 33010602011771号